基于深度强化学习的无人车自适应速度规划
原创基于深度强化学习的无人车自适应速度规划
原创
论文:Adaptive speed planning for Unmanned Vehicle Based on Deep Reinforcement Learning
编辑:东岸因为@一点人工一点智能
01 简要
在未来技术的发展中,在线路径规划对于无人车辆尤其关键,尤其是在复杂的城市交通网络中。近年来,深度强化学习(DRL)已成为解决此类问题的前沿技术。
本文对无人车辆的速度规划部分进行了一些改进。首先,将车辆速度与车辆与障碍物之间的角度耦合,并将这种耦合关系整合到奖励函数中。其次,使用DDQN算法替换无人车辆的局部路径规划模块;最后,在Gazebo仿真环境中完成了不同环境下的车辆速度规划测试。
02 模型构建
2.1 DQN算法
深度Q网络(DQN)结合了Q-Learning原则和深度神经网络,以处理具有高维状态空间的环境。DQN算法通过使用深度神经网络来近似最优动作价值函数,从而在各种状态下做出明智的决策,这标志着强化学习领域的重大突破。
DQN算法的核心是动作价值函数的更新规则,该规则通过Q-Learning更新和梯度下降优化迭代改进策略。DQN算法利用Q-Learning框架推导出一个可优化的损失函数,用于训练神经网络。该更新方程定义如下(1):
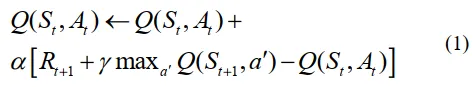
训练过程涉及减少预测和目标Q值之间的差异的损失函数。根据方程(1),DQN算法的损失函数表示如下(2):
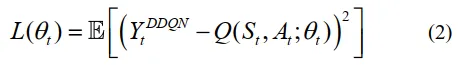
目标Q值代表预期的未来奖励,通过折扣因子\gamma进行折扣,对于学习过程的稳定性至关重要:
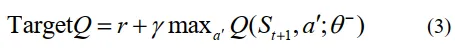
DQN算法采用一个单独的目标网络来稳定学习更新。目标网络的参数定期从主网络(θ)更新,以防止目标值的快速变化,这可能导致学习过程不稳定。
2.2 DDQN算法
双重深度Q网络(DDQN)通过解决DQN中Q值高估的问题,增强了原始DQN。DQN和DDQN都使用深度神经网络来近似Q值函数,在高维状态空间的环境中进行动作选择,这是强化学习领域的一个重要进步。
DDQN算法的关键创新在于将动作选择过程与Q值评估过程分离。通过这一微妙的改变,DDQN减少了在DQN中可能出现的高估值估计,从而产生更稳定和可靠的学习,并防止代理在策略开发过程中过高估计动作的价值。这反过来通常会导致在强化学习各种基准任务中取得更好的性能。
2.3 改进的奖励函数
在一些现有的强化学习算法中,奖励函数的设置简单,这会导致移动机器人过于关注避障,在进行转向控制和速度控制时,即使车辆与障碍物的偏差很大,性能也会大幅降低。速度是为了确保避障,在规划过程中不够灵活。类似的奖励函数如方程(4)所示:

因此,提出了一种基于动态奖励函数的改进算法,以防止移动机器人在驾驶时因接近障碍物而降低速度。本文将车辆速度与航向角的关系应用于奖励函数的设置,并通过选择不同的动作获得不同的奖励值,如方程(5)所示:
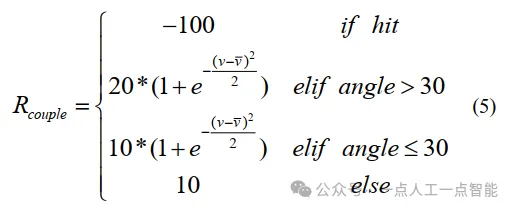
式中,v表示车辆的当前速度,\bar{v}表示期望的车辆速度。
如图1所示,角度是根据自动驾驶车辆当前的行驶方向和障碍物的边缘位置确定的。这样可以确保在行驶过程中,车辆的速度规划不会受到车辆位置因素的干扰。如果车辆当前的行驶方向与障碍物一致,且距离较远,即使车辆靠近障碍物,也应保持正常速度而不会减速。当障碍物位于车辆的行驶路径上时,应适当减速以保持安全。
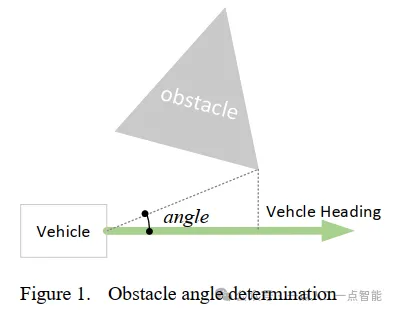
通过在奖励函数中加入高斯函数,可以根据车辆的实时状态动态改变奖励值。如果车辆当前的航向角与障碍物角度之间的偏差大于30度,此时应保持正常车速。
当车辆的航向角与障碍物的角度小于30度时,对于静态障碍物不应减速,只需以恒定速度通过。通过将无人车的奖励与无人车的当前速度耦合,在以安全角度通过障碍物时,无人车仍能保持适当的速度。
03 实验
所有实验均在装备有Intel(R)Core(TM)i7-7700HQ CPU@2.80GHz和NVIDIA GeForceGTX1080GPU的计算机上进行。所有实验基于ubuntu20.04操作系统和ROS,并在Gazebo中进行物理模拟。
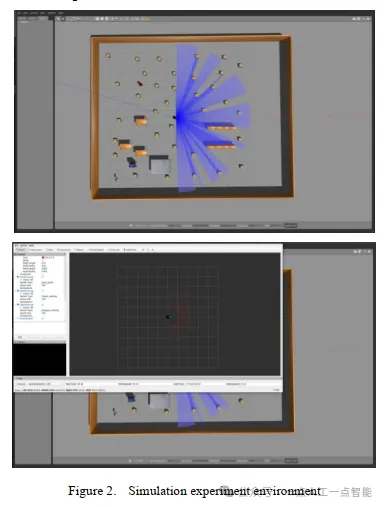
实验环境如图2所示。我们在一个10✖15米的封闭空间中放置了许多障碍物来训练DDQN。
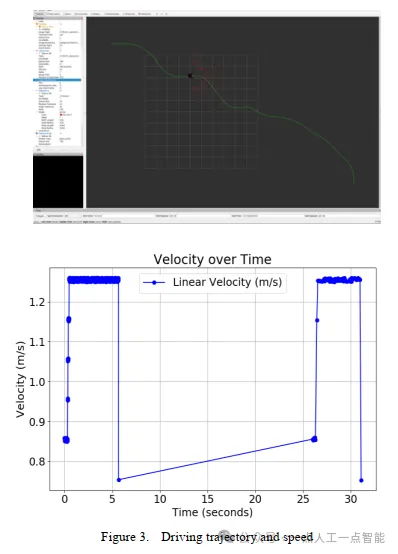
图3显示了模拟环境中单一规划的效果。如图所示,尽管环境中有很多障碍物,但无人车的平均速度仍能达到1.0以上。这种算法在障碍物多的环境中可以取得较好的结果。

表1显示了不同环境下不同奖励函数的平均行驶速度。我们在每个环境中进行了20次实验。可以看出,无论是10米✖15米环境还是25米✖25米环境,具有耦合关系的奖励函数在速度规划方面表现良好。我们设定的期望速度为1.2米/秒。从表中可以看出,普通奖励函数生成的速度规划的平均速度较低,而本文提出的具有耦合关系的奖励函数可以在不影响规划成功率的情况下使速度达到预期值。
04 结论
本文主要研究了通过将奖励函数与车速相互耦合来改进车辆速度控制。本文表明,使用DDQN模型和改进的奖励函数可以提高自动驾驶车辆的速度规划。通过更新系统对障碍物的响应方式,车辆能够在不必要减速的情况下保持稳定的速度。最后,通过Gazebo环境的模拟实验验证了该算法。
结果表明,改进的奖励函数可以根据局部环境和障碍物数量进行相应的速度规划,并在满足条件的情况下规划出符合速度要求的行驶速度。在模拟测试中确认了这些方法在各种障碍物环境中的良好效果。本文对奖励函数的改进可以使无人车在现实世界中更加可靠和高效。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。