综述 | 牛津大学等机构最新研究:扩散模型在时间序列和时空数据中的应用
综述 | 牛津大学等机构最新研究:扩散模型在时间序列和时空数据中的应用

本文介绍一篇来自牛津大学、莫纳什大学等12家机构联合发表的一篇综述研究工作。这篇综述文章深入探讨了扩散模型在时间序列和时空数据中的应用。扩散模型作为一种强大的工具,不仅增强了序列和时序数据的生成和推理能力,还扩展到了其他下游任务。文章从模型类别、任务类型、数据模态和实际应用领域等多个维度对扩散模型进行了分类和讨论。

【论文标题】A Survey on Diffusion Models for Time Series and Spatio-Temporal Data
【论文地址】https://arxiv.org/abs/2404.18886
【项目地址】https://github.com/yyysjz1997/awesome-timeseries-spatiotemporal-diffusion-model
【作者】Yiyuan Yang (杨毅远), Ming Jin (金明), Haomin Wen (温浩珉), Chaoli Zhang (张超利), Yuxuan Liang (梁宇轩), Lintao Ma (马琳涛), Yi Wang (王毅), Chenghao Liu (刘成昊), Bin Yang (杨彬), Zenglin Xu (徐增林), Jiang Bian (边江), Shirui Pan (潘世瑞), Qingsong Wen (文青松)
【机构】牛津大学,莫纳什大学,北京交通大学,香港科技大学(广州),浙江师范大学,蚂蚁集团,香港大学,Salesforce,华东师范大学,复旦大学,微软亚洲研究院,格里菲斯大学,松鼠AI
论文概述
时间序列和时空数据分析从根本上依赖于对它们内在时间动态的深刻理解,其中主要任务主要集中在骨干模型的生成能力上,如预测、插补和生成。这些分析集中在以有条件或无条件的方式为特定目的生成时序数据样本上。鉴于时间序列和时空基础模型的近期发展,无论这些模型是基于大模型(LLMs)构建的,还是从头开始训练的,它们的成功都可以归因于它们能够估计训练样本的分布,并从中提取有效的数据表示。
在这方面,扩散模型作为一种强大的生成框架脱颖而出,它使得对时序数据中的复杂模式进行建模,以及支持广泛的下游任务成为可能,如图1所示。
扩散模型代表了一类概率生成模型,这些模型通过一个包括在一组训练样本中注入噪声及其后续移除的两步过程进行优化。这个过程包括一个前向阶段,称为扩散,以及一个反向阶段,称为去噪。通过训练模型去除在扩散过程中加入的噪声,模型在推断过程中学会生成与训练数据分布紧密对齐的有效数据样本。
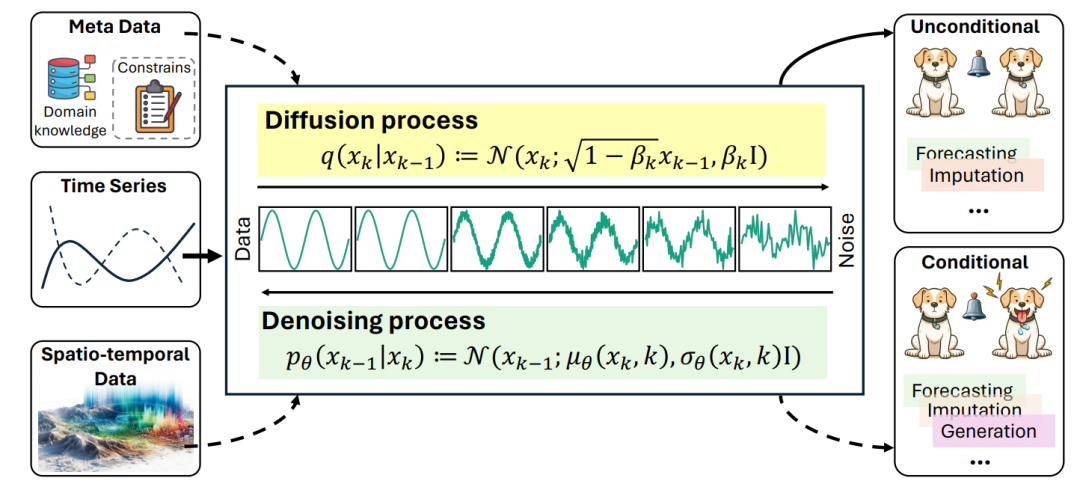
图1 时间序列和时空数据分析中扩散模型的概述
