【LangChain系列】第四节:向量数据库与嵌入
原创【LangChain系列】第四节:向量数据库与嵌入
原创
toc
在这篇博文中,我们将探讨向量存储和嵌入,它们是构建聊天机器人和对数据语料库执行语义搜索的最重要组件。
一、工作流
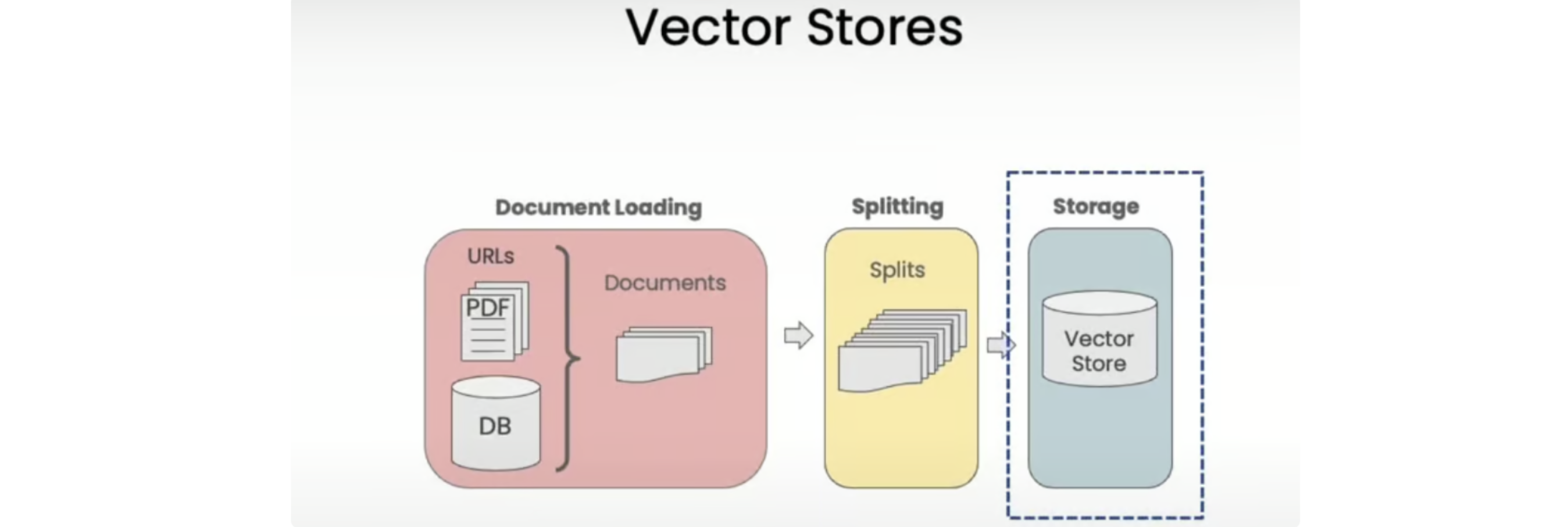
回想一下检索增强生成 (RAG) 的整个工作流程:

我们从文档开始,创建这些文档的较小拆分,为这些拆分生成嵌入,然后将它们存储在矢量存储中。向量存储是一个数据库,您可以在以后轻松查找类似的向量。
二、安装
设置适当的环境变量并加载我们将要处理的文档 - cs229_lectures:
import os
from langchain_openai import OpenAI
from dotenv import load_dotenv, find_dotenv
from langchain_community.document_loaders.pdf import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
_ = load_dotenv(find_dotenv())
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY")
)
loaders = [
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"), # Duplicate documents on purpose - messy data
