CVPR 2024 | Scaffold-GS:自适应视角渲染的结构化 3D 高斯
CVPR 2024 | Scaffold-GS:自适应视角渲染的结构化 3D 高斯

引言
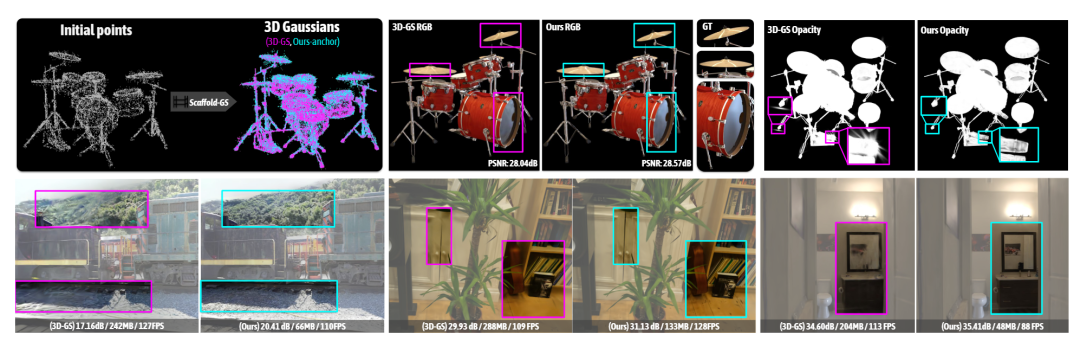
图 1
神经辐射场利用基于学习的参数模型来产生连续的渲染图像,并保留更多的细节。然而,其耗时的随机采样,会导致性能下降和出现潜在的噪声。
近年来,3D 高斯溅射(3D-GS)实现了最先进的渲染质量和速度。该方法从运动结构(SfM)产生的点云初始化,优化了一组 3D 高斯点,同时通过将 3D 高斯点投影到 2D 图像平面上来实现光栅化。但它往往会过度扩展高斯点以适应每个训练视图,从而忽略了底层的场景结构,这会导致严重的冗余并限制其可扩展性,特别是在复杂的大规模场景中。
为了解决这一问题,作者提出了 Scaffold-GS,利用锚点来建立分层和区域感知的 3D 场景表示。首先构建了一个从SfM 初始点的锚点稀疏网格。每个锚点都连接着一组具有可学习偏移量的神经高斯函数,根据锚点特征和视角位置动态预测其属性。Scaffold-GS 利用场景结构来引导和约束 3D 高斯的分布,同时允许它们局部适应不同的视角和距离。作者进一步引入锚点相应的致密和修剪操作,以增强场景覆盖范围。在推理时,将神经高斯的预测限制在视锥体内,并采用过滤操作筛选不透明度较低的神经高斯。
方法
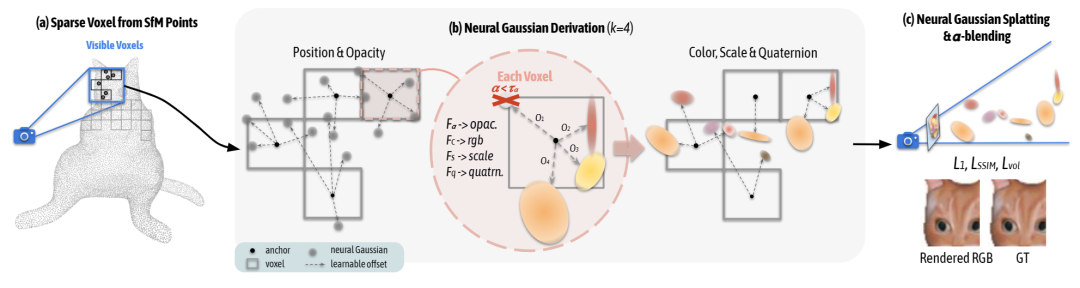
图 2.Scaffold-GS的框架
Scaffold-GS 使用具有层次结构的锚点表征场景。锚定在初始点的稀疏网格上,从每个锚点生成一组神经高斯,以动态适应各种视角和距离。该方法通过更紧凑的模型实现了与 3D-GS 相当的渲染质量和速度。在多个数据集上,Scaffold-GS 在大型室外场景和复杂的室内环境(具有挑战性的观察视图,例如室内)中表现出更强的鲁棒性。