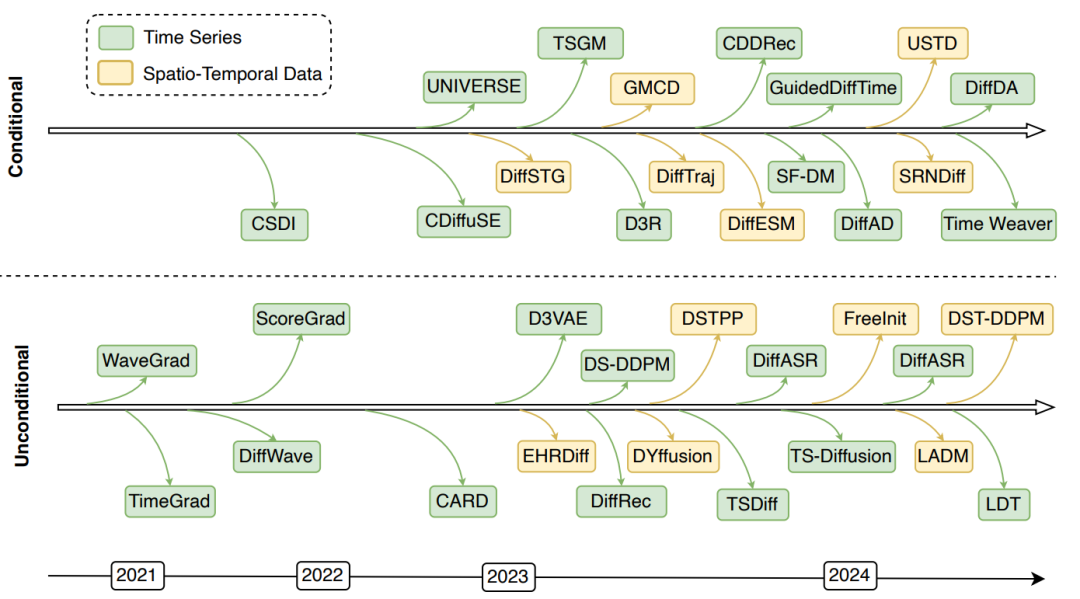
图2 近年来时间序列和时空数据的代表性扩散模型
尽管扩散模型在处理时间序列和时空数据方面展现出了令人鼓舞的前景和快速的进步,但现有文献中对该模型族的系统分析却明显不足。本文旨在弥补这一空白,通过前瞻性综述详细阐述“为什么”以及“如何”——详细解释为什么扩散模型适合这些数据类型,并揭示它们如何赋予优势。
该论文综述的主要框架思路如下,本文将摘取部分内容进行解读,感兴趣的朋友可阅读论文原文了解更多。
- 第2章:介绍扩散模型的背景,详细阐述了其发展历程、理论基础和各种实现方式。
- 第3章:对应用于时间序列和时空数据的扩散模型进行结构化的概述和分类。
- 第4章:从模型视角出发,深入探讨各种扩散模型的机制、特性和应用,以揭示它们在处理时间序列和时空数据时的优势和限制。
- 第5章:从任务视角出发,探讨扩散模型在预测、生成、插补、异常检测等任务中的应用。
- 第6章:从数据视角出发,讨论时间序列和时空数据特有的挑战和解决方案。
- 第7章:探索扩散模型在不同领域的应用,如医疗保健、交通和能源等。通过实际案例和应用场景,展示扩散模型在这些领域中的广泛适用性和实用性。
- 第8章:总结扩散模型在时间序列和时空数据分析中的优势和挑战,并探讨未来可能的研究方向和发展趋势。
扩散模型概述分类
本节概述并分类了用于解决时间序列和时空数据分析中挑战的扩散模型。论文的讨论沿着四个主要维度展开:扩散模型的类别、任务类型、数据模态以及实际应用。图3展示了相关工作的综合总结。
研究者将现有文献分为两大类:无条件扩散模型和条件扩散模型,重点关注时间序列和时空数据。
在无条件类别中,扩散模型以无监督的方式工作,生成数据样本而无需监督信号。这种设置代表了分析时间序列和时空数据的基础方法。在这一类别中,文献可以进一步分为基于概率的扩散模型和基于得分的扩散模型。例如,包括去噪扩散概率模型(DDPMs)和基于得分的随机微分方程(Score SDEs)。该类别中的研究大致分为两个任务组:预测任务和生成任务。
在条件类别中,扩散模型被定制用于时间序列和时空数据的条件分析。实证研究表明,利用数据标签的条件生成模型相较于无条件模型更容易训练,并且性能更优。在此上下文中,标签(又称条件)通常来自各种来源,如提取的短期趋势和城市流量图,以增强模型的推断能力。这一类别包含了基于概率和基于得分的扩散模型,用于预测和生成任务,为在特定约束下利用扩散模型解决时间序列和时空数据分析中的实际问题提供了新的视角。
在论文的后续部分,研究者则更详细地探讨这些模型的具体实现、优缺点以及在不同任务和数据模态下的应用。
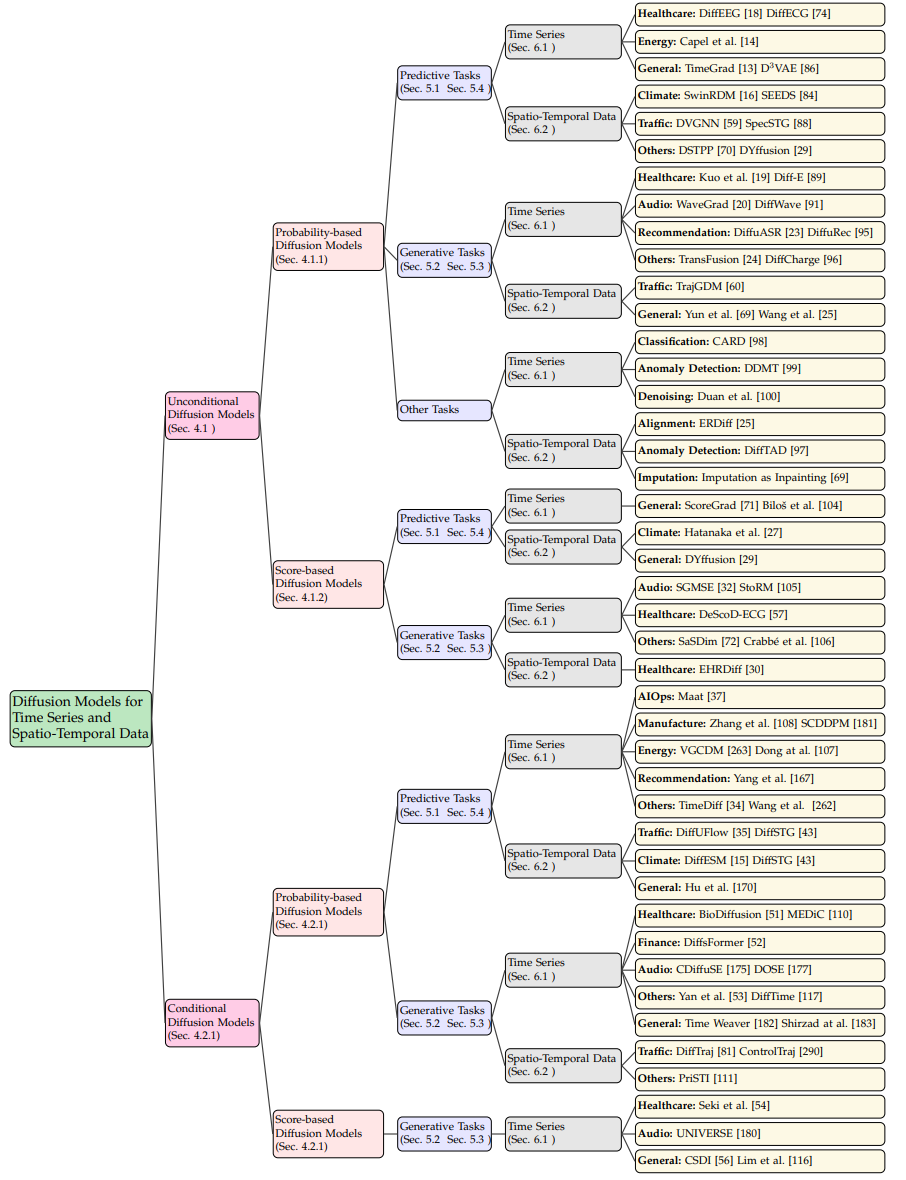
图3 时间序列和时空数据扩散模型的全面分类,按照方法学(即无条件与条件)、任务(例如预测与生成)、数据类型和应用领域进行分类
