PostgreSQL 的空闲数据块管理机制解析
原创
PostgreSQL 的空闲数据块管理机制解析
原创
腾讯云数据库团队
修改于 2017-08-15 11:25:39
修改于 2017-08-15 11:25:39
导语
在上一篇文章《PostgreSQL的MVCC机制解析》结尾处讲到PostgreSQL是通过vacuum命令来处理过期数据,本文将继续对vacuum命令做介绍,并以此引出PostgreSQL空闲数据块的产生,然后对空闲数据块管理机制的原理做解析。
数据块空闲空间的产生
根据PostgreSQL的MVCC机制,所有UPDATE和DELETE操作都会产生过期数据,需要通过vacuum命令来清理过期数据。vacuum命令基本上有两种:
- VACUUM 将过期tuple对应的磁盘空间标记为可用,但不会真正释放空间给操作系统,其他程序无法再利用。该操作执行时不会要求排它锁(EXCLUSIVE LOCK),不影响表读写操作。
- VACUUM FULL 将正常的tuple数据拷贝到新磁盘文件中,重新组织,将原数据文件删除,未使用的磁盘空间退还给操作系统,该操作执行时需要获取排它锁,会影响正常的读写操作。因此执行该操作时需要慎重,特别是表数据量较大时,执行时间会比较长。
我们知道PostgreSQL的表(Relation)实际上是由多个物理数据块(页)组成,当执行vacuum操作后,这些数据块中的保存有过期记录(tuple)的磁盘空间就会被标记为可用,就会产生空闲空间。
当新增记录(tuple)时,会优先重新利用表中数据块的空闲空间,而不是分配一个新的数据块。然而当多个数据块都有空闲空间时,该选取哪个数据块来保存新记录呢?被选取的记录必须要能够有足够的空间存放新记录。
空闲数据块的组织结构
为解决以上问题,PostgreSQL设计了FSM(Free Space Map)结构来表示各个数据块中空闲磁盘空间的大小。在pg8.4版本之后,每个表(Relation)都会独立的FSM空间,具体表现为以_fsm为后缀的物理文件:
-bash-4.2$ cd $PGDATA/ins2/base
-bash-4.2$ ll *fsm
-rw------- 1 postgres postgres 24576 Jun 26 15:40 1247_fsm
-rw------- 1 postgres postgres 24576 Jun 26 15:40 1249_fsm
-rw------- 1 postgres postgres 24576 Jun 26 15:40 1255_fsm
FSM文件的存储结构如下所示:
为了快速搜索到合适数据块,减少因搜索带来的IO开销(即节省FSM文件大小),FSM结构只使用一个字节来记录一个数据块中的空闲磁盘空闲大小,因1byte=8bits,那么就可以记录2^8种空闲磁盘大小,假设一个数据块大小(BLCKSZ)为8k(PostgreSQL默认为8k),那么就可以划分成256(2^8)等份,每份有BLCKSZ/256字节来表示范围,示例如下:
Range Category
0 - 31 0
32 - 63 1
... ... ...
