MMsys'24 | 基于离线强化学习的实时流媒体带宽精确预测
MMsys'24 | 基于离线强化学习的实时流媒体带宽精确预测

作者:Institute of Computing Technology, Chinese Academy of Sciences 来源:MMsys'24 论文题目:Accurate Bandwidth Prediction for Real-Time Media Streaming with Offline Reinforcement Learning 论文链接:https://dl.acm.org/doi/abs/10.1145/3625468.3652183 内容整理:王柯喻
引言
近年来,实时通信(RTC)已成为一项重要的通信技术,并得到了广泛的应用,包括低延迟直播,视频会议和云游戏。RTC 系统的首要目标是提供高质量的视频和音频并确保稳定的通信过程(例如,避免卡顿、视频模糊)。为了实现这一目标,现有的 RTC 系统(如 WebRTC)基于动态的网络条件预测链路带宽并自适应地调整传输视频质量。主流的带宽预测方法可以分为两类: 启发式算法和机器学习算法。常用的启发式带宽预测算法有 WebRTC 框架中的Google拥塞控制(GCC)。GCC主要通过监测链路的往返时间(RTT)变化来预测带宽。虽然 GCC 展示了其主动避免拥塞的高灵敏度,但现实世界RTC流的复杂性和可变性可能会干扰 GCC 的准确性。而机器学习方案包括在线强化学习与模仿学习,不仅具有很高的训练成本,同时一般基于模拟的网络环境进行训练,往往在真实世界中鲁棒性较差。因此本文提出了一类低成本,高泛化性能的离线训练模型以优化各种网络环境中的用户体验质量(QoE)。
概述
为解决之前的问题,本文提出了一种基于离线(数据驱动)强化学习(RL)技术的RTC流带宽预测方法。离线 RL 利用预先收集的静态离线数据集来训练一种可以优化QoE的策略。通过这种方式,该模型可以利用任意其他专家策略的历史优秀经验,并且无需与真实的环境进行在线交互。
框架设计
数据集
训练和评估数据集是从世界各地的音频/视频点对点 Microsoft Teams通信中收集的。训练数据集中有18859个会话,评估数据集中有9405个会话,每个会话对应一个音频/视频呼叫,包含以下字段的数千个序列:(i)150维状态向量, (ii)来自6种不同专家策略的估计带宽 (iii)客观音频质量 (iv)客观视频质量。质量表示平均意见得分(MOS)∈ [0,5],得分5为最高。评估数据集还提供了每个序列的实际链路容量。本文使用大约10%的训练数据集来训练模型,所提供的训练集总共包括六种不同的行为策略。因此,为每种策略类型随机选择300个会话,总共有1800个会话组成用于训练的数据集。使用所有的评估数据集来评估模型。
状态向量(states)
一个150维状态向量包含15个与网络状况和数据包信息相关的度量,包括接收速率、延迟、数据包抖动、数据包丢失率、音频/视频数据包比例等。每个向量包含5个最近的60ms短监测间隔(MI)和5个最近的600ms长监测间隔。在传递到神经网络之前,所有输入特征都被归一化以便于模型训练。具体而言,所有特征值被限制为[-10,10]。例如,接收速率除以
