大数据必学Java基础(五十九):Map接口源码部分
原创
大数据必学Java基础(五十九):Map接口源码部分
原创
Lansonli
发布于 2022-09-30 00:52:05
发布于 2022-09-30 00:52:05
Map接口源码部分
一、HashMap
1、代码展示特性
package com.lanson.test03;
import java.util.HashMap;
/**
* @author : Lansonli
*/
public class Test {
//这是main方法,程序的入口
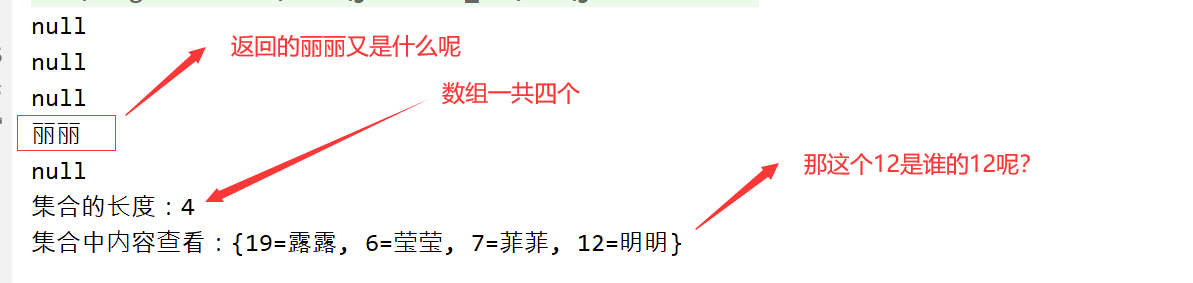
public static void main(String[] args) {
//JDK1.7以后支持后面的<>中内容可以不写
HashMap<Integer,String> hm = new HashMap<>();
System.out.println(hm.put(12,"丽丽"));
System.out.println(hm.put(7,"菲菲"));
System.out.println(hm.put(19,"露露"));
System.out.println(hm.put(12,"明明"));
System.out.println(hm.put(6,"莹莹"));
System.out.println("集合的长度:"+hm.size());
System.out.println("集合中内容查看:"+hm);
}
}结果展示:
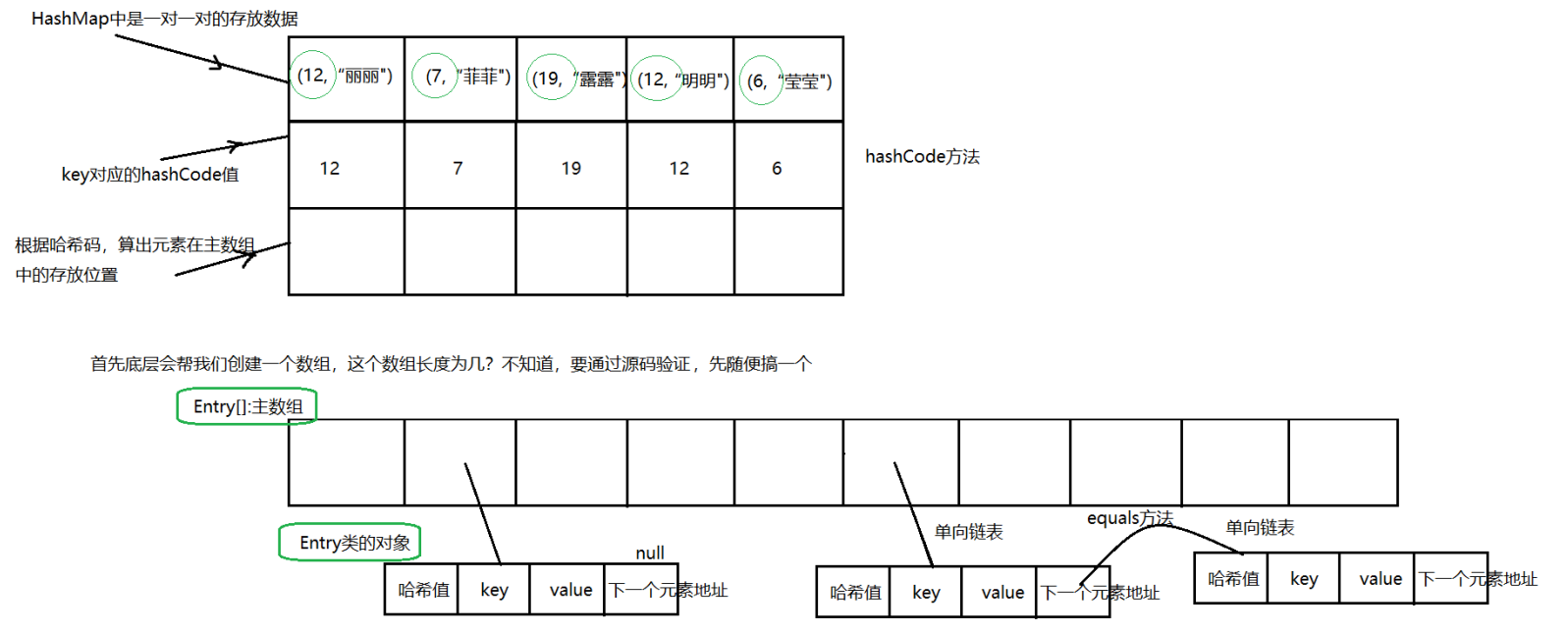
2、先演示原理
先演示原理图,再看源码,直接看的话,有的人接不上就蒙了:
相当于先看原理,然后从源码中验证这个原理是否正确:把图搞懂了,就是事倍功半的效果
原理如下:(JDK1.7)
3、源码(JDK1.7版本)
public class HashMap<K,V>
extends AbstractMap<K,V> //【1】继承的AbstractMap中,已经实现了Map接口
//【2】又实现了这个接口,多余,但是设计者觉得没有必要删除,就这么地了
implements Map<K,V>, Cloneable, Serializable{
//【3】后续会用到的重要属性:先粘贴过来:
static final int DEFAULT_INITIAL_CAPACITY = 16;//哈希表主数组的默认长度
//定义了一个float类型的变量,以后作为:默认的装填因子,加载因子是表示Hsah表中元素的填满的程度
//太大容易引起哈西冲突,太小容易浪费 0.75是经过大量运算后得到的最好值
//这个值其实可以自己改,但是不建议改,因为这个0.75是大量运算得到的
static final float DEFAULT_LOAD_FACTOR = 0.75f;
transient Entry<K,V>[] table;//主数组,每个元素为Entry类型
transient int size;
int threshold;//数组扩容的界限值,门槛值 16*0.75=12
final float loadFactor;//用来接收装填因子的变量
//【4】查看构造器:内部相当于:this(16,0.75f);调用了当前类中的带参构造器
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
//【5】本类中带参数构造器:--》作用给一些数值进行初始化的!
public HashMap(int initialCapacity, float loadFactor) {
//【6】给capacity赋值,capacity的值一定是 大于你传进来的initialCapacity 的 最小的 2的倍数
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
//【7】给loadFactor赋值,将装填因子0.75赋值给loadFactor
this.loadFactor = loadFactor;
//【8】数组扩容的界限值,门槛值
threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//【9】给table数组赋值,初始化数组长度为16
table = new Entry[capacity];
}
//【10】调用put方法:
public V put(K key, V value) {
//【11】对空值的判断
if (key == null)
return putForNullKey(value);
//【12】调用hash方法,获取哈希码
int hash = hash(key);
//【14】得到key对应在数组中的位置
int i = indexFor(hash, table.length);
//【16】如果你放入的元素,在主数组那个位置上没有值,e==null 那么下面这个循环不走
//当在同一个位置上放入元素的时候
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//哈希值一样 并且 equals相比一样