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"),
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture02.pdf"),
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture03.pdf"),
]
docs = []
for loader in loaders:
docs.extend(loader.load())
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=150)
splits = text_splitter.split_documents(docs)
print("Length of splits: ", len(splits)) # Length of splits: 209三、嵌入
现在,我们已经将文档拆分为更小的、语义上有意义的块,是时候为它们创建嵌入了。嵌入获取一段文本并创建该文本的数字表示,以便具有相似内容的文本在此数字空间中具有相似的向量。这使我们能够比较这些向量并找到相似的文本片段。
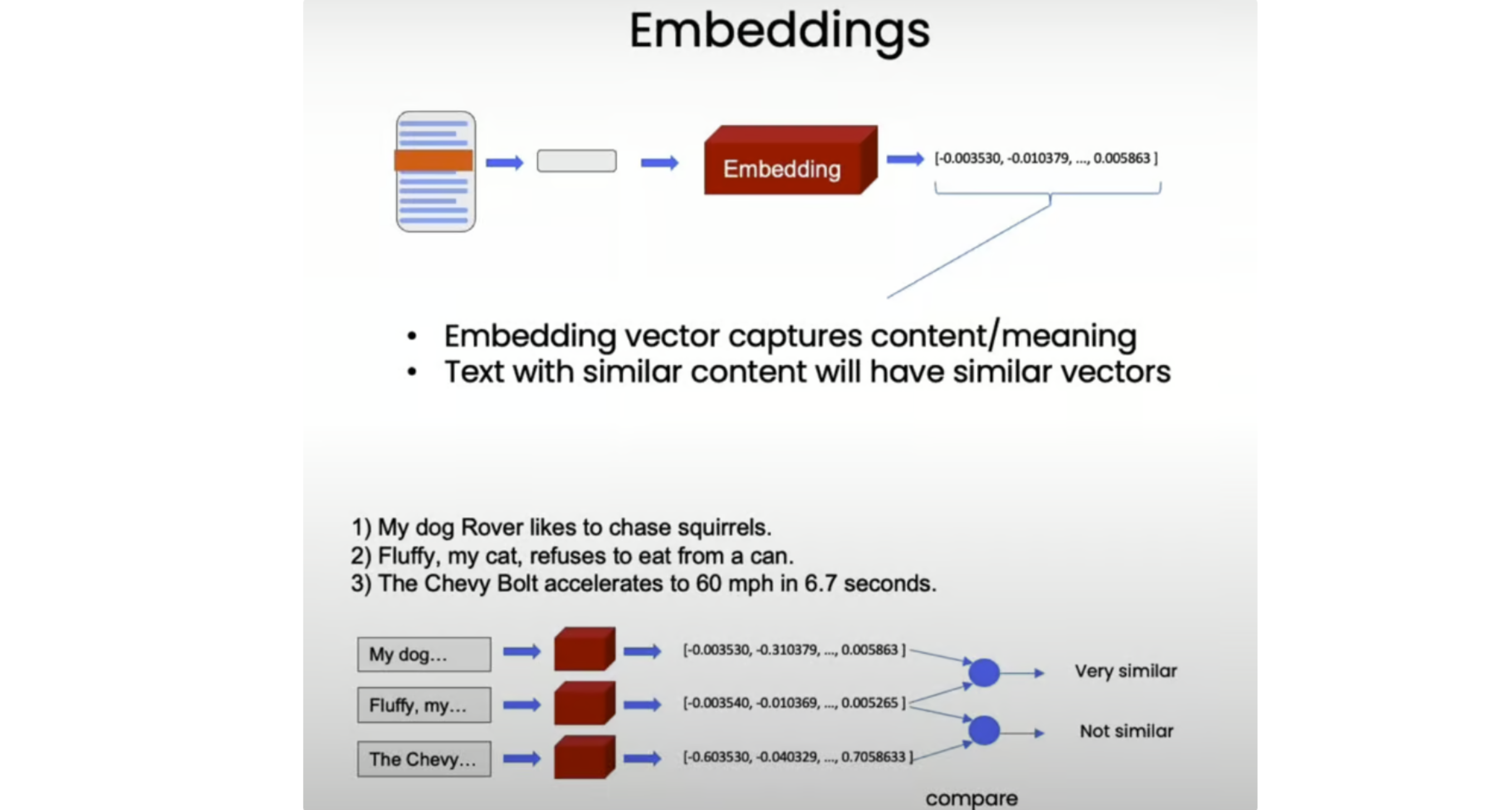
为了说明这一点,让我们尝试一些玩具示例:
from langchain_openai import OpenAIEmbeddings
import numpy as np
embedding = OpenAIEmbeddings()
sentence1 = "i like dogs"
