Flink引擎介绍 | 青训营笔记

Flink概述
大数据计算架构发展历史

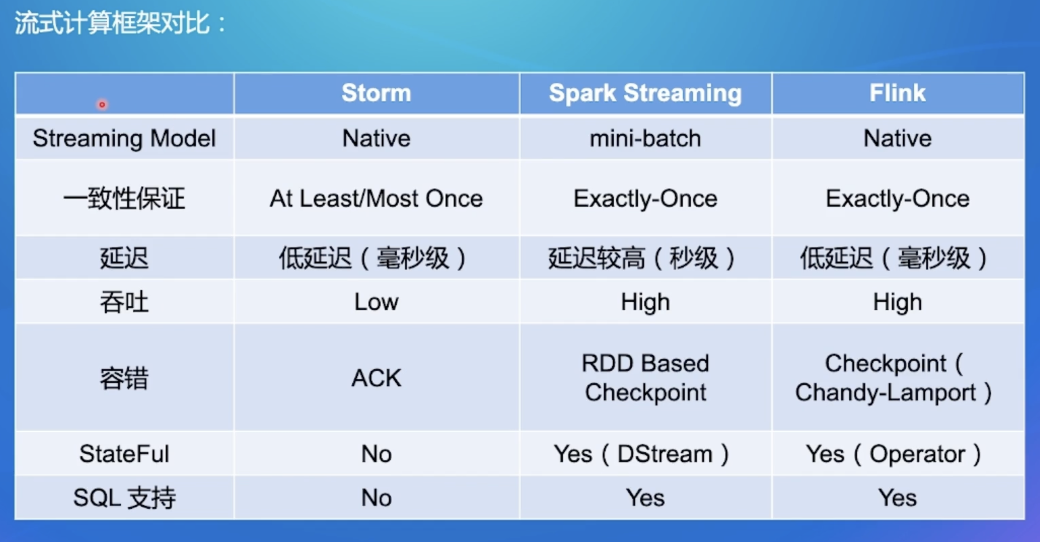
流式计算引擎对比
什么是Flink
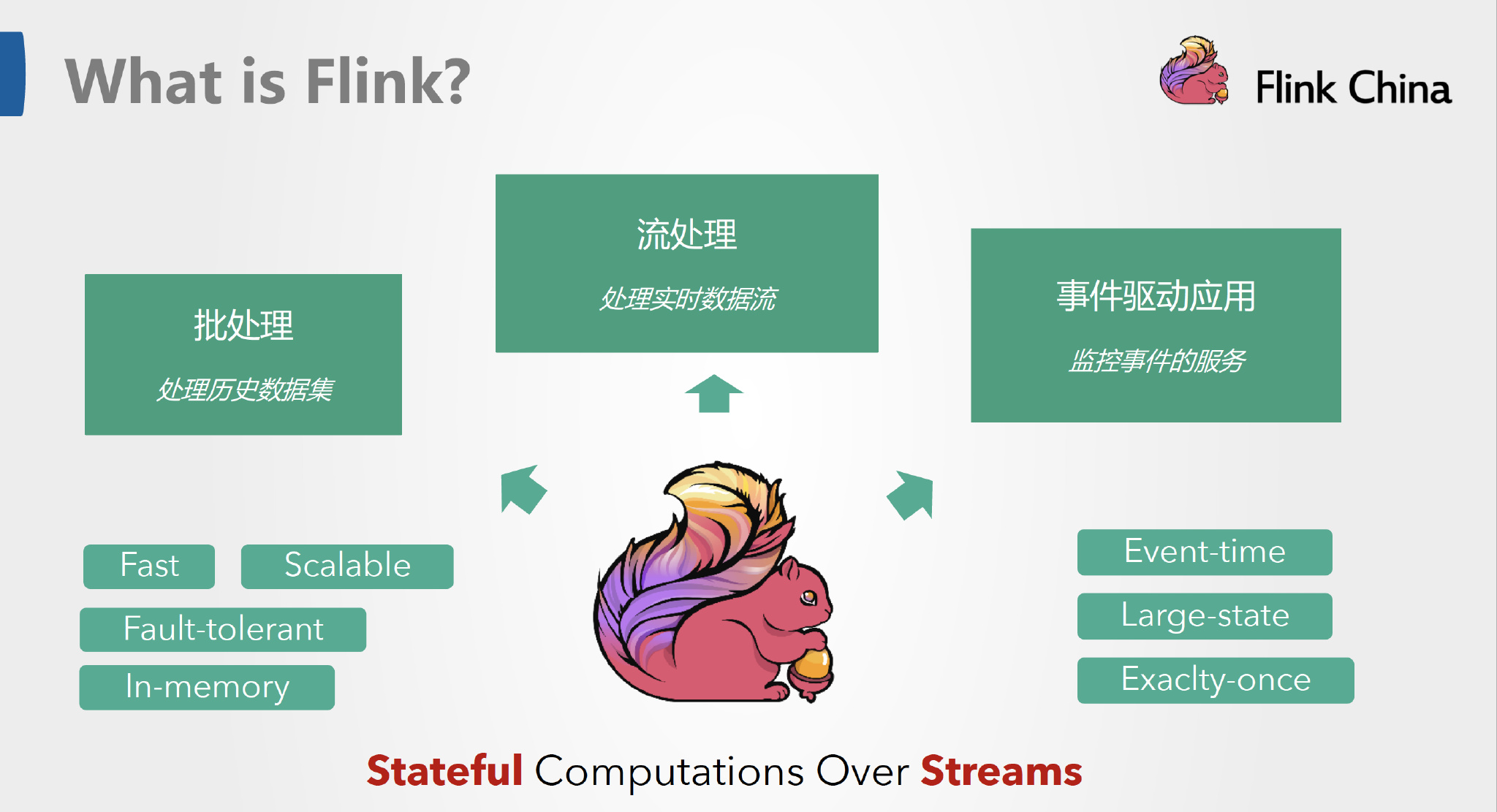
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink 不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。事实证明,Flink 已经可以扩展到数千核心,其状态可以达到 TB 级别,且仍能保持高吞吐、低延迟的特性。世界各地有很多要求严苛的流处理应用都运行在 Flink 之上。
- 批处理的特点是有界、持久、大量,非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。
- 流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
在Flink中,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流。
- 无界流:有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
