MySQL AHI 实现解析
原创
MySQL AHI 实现解析
原创
musazhang
修改于 2017-08-22 14:56:48
修改于 2017-08-22 14:56:48
MySQL 定位用户记录的过程可以描述为:
打开索引 -> 根据索引键值逐层查找 B+ 树 branch 结点 -> 定位到叶子结点,将 cursor 定位到满足条件的 rec 上
如果树高为 N, 则需要读取索引树上的 N 个结点并进行比较,如果 buffer_pool 较小,则大量的操作都会在 pread 上,用户响应时间变长;另外,MySQL中 Server 层与 Engine 之间的是以 row 为单位进行交互的,engine 将记录返回给 server 层,server 层对 engine 的行数据进行相应的计算,然后缓存或发送至客户端,为了减少交互过程所需要的时间,MySQL 做了两个优化:
- 如果同一个查询语句连续取出了 MYSQL_FETCH_CACHE_THRESHOLD(4) 条记录,则会调用函数 row_sel_enqueue_cache_row_for_mysql 将 MYSQL_FETCH_CACHE_SIZE(8) 记录缓存至 prebuilt->fetch_cache 中,在随后的 prebuilt->n_fetch_cached 次交互中,都会从prebuilt->fetch_cache 中直接取数据返回到 server 层,那么问题来了,即使是用户只需要 4 条数据,Engine 层也会将 MYSQL_FETCH_CACHE_SIZE 条数据放入 fetch_cache 中,造成了不必要的缓存使用。另外, 5.7 可以根据用户的设置来调整缓存用户记录的条数;
- Engine 取出数据后,会将 cursor 的位置保存起来,当取下一条数据时,会尝试恢复 cursor 的位置,成功则并继续取下一条数据,否则会重新定位 cursor 的位置,从而通过保存 cursor 位置的方法可以减少 server 层 & engine 层交互的时间;
Server 层 & engine 层交互的过程如下,由于 server & engine 的 row format 不一样,那么 engine row format -> server row format 在读场景下的开销也是比较大的。
while (rc == NESTED_LOOP_OK && join->return_tab >= join_tab)
{
int error;
if (in_first_read)
{
in_first_read= false;
error= (*join_tab->read_first_record)(join_tab);
}
else
error= info->read_record(info); /* load data from engine */
rc= evaluate_join_record(join, join_tab); /* computed by server */
}
AHI 功能作用
由以上的分析可以看到 MySQL 一次定位 cursor 的过程即是从根结点到叶子结点的路径,时间复杂度为:height(index) + [CPU cost time],上述的两个优化过程无法省略定位 cursor 的中间结点,因此需要引入一种可以从 search info 定位到叶子结点的方法,从而省略根结点到叶子结点的路径上所消耗的时间,而这种方法即是 自适应索引(Adaptive hash index, AHI)。查询语句使用 AHI 的时候有以下优点:
- 可以直接通过从查询条件直接定位到叶子结点,减少一次定位所需要的时间
- 在 buffer pool 不足的情况下,可以只针对热点数据页建立缓存,从而避免数据页频繁的 LRU
