【论文合集】- 存内计算加速机器学习
原创【论文合集】- 存内计算加速机器学习
原创
本章节论文合集,存内计算已经成为继冯.诺伊曼传统架构后,对机器学习推理加速的有效解决方案,四篇论文从存内计算用于机器学习,模拟存内计算,对CNN/Transformer架构加速角度阐述存内计算。
【1】WWW: What, When, Where to Compute-in-Memory
简介:本文探讨了在机器学习推理加速中整合Compute-in-memory(CiM)的问题,CiM已经成为缓解冯诺依曼机器高数据移动成本的一个有效解决方案。CiM可以在内存中执行大规模并行的通用矩阵乘法(GEMM)操作,这是机器学习推理中的主要计算。然而,将内存重新用于计算会带来关键问题:1)使用何种类型的CiM:考虑到众多模拟和数字CiM,需要从系统角度确定它们的适用性;2)何时使用CiM:机器学习推理包括具有各种内存和计算要求的工作负载,难以确定何时CiM比标准处理器更有利;3)在何处整合CiM:每个内存级别具有不同的带宽和容量,这会影响CiM整合的数据移动和局部性优势。本文使用Timeloop-Accelergy对CiM原型进行了早期系统级评估,包括模拟和数字基元。我们将CiM整合到不同的缓存内存级别中,在类似Nvidia A100的基线架构中为各种机器学习工作负载量身定制数据流。我们的实验表明,CiM架构可以提高能效,使用INT-8精度能够实现高达0.12倍的能量降低,使用权重交错和复制可以获得高达4倍的性能提升。本文提供了关于使用何种类型的CiM,何时和在何处最优地将其整合到缓存层次结构中以加速GEMM的见解。

论文链接:https://arxiv.org/abs/2312.15896v1
【2】AiDAC: A Low-Cost In-Memory Computing Architecture with All-Analog Multi-Bit Compute and Interconnect
简介:本文介绍了一种新兴技术——模拟内存计算(Analog in-memory computing,AiMC),该技术在神经网络加速方面表现出了极高的性能优势。然而,随着计算位宽和规模的增加,高精度数据转换和远距离数据路由将导致AiMC系统不可接受的能量和延迟开销。本文重点研究了负责计算和及时互联的潜力,并展示了一种创新的AiMC架构——AiDAC,它有三个关键贡献:(1)AiDAC通过采用电容器分组技术增强了多位计算效率并减少了数据转换时间;(2)AiDAC首次采用行驱动器和列时间累加器实现了大规模AiMC阵列集成,同时最小化了数据移动的能耗;(3)AiDAC是第一项支持大规模全模拟多位向量矩阵乘法(VMM)操作的工作。评估结果显示,AiDAC在保持高精度计算(总计算误差小于0.79%)的同时,还具有出色的性能特征,如高并行性(最高可达26.2TOPS)、低延迟(<20ns/VMM)和高能量效率(123.8TOPS/W),适用于具有1024个输入通道的8位VMM。

论文链接:https://arxiv.org/abs/2312.11836v2
【3】CLSA-CIM: A Cross-Layer Scheduling Approach for Computing-in-Memory Architectures
简介:机器学习(ML)加速器的需求正在快速增长,推动了新型计算概念的发展,例如基于电阻式随机存取存储器(RRAM)的分块计算内存(CIM)架构。CIM允许在内存单元内计算,从而实现更快的数据处理和降低功耗。高效的编译器算法是利用分块CIM架构潜力的关键。虽然传统的ML编译器专注于为CPU、GPU和其他冯诺伊曼架构生成代码,但需要进行适应以覆盖CIM架构。跨层调度是一种有前途的方法,因为它增强了CIM核的利用率,从而加速计算。虽然类似的概念在以前的工作中隐含使用,但缺乏明确且可量化的算法定义,用于分块CIM架构的跨层调度。为了填补这一空白,我们提出了CLSA-CIM,这是一种用于分块CIM架构的跨层调度算法。我们将CLSA-CIM与现有的权重映射策略集成,并将其与最先进的调度算法进行性能比较。CLSA-CIM将利用率提高了高达17.9倍,从而将总体加速比提高了高达29.2倍,与SOTA相比。

论文链接:https://arxiv.org/abs/2401.07671v1
【4】Towards Joint Optimization for DNN Architecture and Configuration for Compute-In-Memory Hardware
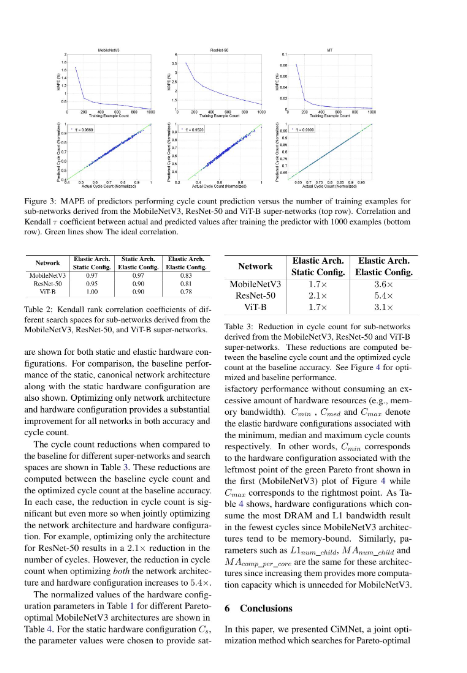
简介:随着对大规模深度神经网络需求的增长,计算内存(CiM)已成为缓解限制Von-Neuman架构的带宽和芯片内互连瓶颈的突出解决方案。然而,CiM硬件的构建面临挑战,因为任何特定的存储器层次结构,如不同接口的缓存大小和存储器带宽,可能不完全匹配于任何神经网络的属性,例如张量维度和算术强度,从而导致次优和表现不佳的系统。尽管神经结构搜索(NAS)技术在产生适用于给定硬件度量预算(例如DNN执行时间或延迟)的高效子网络方面取得了成功,但它假定硬件配置已经被冻结,往往会为给定预算产生次优的子网络。在本文中,我们提出了CiMNet,这是一个框架,它共同搜索了CiM架构的最佳子网络和硬件配置,创建了下游任务准确性和执行度量(例如延迟)的帕累托最优前沿。所提出的框架可以理解子网络性能和CiM硬件配置选择之间的复杂相互作用,包括带宽、处理单元大小和存储器大小。来自CNN和Transformer家族的不同模型架构的详尽实验证明了CiMNet在寻找协同优化的子网络和CiM硬件配置方面的有效性。具体而言,对于与基线ViT-B相似的ImageNet分类准确性,仅优化模型架构可以将性能(或减少工作负载执行时间)提高1.7倍,而同时优化模型架构和硬件配置可以将其提高3.1倍。
论文链接:https://arxiv.org/abs/2402.11780v1
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。