ECCV 2024 Workshop | 一文了解多元化议题、前沿技术与全球研究动向
ECCV 2024 Workshop | 一文了解多元化议题、前沿技术与全球研究动向

关注公众号,发现CV技术之美

欧洲计算机视觉会议(ECCV)是由欧洲计算机视觉协会(ECVA)主办的双年度顶级计算机视觉和机器学习研究会议。该会议汇集了这一领域的科学和工业界的专业人士。每两年举办一次,今年的会议定于 9 月 29日(星期日)至 10 月 4 日(星期五)在米兰 MiCo 举行。
既CVPR 2024 Workshop(上)和CVPR 2024 Workshop(下)后,本文继续梳理 ECCV 2024 Workshop 研究方向。此外,征稿截止日期大多集中在7月和8月,感兴趣的伙伴们可以密切关注投稿信息!
1.3D Vision
https://3dv-in-ecommerce.github.io/
- 项目主页:https://3dv-in-ecommerce.github.io/
研讨会聚焦于三维计算机视觉和图形的研究,重点关注以下主题:
- 3D电子商务中的3D物体/场景建模与理解,如语义分割、可供性和运动、多视角重建;
- 3D电子商务中的人体建模和时尚,如虚拟试穿和个性化时尚推荐;
- 语言辅助推理,如从文本中合成形状/场景和3D模型的语言基础。
是否征稿:否
Dense Neural SLAM Workshop (NeuSLAM)
- 项目主页:https://sites.google.com/view/neuslam
研讨会聚焦于密集神经 SLAM 领域所面临的挑战和机遇,探讨相关技术和应用问题。
是否征稿:否

Half-century of Structure-from-Motion (50SfM)
- 项目主页:https://50sfm.fbk.eu/
研讨会聚焦于 Structure-from-Motion (SFM)领域所面临的挑战和机遇,探讨相关技术和应用问题。
是否征稿:否

Transparent & Reflective objects In the wild Challenges (TRICKY)
- 项目主页:https://sites.google.com/view/eccv24-tricky-workshop/
研讨会聚焦于对透明和反射物体进行分类、检测、跟踪、重建、深度和姿态估计的相关问题研究,重点讨论各种方法在自然场景布置、mix of Lambertian 和 non-Lambertian objects 或光照变化等无约束场景中的适用性。
征稿截止日期:2024 年 7 月 12 日:
Wild3D: 3D Modeling, Reconstruction, and Generation in the Wild
- 项目主页:https://3d-in-the-wild.github.io/
研讨会聚焦于在不受控制(uncontrolled)、部分观察(partially-observed)和嘈杂环境(noisy environments)中进行三维建模所面临的挑战和机遇,探讨相关技术和应用问题。
征稿截止日期:2024 年 8 月 10 日

Workshop on Spatial AI
- 项目主页:https://sites.google.com/view/spatial-ai-eccv24
研讨会聚焦于 Spatial AI 所面临的挑战和机遇,探讨相关技术和应用问题。
是否征稿:否
2.Applications
2nd Workshop on Vision-based Industrial Inspection (VISION)
- 项目主页:https://vision-based-industrial-inspection.github.io/eccv-24/
研讨会聚焦于基于视觉的工业检查领域所面临的挑战和机遇,探讨相关技术和应用问题。
是否征稿:TBD
9th Workshop on Computer Vision in Plant Phenotyping and Agriculture (CVPPA)
- 项目主页:https://cvppa2024.github.io/
研讨会聚焦于植物表型分析和农业计算机视觉领域所面临的挑战和机遇,探讨相关技术和应用问题。
征稿截止日期:2024 年 7 月 12 日
FashionAI: Exploring the intersection of Fashion and Artificial Intelligence for reshaping the Industry
- 项目主页:https://sites.google.com/view/fashionai2024
研讨会聚焦于人工智能和时尚应用领域 所面临的挑战和机遇,探讨相关技术和应用问题。
征稿截止日期:2024 年 7 月 12 日

