kubernetes 中 kafka 和 zookeeper 有状态集群服务部署实践 (二)
原创
kubernetes 中 kafka 和 zookeeper 有状态集群服务部署实践 (二)
原创
腾讯云容器服务团队
修改于 2017-09-07 11:09:49
修改于 2017-09-07 11:09:49
引言
Kafka和zookeeper是在两种典型的有状态的集群服务。首先kafka和zookeeper都需要存储盘来保存有状态信息,其次kafka和zookeeper每一个实例都需要有对应的实例Id(Kafka需要broker.id,zookeeper需要my.id)来作为集群内部每个成员的标识,集群内节点之间进行内部通信时需要用到这些标识。
在上文中,已经介绍了如何基于StatefulSet(PetSet)+Persistent Volume搭建kafka和zookeeper服务。本文将介绍如何基于腾讯云容器服务已经支持的CBS(Cloud Block Storage)存储和Headless Service创建kafka和zookeeper有状态集群服务。
方案整体介绍
目前腾讯云容器服务支持在服务的Pod上挂载CBS盘,Pod异常挂掉后,kubernetes会重新创建新的Pod,此时CBS盘也会随着Pod迁移。通过这种方式,可以使用CBS盘来存储服务实例的状态信息。
Headless服务支持通过服务的域名解析得到服务所有实例的IP,如果服务实例数为1,则可以得到服务对应实例的IP。
这样在zookeeper和kafka服务创建时,将每一个服务实例拆分成一个独立的服务。这样每个服务实例可以单独设置环境变量,配置zookeeper和kafka服务实例需要的实例Id。通过在每个服务实例上挂载CBS盘,则可以存储服务实例的状态信息。通过Headless服务,服务实例之间可以通过Pod的IP直接访问。
具体的方案架构如下图所示:
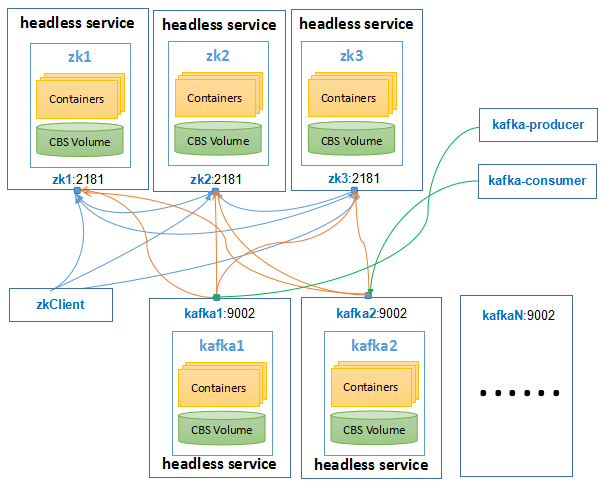
zookeeper服务创建
如整体方案图所示,将zookeeper服务每个实例拆分成对应的headless服务,默认实例数为3,分别为服务zk1,zk2,zk3。目前容器服务暂时不支持创建headless service,这里先在控制台的服务页面创建deployment(zk1,zk2,zk3)。然后再通过命令行创建对应的headless service。后期,支持在控制台直接创建headless service从而可以直接创建对应的服务实例。
创建对应的Deployment
第一步: 选择对应的数据卷

由于容器中将zookeeper程序和zookeeper的数据存放到了不同目录。所以需要选择挂载两个不同的目录。其中zookeeper日志目录较小使用一个30G左右的小容量CBS盘。
第二步: 选择镜像
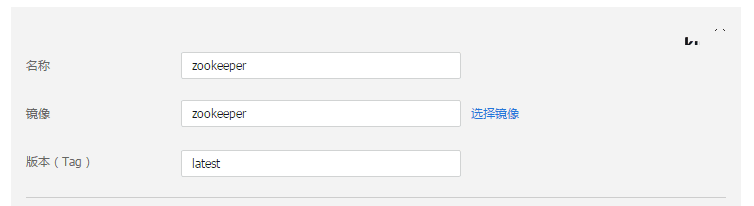
选择zookeeper tag为latest的公有镜像。
第三步: 设置环境变量

由于zookeeper服务的不同示例是单独部署的,所以可对不同服务实例设置不同的环境变量。zookeeper服务需要设置的环境变量为ZOO_MY_ID,ZOO_SERVERS。其中ZOO_MY_ID设置为对应的每个实例的id。ZOO_SERVERS都设置成server.1=zk1:2888:3888 server.2=zk2:2888:3888 server.3=zk3:2888:3888。其中(zk1,zk2,zk3)为拆分后的服务名称。
第四步: 设置数据卷的挂载点

