深入浅出HBase实战 | 青训营笔记

深入浅出 HBase 实战
HDFS是一种开源的分布式文件系统,基于常见商用硬件构建海量大规模存储集群,提供极低的存储成本,极大的存储容量支持。 HDFS提供高可靠性的数据保障,通常采用三副本冗余存储数据到不同的机器来实现容灾备份能力。 HBase基于HDFS实现存储计算分离架构的分布式表格存储服务
HBase
HBase 是一个面向列式存储的分布式数据库,其设计思想来源于 Google 的 BigTable 论文。HBase 底层存储基于 HDFS 实现,集群的管理基于 ZooKeeper 实现。HBase 良好的分布式架构设计为海量数据的快速存储、随机访问提供了可能,基于数据副本机制和分区机制可以轻松实现在线扩容、缩容和数据容灾,是大数据领域中 Key-Value 数据结构存储最常用的数据库方案。
HBase特点
易扩展
Hbase 的扩展性主要体现在两个方面,一个是基于运算能力(RegionServer) 的扩展,通过增加 RegionSever 节点的数量,提升 Hbase 上层的处理能力;另一个是基于存储能力的扩展(HDFS),通过增加 DataNode 节点数量对存储层的进行扩容,提升 HBase 的数据存储能力。
海量存储
HBase 作为一个开源的分布式 Key-Value 数据库,其主要作用是面向 PB 级别数据的实时入库和快速随机访问。这主要源于上述易扩展的特点,使得 HBase 通过扩展来存储海量的数据。
列式存储
Hbase 是根据列族来存储数据的。列族下面可以有非常多的列。列式存储的最大好处就是,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段时,能大大减少读取的数据量。
高可靠性
WAL 机制保证了数据写入时不会因集群异常而导致写入数据丢失,Replication 机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。而且 Hbase 底层使用 HDFS,HDFS 本身也有备份。
稀疏性
在 HBase 的列族中,可以指定任意多的列,为空的列不占用存储空间,表可以设计得非常稀疏。
HBase和关系型数据库的区别

HBase 数据模型
HBase以列族(column family)为单位存储数据,以行键(rowkey)索引数据,具体解析如下:
行键(rowkey):用于唯一索引一行数据的"主键",以字典序组织。一行可以包括多个列族。
列族(column family);用于组织一系列列名,一个列族可以包含任意多个列名。每个列族的数据物理上相互独立地存储,以支持按列读取部分数据。
列名(column qualifier);用于定义到一个具体的列,一个列名可以包含多个版本的数据。不需要预先定义列名,以支持半结构化的数据模型。
版本号(version):用于标识一个列内多个不同版本的数据,每个版本号对应一个值。
值(value):存储的一个具体值。
列族需要在使用前预先创建,列名(column qualifier)不需要预先声明,因此支持半结构化数据模型。
支持保留多个版本的数据, (行键+列族+列名+版本号)定义一个具体的值
HBase数据模型-逻辑结构