。
反馈奖励(reward)
对于每个状态-动作对,数据集提供每个 MI 期间的音频质量和视频质量。将奖励函数设置为这两个质量的加权和:
是音频质量,
是视频质量,a∈ [0,2]控制这两个质量的权重(考虑到它们可能对整体质量的贡献不相等),在后续消融实验中发现 a 取1.5时,训练效果最佳.而在每个会话的开始和结束处,存在视频质量值缺失的过渡部分(即,NaN)。这是因为在这些阶段期间,链路中没有视频数据包,导致视频质量不确定。因此,本文尝试了如下三种不同的方法来处理缺失值:
- 迹线裁剪:在这些会话开始时删除数据,以及在视频质量为NaN的结束时删除数据。这可确保在整个会话中仅保留具有有效音频和视频质量的数据。
- 零填充:简单地将这些NaN奖励信号分配为0。(ours)
- 平均填充:用整个轨迹的有效奖励信号的平均值替换NaN值。
通过这种方法,在整个轨迹中避免了显著的奖励波动,并且它有助于减轻模型在会话开始时严重高估带宽的趋势。这种方法还有助于在会话开始时做出正确的决策。虽然可以考虑其他方法,例如使用音频质量来填充缺失的视频质量,但这些方法并不总是可行的。在某些情况下,视频和音频质量都可能丢失。此外,这两种性质的分布通常是不同的。因此,简单地将值从一个复制到另一个是不合适的。最终选择了平均值填充方法,用所有转换的平均值替换缺失值。
模型设计
算法
目前三种代表性的离线 RL 算法:
- 双延迟深度确定性策略梯度算法加行为克隆(TD3_BC)
- 保守 Q 学习(CQL)
- 隐式 Q 学习(IQL)
TD3_BC 是一种策略约束方法。它只是将行为克隆项添加到在线RL算法TD3的策略更新中。对于 CQL,与 TD3_BC 中的策略约束不同,它将惩罚放在 Q 函数上(即,state-action value函数),其旨在学习保守的 Q 函数,使得策略在该 Q 函数下的期望值低于其真实值。IQL 是 SARSA 类型学习的代表,通过将状态值函数视为随机变量来隐式地近似策略价值函数。尽管 TD3_BC 和 CQL 都减轻了分布外(OOD)动作采样,但由于潜在的分布偏移,它们的性能仍然受到损害。相比之下,IQL 利用预期回归来实现样本内训练,避免了分布偏移引起的错误。相应地,IQL 有望更准确地学习 Q 函数,并获得更好的最终策略。因此,本文选择 IQL 算法来训练模型。在后续中的评估结果也证明了 IQL 优于其他两种算法的性能。IQL的目标是在策略评估阶段近似值函数
和状态-动作值函数
,并在策略提取阶段获得最终的策略
。在策略评估阶段,IQL 使用期望回归来近似最优值函数
。优化目标如下所示:
其中
,
为指示函数当u<0时取1反之取0。
为目标价值函数网络。在策略提取阶段,IQL最大限度地减少了优化最终策略的损失,策略提取公式为:
Actor网络结构
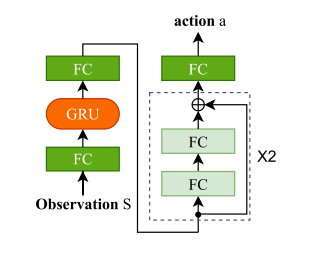
图1 网络结构