在容器中分别将data盘和datalog盘,映射到/data目录和/datalog目录
第五步: 选择服务的访问方式

由于只希望创建deployment,所有这里选择不启用服务访问方式。后期可以支持直接选择headless方式访问。具体的服务访问方式介绍可以参考服务访问方式设置。
在控制台中依次创建zk1,zk2,zk3这三个服务,创建完成后通过命令行可以查看到对应的deployment信息。
# kubectl get deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
zk1 1 1 1 1 55m
zk2 1 1 1 1 43m
zk3 1 1 1 1 40m创建对应的headless service
在创建完deployment后,可以创建对应的headless service来提供Pod和Pod之间直接的访问能力。zookeeper headless service 创建的示例如下:
apiVersion: v1
kind: Service
metadata:
labels:
qcloud-app: zk1
name: zk1
namespace: default
spec:
clusterIP: None
ports:
- name: tcp-2181-2181-onwfi
port: 2181
selector:
qcloud-app: zk1
sessionAffinity: None
type: ClusterIP依次创建zk1,zk2,zk3对应的headless service
# kubectl create -f zk1.service.yaml
service "zk1" created
# kubectl get service
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
zk1 None <none> 2181/TCP 33m
zk2 None <none> 2181/TCP 28m
zk3 None <none> 2181/TCP 7s查询对应的Pod信息如下:
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
zk1-2444207826-3g0s1 1/1 Running 0 29m 172.31.0.5 10.0.0.34
zk2-2923476994-7lfve 1/1 Running 0 29m 172.31.1.5 10.0.0.42
zk3-459250537-9k0kg 1/1 Running 0 10m 172.31.0.7 10.0.0.34查看dns中的域名信息
$ dig @172.31.1.2 zk1.default.svc.cluster.local
;; ANSWER SECTION:
zk1.default.svc.cluster.local. 30 IN A 172.31.0.5
$ dig @172.31.1.2 zk2.default.svc.cluster.local
;; ANSWER SECTION:
zk2.default.svc.cluster.local. 30 IN A 172.31.1.5
$ dig @172.31.1.2 zk3.default.svc.cluster.local
;; ANSWER SECTION:
zk3.default.svc.cluster.local. 30 IN A 172.31.0.7对zookeeper集群进行简单测试
这样zookeeper的服务就搭建完成。下面登录到zookeeper服务对应的Pod中,下面进行简单的测试。
bash-4.3# zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 2] create /tst 111
Created /tst
[zk: localhost:2181(CONNECTED) 3] ls /
[zookeeper, tst]kafka服务创建
zookeeper服务搭建完成后,开始采用同样的方式搭建kafka服务。
创建对应的Deployment
第一步: 选择对应的数据卷

在这里,由于容器中将kafka的日志和kafka的数据存放到了不同目录。所以需要选择挂载两个不同的目录。其中kafka程序的日志数据量较少,使用一个30G左右的小容量CBS盘。
注意:由于在kafka的镜像中,会对KAFKA*这样的环境变量进行解析,为了避免错误的解析,所有特意将服务名称设置成ckafka。
第二步: 选择对应的镜像
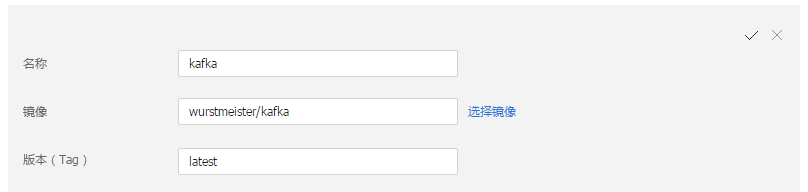
按照上图创建服务,选择wurstmeister/kafka tag为latest的公有镜像。
第三步: 设置环境变量
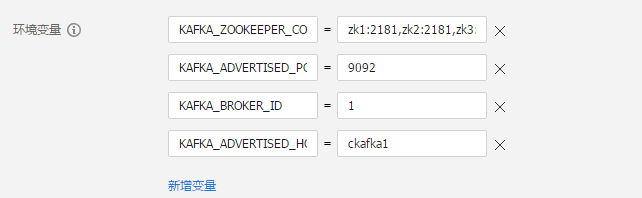
由于kafka服务的不同示例是单独部署的,所以可对不同服务实例设置不同的环境变量。kafka设置的环境变量如下所示:
KAFKA_ZOOKEEPER_CONNECT=zk1:2181,zk2:2181,zk3:2181/kafka
KAFKA_ADVERTISED_PORT=9092
KAFKA_BROKER_ID=1
KAFKA_ADVERTISED_HOST_NAME=ckafka1其中KAFKA_BROKER_ID和KAFKA_ADVERTISED_HOST_NAME根据服务实例的不同,需要设置不同的值。
第四步: 设置数据卷的挂载点
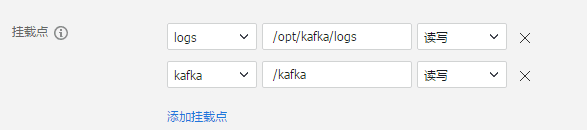
第五步: 选择服务的访问方式