HBase是半结构化数据模型。以列族(column family) 为单位存储数据,以行键(rowkey) 索引数据, 列族需要在使用前预先创建,列名(column qualifier) 不需要预先声明,因此支持半结构化数据模型 支持保留多个版本的数据, (行键+列族+列名+版本号) 定位一个具体值
HBase数据模型-物理结构
HBase的物理数据结构最小单元式KeyValue结构,每个版本的数据都携带全部行列信息,同一行,同一列族的数据物理上连续有序存储。同列族内的KeyValue按rowkey字典序升序,column qualifier升序,version降序排列,不同列族的数据存储在相互独立的物理文件,列族间不保证数据全局有序。同列族下不同物理文件间不保证数据全局有序,仅单个物理文件内有序。
使用场景
- "近在线"的海量分布式KV/宽表存储,数据量级可达到PB级以上
- 写密集型、高吞吐应用,可接受一定程度的时延抖动
- 字典序主键索引、批量顺序扫描多行数据的场景
- Hadoop大数据生态友好兼容
- 半结构化数据模型,行列稀疏的数据分布,动态增删列名
- 敏捷平滑的水平扩展能力,快速响应数据体量、流量变化
HBase架构设计
HBase的主要组件包括HMaster、RegionServer、ThriftServer,依赖组件包括Zookeeper、HDFS
HMaster
元数据管理,集群调度、保活。
主要职责
- 管理RegionServer实例生命周期,保证服务可用性
- 协调RegionServer数据故障恢复,保证数据正确性
- 集中管理集群元数据,执行负载均衡等维护集群稳定性
- 定期巡检元数据,调整数据分布,清理废弃数据等
- 处理用户主动发起的元数据操作如建表、删表等
主要组件:
- ActiveMasterManager:管理HMaster的active/backup状态
- ServerManager:管理集群内RegionServer的状态
- AssignmentManager:管理数据分片(region)的状态
- SplitWalManager:负责故障数据恢复的WAL拆分工作
- LoadBalancer:定期巡检、调整集群负载状态
- RegionNormalize:定期巡检并拆分热点、整合碎片
- CatalogJanitor:定期巡检、清理元数据
- Cleaners:定期清理废弃的HFile\WAL等文件
- MasterFileSystem:封装访问HDFS的客户端SDK
RegionServer
提供数据读写服务,每个实例负责若干个互不重叠的rowkey区间内的数据
主要职责:
- 提供部分rowkey区间数据的读写服务
- 如果负责meta表,向客户端SDK提供rowkey位置信息
- 认领HMaster发布的故障恢复任务,帮助加速数据恢复过程
- 处理HMaster下达的元数据操作,如region打开/关闭/分裂/合并操作等
主要组件
- MemStore:基于SkipList数据结构实现的内存态存储,定期批量写入硬盘
- Write-Ahead-Log:顺序记录写请求到持久化存储,用于故障恢复内存中丢失的数据
- StoreFile:即HFile,表示HBase在HDFS存储数据的文件格式,其内数据按rowkey字典序有序排列
- BlockCache:HBase以数据块为单位读取数据并缓存在内存中以加速重复数据的读取
ZooKeeper