锚点初始化
使用 COLMAP 中的稀疏点云作为初始输入, 然后将点云
中的场景体素化为:
其中
表示体素中心,
是体素大小。
表示删除重复的锚点,以减少
中的冗余和不规则性。
每个体素
的中心被视为锚点,其属性有局部上下文特征
、缩放因子
和 k 个可学习偏移量
。为方便表示,将锚点表示为
。为了增强上下文特征
的多分辨率性和视图相关性, 对于每个锚点
:1) 创建一个特征库
,其中
表示
被下采样
个因子;2)将特征库和视角相关的权重累加以形成集成的锚特征
。具体来说,给定相机位置
和锚点位置
,利用下式计算得到它们的相对位置
和视角方向
:
然后利用小型 MLP
预测权重,对特征库进行加权求和:
如图 2 所示,神经高斯的属性有位置
、不透明度
、协方差相关的四元数
和缩放
以及颜色
。如图 2(b)所示,对于视锥体内的每个可见锚点,生成 k 个神经高斯并预测它们的属性。具体来说,给定位于
的锚点,其神经高斯的位置计算如下:
其中
是可学习的偏移量,
是与该锚点相关的缩放因子。k 个神经高斯的属性是通过各个独立的 MLP(
、
、
和
)进行预测。例如,从锚点生成的神经高斯函数的不透明度值由以下公式给出:
属性颜色
、四元数
和尺度
的预测方式和上式类似。渲染时,只有视锥体内可见的锚点才会生成神经高斯。为了使光栅化更有效,只保留不透明度大于预定义的阈值
的神经高斯。这大大减少了计算量,并使得 Scaffold-GS 保持与原始 3D-GS 相当的渲染速度。
锚点细化
1. 致密操作
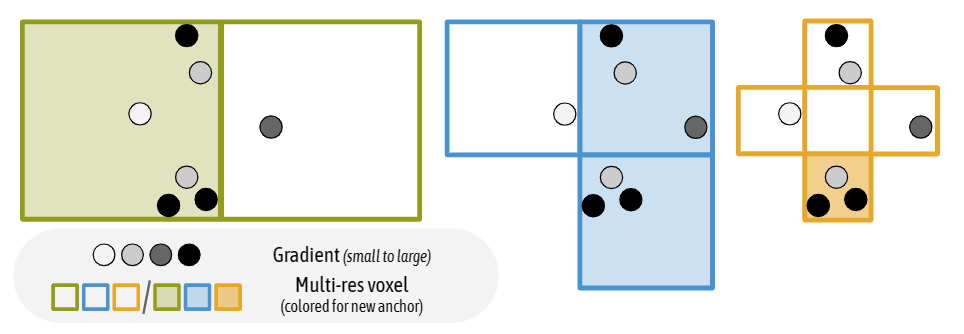
图 3.致密操作
由于神经高斯模型与其初始化的锚点密切相关,因此它们的建模能力仅限于局部区域。为此,作者提出了一种基于误差的锚点致密策略,即在神经高斯函数发现显著的地方产生新的锚点。为了确定显著区域,如图 3 所示,首先通过构造大小为
