ICML 2024 | Moirai:首个全开源时间序列预测基础模型来了!
ICML 2024 | Moirai:首个全开源时间序列预测基础模型来了!

时序数据广泛存在于零售、金融、制造业、医疗等多个领域,其中时序预测应用对于决策制定有着重要的意义。尽管深度学习方法在时序预测中取得了巨大进展,但其依旧遵循传统机器学习范式:针对特定数据集的特定预测任务(预测长度)训练相对应的模型。
然而,这种模式随着时序预测任务的增多,计算成本和人力成本会显著的增加。能否像视觉和语言领域一样,构造一个预训练大模型进行通用时序预测?近期,ICML 2024 的一篇论文给出了肯定答案!
来自 Salesforce AI research 的研究者提出了首个全开源时间序列预测基础模型MOIRAI,这是一种通用的预测范式,使得预训练模型有能力处理任意的时序预测任务。与当下最优的从零训练模型相比,MOIRAI 的 zero-shot 预测能力具有竞争力甚至表现出更优越的性能。
此外,研究者们发布并开源了预训练框 uni2ts、MOIRAI 模型权重以及 LOTSA 当下最大的开源时序预测预训练数据集。

【论文标题】Unified Training of Universal Time Series Forecasting Transformers
【预训练代码】https://github.com/SalesforceAIResearch/uni2ts
【预训练数据集】https://huggingface.co/datasets/Salesforce/lotsa_data
通用时序预测基础模型面临的挑战
与视觉和语言模态分别具有统一的图像和文本格式不同,时间序列数据具有高度异质性。
第一,时间序列的频率(例如,分钟级、小时级、日采样率)在确定时间序列中存在的模式方面起着重要作用。由于负干扰,跨频率学习已被证明是一项具有挑战性的任务,现有工作通常为每个频率训练一个模型来解决多频率问题。
第二,时间序列数据在维度上也是异质的,其中多元时间序列可以有不同数量的变量。此外,每个变量在跨数据集时测量的是语义上不同的量。虽然可以考虑多元时间序列的每个变量独立地来规避这个问题,但我们期望一个通用模型能够足够灵活,以考虑多元变量之间的交互并考虑外生协变量。
第三,概率预测是实践者经常需要的关键特征。然而,不同的数据集具有不同的支撑集和分布特性——例如,使用对称分布(如正态分布、t分布)作为预测分布不适合正时间序列——使得预先定义简单参数分布的标准方法不足以灵活地捕获各种数据集。
第四,一个能够进行通用预测的大型预训练模型需要来自不同领域的大规模数据集。现有的时间序列数据集不足以支持此类模型的训练。