- 有界流:有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
Flink整体架构
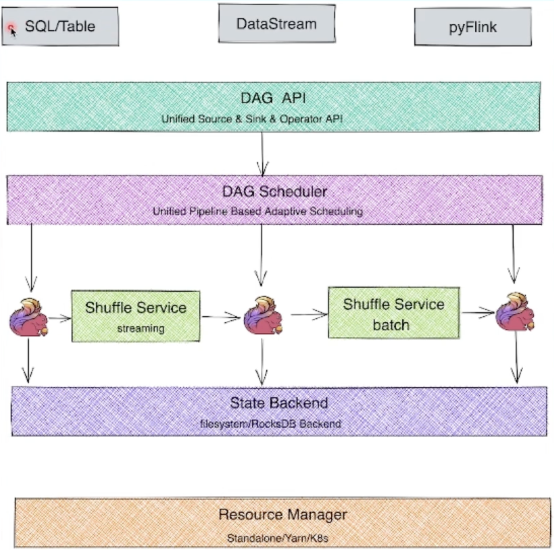
- SDK层 :Flink的SDK目前主要有三类,SQL/Table、DataStream、Python;
- 执行引擎层(Runtime层) :将流水线上的作业(不论是哪种语言API传过来的数据,不论是流还是批)都转化为DAG图,调度层再把DAG转化为分布式环境下的Task,Task之间通过Shuffle传输数据。
- 状态存储层:负责存储算子的状态信息
- 资源调度层:目前Flink可以支持部署在多种环境
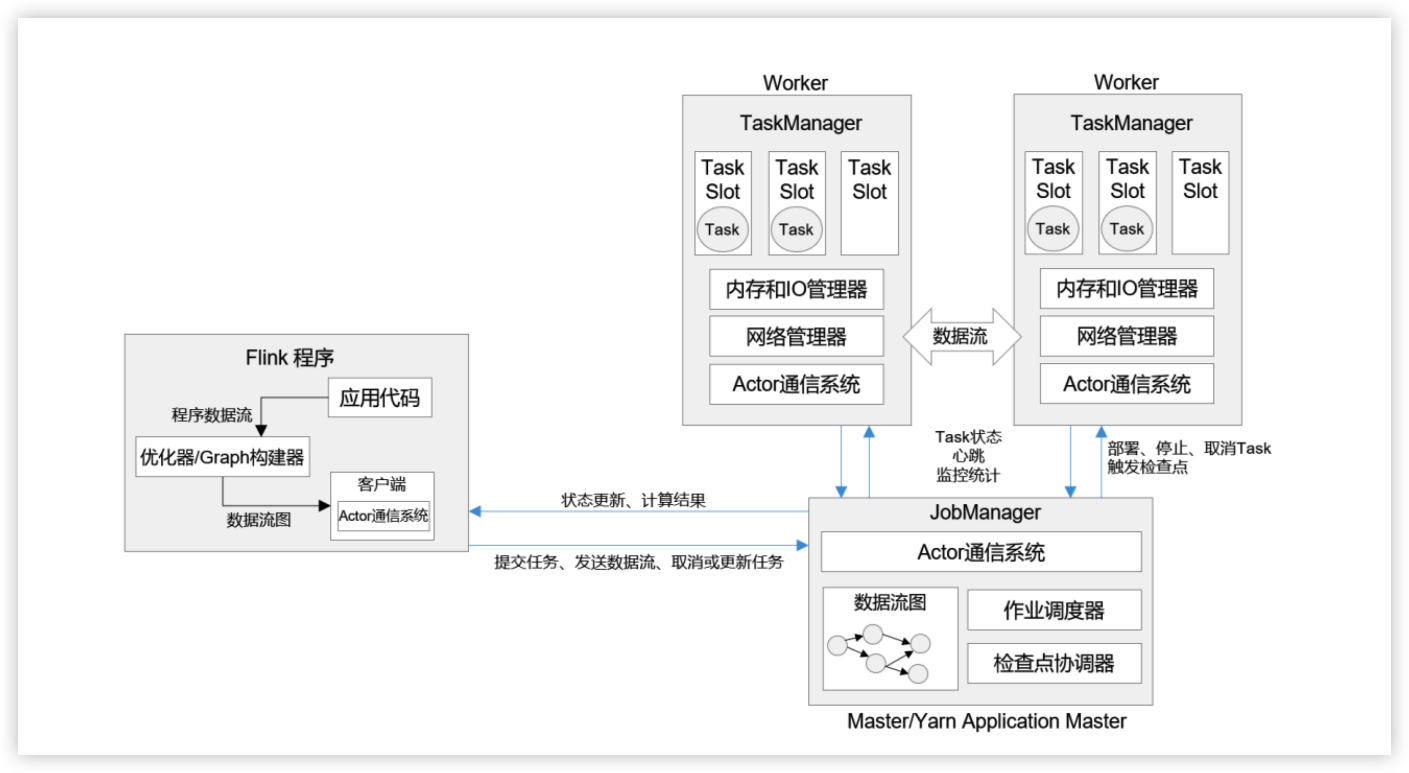
一个Flink集群,主要包含以下两个核心组件:作业管理器(JobManger)和 任务管理器(TaskManager) 。
- JobManager(JM) :由ResourceManager、jobMaster、Dispatcher组成,负责整个任务的协调工作包括:调度task、触发协调Task做Checkpoint、协调容错恢复等;