模型视角
在模型视角的这一部分,研究者分析了如何从模型的角度使用扩散模型来处理时间序列和时空数据。具体地,将重点关注标准扩散模型(如DDPM和score SDE)以及改进的扩散模型(如有条件的扩散模型、LDM、DDIM等)。
标准扩散模型:如DDPM(去噪扩散概率模型)和score SDE(基于得分的随机微分方程),在时间序列和时空数据的处理中发挥着基础性的作用。这些模型通过引入噪声并学习从噪声中恢复数据的过程,实现了对数据的生成和推理。
DDPM模型:通过定义前向过程和反向过程来处理数据。在前向过程中,模型将原始数据逐步添加噪声以生成噪声数据;在反向过程中,模型则通过学习从噪声数据中恢复原始数据的能力,来实现对数据的生成。DDPM模型的关键在于训练一个能够准确估计噪声的模型,以便在反向过程中能够成功恢复原始数据。
score SDE模型:则通过定义基于得分的随机微分方程来描述数据的动态变化过程。该模型利用得分函数(即数据分布的对数导数的负值)来指导数据的生成和推理过程。通过求解得分方程,模型可以生成符合给定数据分布的新数据。
改进的扩散模型:在标准模型的基础上进行了扩展和优化,以适应更复杂的数据和任务。有条件的扩散模型通过引入额外信息(如类别标签、条件约束等)来增强模型的性能。LDM(潜在扩散模型)和DDIM(离散时间隐变量模型)等模型则通过引入隐变量和离散时间步长等概念来改进模型的生成和推理能力。
在处理时间序列和时空数据时,这些模型可以通过捕捉数据中的时间和空间依赖关系来实现对数据的准确生成和推理。例如,在时间序列预测任务中,模型可以通过学习历史数据中的趋势和周期性规律来预测未来的数据值。在时空数据分析中,模型可以通过捕捉不同空间位置和时间点之间的相关性来揭示数据中的复杂模式和结构。
任务视角
在这一部分中,研究者探讨了扩散模型在不同任务中的应用,包括预测、生成、插补和异常检测,并强调它们在不同领域中对复杂时间序列和时空数据分析的有效性。
01、预测
时间序列预测领域在引入扩散模型后取得了显著的进展。TimeGrad 和 D3VAE 都采用了扩散概率模型来增强预测能力。TimeGrad 专注于自回归技术(即RNN)来进行概率预测,而D3VAE则引入了一个包含扩散和去噪过程的双向变分自编码器。这种生成式方法在D-Va 的工作中得到了进一步扩展,该研究通过深度层次VAE结合扩散概率技术来处理股票价格数据的随机性。
与此同时,另一项研究[104]采取了不同的方法,将时间数据建模为连续函数,从而能够处理不规则采样的数据。基于扩散模型,TimeDiff 引入了新颖的条件机制、未来混合(future mixup)和自回归初始化(autoregressive initialization),以改进时间序列预测。最后,研究[164]探索了与任务无关的无条件扩散模型,提出了TSDiff,它采用了一种自指导机制,适用于各种时间序列应用。