//(k = e.key) == key 如果是一个对象就不用比较equals了
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//【17】走addEntry添加这个节点的方法:
addEntry(hash, key, value, i);
return null;
}
//【13】hash方法返回这个key对应的哈希值,内部进行二次散列,为了尽量保证不同的key得到不同的哈希码!
final int hash(Object k) {
int h = 0;
if (useAltHashing) {
if (k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h = hashSeed;
}
//k.hashCode()函数调用的是key键值类型自带的哈希函数,
//由于不同的对象其hashCode()有可能相同,所以需对hashCode()再次哈希,以降低相同率。
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
/*
接下来的一串与运算和异或运算,称之为“扰动函数”,
扰动的核心思想在于使计算出来的值在保留原有相关特性的基础上,
增加其值的不确定性,从而降低冲突的概率。
不同的版本实现的方式不一样,但其根本思想是一致的。
往右移动的目的,就是为了将h的高位利用起来,减少哈西冲突
*/
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
//【15】返回int类型数组的坐标
static int indexFor(int h, int length) {
//其实这个算法就是取模运算:h%length,取模效率不如位运算
return h & (length-1);
}
//【18】调用addEntry
void addEntry(int hash, K key, V value, int bucketIndex) {
//【25】size的大小 大于 16*0.75=12的时候,比如你放入的是第13个,这第13个你打算放在没有元素的位置上的时候
if ((size >= threshold) && (null != table[bucketIndex])) {
//【26】主数组扩容为2倍
resize(2 * table.length);
//【30】重新调整当前元素的hash码
hash = (null != key) ? hash(key) : 0;
//【31】重新计算元素位置
bucketIndex = indexFor(hash, table.length);
}
//【19】将hash,key,value,bucketIndex位置 封装为一个Entry对象:
createEntry(hash, key, value, bucketIndex);
}
//【20】
void createEntry(int hash, K key, V value, int bucketIndex) {
//【21】获取bucketIndex位置上的元素给e
Entry<K,V> e = table[bucketIndex];
//【22】然后将hash, key, value封装为一个对象,然后将下一个元素的指向为e (链表的头插法)
//【23】将新的Entry放在table[bucketIndex]的位置上
table[bucketIndex] = new Entry<>(hash, key, value, e);
//【24】集合中加入一个元素 size+1
size++;
}
//【27】
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//【28】创建长度为newCapacity的数组
Entry[] newTable = new Entry[newCapacity];
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
//【28.5】转让方法:将老数组中的东西都重新放入新数组中
transfer(newTable, rehash);
//【29】老数组替换为新数组
table = newTable;
//【29.5】重新计算
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
//【28.6】
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//【28.7】将哈希值,和新的数组容量传进去,重新计算key在新数组中的位置
int i = indexFor(e.hash, newCapacity);
//【28.8】头插法
e.next = newTable[i];//获取链表上元素给e.next
newTable[i] = e;//然后将e放在i位置
e = next;//e再指向下一个节点继续遍历
}
}
}
}4、细节讲解:主数组的长度为2的倍数
主数组的长度为2的倍数