但是AHI 并不总能提升性能,在多表Join & 模糊查询 & 查询条件经常变化的情况下,此时系统监控 AHI 使用的资源大于上述的好处时,不仅不能发挥 AHI 的优点,还会为系统带来额外的 CPU 消耗,此时需要将 AHI 关闭来避免不必要的系统资源浪费,关于 AHI 的适应场景可以参考:mysql_adaptive_hash_index_implementation。
AHI 内存结构
AHI 会监控查询语句中的条件并进行分析(稍后会进行详细的介绍),当满足 AHI 缓存建立的条件后,会选择索引的若干前缀索引列对热点数据页组建 hash page 以记录 hash value -> page block 之间的对应关系, 本小节主要对 AHI 的内存结构 & 内存来源进行相应的介绍,其内存结构如图:
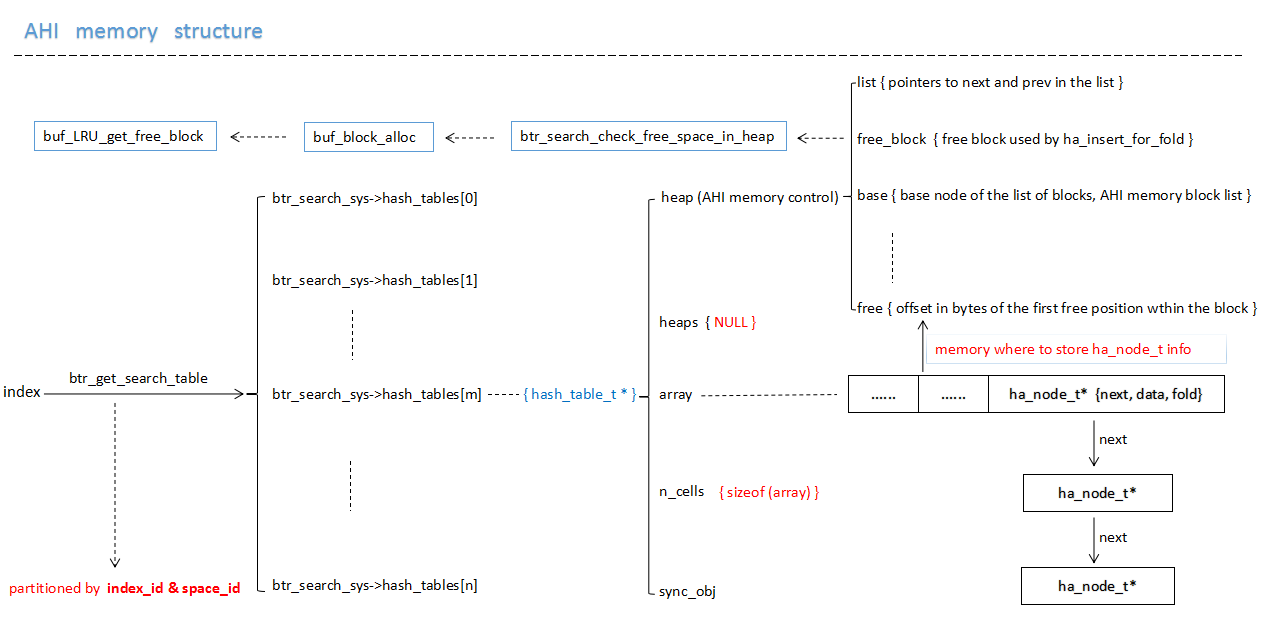
上图是 AHI 的一个内存结构示意图,AHI 主要使用以下两种内存:
- 系统初始化分配的 hash_table 的内存,其中每一个 hash_table 的数组大小为:(buf_pool_get_curr_size() / sizeof(void*) / 64),根据机器位数的不同,数组大小不同, 32位机器为 buffer_pool大小的 1/256, 64 位机器为 buffer_pool 大小的 1/512, 此部分内存为系统内存(mem_area_alloc->malloc),主要用于构建 hash_table 结构;
#0 mem_area_alloc (psize=0x7fffffff9888, pool=0x19c27c0) at ../storage/innobase/mem/mem0pool.cc:380
#1 0x0000000000bafb00 in mem_heap_create_block_func (heap=0x0, n=72, file_name=0x10bd7f8 "../storage/innobase/ha/hash0hash.cc", line=303, type=0)
at ../storage/innobase/mem/mem0mem.cc:336
#2 0x0000000000d91c3a in mem_heap_create_func (n=72, file_name=0x10bd7f8 "../storage/innobase/ha/hash0hash.cc", line=303, type=0) at ../storage/innobase/include/mem0mem.ic:449
#3 0x0000000000d91d78 in mem_alloc_func (n=72, file_name=0x10bd7f8 "../storage/innobase/ha/hash0hash.cc", line=303, size=0x0) at ../storage/innobase/include/mem0mem.ic:537
#4 0x0000000000d9358b in hash0_create (n=16352) at ../storage/innobase/ha/hash0hash.cc:303
#5 0x0000000000d8f699 in ha_create_func (n=16352, sync_level=0, n_sync_obj=0, type=3) at ../storage/innobase/ha/ha0ha.cc:67
#6 0x0000000000cfeaff in btr_search_sys_create (hash_size=16352) at ../storage/innobase/btr/btr0sea.cc:179
#7 0x0000000000d099f9 in buf_pool_init (total_size=8388608, n_instances=1) at ../storage/innobase/buf/buf0buf.cc:1498
...