本文提出的 Actor 神经网络的结构如图1所示。每个状态的输入是包含短期和长期时间信息的150维归一化观测向量。然后将输入馈送到大小为150x256的全连接(FC)层。接下来,引入门控递归单元(GRU)来捕获每个中的内部时间信息。输出在进入残差块之前通过另一个大小为256 x256的FC,这减轻了梯度消失的风险并提高了模型性能的稳定性,然后进入大小为256 x1的最终FC。在应用了预测带宽激活函数之后,输出动作表示以Mbps为单位的预测带宽,并进一步乘以106以转换为bps。
实验
模型评估
评估本文所提出的方法的性能的最佳指标是音频和视频质量。但是,由于没有质量评估模型,无法获得每个动作后的实际质量。因此,转而评估预测精度。一般来说,准确的带宽预测有望确保更高的音频和视频质量。选择三个指标来评估所有方法的预测准确性,包括(i)预测误差率,(ii)高估率(iii)均方误差(MSE)。通常,这三个度量的较低值对应于较高的预测精度。其中baseline为MMsys提供的一种基于IQL的带宽预测模型,实验结果如图2所示:
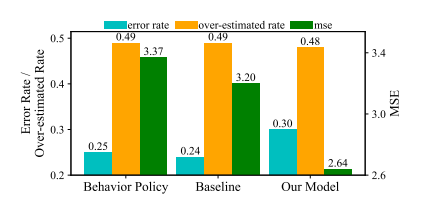
图2 实验统计结果
在错误率方面,模型没有超过行为策略和基线的性能。三个模型的高估率也相似,本文模型略低。然而,当考虑MSE时,与其他模型相比,本文的模型表现出更小的均方误差,比基线和行为策略低18%和22%,
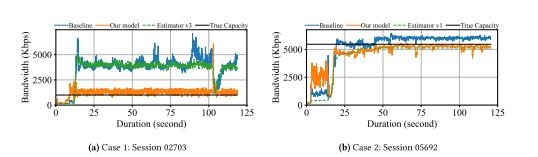
图3 模型性能对比
图3中的两个案例展示了模型相对于基准模型和行为策略的上级预测性能。在第一种情况下,模型展示了当行为策略显著高估链路带宽时做出准确预测的能力。基线模型遵循行为策略,以维持较大的高估。相比之下,本模型与真实容量密切相关。在第二种情况下,基准模型在启动阶段后往往会高估。在这种情况下,本模型倾向于与行为策略保持一致,从而具有更保守和准确的预测。
消融实验
在reward处理缺失值的三种方法中零填充和平均值填充都是值替换方法。在相同的训练算法和演员网络结构下,这三种方法在评估集上的比较结果如图4所示。
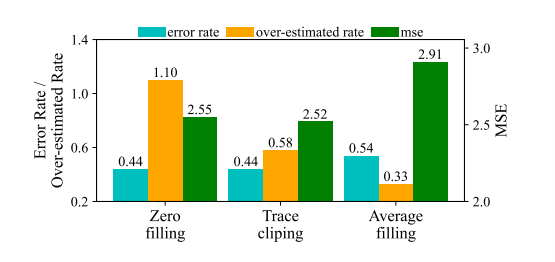
图 4 缺失值填充方法消融实验
在平均填充方法下,奖励函数中音频质量和视频质量的比例相等。从结果来看,平均填充法仅在高估率上有优势,但本文还是选择了这种方法。这是因为,与其他两种方法相比,它保留了更完整的会话信息。一方面,零填充在整个会话的奖励轨迹中引入了突然的变化,其中未定义的奖励被简单地视为最坏情况(0)。因此,模型可能会错误地将“好”行为视为“坏”行为。另一方面,跟踪裁剪会删除所有丢失的数据,使模型无法从会话开始时的操作中学习
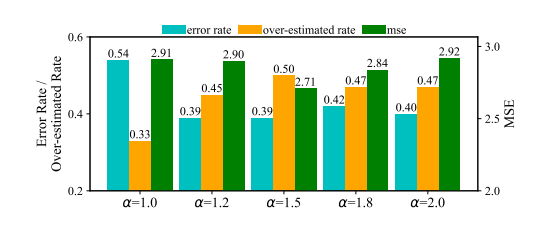
图 5 音视频质量权重消融实验
在reward计算公式中
负责调整音频和视频质量的权重。图5评估了不同
下模型的性能。
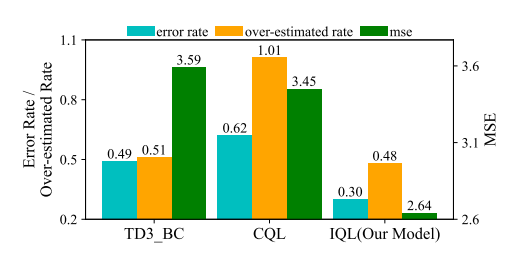
图 6 不同算法的消融实验
图6显示了三种不同算法模型的评估结果。:TD3_BC,CQL和IQL。这些评估是在一致的条件下进行的(即相同的训练集和输入特征)。实验表明使用IQL训练的模型在所有指标方面都优于其他模型,这表明IQL更适合于训练带宽预测模型。