- TaskManager(TM) :负责执行一个DataFlow Graph的各个task以及data streams的buffer和数据交换。
作业管理器(JobManger)
JobManager 是一个 Flink 集群中任务管理和调度的核心,是控制应用执行的主进程。也就是说,每个应用都应该被唯一的 JobManager 所控制执行。JobManger 又包含 3 个不同的组件:分发器(Dispatcher)、JobMaster、资源管理器(ResourceManager) 。
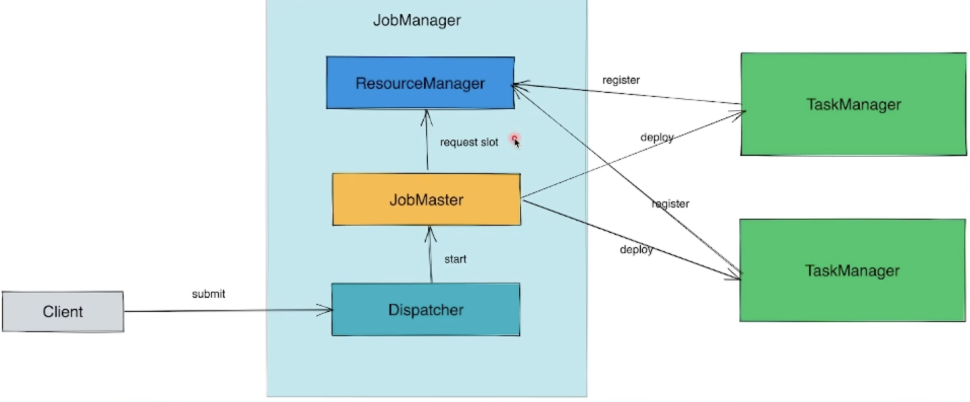
- 分发器(Dispatcher):接收作业,拉起JobManager来执行作业,并在JobMaster挂掉之后恢复作业;
- JobMaster:管理一个job的整个生命周期,会向ResourceManager申请slot ,并将task调度到对应TM上;
- 资源管理器(ResourceManager) :负责slot资源的管理和调度,Task manager拉起之后会向RM注册。
- 任务管理器(TaskManager):TaskManager 是 Flink 中的工作进程,数据流的具体计算就是它来做的,所以也被称为“Worker”。