(gdb) n
381 return(malloc(*psize));
- 当 AHI 对数据页面构造 AHI 缓存时,此时使用 buffer_pool 的 free 链接中的内存,即 buffer_pool 的内存,所以在页数据发生变化的时候,需要对 AHI 缓存进行相应的维护;
AHI 实现解析
【 AHI 在查询过程中的作用范围 】
MySQL 中 Server & Innodb 的交互中是以行为单位进行交互的,Innodb 逐行取数据的过程可以分为以下 6 个步骤:
- 0.如果发现其它线程需要对btr_search_latch上锁,则释放 btr_search_latch,然后执行
1; (5.6 & 5.7 在实现上不同) - 1.尝试从 row_prebuilt_t->fetch_cache 中取数据库记录,有则直接返回,如果没有数据或者不可以使用 fetch cache, 则执行
2 - 2.在满足条件的情况下,使用 AHI 定位 cursor 位置并返回数据, 否则执行
3 - 3.根据 direction 的值确认是否可以从 row_prebuilt_t中恢复 cursor 的位置,如果 direction = 0 或不可以从 row_prebuilt_t中恢复 cursor 的位置, 则调用 btr_pcur_open_at_index_side 打开索引,调用 btr_cur_search_to_nth_level,如果可以使用 AHI,则快速定位叶子结点,否则遍历 height(index) 个结点定位 cursor, 然后进入
4;如果可以从 row_prebuilt_t 恢复则执行5 - 4.根据查找的值在叶子结点中逐个匹配,查找满足条件的记录,返回数据,取下一条记录时执行
3,5 - 5.移动 cursor 到下一条记录并返回数据
AHI 则在第 [2, 3] 两个步骤中影响着定位叶子结点的过程,根据查询条件定位叶子节点的过程中发挥着 hash 的作用,AHI 的实现主要包括 AHI 初始化过程、构建条件、使用过程、维护过程、系统监控等部分,我们从源码的实现的角度上分析上述过程。
【 AHI 初始化过程 】
AHI 作为 buffer_pool 的一部分,是建立查询条件与 REC 在内存中位置的一个 hash_table, 在系统启动的时候会随着 buffer_pool 的初始化而自动的建立相应的内存结构,其初始化过程为:
- 利用系统内存 (malloc) 创建全局变量 btr_search_sys 及其锁结构
- 利用系统内存 (malloc) 建立 hash_table 内存结构,并初始化其成员变量,其中 hash_table 数组的大小取决于当前 buffer_pool 的 size 与 系统的机器位数,计算公式为:
buf_pool_get_curr_size() / sizeof(void*) / 64,hash_table_t 的结构如下所示:
(gdb) p table
$37 = (hash_table_t *) 0x1aabfc8
(gdb) p *table
$38 = {
type = HASH_TABLE_SYNC_NONE,
adaptive = 0,
n_cells = 0,
array = 0x0,
n_sync_obj = 0,
sync_obj = {
mutexes = 0x0,
rw_locks = 0x0
},
heaps = 0x0,
heap = 0x0,
magic_n = 0
}
说明:
- 所有 buffer_pool instances 共享一个 AHI, 而不是每一个 buffer_pool instance 一个 AHI
- 5.7.8 之前 AHI 只有一个全局的锁结构 btr_search_latch, 当压力比较大的时候会出现性能瓶颈,5.7.8 对 AHI 进行了拆锁处理,详情可以参考函数:
btr_get_search_table() & btr_search_sys_create() - AHI 的 btr_search_latch (bug#62018) & index lock 是MySQL中两个比较大的锁,详情可以参考 Index lock and adaptive search – next two biggest InnoDB problems,5.7 通过对 AHI 锁拆分 (
5.7 commit id: ab17ab91) 以及引入不同的索引锁协议 (WL#6326) 解决了这两个问题。
【 AHI 构建条件 】