3.Art
AI4DH: Artificial Intelligence for Digital Humanities
- 项目主页:https://sites.google.com/view/ai4dh2024
研讨会聚焦于人工智能技术在文化遗产修复应用所面临的挑战和机遇,探讨相关技术和应用问题。
征稿截止日期:2024年7月12日

AI for Visual Arts Workshop and Challenges (AI4VA)
- 项目主页:https://sites.google.com/view/ai4vaeccv2024
研讨会聚焦于计算机视觉与创意交叉领域所面临的挑战和机遇,探讨相关技术和应用问题。
是否征稿:TBD
Vision for Art (VISART) VII Workshop
- 项目主页:https://visarts.eu/
研讨会聚焦于计算机视觉和数字人文应用领域所面临的挑战和机遇,探讨相关技术和应用问题。
征稿截止日期:2024 年 7 月 3 日

4.Autonomous Driving and Robotics
ACVR2024 - 12th International Workshop on Assistive Computer Vision and Robotics
- 项目主页:https://iplab.dmi.unict.it/acvr2024/
研讨会聚焦于计算机视觉和机器人技术应用领域所面临的挑战和机遇,探讨相关技术和应用问题。
征稿全文:7月15日 摘要:8月20日
Multi-Agent Autonomous Systems Meet Foundation Models: Challenges and Futures
- 项目主页:https://coop-intelligence.github.io/
研讨会聚焦于 Cooperative Intelligence(集体智能)在自动驾驶和机器人应用领域所面临的挑战和机遇,探讨相关技术和应用问题。包括:
- 集体智能对于自动驾驶和机器人技术的价值和前景。
- 多代理自主系统集体智能的挑战和最新进展。
- 多代理自主系统的基础模型。
征稿截止日期:2024 年 7 月 25 日

Multimodal Perception and Comprehension of Corner Cases in Autonomous Driving: Towards Next-Generation Solutions
- 项目主页:https://coda-dataset.github.io/w-coda2024/
研讨会聚焦于多模态感知与理解、端到端驾驶系统以及高级 AIGC 技术在自动驾驶系统中的应用等方面的创新研究。
征稿截止日期:8 月 1 日

The Third ROAD Workshop & Challenge: Event Detection for Situation Awareness in Autonomous Driving
- 项目主页:https://sites.google.com/view/road-eccv2024/home
研讨会聚焦于自动驾驶中态势感知能力研究中所面临的挑战和机遇,探讨相关技术和应用问题。
征稿截止日期:2024 年 8 月 1 日

5.Detection, Recognition, and Low-Level Vision
5th Advances in Image Manipulation (AIM) Workshop and Challenges
- 项目主页:https://www.cvlai.net/aim/2024/
研讨会聚焦于图像处理在监控、汽车工业、电子、遥感或医学图像分析应用领域的新趋势和新进展,探讨相关技术和问题。
征稿截止日期:2024 年 7 月 24 日
Instance-Level Recognition
- 项目主页:https://ilr-workshop.github.io/ECCVW2024/
研讨会聚焦于 Visual instance-level recognition and retrieval(视觉实例级识别与检索)所面临的挑战和机遇,探讨相关技术和应用问题。
是否征稿:TBD
Large-scale Video Object Segmentation
- 项目主页:https://lsvos.github.io/
研讨会聚焦于复杂环境下的 VOS 所面临的挑战和机遇,探讨相关技术和应用问题。
6.Human
7th Workshop and Competition on Affective Behavior Analysis in-the-wild
- 项目主页:https://affective-behavior-analysis-in-the-wild.github.io/7th/
研讨会聚焦于情感行为分析领域所面临的挑战和机遇,探讨相关技术和应用问题。征集人脸、肢体、手势、语音、音频、文本和语言的识别、分析、生成-合成和建模方面的最新进展论文,以及用于此类自然环境(即在无限制环境中)分析和跨模态(如从人脸到语音)分析的最先进论文。
征稿截止日期:7 月 29 日