sentence2 = "i like canines"
sentence3 = "the weather is ugly outside"
embedding1 = embedding.embed_query(sentence1)
embedding2 = embedding.embed_query(sentence2)
embedding3 = embedding.embed_query(sentence3)
print(np.dot(embedding1, embedding2)) # 0.9631227500523609
print(np.dot(embedding1, embedding3)) # 0.7703257495981695
print(np.dot(embedding2, embedding3)) # 0.7591627401108028不出所料,关于宠物的前两句话有非常相似的嵌入(点积为 0.96),而关于天气的句子与两个与宠物相关的句子不太相似(点积为 0.77 和 0.76)。
四、向量存储
接下来,我们将这些嵌入存储在向量存储中,这将使我们能够在以后尝试查找给定问题的相关文档时轻松查找类似的向量。
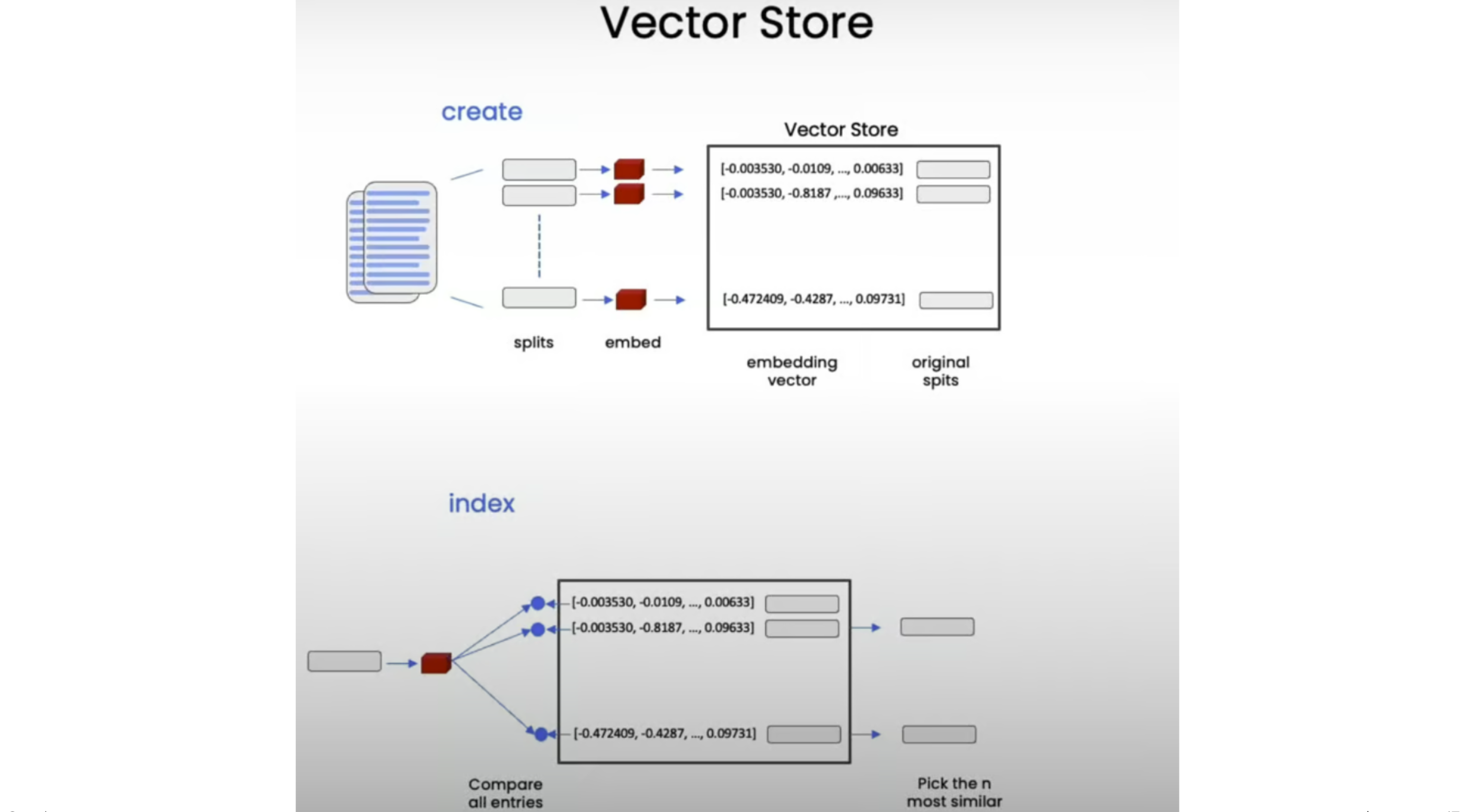
在本课中,我们将使用 Chroma 矢量存储,因为它是轻量级的,并且在内存中,因此很容易上手:
from langchain.vectorstores import Chroma
persist_directory = "docs/chroma/"