的体素来对神经高斯进行空间量化。对于每个体素,计算 N 次训练迭代中包含的神经高斯函数的平均梯度,表示为
。然后,
的体素被认为是显著的,其中
是预先定义的阈值,锚点会部署在该体素的中心。实际应用中,空间会被量化为多分辨率的体素网格,以允许以不同的体素添加新的锚点,其中:
其中
表示量化级别。为了进一步规范新锚点的添加,作者对这些候选锚点采用随机消除的方式,这有效遏制了锚点的快速扩张。
2. 裁剪操作
为了消除冗余的锚点,在 N 次训练迭代中累积其相关神经高斯的不透明度值。如果锚点中神经高斯的不透明度小于阈值,就会将其删除。
损失函数设计
使用 SSIM 项
、体积正则化
,以及针对渲染像素颜色的
损失来优化可学习参数和 MLP。总损失函数由以下方式给出:
其中体积正则化
表示为:
其中
表示场景中神经高斯的数量,
是向量值的乘积,向量为每个神经高斯的尺度
。体积正则化项使得神经高斯变小并最小化重叠。
实验结果
对比实验
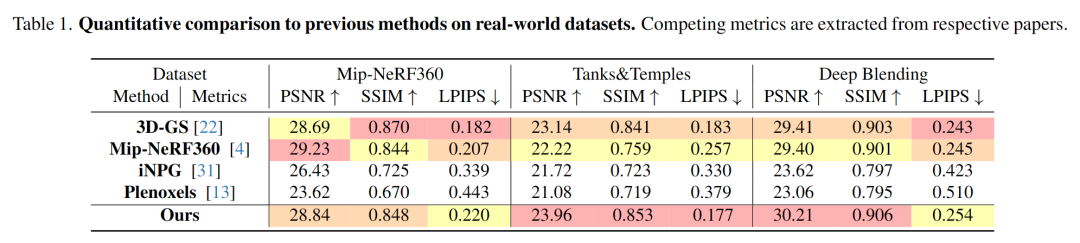
表 1.与各数据集上的先前方法进行定量比较
在评估 Scaffold-GS 的质量时,在真实数据集上与 3D-GS 、Mip-NeRF360、iNGP 和 Plenoxels 进行了比较,定性结果显示在表 1 中。Mip-NeRF360、iNGP 和 Plenoxels 的质量指标与 3D-GS 研究中报告的一致。可以注意到,Scaffold-GS 在 Mip-NeRF360 数据集上取得了与 SOTA 算法相当的结果,并且超越了 Tanks&Temples 和 DeepBlending 上的 SOTA,后者捕获了更具挑战性的环境,例如改变光照、无纹理区域和反射。