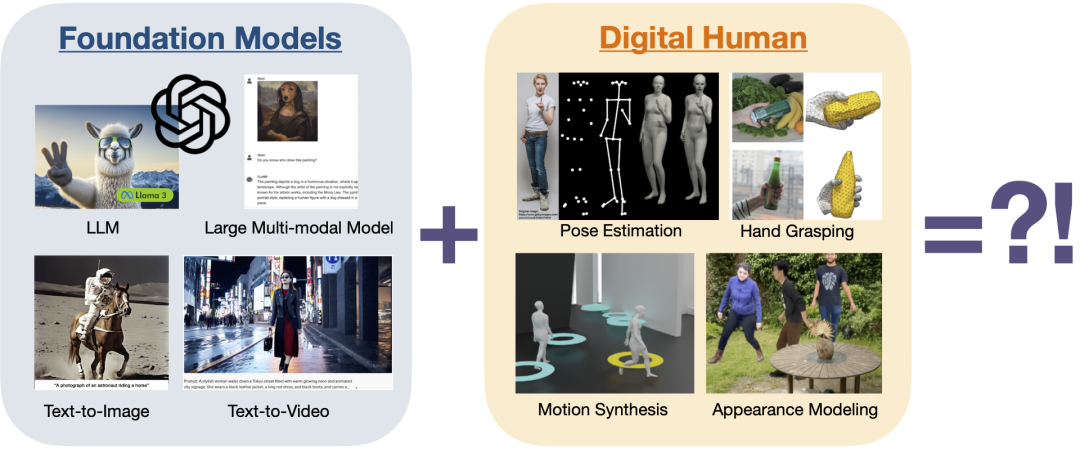
Foundation Models for 3D Humans
- 项目主页:https://human-foundation.github.io/workshop-eccv-2024/
研讨会聚焦于三维数字人建模与基础模型之间所面临的挑战和机遇,探讨相关技术和应用问题。重点探讨以下两个关键问题:
- 基础模型如何帮助研究数字人类;
- 如何建立数字人类的基础模型。
是否征稿:TBD
Observing and Understanding Hands in Action
- 项目主页:https://hands-workshop.org/
研讨会聚焦于手部动作感知领域,包括二维和三维手部检测、分割、姿势/形状估计、跟踪,以及二维和三维手部检测、分割、姿势/形状估计、跟踪研究中所面临的挑战和机遇,探讨相关技术和应用问题。
征稿详情:TBD

T-CAP - Towards a Complete Analysis of People: Fine-grained Understanding for Real-World Applications
- 项目主页:https://sites.google.com/view/t-cap-2024/home
研讨会聚焦于人体分析在现实世界中应用所面临的挑战和机遇,探讨相关技术和应用问题。
征稿截止日期:2024 年 7 月 12 日
The First Workshop on Expressive Encounters: Co-speech gestures across cultures in the wild
- 项目主页:https://expressive-encounters-workshop.github.io/2024/
研讨会聚焦于 virtual embodied agents 和机器人在现实应用中所面临的挑战和机遇,探讨相关技术和应用问题。
征稿截止日期:2024 年 7 月 19 日