分布式一致性共识协作管理,例如HMaster选主、任务分发、元数据变更管理等
主要职责
- HMaster登记信息,对activer/backup分工达成工事
- RegionServer登记信息,失联时HMaster保活处理
- 登记meta表位置信息,供SDK查询读写位置信息
- 供HMaster和RegionServer协作处理分布式任务
ThriftServer
提供Thrift API读写的代理层
主要职责
- 实现HBase定义的Thrift API,作为代理层向用户提供RPC读写服务
- 用户可根据IDL自行生成客户端实现
- 独立于RegionServer水平扩展,用户可访问任意ThriftServer实例(scan操作较特殊,需要同实例维护scan状态)
大数据支撑
- 对TB、PB级海量数据支持强一致、近实时的读写性能,支持快速的ad-hoc分析查询任务;
- 支持字典序批量扫描大量数据,支持只读取部分列族的数据,灵活支持不同查询模式,避免读取不必要的数据;
- 存储大规模任务(例如MapReduce , Spark,Flink )的中间/最终计算结果;
- 平滑快速的水平扩展能力,能够敏捷应对大数据场景高速增长的数据体量和大规模的并发访问;
- 精细化的资源成本控制,计算层和存储层分别按需扩展,避免资源浪费。
水平扩展能力
- 增加RegionServer实例,分配部分Region到新实例
- 扩展过程平滑,无需搬迁实际数据
- 可用性影响时间很短,用户基本无感知
Region热点切分
- 当某个region数据量过多,切分成两个独立的子region分摊负载。
- RegionServer在特定时机检查region是否应该切分,计算切分点并RPC上报HMaster,由AssignmentManager负责执行RegionStateTansition。
- 不搬迁实际数据,切分产生的新region数据目录下生成一个以原region文件信息命名的文件,内容是切分点对应的rowkey,以及标识新region是上/下半部分的数据
切分点选择
HBase原生提供的多种切分能的的用的司的的分点选择策略。
目标:优先把最大的数据文件均匀切分
切分点选择步骤
- 找到该表中哪个Region的数据大小最大
- 找到该表中哪个column family最大
- 找到该表中哪个HFile最大
- 找到HFile里处于最中间位置的Data Block
- 用这个Data Block的第一条KeyValue的RowKey作为切分点
切分步骤
- 所有column family都按照统一的切分点来切分数据
- 目的是优先均分最大的文件,不保证所有column family的所有文件都被均分
- 最大的文件被均分,其他文件也必须以相同的rowkey切分以保证对其新Region的rowkey区间
- 每个新Region分别负责原Region的上/下半部分rowkey区间的数据
- 在compaction执行前不实际切分文件,新Region下的文件通过reference file指向原文件读取实际数据
流程设计
AssignmentManager检查cluster. table、 region 的状态后,创建SplitTableRegionProcedure通过状态机实现执行切分过程。
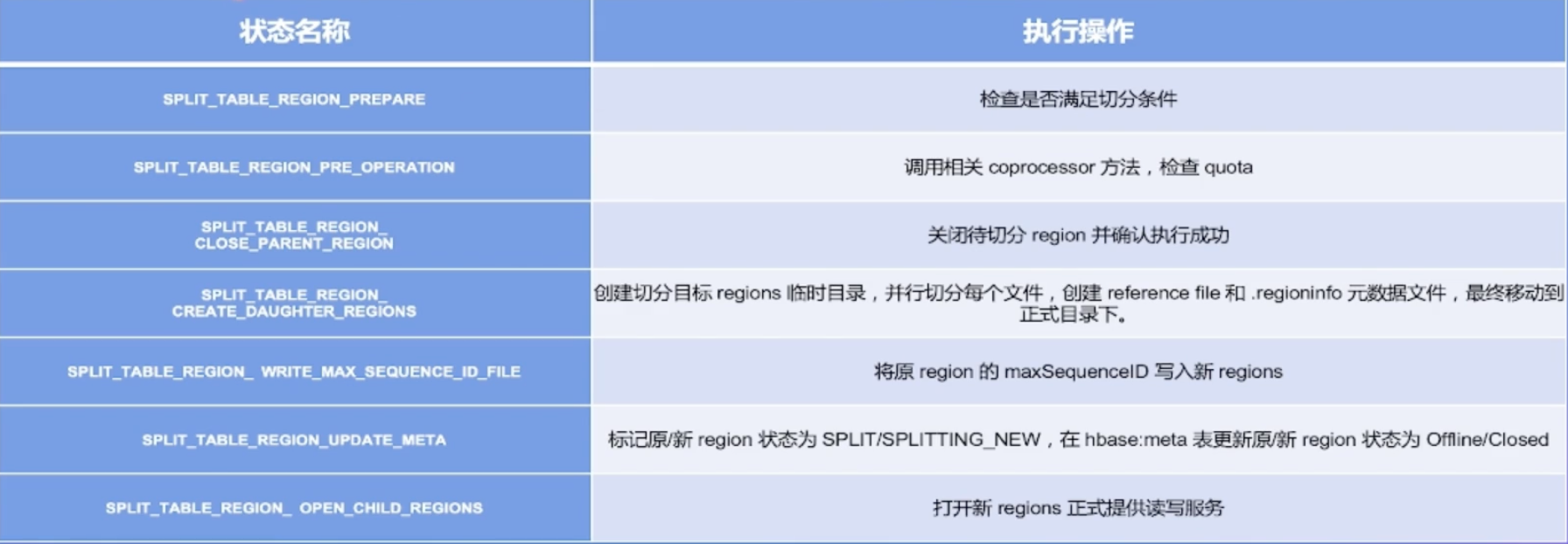