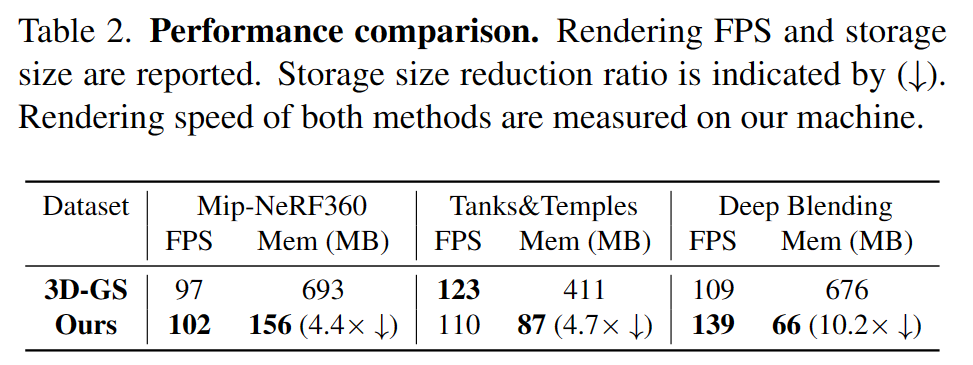
表 2.性能比较
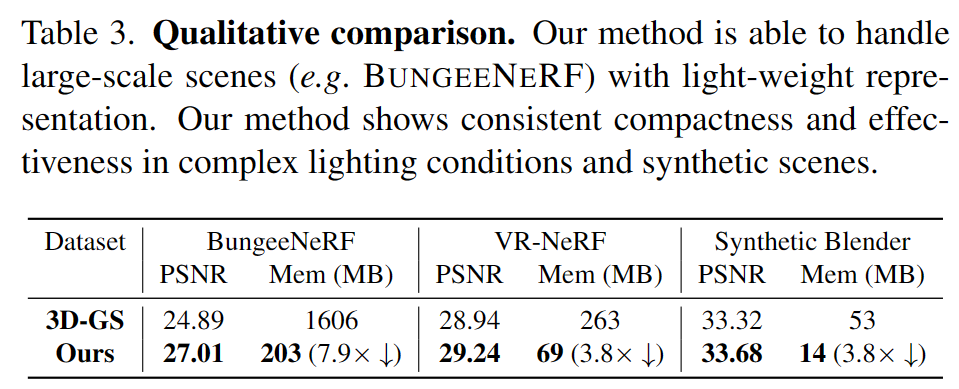
表 3.定性比较
在效率方面,作者评估了 Scaffold-GS 和 3D-GS 的渲染速度和存储大小,如表 2 所示。该方法在使用较少存储的情况下实现了实时渲染,这表明该模型比 3D-GS 更紧凑,而不会牺牲渲染质量和速度。此外,与之前基于网格的方法类似,该方法比 3D-GS 收敛得更快。此外在合成 Blender 数据集上进行了实验。由于此数据集不容易获得一组良好的初始 SfM 点,因此从 100k 的点开始,通过锚点细化操作进行致密和修剪。经过 30k 次迭代后,使用剩余的点作为初始化锚点并重新运行。表 3 为与 3D-GS 对比的 PSNR 和存储大小。
消融实验
1. 过滤策略的有效性
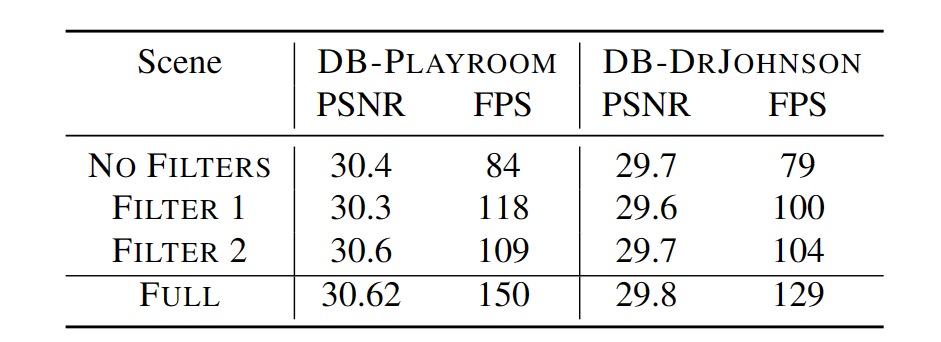
表 4.过滤策略的效果
过滤策略对于加快渲染速度至关重要。如表 4 所示,虽然该策略对渲染质量没有显著的影响,但它们提高了推理速度。然而,该策略存在掩盖相关神经高斯的问题。
2. 锚点细化策略的有效性
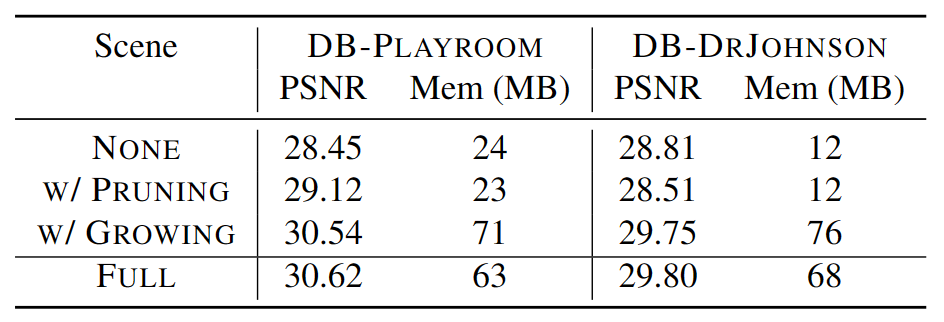
表 5.锚点细化的效果
表 5 显示了单独禁用致密操作和裁剪操作的实验结果。致密操作对于重建细节和无纹理区域至关重要,而修剪操作在消除冗余锚点起着重要作用。
总结
通过实验,作者发现初始点对于高质量渲染结果起着至关重要的作用。考虑到这些点云通常作为图像校准过程的副产品出现,从 SfM 点云初始化框架是一个快速且可行的解决方案。对于较大的无纹理区域为主的场景,这种方法可能不是最佳的。尽管锚点细化策略可以在一定程度上解决这个问题,但它仍然受到初始点极其稀疏的影响。