Workshop on Artificial Social Intelligence
- 项目主页:https://sites.google.com/andrew.cmu.edu/asi-eccv-2024
研讨会聚焦于 artificial social intelligence 应用中所面临的挑战和机遇,探讨相关技术和应用问题。
是否征稿:否
7.Medical and Bio-Inspired Vision
BioImage Computing (BIC)
- 项目主页:https://www.bioimagecomputing.com/
研讨会聚焦于生物图像计算领域所面临的挑战和机遇,探讨相关技术和应用问题。
征稿截止日期:TBD
Human-inspired Computer Vision
- 项目主页:https://sites.google.com/view/hcvworkshop2024
研讨会聚焦于 Computational Vision、Biological Vision、Cognitive Aspects 领域所面临的挑战和机遇,探讨相关技术和应用问题。
征稿截止日期:2024 年 7 月 19 日
8.ML
2nd Workshop on More Exploration, Less Exploitation (MELEX)
- 项目主页:https://sites.google.com/view/melex2024
研讨会聚焦于计算机视觉所有领域的最新创新模型、算法和想法,探讨相关技术和应用问题。
征稿截止日期:2024 年 7 月 4 日
2nd Workshop on Quantum Computer Vision and Machine Learning (QCVML)
- 项目主页:https://qcvml.github.io/index.html
研讨会聚焦于量子计算在计算机视觉和机器学习应用领域所面临的挑战和机遇,探讨相关技术和应用问题。
征稿详情:TBD
Beyond Euclidean: Hyperbolic and Hyperspherical Learning for Computer Vision
- 项目主页:https://sites.google.com/view/beyondeuclidean/home
研讨会聚焦于 Hyperbolic and hyperspherical learning 在计算机视觉应用领域所面临的挑战和机遇,探讨相关技术和应用问题。
征稿截止日期:7 月 7 日
Emergent Visual Abilities and Limits of Foundation Models (EVAL-FoMo)
- 项目主页:https://sites.google.com/view/eval-fomo-24/home
研讨会聚焦于视觉新兴能力(和限制)研究中所面临的挑战和机遇,探讨相关技术和应用问题。
是否征稿:否
Self-Supervised Learning - What is next?
- 项目主页:https://sslwin.org/
研讨会聚焦于自监督学习的最新进展,探讨相关技术和应用问题。
是否征稿:否
Sometimes Less is More: The First Dataset Distillation Challenge
- 项目主页:https://dd-challenge-main.vercel.app/
研讨会聚焦于数据集蒸馏方法的最新进展,探讨相关技术和应用问题。
征稿截止日期:2024 年 7 月 21 日
Synthetic Data for Computer Vision
- 项目主页:https://syntheticdata4cv.wordpress.com/
研讨会聚焦于合成数据的有利影响,以及合成数据潜在滥用相关的挑战和风险。例如在安全领域,合成数据可能被用来规避生物识别系统,破坏其有效性,使未经授权的访问或欺诈活动成为可能。探索开发出检测这些数据的强大算法。
征稿截止日期:7 月 10 日
The 3rd Workshop for Out-of-Distribution Generalization in Computer Vision Foundation Models
- 项目主页:https://www.ood-cv.org/
研讨会聚焦于计算机视觉中的分布外泛化研究中所面临的挑战和机遇,探讨相关技术和应用问题。
征稿截止日期:2024 年 8 月 10 日

Traditional Computer Vision in the Age of Deep Learning (TradiCV)
- 项目主页:https://sites.google.com/view/tradicv
研讨会聚焦于解决计算机视觉问题的算法和方法论,采用“传统”或“经典”的方式,即部署分析/显式模型,而不是学习/神经模型。
征稿详情:TBD
Uncertainty Quantification for Computer Vision
- 项目主页:https://uncertainty-cv.github.io/2024/
研讨会聚焦于计算机视觉不确定性量化方法和应用的最新进展,探讨相关技术和应用问题。
征稿截止日期:2024 年 7 月 10 日
Workshop on Unlearning and Model Editing (U&ME'24)
- 项目主页:https://sites.google.com/view/u-and-me-workshop
研讨会聚焦于模型编辑(包括模型压缩)技术的最新进展,探讨相关技术和应用问题。
征稿截止日期:2024 年 7 月 10 日
Workshop on Visual Concepts
- 项目主页:https://sites.google.com/cs.stanford.edu/visualconcepts
研讨会聚焦于概念学习和推理应用中所遇到的机遇和挑战,探讨相关技术和应用问题。
是否征稿:否
9.Multimodal
2nd OmniLabel Workshop: Enabling Complex Perception Through Vision and Language Foundational Models
- 项目主页:https://sites.google.com/view/omnilabel-workshop-eccv24/overview
研讨会聚焦于视觉感知系统的研究,探讨相关技术和应用问题。
是否征稿:否
AVGenL: Audio-Visual Generation and Learning
- 项目主页:https://sites.google.com/view/avgenl
研讨会聚焦于视听生成和学习领域的最新发展、挑战和突破,探讨相关技术和应用问题。
征稿截止日期:2024 年 7 月 28 日