碎片整合
- 当某些Region数据量较小、碎片化,合并相邻Region整合优化数据分布
- AssignmentManager创建Merge TableRegionsProcedure执行整合操作。
- 不搬迁实际数据,通过reference file指向原文件读取实际数据,直到下次compaction时实际处理数据。
- 注意:只允许合并相邻region,否则会打破rowkey空间连续且不重合的约定
负载均衡策略
定期巡检RegionServer上的region数量,保持region的数量均匀分布在各个RegionServer上。
SimpleLoadBalancer具体步骤
- 根据总Region数量和RegionServer数量计算平均Region数,设定弹性上下界避免不必要的操作。
- 将RegionServer按照Region数量降序排序,对Region数量超出上限的选取要迁出Region并按创建时间从新到老排序
- 选取出Region数量低于下限的RegionServer列表,round-robin分配步骤2选取的Region,尽量使每个RS的Region数量都不低于下界
- 处理边界情况,无法满足所有RS的Region数量都在合理范围时,尽量保持Region数量相近
负载均衡的其他策略
StochasticLoadBalancer
- 随机尝试不同的region放置策略,根据提供的cost function计算不同策略的分值排名
- cost计算将下列指标纳入统计:Region负载、表负载、数据本地性(本地访问HDFS)、Memstore大小、HFile大小
- 根据配置加权计算最终cost,选择最优方案进行负载均衡
FavoredNodeLoadBalance
- 用于充分利用本地读写HDFS文件来优化读写性能
- 每个Region会指定优选的3个RegionServer地址,同时会告知HDFS在这些优选节点上放置该Region的数据
- 即使第一节点出现故障,HBase也可以将第二节点提升为第一节点,保证稳定的读时延
故障恢复机制 - HMaster
HMaster通过多实例基于ZooKeeper选主实现高可用性
- 所有实例尝试向ZooKeeper的
/hbase/active-master临时节点CAS写入自身信息 - 写入成功表示成为主实例,失败则成为从实例,通过watch监听
/hbase/active-master节点的变动 - 主实例不可用时临时节点被删除,此时触发其他从实例重新尝试选主
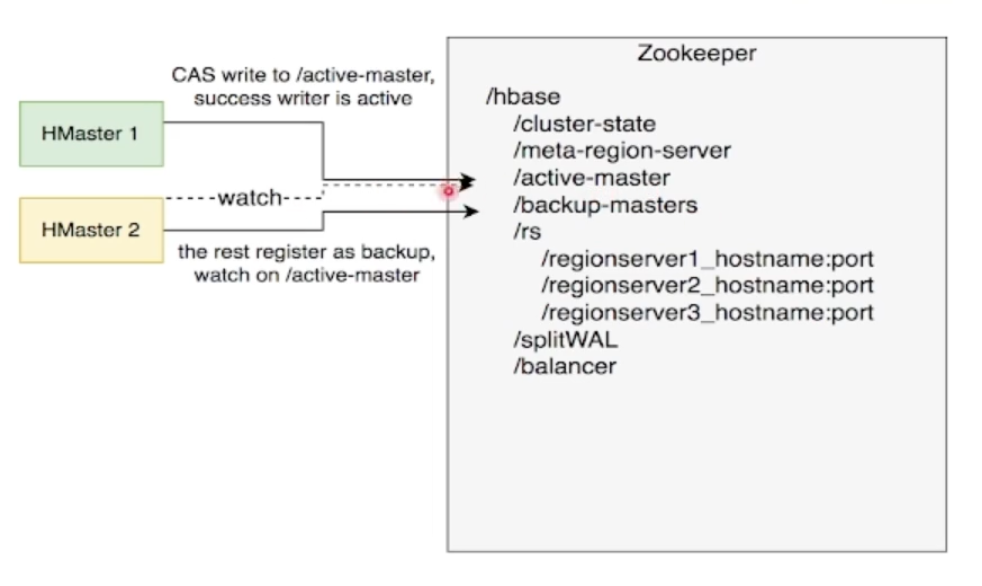
HMaster自身恢复流程
- 监听到
/hbase/active-master临时节点被删除的时间,触发选主逻辑 - 选主成功后执行HMaster启动流程,从持久化存储读取未完成的Procedures从之前状态继续执行
- 故障HMaster实例恢复后发现主节点已存在,继续监听
/hbase/active-master
调度RegionServer的故障恢复流程:
- AssignmentManager从procedure列表中找出Region-ln-Transition 状态的region继续调度过程;