同zookeeper的部署选择不启用服务访问方式。
创建对应的headless service
在创建完deployment后,可以创建对应的headless service来提供Pod和Pod之间直接的访问能力。kafka headless service创建的示例如下:
apiVersion: v1
kind: Service
metadata:
labels:
qcloud-app: ckafka1
name: ckafka1
namespace: default
spec:
clusterIP: None
ports:
- name: tcp-9092-9092-3ove1
port: 9092
selector:
qcloud-app: ckafka1
sessionAffinity: None
type: ClusterIP依次创建ckafka11,ckafka12,ckafka13对应的headless service
# kubectl create -f ckafka1.service.yaml
service "ckafka1" created
# kubectl get service
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ckafka1 None <none> 9092/TCP 2h
ckafka2 None <none> 9092/TCP 2h
ckafka3 None <none> 9092/TCP 2h查询对应的Pod信息如下:
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
ckafka1-3481659676-3j2f8 1/1 Running 0 15h 172.31.2.6 10.0.0.30
ckafka2-2214717934-e3yj9 1/1 Running 0 2h 172.31.2.7 10.0.0.30
ckafka3-2797922667-fhkaa 1/1 Running 0 2h 172.31.1.6 10.0.0.42查看dns中的域名信息
$ dig @172.31.1.2 ckafka1.default.svc.cluster.local
;; ANSWER SECTION:
ckafka1.default.svc.cluster.local. 30 IN A 172.31.2.6
$ dig @172.31.1.2 ckafka2.default.svc.cluster.local
;; ANSWER SECTION:
ckafka2.default.svc.cluster.local. 30 IN A 172.31.2.7
$ dig @172.31.1.2 ckafka3.default.svc.cluster.local
;; ANSWER SECTION:
ckafka3.default.svc.cluster.local. 30 IN A 172.31.1.6对kafka服务进行简单的测试:
创建topic测试
bash-4.3# kafka-topics.sh --create \
> --topic test2 \
> --zookeeper zk1:2181,zk2:2181,zk3:2181/kafka \
> --partitions 3 \
> --replication-factor 2
Created topic "test2".创建生产消费测试
bash-4.3# kafka-console-consumer.sh --topic test2 --bootstrap-server localhost:9092
bash-4.3# kafka-console-producer.sh --topic test2 --broker-list localhost:9092
hello world
Listen the world
#在消费者侧显示为:
hello world
Listen the world扩容操作
对于kafka的扩容,可以通过增加一个服务的方式扩容。在本例中增加ckafka4服务,将kafka实例数增加到4个。
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
ckafka1-3481659676-3j2f8 1/1 Running 0 17h 172.31.2.6 10.0.0.30
ckafka2-2214717934-e3yj9 1/1 Running 0 3h 172.31.2.7 10.0.0.30
ckafka3-2797922667-fhkaa 1/1 Running 0 3h 172.31.1.6 10.0.0.42
ckafka4-1279846962-dh4u4 1/1 Running 0 2m 172.31.2.8 10.0.0.30
# kubectl get service
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ckafka1 None <none> 9092/TCP 3h
ckafka2 None <none> 9092/TCP 3h
ckafka3 None <none> 9092/TCP 3h
ckafka4 None <none> 9092/TCP 8m创建一个4个副本的topic测试
kafka-topics.sh --create \
--topic test3 \
--zookeeper zk1:2181,zk2:2181,zk3:2181/kafka \
--partitions 3 \
--replication-factor 4
Created topic "test3".说明kafka实例个数,已经从3个扩容到了4个。
总结
通过Pod上挂载CBS盘的方式,能够存储有状态服务中的状态信息。同时通过将服务实例拆分成对应一个个的服务,可以单独对服务实例配置对应的Id信息,从而对服务实例进行标识。再结合Headless Service实现服务实例之间,直接通过域名进行访问。这种方式,对比StatefulSet(PetSet)的方式不需要依赖底层的Persistent Volume和Persistent Volume Cliam机制。同时,可以对单个服务实例进行升级和配置变更,升级和配置变更更加灵活。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号