International Challenge on Compositional and Multimodal Perception
- 项目主页:https://campworkshop.org/
研讨会聚焦于合成和多模式感知的研究,探讨相关技术和应用问题。
是否征稿:否
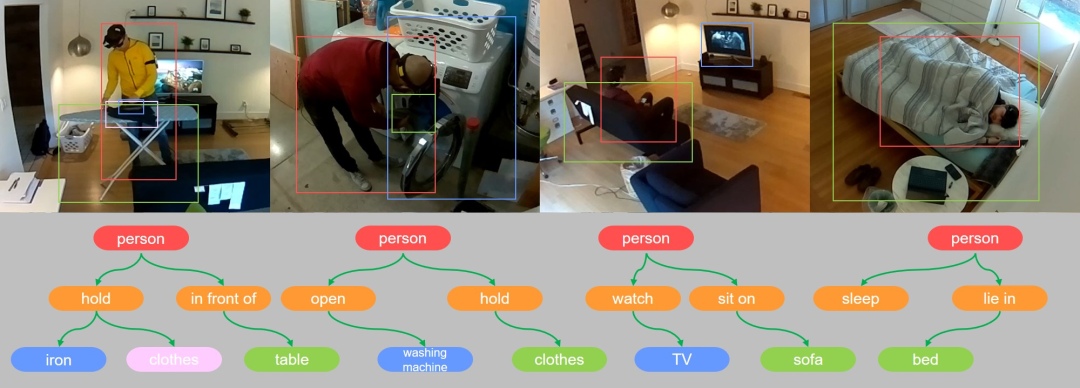
10.Scene Understanding
Map-free Visual Relocalization
- 项目主页:https://nianticlabs.github.io/map-free-workshop/2024/
研讨会聚焦于 Map-free Visual Relocalization(无地图视觉定位)的研究,探讨相关技术和应用问题。
是否征稿:否
Scalable 3D Scene Generation and 3D Geometric Scene Understanding
- 项目主页:https://s3dsgr.github.io/
研讨会聚焦于三维场景生成与几何场景理解的研究,探讨相关技术和应用问题。
征稿截止日期:2024 年 7 月 7 日
11.Sensing Devices
1st Workshop on Neural Fields Beyond Conventional Cameras
- 项目主页:https://neural-fields-beyond-cams.github.io/
研讨会聚焦于传统相机之外的神经场,例如
- 从不同传感器的数据中学习神经场,包括激光雷达、低温电子显微镜(cryoEM)、热成像、事件相机、声学等;
- 建立相关的基于物理学的可微分前向模型和/或更复杂的光传输物理学模型(反射、阴影、偏振、衍射极限、光学、雾或水中的散射等)。
探讨相关技术和应用问题。
征稿截止日期:7 月 19 日
Eyes of the Future: Integrating Computer Vision in Smart Eyewear
- 项目主页:https://sites.google.com/view/icvse-eccv2024
研讨会聚焦于智能眼镜技术的最新进展,探讨相关技术和应用问题。
征稿截止日期:7月1日