- RegionServer Tracker从Zookeeper梳理online 状态的RegionServer列表,结合ServerCrashProcedure列表、HDFS中WAL目录里alive / splitting 状态的RegionServer记录,获取掉线RegionServer的列表,分别创建ServerCrashProcedure执行恢复流程。
故障恢复机制 - RegionServer
- 每个RegionServer实例启动时都会向ZooKeeper的
/hbase/rs路径下创建对应的临时节点 - HMaster通过监听RegionServer在ZooKeeper的临时节点情况,监控数据读写服务的可用性,及时调度恢复不可用的regions
- RegionServer的故障恢复需要将内存中丢失的数据从WAL中恢复,HMaster利用ZooKeeper配合所有RegionServer实例,分布式地处理WAL数据,提升恢复速度
启动流程:
- 启动时去Zookeeper登记自身信息,告知主HMaster实例有新RS实例接入集群。
- 接收和执行来自HMaster的region调度命令
- 打开region前先从HDFS读取该region的recovered.edits目录下的WAL记录,回放恢复数据
- 恢复完成,认领Zookeeper.上发布的分布式任务(如WAL切分)帮助其他数据恢复
Distributed Log Split原理
背景:写入HBase的数据首先顺序持久化到Write-Ahead-Log中,然后写入内存的MemStore即完成,不立即写盘,RegionServer故障会导致内存中的数据丢失,需要回放WAL恢复。同RegionServer的所有Region复用WAL,因此不同Region的数据交错穿插,RegionServer故障后重新分配的Region前需要先按Region维度拆分WAL
具体流程实现原理
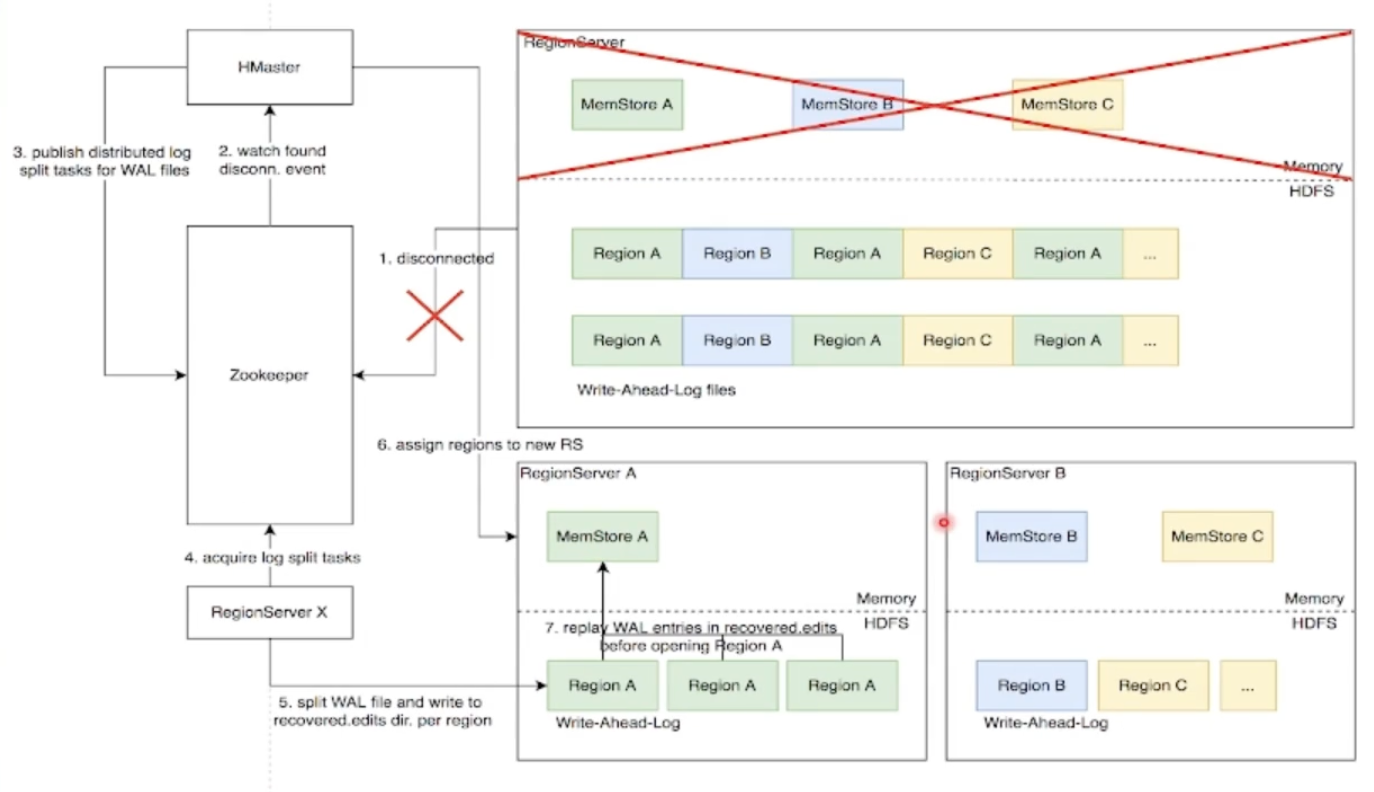
- RegionServer 故障,Zookeeper 检测到心跳超时或连接断开,删除对应的临时节点并通知监听该节点的客户端
- active HMaster监听到RS临时节点删除事件,从HDFS梳理出该RS负责的WAL文件列表
- HMaster为每个WAL文件发布一个log split task到ZK
- 其他在线的RS监听到新任务,分别认领
- 将WAL entries按region拆分,分别写入HDFS.上该region 的recovered.edits目录
- HMaster监听到log split 任务完成,调度region到其他RS
- RS打开region前在HDFS找到先回放recovered.edits目录下的WAL文件将数据恢复到Memstore里,再打开region恢复读写服务
优化空间
进一步优化: Distributed Log Replay
- HMaster 先将故障RegionServer.上的所有region以Recovering状态调度分配到其他正常RS上;
- 再进行类似Distributed Log Split的WAL日志按region维度切分;
- 切分后不写入HDFS ,而是直接回放,通过SDK写流程将WAL记录写到对应的新RS ;
- Recovering 状态的region接受写请求但不提供读服务,直到WAL回放数据恢复完成。