对于时空数据,已经提出了多种基于扩散模型的方法来解决复杂的预测问题。以下是一些主要的研究进展:
DiffSTG 是首个将去噪扩散概率模型推广到时空图的工作,旨在建模时空图数据中的复杂时空依赖性和内在不确定性,以进行更好的预测。通过这种方法,DiffSTG 可以更准确地捕捉和预测时空数据中的动态变化。
DYffusion 介绍了一个框架,该框架训练了一个随机、时间条件插值器和一个预测器网络,用于执行时空数据的多步骤和长范围概率预测。这种方法考虑了时空数据的复杂性和不确定性,从而提高了预测的准确性。
DiffUFlow 则专注于城市数据,旨在解决细粒度流量推断的挑战。它采用了一种基于扩散模型的框架,可以捕捉城市中的交通流量模式,并预测未来的流量情况。
DSTPP 为时空点过程提供了一种新颖的参数化方法。这种方法可以建模和预测时空数据中的点事件,如地震、疾病爆发等,为灾害预警和公共卫生管理提供了有力的工具。
SwinRDM 和 DOT 分别展示了扩散模型在改进天气预报和旅行时间估计质量方面的适应性。SwinRDM 通过结合变分递归神经网络和特征摄动模块,实现了高精度的天气预报。而 DOT 则采用了一个基于扩散模型的起点-终点行程时间估计框架,通过学习OD对和历史轨迹之间的关联性,提高了旅行时间估计的精度。
02、生成
受到扩散模型在高维分布学习方面强大能力的启发,一个直观的应用是将学习到的扩散模型用于数据生成。目前,已经提出了多种扩散模型来生成音频数据。
WaveGrad 是一项开创性的工作,它利用基于梯度的采样来生成高保真度的音频波形,标志着音频合成领域的重大进展。同样,DiffWave 采用了一种非自回归的方法,通过马尔可夫链过程实现高效且高质量的原始音频合成。WaveGrad 和DiffWave 都属于同一研究脉络,利用扩散模型的强大功能从简单的噪声分布中创建复杂的波形。
DOSE 则采取了不同的方法,专注于语音增强任务。它引入了一种模型无关的方法,将条件信息整合到扩散过程中。这种方法可以提高语音信号的质量,减少背景噪声和其他干扰因素。
除了上述提到的应用外,扩散模型还被用于序列推荐。DiffuASR 提出了一种基于扩散的序列生成框架,以解决序列推荐系统中数据稀疏性和长尾用户问题。它引入了一个专为离散序列生成任务设计的序列 U-Net,并利用两种引导策略来模拟生成序列和原始序列之间的偏好。DreamRec 则采用 Transformer 编码器来创建引导表示作为扩散过程中的条件。
在时空数据的领域,扩散模型也被用于生成轨迹数据。例如,DiffTraj 首次提出了一个无条件模型来生成高质量的人类轨迹,其动机是保护隐私。与此同时,[65] 利用基于起止点(origin-destination)信息的条件模型来生成网格格式的轨迹。这些工作展示了扩散模型在生成轨迹数据方面的潜力,不仅可以在保护隐私的同时生成高质量的轨迹,还可以根据特定条件生成符合需求的轨迹。