# this code is only for ipynb files
# !rm -rf ./docs/chroma # remove old database files if any
vectordb = Chroma.from_documents(
documents=splits, embedding=embedding, persist_directory=persist_directory
)
print(vectordb._collection.count()) # 209五、相似性检索
相似性搜索是如何工作的:
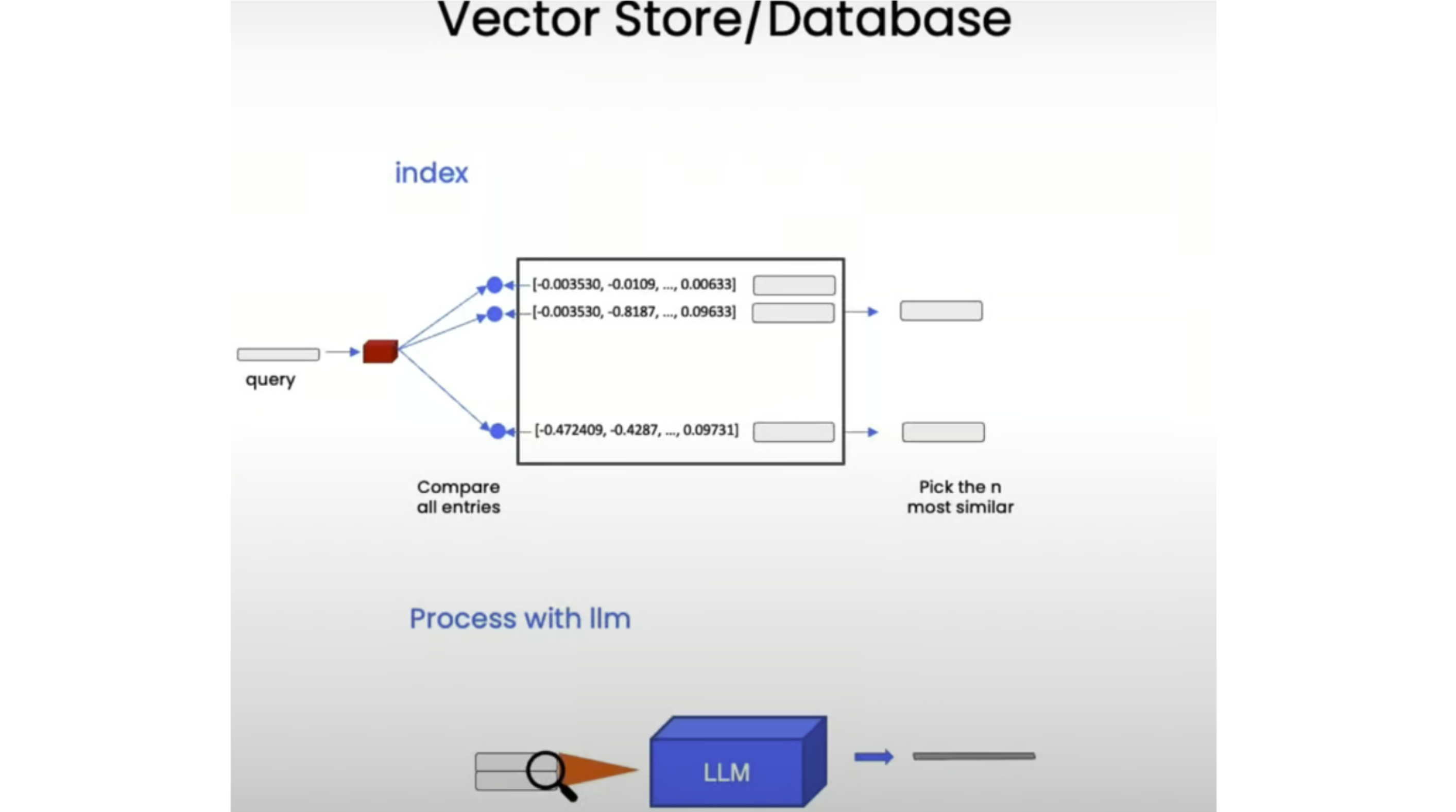
question = "is there an email i can ask for help"
docs = vectordb.similarity_search(question, k=3)
print("Length of context docs: ", len(docs)) # 3
print(docs[0].page_content)cs229-qa@cs.stanford.edu. This goes to an acc ount that's read by all the TAs and me. So
rather than sending us email individually, if you send email to this account, it will
actually let us get back to you maximally quickly with answers to your questions.