因为这个length的长度,会影响 key的位置:
key的位置的计算:

实际上这个算法就是: h%length ,但是取模的话 效率太低,所以用位运算效率会很高。
原因1:

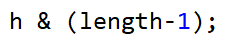
等效的前提就是 length必须是2的整数倍
原因2:
如果不是2的整数倍,那么 哈西碰撞 哈西冲突的概率就高了很多
位运算 就 涉及 到 length是不是2的整数倍:
比如是2的整数倍:


并且这个得到的索引值,一定在 0-15之间(数组是16的时候):

当然如果你扩容后数组长度为 32,那么这个索引就在0-31之间
比如如果不是2的整数倍:

发现:如果不是2的整数倍,那么 哈西碰撞 哈西冲突的概率就高了很多
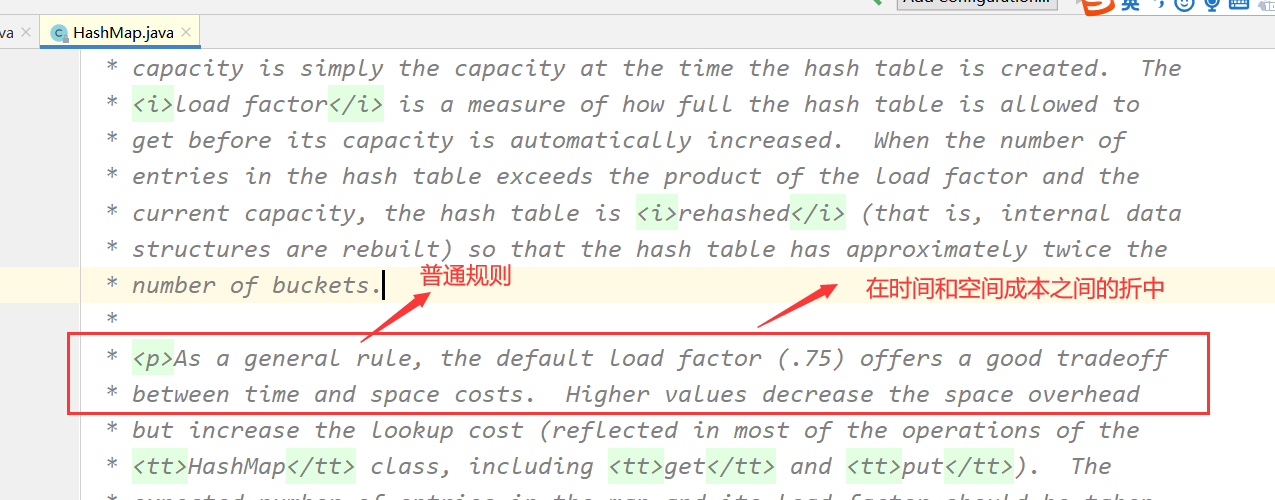
5、细节讲解:装填因子0.75的原因
如果装填因子是1, 那么数组满了再扩容,可以做到最大的空间利用率,但是这是一个理想状态,元素不可能完全的均匀分布,很可能就哈西碰撞产生链表了。产生链表的话 查询时间就长了。
空间好,时间不好
那么有人说 ,把装填因子搞小一点,如果是0.5的话,就浪费空间,但是可以做到0.5就扩容 ,然后哈西碰撞就少,不产生链表的话,那么查询效率很高
时间好,空间不好
所以在空间和时间中,取中间值,平衡这个因素就取值为0.75