03、插补
时间序列和时空数据分析的领域中,插补(Imputation)指的是根据给定的观测数据生成未观测到的数据。以下是一些与插补相关的基于扩散模型的方法:
CSDI (Conditional Score-based Diffusion Imputation):该方法提出了一个基于得分的扩散模型,用于概率性地插补缺失的时间序列和时空数据。它基于条件扩散模型进行多变量时间序列插补,确保了观测值和缺失值的一致性。
MIDM (Multivariate Imputation with Diffusion Models):该方法重新定义了条件扩散模型中的证据下界(ELBO),以适应多变量时间序列插补的需求。通过这种方法,MIDM能够在保持观测值和缺失值一致性的同时,实现准确的插补。
PriSTI (Prioritized Spatio-Temporal Imputation):该方法专门为时空数据插补设计了一个条件扩散框架。它利用全局上下文先验信息和地理关系来处理由于传感器故障导致的高缺失数据率场景。通过结合这些信息,PriSTI能够在复杂的时空环境中进行准确的插补。
TabCSDI (Tabular Conditional Score-based Diffusion Imputation):该方法利用扩散模型对表格数据进行缺失值插补。它有效地管理了表格数据集中的分类和数值数据,为不同数据类型提供了定制的解决方案。
MissDiff:该方法通过引入一种新颖的掩码技术来改进扩散模型的训练过程,从而确保了对数据分布的一致学习和对不同缺失数据场景的鲁棒性。MissDiff专注于通过回归损失进行插补,适用于各种表格数据中的缺失值问题。
04、异常检测
在异常检测领域,特别是在时间序列和时空数据的异常检测中,目标是从给定的数据中识别出异常值。这些异常值对于许多现实世界的应用来说都是非常重要和实用的。以下是一些基于扩散模型的异常检测方法:
DiffAD 和 ImDiffusion:这两个方法都探索了插补技术与扩散模型在时间序列异常检测中的协同作用,通过准确建模复杂的依赖关系来增强异常检测过程的鲁棒性。
其他基于扩散的方法:还有其他的研究使用了类似的基于扩散的方法来解决异常检测问题,但应用了不同的增强技术来提高性能和计算效率。
处理动态环境和噪声:针对动态环境中的不稳定性和噪声问题,一些研究实施了先进的扩散重构技术来保持准确性。
跨领域的应用:除了针对一般时间序列异常检测的方法外,还有一些工作将先进的扩散技术应用于各种领域。例如,Maat 使用条件去噪扩散模型预测云服务中的性能指标并检测异常;[270]使用条件扩散模型框架中的注意力机制来增强机器故障诊断的数据合成;Diffusion-UDA 提出了一种基于扩散的方法,用于潜水器故障诊断中的无监督领域适应,利用扩散过程来适应不同领域以实现有效的故障识别。
