KNN——K最近邻算法以及实例应用

持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第19天,点击查看活动详情
KNN-K最近邻算法
什么是KNN算法
KNN算法是寻找最近的K个数据,以此推测新数据的分类算法。 所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来代表。近邻算法就是将数据集合中每一个记录进行分类的方法。
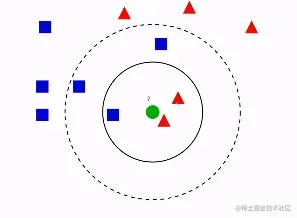
数据样本
算法原理
通用步骤
- 计算距离(常用有欧几里得距离、马氏距离)
- 升序排序
- 取前K个
- 加权平均
K的选取
- K太大:会导致分类模糊
- K太小:容易受个例影响,波动较大
- 选取:均方根误差(找到峰值)
实例:预测癌症良性 OR 恶性
数据集结构如下图所示:

数据样本
- 数据分析与预处理
数据标签
- M:恶性
- B:良性
其他字段组成八维的数据集,为后续判断良性 、 恶性的依据
- 划分数据集
取数据的1/3作为测试集,2/3作为训练集
import random
import csv
# 癌症预测数据文件读取
with open("Prostate_Cancer.csv", "r") as file:
reader = csv.DictReader(file)
datas = [row for row in reader]
# 分组 -训练集2/3 -测试集1/3
# 将数据打乱,每次得到不同的分组
random.shuffle(datas)
n = len(datas) // 3
test_set = datas[0:n]
train_set = datas[n:]- 欧几里得公式测距离
# 距离
def distance(d1, d2):
res = 0
for key in ("radius", "texture", "perimeter", "area", "smoothness", "compactness", "symmetry", "fractal_dimension"):
res += (float(d1[key]) - float(d2[key])) ** 2
return res ** 0.5- 选取K值
先尝试K取5
- 将运算后的数据按距离升序排列
- 选取距离最小的k个样点
- 加权平均
分类计算加权平均距离,多数表决预测
源码
import random
import csv
# 癌症预测数据文件读取
with open("Prostate_Cancer.csv", "r") as file:
reader = csv.DictReader(file)
datas = [row for row in reader]
# 分组 -训练集2/3 -测试集1/3
# 将数据打乱,每次得到不同的分组
random.shuffle(datas)
n = len(datas) // 3
test_set = datas[0:n]
train_set = datas[n:]
# KNN
# 距离
def distance(d1, d2):
res = 0
for key in ("radius", "texture", "perimeter", "area", "smoothness", "compactness", "symmetry", "fractal_dimension"):
res += (float(d1[key]) - float(d2[key])) ** 2
return res ** 0.5
K = 5
def knn(data):
# 1.所有的距离
res = [
{"result": train["diagnosis_result"], "distance": distance(data, train)}
for train in train_set
]
# 2.升序排序
res = sorted(res, key=lambda item: item["distance"])
# 3.取前K个
res2 = res[0:K]
# 4.加权平均
result = {'B': 0, 'M': 0}
# 总距离
sum = 0
for r in res2:
sum += r["distance"]
for r in res2:
result[r["result"]] += 1 - r["distance"] / sum
# print(result)
# print(data["diagnosis_result"])
if result['B'] > result['M']:
return "B"
else:
return "M"
# 测试阶段
correct = 0
for test in test_set:
result = test["diagnosis_result"]
result2 = knn(test)
if result == result2:
correct += 1
print("准确个数:", correct)
print("测试总数:", len(test_set))
print("准确率:{:.2f}%".format(100 * correct / len(test_set)))本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-05-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
相关产品与服务
腾讯云服务器利旧
云服务器(Cloud Virtual Machine,CVM)提供安全可靠的弹性计算服务。 您可以实时扩展或缩减计算资源,适应变化的业务需求,并只需按实际使用的资源计费。使用 CVM 可以极大降低您的软硬件采购成本,简化 IT 运维工作。