8096 - 8127 253
8128 - 8163 254
8164 - 8192 255
FSM数据块内的数据结构
知道了数据块中空闲空间大小的表示方法,那如何来组织这些表示记录,保持高效查询效率呢?答案是PostgreSQL使用了一种二叉树结构(大根堆)来存储这些表示空闲空间大小的记录,叶子节点存储实际的空间大小记录,非叶子节点只是作为辅助查询。当需要查询是否有合适的数据块大小时,只需要先比较树的根节点即可知道,大大减少了查询次数。大根堆数据结构示例如下:
4
4 2
3 4 0 2 <- This level represents heap pages
上述例子中叶子节点的值3,4,0,2分别代表了空闲数据块的map值,值3代表的就是空闲磁盘空间大小在[96,127]的数据块。PostgreSQL源码中FSM页数据结构定义如下:
typedef struct
{
int fp_next_slot;
uint8 fp_nodes[FLEXIBLE_ARRAY_MEMBER];
} FSMPageData;
其中,fp_next_slot指向的是下一次查询开始的slot位置,具体作用稍后阐述,fp_nodes数组存储二叉树的节点值。FSM数据块内的数据存储结构类似如下图所示:
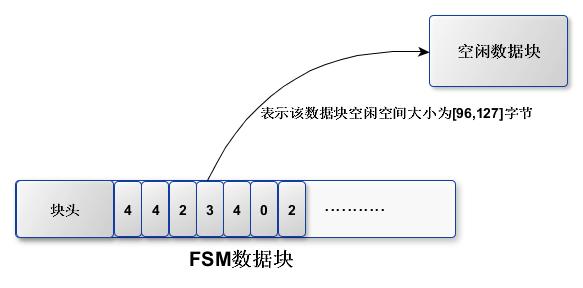
按照这种存储结构,一个FSM数据块(存储FSM记录的数据块,和普通数据块大小是一致的)可以存储的实际记录数(数据块的空闲空间大小对应的map value)为:
(BLCKSZ - headers) / 2 //除以2是因为二叉树的叶子节点数约为总节点数的1/2
其中,BLCKSZ表示数据块大小,headers表示数据块固定大小的头部信息。如果按照数据块默认大小8k,那么单个FSM数据块可存储的记录数大约为4000个,另外,PostgreSQL中一个表(Relation)最多可以有2^32个数据块,那么最多就需要2^32条map记录来表示这些数据块中拥有的空闲空间大小,显然,单个FSM数据块是无法存储下这些记录,实际需要约2^32/4000个FSM数据块来存储。
前面我们介绍了单个FSM数据块内的存储map值的数据结构,当有多个FSM数据块时,但是我们又该按照什么顺序去选择FSM数据块页来搜索呢?顺序查找FSM数据块显然效率太低。
FSM数据块间的逻辑组织结构
为了提升查找FSM数据块的效率,PostgreSQL采用Higher-level(类似多叉树)的逻辑结构来组织FSM数据。为每个FSM数据块指定一个额外的逻辑结构FSMAddress,数据结构定义如下:
#define FSM_TREE_DEPTH ((SlotsPerFSMPage >= 1626) ? 3 : 4)
#define FSM_ROOT_LEVEL (FSM_TREE_DEPTH - 1)
#define FSM_BOTTOM_LEVEL 0
typedef struct
{
int level; /* level */
int logpageno; /* page number within the level */