未来展望
研究者指出了时间序列和时空数据的扩散模型未来值得进一步研究的5大方向。
01、可扩展性和效率
扩散模型的计算复杂度为其在资源受限或实时环境中的应用带来了挑战。因此,提高其可扩展性和效率对于在现实世界场景中部署这些模型至关重要。未来的研究可以探索更轻量、更快的扩散模型版本,这些版本在显著降低计算需求的同时保持性能。此外,还可以进一步努力进行模型压缩、并行计算和针对时间序列和时空数据中的扩散模型优化的高效采样策略。
02、鲁棒性和泛化能力
现实世界中的时间序列和时空数据常常存在噪声、缺失数据、异常值和分布偏移等数据挑战。研究并增强扩散模型对这些数据挑战的鲁棒性至关重要。因此,提高模型在不同数据集和场景下的泛化能力也是一个有趣的扩展方向,以增加在不同领域中的应用性和可靠性。此外,研究还可以关注开发能够动态适应新数据特性或变化环境而无需人工干预的框架。
03、先验知识指导的生成
时间序列和时空数据的生成过程应该遵循特定的约束条件。例如,生成的轨迹应该沿着道路网络传播,人口迁移数据应符合社会演变模式,火灾的蔓延应遵守热力学原理。尽管现有的大多数扩散模型能够基于某些有用条件生成相应的时间序列或时空数据,但在实践中仍然缺乏对这类先验知识的充分考虑。
未来的研究可以探索如何在扩散模型的生成过程中整合和利用这些先验知识。这可以通过设计具有特定约束的模型架构、引入领域特定的规则或正则化项,以及利用专家知识或历史数据来指导生成过程来实现。通过这种方式,扩散模型可以生成更符合实际世界规律和约束的时间序列和时空数据。
04、多模态数据融合
在复杂的现实世界中,时间序列和时空数据通常伴随着其他数据类型,如文本和视觉信息。在扩散模型中探索多模态数据源的融合可以显著提高性能。这在金融和医疗保健等领域尤为有用,因为整合多样化的数据源可以带来更全面和准确的分析。
未来的研究可以开发新的架构,更有效地合并这些多样化的数据流。这可以通过设计能够同时处理不同类型数据的模型、开发跨模态交互的机制以及利用深度学习技术来提取和融合来自不同模态的信息来实现。通过这种方法,扩散模型可以在处理多模态时间序列和时空数据时提高预测性能和对上下文的理解能力。
05、大模型与扩散模型的结合
大模型(LLMs)与扩散模型在时间序列和时空数据分析中的结合,为深入理解复杂系统和改进决策制定提供了巨大的潜力。特别是,利用LLMs的自然语言理解能力可以增强时间推理,并为复杂系统提供更全面的视图。
未来的研究可以包括开发结合模型,这些模型利用扩散模型的生成能力,同时结合LLMs丰富的语义和句法处理能力。这种结合有可能为自动推理和决策系统开辟新的途径。
*作者简介:杨毅远,牛津大学计算机系博士生,牛津克拉伦登学者,研究方向数据挖掘、时间序列、生成模型、信号处理等。