If you're asking questions about homework probl ems, please say in the subject line which
assignment and which question the email refers to, since that will also help us to route
your question to the appropriate TA or to me appropriately and get the response back to
you quickly.
Let's see. Skipping ahead — let's see — for homework, one midterm, one open and term
project. Notice on the honor code. So one thi ng that I think will help you to succeed and
do well in this class and even help you to enjoy this cla ss more is if you form a study
group.
So start looking around where you' re sitting now or at the end of class today, mingle a
little bit and get to know your classmates. I strongly encourage you to form study groups
and sort of have a group of people to study with and have a group of your fellow students
to talk over these concepts with. You can also post on the class news group if you want to
use that to try to form a study group.
But some of the problems sets in this cla ss are reasonably difficult. People that have
taken the class before may tell you they were very difficult. And just I bet it would be
more fun for you, and you'd probably have a be tter learning experience if you form a这将返回提及 cs229-qa@cs.stanford.edu 电子邮件地址的相关块,用于询问有关课程材料的问题。
在此之后,让我们保留向量数据库以备将来使用:
vectordb.persist()六、故障模式
虽然基本的语义搜索效果很好,但可能会出现一些边缘情况和故障模式。让我们来探讨其中的一些。
1.重复文档
question = "what did they say about matlab?"
docs = vectordb.similarity_search(question, k=5)
print(docs[0].page_content)
# Document(page_content='those homeworks will be done in either MATLA B or in Octave, which is sort of — I \nknow some people call it a free ve rsion of MATLAB, which it sort of is, sort of isn\'t. \nSo I guess for those of you that haven\'t s een MATLAB before, and I know most of you \nhave, MATLAB is I guess part of the programming language that makes it very easy to write codes using matrices, to write code for numerical routines, to move data around, to \nplot data. And it\'s sort of an extremely easy to learn tool to use for implementing a lot of \nlearning algorithms. \nAnd in case some of you want to work on your own home computer or something if you \ndon\'t have a MATLAB license, for the purposes of this class, there\'s also — [inaudible] \nwrite that down [inaudible] MATLAB — there\' s also a software package called Octave \nthat you can download for free off the Internet. And it has somewhat fewer features than MATLAB, but it\'s free, and for the purposes of this class, it will work for just about \neverything. \nSo actually I, well, so yeah, just a side comment for those of you that haven\'t seen \nMATLAB before I guess, once a colleague of mine at a different university, not at \nStanford, actually teaches another machine l earning course. He\'s taught it for many years. \nSo one day, he was in his office, and an old student of his from, lik e, ten years ago came \ninto his office and he said, "Oh, professo r, professor, thank you so much for your', metadata={'page': 8, 'source': 'docs/cs229_lectures/MachineLearning-Lecture01.pdf'})
print(docs[1].page_content)