AHI 是建立在 search info & REC 内存地址之间的映射信息,在系统接受访问之前并没有足够的信息来建立 AHI 的映射信息,所以需要搜集 SQL 语句在执行过程中的 search_info & block info 信息并判断是否可以为数据页建立 AHI 缓存,其中:
search info 对应 btr_search_t, 用于记录 index 中的 n_fields (前缀索引列数) & n_bytes(last column bytes) 信息,这些被用于计算 fold 值;
block info 用于记录计算 fold 的值所需要的 fields & bytes 之外,还记录了在此情况下使用 AHI 在此数据页上潜在成功的次数;
我们简单的对 AHI 统计信息的几个方面进行简单的描述。
触发 AHI 索引统计的条件
SQL 语句在定位 cursor 的过程中会执行 btr_cur_search_to_nth_level 函数,当打开 AHI 的时候,在btr_cur_search_to_nth_level 返回之前会调用 btr_search_info_update 来更新相应的统计信息,如果当前的索引的 serch_info->hash_analysis < BTR_SEARCH_HASH_ANALYSIS (17),则对 search info & block info 不进行统计,否则则会调用 btr_search_info_update_slow 更新 search info & block info 信息,实现如下:
void btr_search_info_update(
/*===================*/
dict_index_t* index, /*!< in: index of the cursor */
btr_cur_t* cursor) /*!< in: cursor which was just positioned */
{
...
info->hash_analysis++;
if (info->hash_analysis < BTR_SEARCH_HASH_ANALYSIS) {
/* Do nothing */
return;
}
btr_search_info_update_slow(info, cursor);
}
AHI 中索引查询信息 (index->search_info) 的更新与自适应的过程
背景知识: btr_cur_search_to_nth_level 中在定位 cursor 的过程中会在树的每一层调用 page_cur_search_with_match 来确定下一个 branch 结点或叶子结点,page_cur_search_with_match 函数会将查询过程中比较的前缀索引列数 & 最后一列匹配的字节数记录至 {cursor->up_match, cursor->up_bytes, cursor->low_bytes, cursor->low_match},目的是为了保存与 search tuple 在比较过程时的最小比较单元,详细的计算过程可以参考 page_cur_search_with_match 的实现代码。
首先判断当前 index 是否为 insert buffer tree, 如果是 insert buffer, 则不进行 AHI 等相关的操作;
其次,如果当前索引的 info->n_hash_potential = 0,则会按照推荐算法从 {cursor->up_match, cursor->up_bytes, cursor->low_bytes, cursor->low_match} 推荐出前缀索引列数 & 最后一列的字节数用于计算 AHI 中存储的键 {ha_node_t->fold} 的值。
当 info->n_hash_potential != 0 时,则会判断当前查询匹配模式 & index->search_info 中保存的匹配模式是否发生变化,如果没有发生变化,则会增加此模式下潜在利用 AHI 成功的次数 (info->n_hash_potential),否则需要重新推荐前缀索引列等相关信息,并清空 info->n_hash_potential 的值(info->n_hash_potential = 0),AHI 就是利用这种方法来实现自适应的,所以在打开 AHI 的系统中不建议经常变换查询条件,前缀索引等信息的计算过程如下:
btr_search_info_update_hash
{
...