} FSMAddress;
其中,level表示该FSM数据块所处的层号,logpageno表示在该层中的序号,序号从0开始。类似于FSM单个数据块内的存储方式,只有在最底层(level=0)的FSM数据块才实际存储记录,其它层作为查询的辅助层,上层的叶子节点值代表了下层的根节点值。
那需要多少层逻辑结构才能表示所有的数据块记录呢,答案是当一个FSM数据块内存储超过1626条记录(map value)时,采用三层即可,因为162616261626>=2^32。
下面用一个示意图来表示整体的组织结构,为了让示意图简化,只在图中每个数据块存放4个字节的数据,这和存放1626个字节原理是一致的。FSM文件各数据块间逻辑组织结构示意图如下:
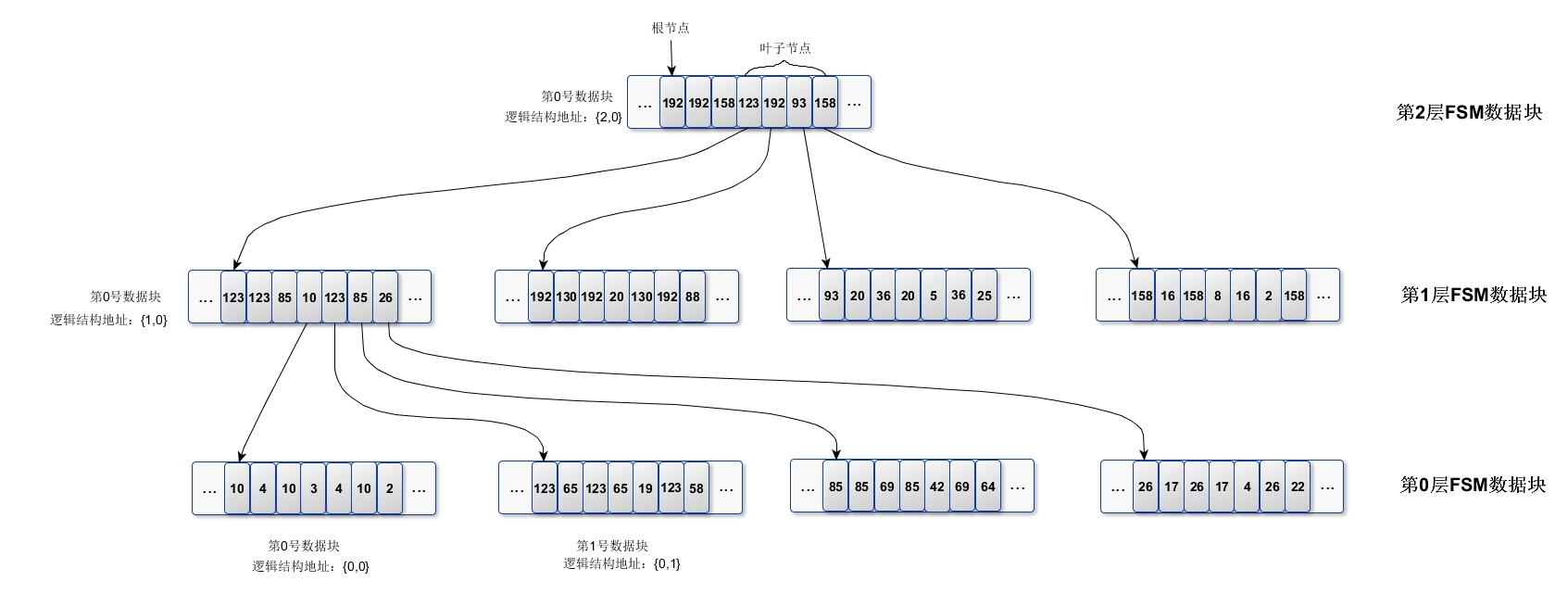
如图所示,第2层数据块中叶子节点值123就代表了它下一层(第1层)第0号数据块的根节点值,而第1层第0号数据块的叶子节点值123则代表的是第0层第1号数据块的根节点,第0层第1号数据块的叶子节点值123代表的是空闲空间大小为[3936,3967]字节的数据块。每个数据块都有逻辑地址,如第1号数据块的逻辑地址{1,0}表示第1层的第0号FSM数据块,实际上是对应的FSM物理文件的第1号数据块。第2层和第1层的FSM数据块内存储的数据都只是作为辅助层索引,实际上只有第0层FSM数据块内的叶子节点才存储着表中空闲数据块的map值,其他节点均是索引值。
空闲数据块的搜索算法
上面介绍了空闲数据块的表示方法和FSM文件中各数据块的组织形式,接下来将介绍空闲空间数据块的搜索算法。
首先,先介绍FSM数据块内的查找算法。对于大根堆二叉树查找,简单的方法就是每次从root节点开始比较查找,如果root节点小于待查找值,则表示该块内没有满足条件的map value,否则可以继续向下找到一个满足条件的叶子节点。但是PostgreSQL的设计并不是这样的,而是通过之前介绍的FSMPageData结构体的fp_next_slot来保存下一次查询的起点位置(slot),搜索算法如下:
- 比较根节点值,如果待查询值大于根节点,则直接返回,表示该FSM数据块内没有满足条件的map值,否则进行下一步。
- 比较查询的起点位置(slot)对应的map值,如果不满足条件,则进行下一步,否则跳到第5步。
- 设置新查询位置为下一个slot(slot序号+1,slot值代表了在叶子节点的顺序号)的父节点,再比较,如果不满足条件则重复该步骤,直到向上查找到根节点。如果找到满足条件的中间节点,则进行下一步。
- 向下查找,找到满足条件的叶子节点,然后进行下一步。
- 重新设置下一次查询的fp_next_slot变量,然后返回该叶子节点的slot。
FSM数据块内搜索算法的核心源码如下:
int
fsm_search_avail(Buffer buf, uint8 minvalue, bool advancenext,
bool exclusive_lock_held)
{
......