Flink 集群中必须至少有一个TaskManager;当然由于分布式计算的考虑,通常会有多个 TaskManager 运行,每一个 TaskManager 都包含了一定数量的任务槽(task slots)。Slot是资源调度的最小单位,slot 的数量限制了 TaskManager 能够并行处理的任务数量。启动之后,TaskManager 会向资源管理器注册它的 slots;收到资源管理器的指令后,TaskManager 就会将一个或者多个槽位提供给 JobMaster 调用,JobMaster 就可以分配任务来执行了。在执行过程中,TaskManager 可以缓冲数据,还可以跟其他运行同一应用的 TaskManager交换数据。
Flink示例
流式的WordCount示例,从kafka中读取一个实时数据流,每10S统计一次单词出现次数,DataStream实现代码如下
DataStream<String> Lines=env.addSource(new FlinkKafkaConsumer<>(...));
DataStream<String> events=lines.map((line)->parse(line));
DataStream<Statistics>stats=events
.keyBy(event->event.id)
.timeWindow(Time.seconds(10))
.apply(new MyWindowAggregationFunction());
stats.addSink(new BucketingSink(path));
业务逻辑转换为一个Streaming DataFlow Graph
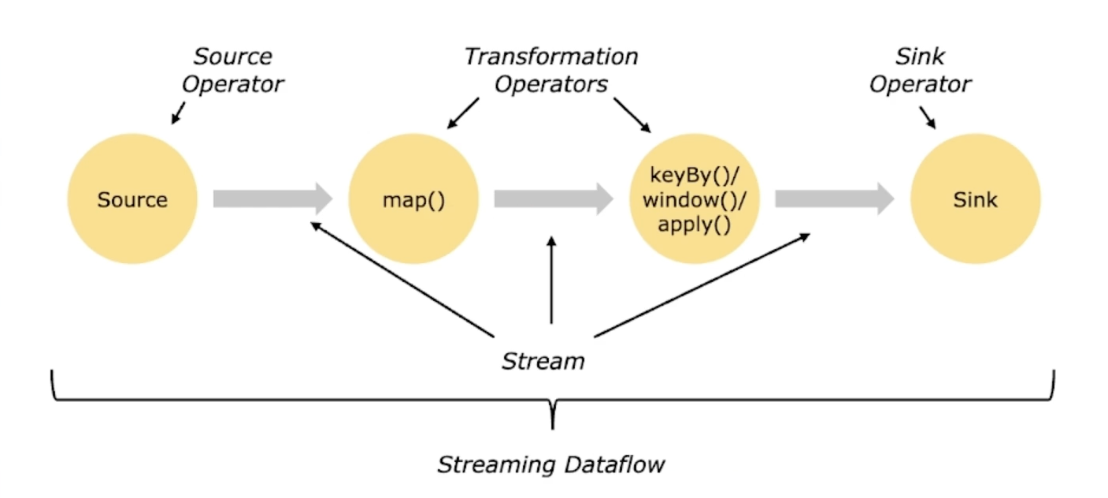
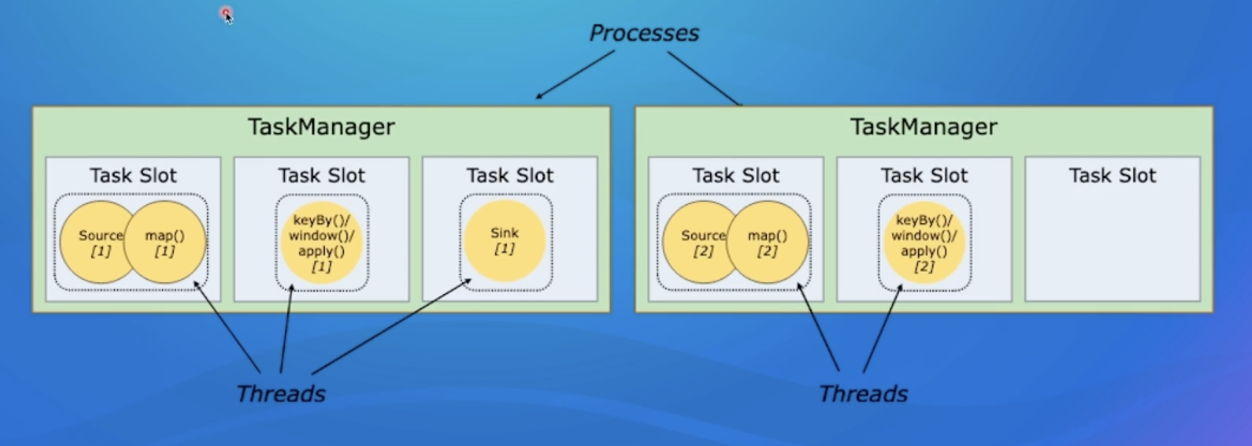
假设示例的sink算子的并发配置为1 , 其余算子并发为2 紧接着会将上面的Streaming DataFlow Graph转化Parallel Dataflow (内部叫Execution Graph) :
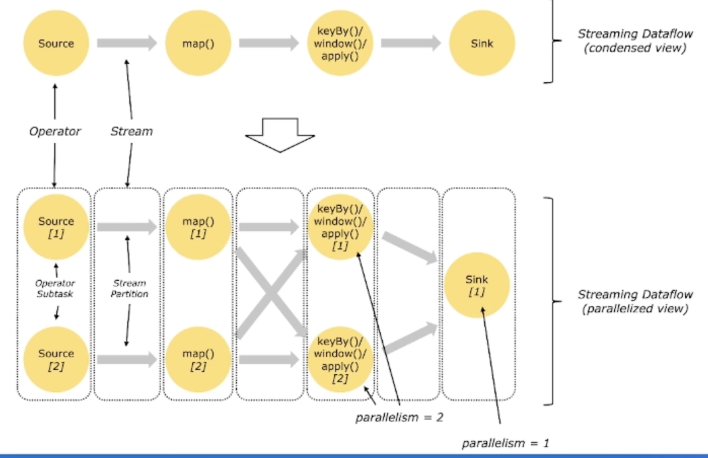
为了更高效地分布式执行,Flink会尽可能地将不同的operator链接( chain )在一起形成Task。 这样每个Task可以在一个线程中执行,内部叫做OperatorChain,如下图的source和map算子可以Chain在一起。
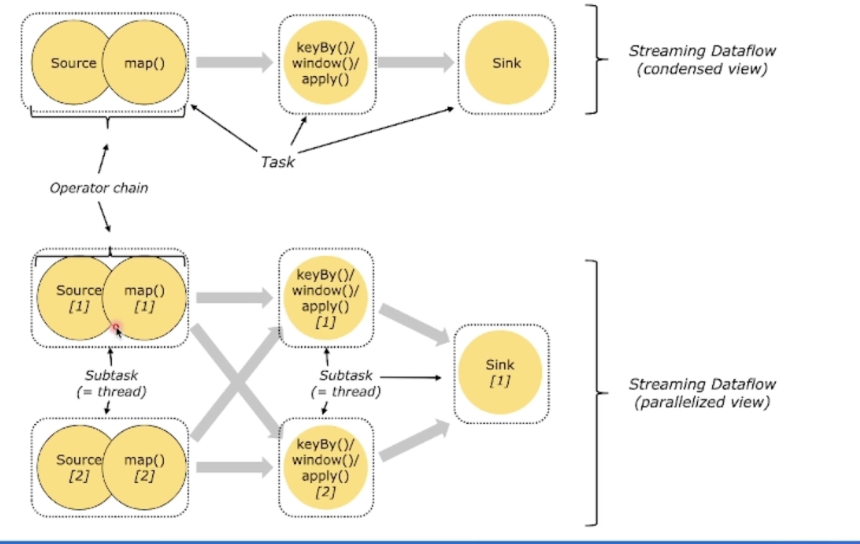
最后将上面的Task调度到具体的TaskManager中的slot 中执行,一个Slot只能运行同一个task的subTask