/* We have to set a new recommendation; skip the hash analysis
for a while to avoid unnecessary CPU time usage when there is no
chance for success */
info->hash_analysis = 0;
cmp = ut_pair_cmp(cursor->up_match, cursor->up_bytes,
cursor->low_match, cursor->low_bytes);
if (cmp == 0) {
info->n_hash_potential = 0;
/* For extra safety, we set some sensible values here */
info->n_fields = 1;
info->n_bytes = 0;
info->left_side = TRUE;
} else if (cmp > 0) {
info->n_hash_potential = 1;
if (cursor->up_match >= n_unique) {
info->n_fields = n_unique;
info->n_bytes = 0;
} else if (cursor->low_match < cursor->up_match) {
info->n_fields = cursor->low_match + 1;
info->n_bytes = 0;
} else {
info->n_fields = cursor->low_match;
info->n_bytes = cursor->low_bytes + 1;
}
info->left_side = TRUE;
} else {
info->n_hash_potential = 1;
if (cursor->low_match >= n_unique) {
info->n_fields = n_unique;
info->n_bytes = 0;
} else if (cursor->low_match > cursor->up_match) {
info->n_fields = cursor->up_match + 1;
info->n_bytes = 0;
} else {
info->n_fields = cursor->up_match;
info->n_bytes = cursor->up_bytes + 1;
}
info->left_side = FALSE;
}
}
由以上算法可以看出,选择{info->n_fields, info->n_bytes, info->left_side}的依据则是在不超过 unique index 列数的前提下,使其计算代价最小,而 index->info->left_side 的值则会决定存储同一数据页上相同前缀索引的最左记录还是最右记录。
数据页 block 信息的更新
数据页 block info 的更新主要包括数据页上的索引匹配模式、在已有索引匹配模式下成功的次数以及是否为该数据页建立 AHI 缓存信息的判断,其主要过程如下:
1) 将 index->info->last_hash_succ 设置为 FALSE, 此时其它线程无法使用该索引上 AHI 功能;
2) 如果 index->search_info 的匹配格式 & 该数据页上保存的匹配模式相同时,则增加此 block 使用 AHI 成功的次数 block->n_hash_helps, 如果已经为该数据页建立 AHI 缓存,则设置 index->info->last_hash_succ = TRUE;
3) 如果 index->search_info 的匹配格式 & 该数据页上保存的匹配模式不相同,则设置 block->n_hash_helps=1 且使用 index->search_info 对 block 上的索引匹配信息进行重新设置,详细过程可参考 btr_search_update_block_hash_info;
4) 判断是否需要为数据页建立 AHI 缓存,在数据页 block 上使用 AHI 成功的次数大于此数据页上用户记录的 1/16 且当前前缀索引的条件下使用 AHI 成功的次数大于 100 时, 如果此数据页使用 AHI 潜在成功的次数大于 2 倍该数据页上的用户记录或者当前推荐的前缀索引信息发生了变化的时,则需要为数据页构造 AHI 缓存信息,详情可参考以下代码;
if ((block->n_hash_helps > page_get_n_recs(block->frame)
/ BTR_SEARCH_PAGE_BUILD_LIMIT)
&& (info->n_hash_potential >= BTR_SEARCH_BUILD_LIMIT)) {
if ((!block->index)
|| (block->n_hash_helps > 2 * page_get_n_recs(block->frame))
|| (block->n_fields != block->curr_n_fields)
|| (block->n_bytes != block->curr_n_bytes)
|| (block->left_side != block->curr_left_side)) {
/* Build a new hash index on the page */
return(TRUE);
}
}
【 AHI 构建过程(收集 & 判断 & 建立)】
AHI 的构建过程指的是根据 index->search_info 构建查询条件 & 数据页的 hash 关系,其主要过程为:
1) 收集 hash 信息。遍历该数据页上的所有用户记录,建立由前缀索引信息 & 物理记录之间的映射关系的数组 {folds, recs},其中 index->info->left_side 用来判断在前缀索引列相同情况下如何保存物理页记录,从代码中可以得知:当 left_side 为 TRUE 时前缀索引列相同的记录只保存最左记录,当 left_side 为 FALSE 时前缀索引列相同的记录只保存最右记录,代码实现如下:
for (;;) {
next_rec = page_rec_get_next(rec);
if (page_rec_is_supremum(next_rec)) {
if (!left_side) {
folds[n_cached] = fold;
recs[n_cached] = rec;
n_cached++;
}
break;
}
offsets = rec_get_offsets(next_rec, index, offsets,
n_fields + (n_bytes > 0), &heap);
next_fold = rec_fold(next_rec, offsets, n_fields,
n_bytes, index->id);