为了解决上述挑战,研究者对传统的时间序列 Transformer 架构进行了新颖的改进,提出了基于掩码编码器的通用时间序列预测 Transformer(MOIRAI),以处理任意时间序列数据的异构性,具体贡献如下:
- 本文通过学习多个输入和输出 projection layer(投影层)来解决时间序列数据中不同频率的挑战。这些层旨在处理不同频率的时间序列中存在的不同模式。并采用 patch-based(基于块)的 projection,较大的 patch size 对应高频数据,这样 projection layer 便能够学到不同频率的模式。
- 研究者提出了 Any-variate(任意变量)的注意力机制来解决可变维度问题,这种方法同时将时间轴和变量轴视为单个序列,并利用 RoPE(Rotary Position Embedding,旋转位置嵌入)和可学习的二元注意力偏差来分别对时间轴和变量轴进行编码。特别地,Any-variate 注意力使得模型能够接受任意数量的变量作为输入。
- 研究者引入了一种混合的参数分布来解决数据集具有不同概率分布的问题,并对分布的(negative log-likelihood)负对数似然进行优化。
最后,为了解决时序领域大规模数据集的欠缺,本文引入了 LOTSA,引入了LOTSA,这是用于预训练时间序列预测模型的最大规模的开放数据集集合。该集合涵盖 9 大数据领域,包含 27B 观测值,231B 数据点。
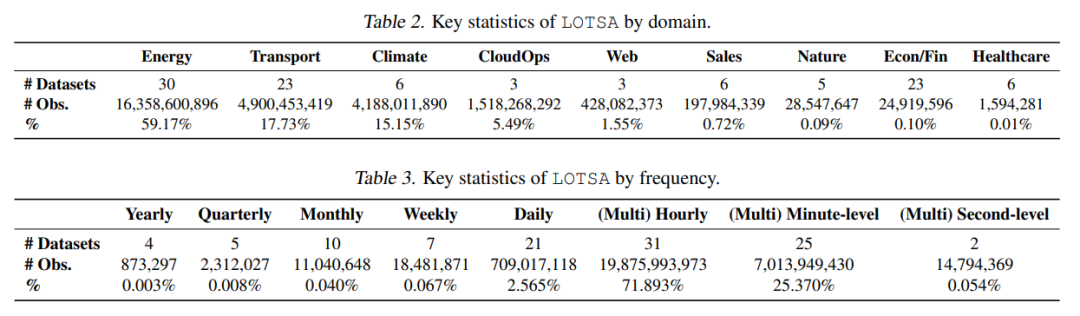
表1 按领域/频率分类的LOTSA关键统计数据
Moirai架构介绍
如图1所示,MOIRAI 采用了一种基于(非重叠)补丁的方法来建模时间序列,其架构为一个带有掩码的编码器。为了在 any-variate 的设置下拓展架构,作者采取的手段是将多变量时序数据“展平”,即将所有变量看作单一的序列。输入变量通过分块处理后,不同 patches 通过 multi-patch 的输入层投影到向量表示。
图1中的 [mask] 表示可替换预测范围内的 patch 的一种可学习的 embedding(嵌入)。最终通过 multi-patch 输出层将输出 token 解码为混合分布的参数。在输入/输出中,作者还加入了 instance normalization(实例标准化)进行处理。
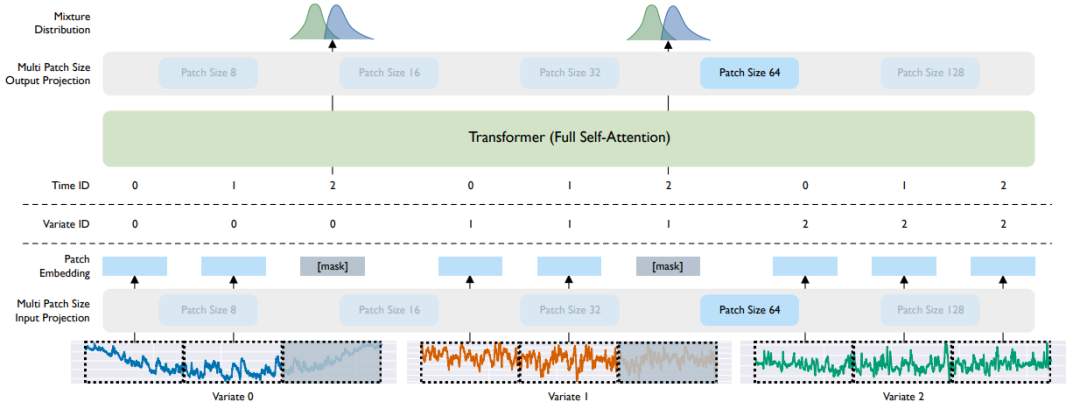
图1 MOIRAI的整体架构
其中变量 0 和 1 是目标变量(即需要预测的变量),而变量 2 是一个动态协变量(在预测范围内已知的值)。基于 64 的补丁大小,每个变量都被划分为 3 个标记。补丁嵌入与序列和变量 ID 一起被输入到 Transformer 中。图中阴影部分的补丁表示需要预测的预测范围,其对应的输出表示被映射为混合分布参数。