GigaVision: When Gigapixel Videography Meets Computer Vision
- 项目主页:https://gigavision.cn/data/news/?nav=ECCV%202024%20Workshop&type=nav&t=1715068056315
研讨会聚焦于三维视觉与计算摄影之间的联系,探讨三维重建、渲染和理解的机遇与挑战。
是否征稿:否
Workshop on Neuromorphic Vision (NeVi): Advantages and Applications of Event Cameras
- 项目主页:https://sites.google.com/view/nevi2024
研讨会聚焦于事件相机的最新发展、挑战和突破,探讨相关技术和应用问题。
是否征稿:否
12.RAI
2nd International Workshop on Privacy-Preserving Computer Vision
- 项目主页:https://privacy-preserving-computer-vision.github.io/eccv24.html
研讨会聚焦于视觉和成像领域的分布式机器学习和隐私保护机器学习的最新进展,致力于改善计算机视觉领域的隐私保护状况。
是否征稿:否
Critical Evaluation of Generative Models and their Impact on Society
- 项目主页:https://sites.google.com/view/cegis-workshop
研讨会聚焦于视觉生成模型的最新进展,力求解决与视觉生成模型及其评估、基准设定和审核相关的复杂挑战。
征稿截止日期:2024 年 7 月 15 日
Explainable AI for Computer Vision: Where Are We and Where Are We Going?
- 项目主页:https://excv-workshop.github.io/
研讨会聚焦于可解释AI在计算机视觉领域的应用,重点探讨:
- 讨论和传播 XAI 研究前沿的观点("Where are we?)
- 对社区面临的挑战和前进方向进行批判性反思("Where are we going?)
征稿详情:TBD
Fairness and ethics towards transparent AI: facing the chalLEnge through model Debiasing (FAILED)
- 项目主页:https://failed-workshop-eccv-2024.github.io/
研讨会聚焦于人工智能系统(尤其是计算机视觉领域)中纠正偏见、促进公平和透明的创新策略,跨学科讨论和分享前沿解决方案。
征稿截止日期:TBD

FOundation models Creators meet USers (FOCUS)
- 项目主页:https://focus-workshop.github.io/
研讨会聚焦于基础模型的最新进展,确定和讨论在开发和使用基础模型的最新进展过程中评估积极和消极(可能出乎意料)行为的策略。
征稿截止日期:TBD
The Dark Side of Generative AIs and Beyond
- 项目主页:https://sites.google.com/view/darksideofgenaiandbeyond
研讨会聚焦于生成式人工智能带来的挑战,如伦理影响、虚假信息、法律方面、模型崩溃、补救措施等,从各个方面揭示生成式人工智能所产生的负面影响。
征稿详情:TBD
Trustworthy in Multi-modal Foundation Models and AI Agents (TiFA)
- 项目主页:https://eccv-tifa.github.io/
研讨会聚焦于多模式基础模型和代理(TiFA)在各个领域应用中所面临的挑战和机遇,探讨相关技术和应用问题。
征稿截止日期:2024 年 8 月 25 日
TWYN: Trust What You learN. 1st Workshop on Trustworthiness in Computer Vision
- 项目主页:https://twyn.unimore.it/
研讨会聚焦于 Trustworthy AI 和 DeepFake Analysis,深入探讨构建人工智能系统的多层面问题。两大主题:
- From Learning to Unlearning: The Role of Privacy in Computer Vision
- DeepFake Analysis and Detection
征稿截止日期:2024 年 7 月 10 日
Women in Computer Vision
- 项目主页:https://sites.google.com/view/wicveccv2024/home
研讨会聚焦于来自世界各地的女性专家和学者,分享她们在计算机视觉领域的研究经验和成果,并就计算机视觉领域中女性面临的挑战和机遇展开讨论。
是否征稿:否

image
Workshop on Green Foundation Models
- 项目主页:https://green-fomo.github.io/ECCV2024/index.html
研讨会聚焦于基础模型的最新进展,探讨 FOMOs 应用于生物多样性、农业、食品安全等具有绿色影响的领域的可能性。
征稿截止日期:2024 年 7 月 12 日

xAI4Biometrics at ECCV 2024 - 4th Workshop on Explainable & Interpretable Artificial Intelligence for Biometrics
- 项目主页:https://vcmi.inesctec.pt/xai4biom_eccv2024/index.html
研讨会聚焦于可解释和可解释人工智能的研究,以推动人工智能/机器学习在生物识别领域的应用。重点讨论:
- 解释生物识别模型的方法,以验证其决定并改进模型和检测可能的漏洞;
- 客观评估和比较自动决定的不同解释的定量方法;
- 生成更好解释的方法;
- 更透明的算法。
征稿截止日期:2024 年 7 月 19 日