if (fold != next_fold) {
/* Insert an entry into the hash index */
if (left_side) {
folds[n_cached] = next_fold;
recs[n_cached] = next_rec;
n_cached++;
} else {
folds[n_cached] = fold;
recs[n_cached] = rec;
n_cached++;
}
}
rec = next_rec;
fold = next_fold;
}
2) 如果之前该数据页已经存在 AHI 缓存信息但前缀索引信息与当前的信息不一致,则释放之前缓存的 AHI 信息,如果释放超过了一个 page size,则将释放的数据页退还给 buffer_pool->free 链表;
3) 调用 btr_search_check_free_space_in_heap 来确保 AHI 有足够的内存生成映射信息 ha_node_t {fold, data, next},该内存从 buffer_pool->free 链表获得,详情参考:buf_block_alloc(), fold 的值的计算可参考函数:rec_fold();
4) 由于操作过程中释放了 btr_search_latch,需要再次检查 block 上的AHI信息是否发生了变化,如果发生变化则退出函数;
5) 调用 ha_insert_for_fold 方法将之前收集的信息生成 ha_node_t, 并将其存放到 btr_search_sys->hash_table 的数组中,其中存放后的结构可以参考图 AHI memory structure;
for (i = 0; i < n_cached; i++) {
ha_insert_for_fold(table, folds[i], block, recs[i]);
}
【 AHI 使用条件及定位叶子结点过程 】
在 “AHI 在查询过程中的作用范围” 一节中我们详细的介绍了 MySQL 中 Server 层 & engine 层中的交互方式以及 AHI 在整个过程中的位置 & 作用,下面着要看一下在 步骤 2, 3 中 AHI 是如何工作的。
步骤 2 中,是使用 AHI 的一种 shortcut 查询方式,只有在满足很苛刻的条件后才能使用 AHI 的 shortcut 查询方式,这些苛刻条件包括:
1) 当前索引是 cluster index;
2) 当前查询是 unique search;
3) 当前查询不包含 blob 类型的大字段;
4) 记录长度不能大于 page_size/8;
5) 不是使用 memcache 接口协议的查询;
6) 事物开启且隔离级别大于 READ UNCOMMITTED;
7) 简单 select 查询而非在 function & procedure;
在满足以上条件后才能使用 AHI 的 shortcut 查询方式定位叶子结点,5.7 中满足条件后的操作可以简单的描述为:
rw_lock_s_lock(btr_get_search_latch(index));
...
row_sel_try_search_shortcut_for_mysql()
...
rw_lock_s_lock(btr_get_search_latch(index));
步骤 3 中使用 AHI 快速定位叶子结点同样需要满足一些条件,具体可以参考代码:btr_cur_search_to_nth_level(),在此不再累述,我们着重分析一下使用 AHI 定位叶子节点的过程。
1) 对 index 所在的 hash_table 上锁,使用查询条件中的 tuple 信息计算出键值 fold;
rw_lock_s_lock(btr_search_get_latch(index));
fold = dtuple_fold(tuple, cursor->n_fields, cursor->n_bytes, index_id);
2) 在 hash_table 上进行查找 key = fold 的 ha_node_t;
const rec_t*
ha_search_and_get_data(
/*===================*/
hash_table_t* table, /*!< in: hash table */
ulint fold) /*!< in: folded value of the searched data */
{
ha_node_t* node;
hash_assert_can_search(table, fold);
ut_ad(btr_search_enabled);
node = ha_chain_get_first(table, fold);
while (node) {
if (node->fold == fold) {
return(node->data);
}
node = ha_chain_get_next(node);
}
return(NULL);
}
rec = (rec_t*) ha_search_and_get_data(btr_search_get_hash_table(index), fold);
3) 释放锁资源并根据返回的记录定位叶子结点;
block = buf_block_align(rec);
rw_lock_s_unlock(btr_search_get_latch(index));
btr_cur_position(index, (rec_t*) rec, block, cursor);
4) 定位到叶子结点后的过程和不使用 AHI 之后的过程类似,直接返回记录并记录 cursor 位置;
AHI 维护 & 监控
MySQL 5.7 中有两个 AHI 相关的参数,分别为:innodb_adaptive_hash_index, innodb_adaptive_hash_index_parts,其中 innodb_adaptive_hash_index 为动态调整的参数,用以控制是否打开 AHI 功能;innodb_adaptive_hash_index_parts 是只读参数,在实例运行期间是不能修改,用于调整 AHI 分区的个数(5.7.8 引入),减少锁冲突,详细介绍可以参考官方说明:innodb_adaptive_hash_index, innodb_adaptive_hash_index,本节主要介绍操作 AHI 的相关命令以及命令的内部实现过程。
1) 打开 AHI 操作 & 内部实现
set global innodb_adaptive_hash_index=ON,此命令只是对全局变量进行设置,代码实现如下:
Enable the adaptive hash search system. */
UNIV_INTERN
void
btr_search_enable(void)
/*====================*/
{
btr_search_x_lock_all();