6、HashSet底层原理
public class HashSet<E>{
//重要属性:
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
//构造器:
public HashSet() {
map = new HashMap<>();//HashSet底层就是利用HashMap来完成的
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
}二、TreeMap
1、原理大致介绍
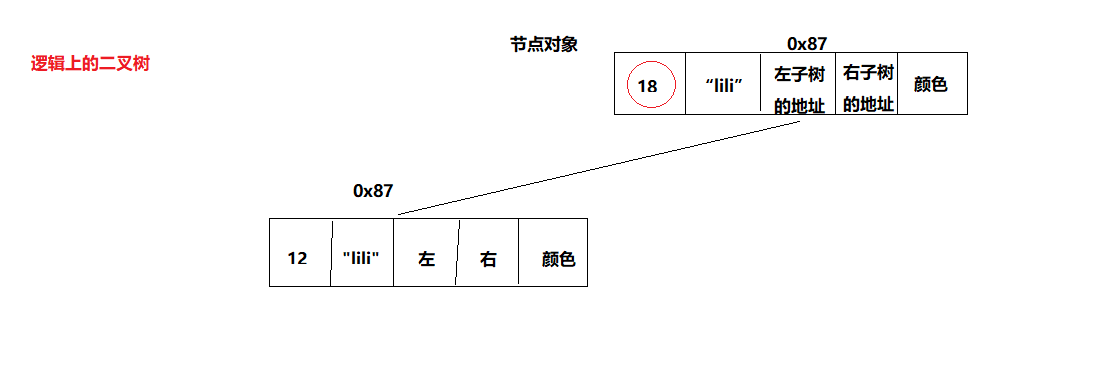
2、源码
public class TreeMap<K,V>{
//重要属性:
//外部比较器:
private final Comparator<? super K> comparator;
//树的根节点:
private transient Entry<K,V> root = null;
//集合中元素的数量:
private transient int size = 0;
//空构造器:
public TreeMap() {
comparator = null;//如果使用空构造器,那么底层就不使用外部比较器
}
//有参构造器:
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;//如果使用有参构造器,那么就相当于指定了外部比较器
}
public V put(K key, V value) {//k,V的类型在创建对象的时候确定了
//如果放入的是第一对元素,那么t的值为null
Entry<K,V> t = root;//在放入第二个节点的时候,root已经是根节点了
//如果放入的是第一个元素的话,走入这个if中:
if (t == null) {
//自己跟自己比
compare(key, key); // type (and possibly null) check
//根节点确定为root
root = new Entry<>(key, value, null);
//size值变为1
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
//将外部比较器赋给cpr:
Comparator<? super K> cpr = comparator;
//cpr不等于null,意味着你刚才创建对象的时候调用了有参构造器,指定了外部比较器
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);//将元素的key值做比较
//cmp返回的值就是int类型的数据:
//要是这个值《0 =0 》0
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else//cpm==0
//如果key的值一样,那么新的value替换老的value 但是key不变 因为key是唯一的
return t.setValue(value);
} while (t != null);
}
//cpr等于null,意味着你刚才创建对象的时候调用了空构造器,没有指定外部比较器,使用内部比较器
else {
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);//将元素的key值做比较
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;//size加1 操作
modCount++;
return null;
}
}
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left = null;
Entry<K,V> right = null;
Entry<K,V> parent;
boolean color = BLACK;
}3、TreeSet源码
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable{
//重要属性:
private transient NavigableMap<E,Object> m;
private static final Object PRESENT = new Object();
//在调用空构造器的时候,底层创建了一个TreeMap
public TreeSet() {
this(new TreeMap<E,Object>());
}
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
}三、Collections工具类
package com.lanson.test12;
import java.util.ArrayList;
import java.util.Collections;
/**
* @author : Lansonli
*/
public class Test01 {
//这是main方法,程序的入口
public static void main(String[] args) {
//Collections不支持创建对象,因为构造器私有化了
/*Collections cols = new Collections();*/
//里面的属性和方法都是被static修饰,我们可以直接用类名.去调用即可:
//常用方法:
//addAll:
ArrayList<String> list = new ArrayList<>();
list.add("cc");
list.add("bb");
list.add("aa");
Collections.addAll(list,"ee","dd","ff");
Collections.addAll(list,new String[]{"gg","oo","pp"});
System.out.println(list);
//binarySearch必须在有序的集合中查找:--》排序:
Collections.sort(list);//sort提供的是升序排列
System.out.println(list);
//binarySearch
System.out.println(Collections.binarySearch(list, "cc"));
//copy:替换方法
ArrayList<String> list2 = new ArrayList<>();
Collections.addAll(list2,"tt","ss");
Collections.copy(list,list2);//将list2的内容替换到list上去
System.out.println(list);
System.out.println(list2);
//fill 填充
Collections.fill(list2,"yyy");
System.out.println(list2);
}
}原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号