# Document(page_content='those homeworks will be done in either MATLA B or in Octave, which is sort of — I \nknow some people call it a free ve rsion of MATLAB, which it sort of is, sort of isn\'t. \nSo I guess for those of you that haven\'t s een MATLAB before, and I know most of you \nhave, MATLAB is I guess part of the programming language that makes it very easy to write codes using matrices, to write code for numerical routines, to move data around, to \nplot data. And it\'s sort of an extremely easy to learn tool to use for implementing a lot of \nlearning algorithms. \nAnd in case some of you want to work on your own home computer or something if you \ndon\'t have a MATLAB license, for the purposes of this class, there\'s also — [inaudible] \nwrite that down [inaudible] MATLAB — there\' s also a software package called Octave \nthat you can download for free off the Internet. And it has somewhat fewer features than MATLAB, but it\'s free, and for the purposes of this class, it will work for just about \neverything. \nSo actually I, well, so yeah, just a side comment for those of you that haven\'t seen \nMATLAB before I guess, once a colleague of mine at a different university, not at \nStanford, actually teaches another machine l earning course. He\'s taught it for many years. \nSo one day, he was in his office, and an old student of his from, lik e, ten years ago came \ninto his office and he said, "Oh, professo r, professor, thank you so much for your', metadata={'page': 8, 'source': 'docs/cs229_lectures/MachineLearning-Lecture01.pdf'})注意,前两个结果是相同的。这是因为我们之前有意复制了第一讲的 PDF,导致相同的信息出现在两个不同的块中。理想情况下,我们希望检索不同的块。
2.未捕获结构化信息
question = "what did they say about regression in the third lecture?"
docs = vectordb.similarity_search(question, k=5)
for doc in docs:
print(doc.metadata)
# {'page': 0, 'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf'}
# {'page': 14, 'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf'}
# {'page': 0, 'source': 'docs/cs229_lectures/MachineLearning-Lecture02.pdf'}
# {'page': 6, 'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf'}
# {'page': 8, 'source': 'docs/cs229_lectures/MachineLearning-Lecture01.pdf'}
print(docs[4].page_content)into his office and he said, "Oh, professo r, professor, thank you so much for your
machine learning class. I learned so much from it. There's this stuff that I learned in your
class, and I now use every day. And it's help ed me make lots of money, and here's a
picture of my big house."
So my friend was very excited. He said, "W ow. That's great. I'm glad to hear this
machine learning stuff was actually useful. So what was it that you learned? Was it
logistic regression? Was it the PCA? Was it the data ne tworks? What was it that you
learned that was so helpful?" And the student said, "Oh, it was the MATLAB."
So for those of you that don't know MATLAB yet, I hope you do learn it. It's not hard,
and we'll actually have a short MATLAB tutori al in one of the discussion sections for
those of you that don't know it.
Okay. The very last piece of logistical th ing is the discussion s ections. So discussion
sections will be taught by the TAs, and atte ndance at discussion sections is optional,
although they'll also be recorded and televi sed. And we'll use the discussion sections
mainly for two things. For the next two or th ree weeks, we'll use the discussion sections
to go over the prerequisites to this class or if some of you haven't seen probability or
statistics for a while or maybe algebra, we'll go over those in the discussion sections as a
refresher for those of you that want one.在这种情况下,我们期望所有检索到的文件都来自问题中指定的第三讲。但是,我们看到结果也包括来自其他讲座的块。这里的直觉是,关于仅查询第三讲的结构化信息并未在语义嵌入中捕获,语义嵌入更侧重于回归本身的概念。
小节
在这篇博文中,我们介绍了使用向量存储和嵌入进行语义搜索的基础知识,以及可能出现的一些边缘情况和故障模式。在下一篇博客中,我们将讨论如何解决这些故障模式并增强我们的检索能力,确保我们检索相关和不同的块,同时将结构化信息合并到搜索过程中。
小编是一名热爱人工智能的专栏作者,致力于分享人工智能领域的最新知识、技术和趋势。这里,你将能够了解到人工智能的最新应用和创新,探讨人工智能对未来社会的影响,以及探索人工智能背后的科学原理和技术实现。欢迎大家点赞,评论,收藏,让我们一起探索人工智能的奥秘,共同见证科技的进步!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。