btr_search_enabled = TRUE; /* global variables which indicate whether AHI can be used */
btr_search_x_unlock_all();
}
2) 关闭 AHI 操作 & 内部实现
set global innodb_adaptive_hash_index= OFF,此命令用于关闭 AHI 功能,具体实现可参考 btr_search_disable(), 关闭流程说明:
- 设置 btr_search_enabled = FALSE,关闭 AHI 功能
- 将数据字典中所有缓存的表对象的 ref_count 设置为0,只有
btr_search_info_get_ref_count(info, index) = 0的情况下才能清除数据字典中的缓存对象,详情见dict_table_can_be_evicted() - 将所有数据页中的统计信息置空,具体实现可参考
buf_pool_clear_hash_index() - 释放 AHI 所使用的 buffer_pool 的内存,
btr_search_disable具体实现如下:
Disable the adaptive hash search system and empty the index. */
UNIV_INTERN
void
btr_search_disable(void)
/*====================*/
{
dict_table_t* table;
ulint i;
mutex_enter(&dict_sys->mutex);
btr_search_x_lock_all();
btr_search_enabled = FALSE;
/* Clear the index->search_info->ref_count of every index in
the data dictionary cache. */
for (table = UT_LIST_GET_FIRST(dict_sys->table_LRU); table;
table = UT_LIST_GET_NEXT(table_LRU, table)) {
btr_search_disable_ref_count(table);
}
for (table = UT_LIST_GET_FIRST(dict_sys->table_non_LRU); table;
table = UT_LIST_GET_NEXT(table_LRU, table)) {
btr_search_disable_ref_count(table);
}
mutex_exit(&dict_sys->mutex);
/* Set all block->index = NULL. */
buf_pool_clear_hash_index();
/* Clear the adaptive hash index. */
for (i = 0; i < btr_search_index_num; i++) {
hash_table_clear(btr_search_sys->hash_tables[i]);
mem_heap_empty(btr_search_sys->hash_tables[i]->heap);
}
btr_search_x_unlock_all();
}
3) AHI 缓存信息的维护
AHI 维护的是 search info & REC 在物理内存地址的 hash 关系,当物理记录的位置或者所在 block 的地址发生变化时,AHI 也需要对其进行相应的维护,如新记录的的插入,表记录的的删除,数据页的分裂,drop table & alter table,LRU 换页等都需要对 AHI 进行相应的维护,详情可参考函数 btr_search_update_hash_ref() & btr_search_drop_page_hash_index() & buf_LRU_drop_page_hash_for_tablespace()的实现;
4) AHI 信息的监控
AHI 默认情况下只对 adaptive_hash_searches (使用 AHI 方式查询的次数) & adaptive_hash_searches_btree (使用 bree 查询的次数,需要遍历 branch 结点) 进行监控,更详细的监控需要进行额外的设置,详细设置方法可参考 innodb_monitor_enable & module_adaptive_hash ,打开 AHI 的监控方法、使用监控、重置监控的方法如下:
MySQL [information_schema]> set global innodb_monitor_enable = module_adaptive_hash;
Query OK, 0 rows affected (0.00 sec)
MySQL [information_schema]> select status, name, subsystem,count, max_count, min_count, avg_count, time_enabled, time_disabled from INNODB_METRICS where subsystem like '%adaptive_hash%';
+---------+------------------------------------------+---------------------+--------+-----------+-----------+--------------------+---------------------+---------------+
| status | name | subsystem | count | max_count | min_count | avg_count | time_enabled | time_disabled |
+---------+------------------------------------------+---------------------+--------+-----------+-----------+--------------------+---------------------+---------------+
| enabled | adaptive_hash_searches | adaptive_hash_index | 259530 | 259530 | NULL | 1663.6538461538462 | 2016-12-16 14:03:07 | NULL |
| enabled | adaptive_hash_searches_btree | adaptive_hash_index | 143318 | 143318 | NULL | 918.7051282051282 | 2016-12-16 14:03:07 | NULL |