预训练阶段
研究者将预训练任务设计为优化混合分布的对数似然。其中,数据分布和任务分布的设计是预训练流程中的两个关键方面。
这种设计赋予长期记忆(LTM)模型以多种能力,使其能够适应一系列下游任务。这种灵活性与现有的深度预测范式形成鲜明对比,后者中的模型通常针对特定数据集和设置进行专门化。
数据分布设计,(Y, Z)~ p(D)定义了如何从数据集中抽取时间序列。研究者在 LOTSA 数据集上进行训练。通过将数据分布分解为子数据集分布和基于子数据集的时间序列分布,进而引入了子数据集的概念。因此,研究者首先从 p(D) 中抽取一个子数据集,然后基于该子数据集抽取一个时间序列。然而,由于不同领域和频率之间的数据不平衡,为避免按比例抽取子数据集,而是首先限制每个子数据集的贡献在 ϵ = 0.001 之内,然后再进行归一化。
任务分布设计,与现有的深度预测范式不同,研究者的目标是训练一个能够在不同上下文和预测长度下具有预测能力的模型。因此,并不定义固定的上下文和预测长度,而是从任务分布中采样,该分布定义了给定时间序列的回溯窗口和预测范围。
实验结果 研究者训练了 small/base/large 三种不同规模的模型,分别有 14m/91m/331m 个参数,在通过 Monash 时序预测基准上进行 in-distribution 评估时,MOIRAI 模型击败了所有的基准模型。
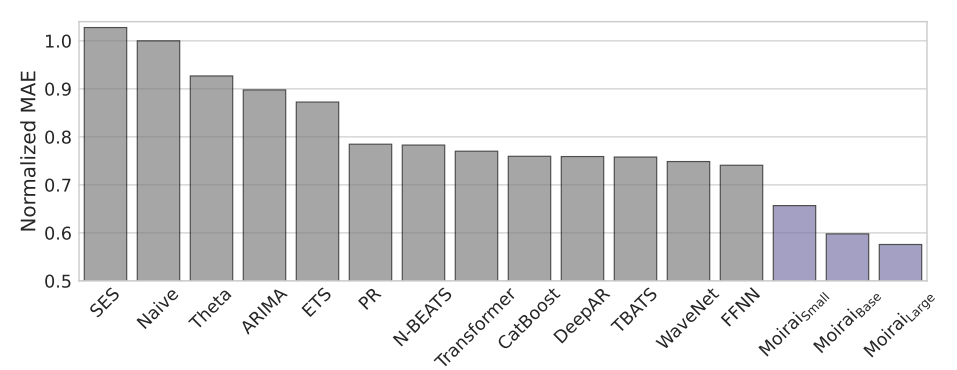
图2 Monash时间序列预测基准的汇总结果
在 out-of-distribution/zero-shot 预测评估中,MOIRAI 始终表现出有竞争力的性能,在一些实例中超过了当下最好的 full-shot 的模型性能。
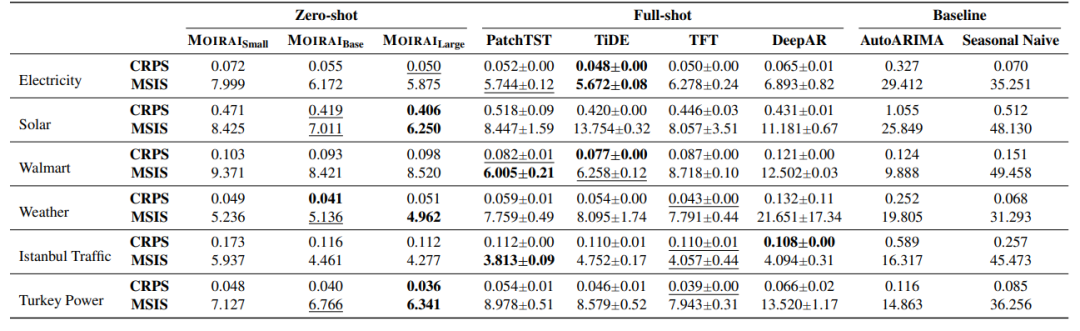
表2 概率预测结果
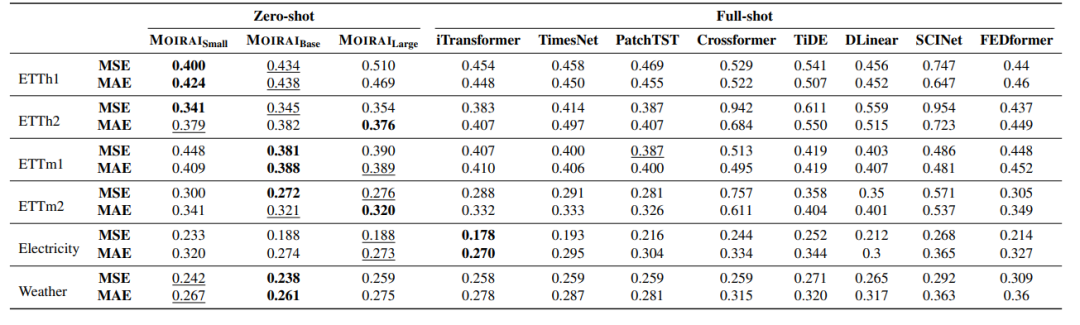
表3 长序列预测结果
总结
MOIRAI 作为一种基于掩码编码器的通用时间序列预测 Transformer,它一定程度上缓解了通用预测范式中面临的问题。通过利用大规模数据预训练的力量,这个时间序列基础模型彻底改变了以往每个数据集一个模型的格局。它为下游预测任务中的用户提供了巨大的优势,消除了使用深度学习模型实现准确预测所需的额外数据、大量计算资源的需求。
尽管 MOIRAI 在分布内和分布外性能上取得了显著成果,但这只是通用预测范式中的第一步。由于资源限制,研究者几乎没有进行超参数调整——可以应用如
等高效的调整技术。目前,研究者们开源了预训练数据,预训练代码以及模型权重为这一新兴研究领域的发展铺平了道路。