restart:
if (fsmpage->fp_nodes[0] < minvalue) //每次查询先检查根节点是否满足条件
return -1;
target = fsmpage->fp_next_slot;
if (target < 0 || target >= LeafNodesPerPage)
target = 0;
target += NonLeafNodesPerPage;
nodeno = target; //开始查询时的slot位置
while (nodeno > 0)
{
if (fsmpage->fp_nodes[nodeno] >= minvalue)
break;
nodeno = parentof(rightneighbor(nodeno)); //返回下一个slot的父节点位置
}
while (nodeno < NonLeafNodesPerPage) //向下查找到叶子节点
{
int childnodeno = leftchild(nodeno); //先查看左子节点
if (childnodeno < NodesPerPage &&
fsmpage->fp_nodes[childnodeno] >= minvalue)
{
nodeno = childnodeno;
continue;
}
childnodeno++; //左子节点不满足条件查找右子节点
if (childnodeno < NodesPerPage &&
fsmpage->fp_nodes[childnodeno] >= minvalue)
{
nodeno = childnodeno;
}
else
{
//都没找到,说明当前可能存在"torn page"的情况( IO写磁盘数据时出现crash,只有部分数据写入)
//重新更新页数据后再查询
.......
fsm_rebuild_page(page);
......
goto restart;
}
}
slot = nodeno - NonLeafNodesPerPage; //找到slot序号
fsmpage->fp_next_slot = slot + (advancenext ? 1 : 0); //保存下一次查询开始的slot位置
return slot;
}
至此,就找到了该FSM数据块中满足条件的叶子节点,如果该页不是处在第0层,则该叶子节点并不是我们最终查询目标,根据前述FSM数据块间的组织结构可知,辅助层中叶子节点对应的是下一层FSM数据块的根节点,因此,需要继续向下查找到第0层的对应叶子节点。查找叶子节点对应下一层的数据块则是通过返回的slot值来计算的,核心查找算法源码如下:
for (;;){
......
slot = fsm_search_avail(buf, min_cat, (addr.level == FSM_BOTTOM_LEVEL), false);
......
if (slot != -1) //找到满足条件的叶子节点,否则退出循环
{
if (addr.level == FSM_BOTTOM_LEVEL) //查找到第0层,返回结果
return fsm_get_heap_blk(addr, slot);
addr = fsm_get_child(addr, slot); //非第0层,继续查找子树
}
......
}
static FSMAddress
fsm_get_child(FSMAddress parent, uint16 slot)
{
FSMAddress child;
Assert(parent.level > FSM_BOTTOM_LEVEL);
child.level = parent.level - 1;
child.logpageno = parent.logpageno * SlotsPerFSMPage + slot; //根据上一层的slot查找下层对应数据页的logpageno
return child;
}
整个搜索算法就介绍完毕,至于为什么要把fp_next_slot来作为起始查询位置而不是root节点呢?原因有几点:
- 当有多个后端连接同时新增tuple时,可以尽量避免对同一数据块的写冲突,提高写并行度。如果每次都从root节点开始查找,有可能多个查询都同时查找到同一个数据块。
- 获取的是上一次返回查询结果的临近数据块,更有利于提升磁盘IO效率。
更新空闲数据块空间大小
查找到表中合适的空闲数据块后,新记录会写入该数据块,然后需要更新该数据块的空闲空间大小。相较于搜索,更新相对简单,核心思想就是先重新计算该空闲数据块的map值,然后更新在FSM数据块中对应叶子节点的值,再以“冒泡”的方式向上不断更新,直到更新到父节点值不变化或者root节点。核心源码如下:
fsmpage->fp_nodes[nodeno] = value; //更新当前节点
do
{
......
nodeno = parentof(nodeno);
lchild = leftchild(nodeno);
rchild = lchild + 1;
newvalue = fsmpage->fp_nodes[lchild];
if (rchild < NodesPerPage) //右子节点存在,则选取最大值作为父节点的新值
newvalue = Max(newvalue, fsmpage->fp_nodes[rchild]);
oldvalue = fsmpage->fp_nodes[nodeno];
if (oldvalue == newvalue) //检查更新后父节点是否有变化
break;
fsmpage->fp_nodes[nodeno] = newvalue; //有变化,更新父节点,继续向上更新
} while (nodeno > 0); //更新到root节点退出
锁
搜索空闲数据块时只会对当前搜索的FSM数据块加共享锁(shared buffer locks),更新FSM数据块时才会加排它锁(exclusive buffer lock)。这里值得注意的一点是在搜索时,使用了fp_next_slot变量来表示下一次搜索的起点位置,并没有为之加一个排它锁,因为维持一个排它锁的代价远比fp_next_slot变量出现异常后的代价大很多。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号