| enabled | adaptive_hash_pages_added | adaptive_hash_index | 14494 | 14494 | NULL | 127.14035087719299 | 2016-12-16 14:03:49 | NULL |
| enabled | adaptive_hash_pages_removed | adaptive_hash_index | 0 | NULL | NULL | 0 | 2016-12-16 14:03:49 | NULL |
| enabled | adaptive_hash_rows_added | adaptive_hash_index | 537933 | 537933 | NULL | 4718.710526315789 | 2016-12-16 14:03:49 | NULL |
| enabled | adaptive_hash_rows_removed | adaptive_hash_index | 0 | NULL | NULL | 0 | 2016-12-16 14:03:49 | NULL |
| enabled | adaptive_hash_rows_deleted_no_hash_entry | adaptive_hash_index | 0 | NULL | NULL | 0 | 2016-12-16 14:03:49 | NULL |
| enabled | adaptive_hash_rows_updated | adaptive_hash_index | 0 | NULL | NULL | 0 | 2016-12-16 14:03:49 | NULL |
+---------+------------------------------------------+---------------------+--------+-----------+-----------+--------------------+---------------------+---------------+
8 rows in set (0.00 sec)
MySQL [information_schema]> set global innodb_monitor_reset_all='adaptive_hash_%';
Query OK, 0 rows affected (0.00 sec)
MySQL [information_schema]> set global innodb_monitor_disable='adaptive_hash%';
Query OK, 0 rows affected (0.00 sec)
MySQL [information_schema]> select status, name, subsystem,count, max_count, min_count, avg_count, time_enabled, time_disabled from INNODB_METRICS where subsystem like '%adaptive_hash%';
+----------+------------------------------------------+---------------------+-------+-----------+-----------+-----------+--------------+---------------+
| status | name | subsystem | count | max_count | min_count | avg_count | time_enabled | time_disabled |
+----------+------------------------------------------+---------------------+-------+-----------+-----------+-----------+--------------+---------------+
| disabled | adaptive_hash_searches | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
| disabled | adaptive_hash_searches_btree | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
| disabled | adaptive_hash_pages_added | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
| disabled | adaptive_hash_pages_removed | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
| disabled | adaptive_hash_rows_added | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
| disabled | adaptive_hash_rows_removed | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
| disabled | adaptive_hash_rows_deleted_no_hash_entry | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
| disabled | adaptive_hash_rows_updated | adaptive_hash_index | 0 | NULL | NULL | NULL | NULL | NULL |
+----------+------------------------------------------+---------------------+-------+-----------+-----------+-----------+--------------+---------------+
8 rows in set (0.00 sec)
值得一提的是只有执行 set global innodb_monitor_reset_all='adaptivehash%' & set global innodb_monitor_disable='adaptive_hash%' 才对状态进行重置,如果发现 adaptive_hash_searches << adaptive_hash_searches_btree 的时候,则应该关闭 AHI 以减少不必要的系统消耗。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号