图解K8s源码 - kube-controller-manager篇

图解K8s源码 - kube-controller-manager篇

才浅Coding攻略
发布于 2022-12-12 18:19:02
发布于 2022-12-12 18:19:02
在kubernetes master节点中最重要的三个组件是:kube-apiserver、kube-controller-manager、kube-scheduler 分别负责k8s集群的资源访问入口、集群状态管理、集群调度。我们在之前的文章介绍了集群资源访问入口kube-apiserver “图解K8s源码 - kube-apiserver篇”,本篇尝试梳理清楚 kube-controller-manager 是如何“Manage Controller”的。
Controller Manager
实际上,kube-controller-manager 就是一系列控制器的集合,下面查看一下kubernetes项目的 pkg/controller 目录:
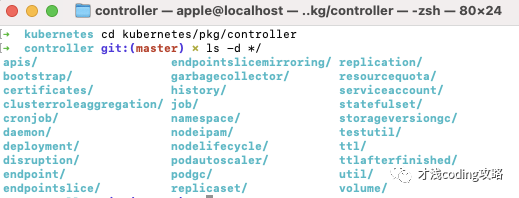
这个目录下的每一个控制器都各自明确分工负责集群内资源的管理。Controller Manager 这个集合则保证了集群中各种资源的实际状态(status)和用户定义的期望状态(spec)一致。
我们可以理解为Controller Manager 主要提供一个事件分发能力,不同的Controller 只需要注册对应的Handler 来等待接收和处理事件。也就是说如果出现与期望状态不一致的情况,会触发相应 Controller 注册的 Event Handler,让它们去根据资源本身的特点进行调整。
以 Deployment Controller 举例,在 pkg/controller/deployment/deployment_controller.go 的 NewDeploymentController 方法中,Deployment Controller 只需要根据不同的事件实现不同的处理逻辑,便可以实现对相应资源的管理。
dInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addDeployment,
UpdateFunc: dc.updateDeployment,
// This will enter the sync loop and no-op, because the deployment has been deleted from the store.
DeleteFunc: dc.deleteDeployment,
})
rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addReplicaSet,
UpdateFunc: dc.updateReplicaSet,
DeleteFunc: dc.deleteReplicaSet,
})
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
DeleteFunc: dc.deletePod,
})
这样的设计好处是能够将 Controller Manager 与具体 Controller 的逻辑相解耦。
我们刚刚提到了 Controller Manager 的事件分发功能,其中关键的部分就是 client-go,该项目在k8s二次开发时经常会被用到,比如开发自定义的controller。我们看下官方给出的 client-go 与自定义 controller 的实现原理。
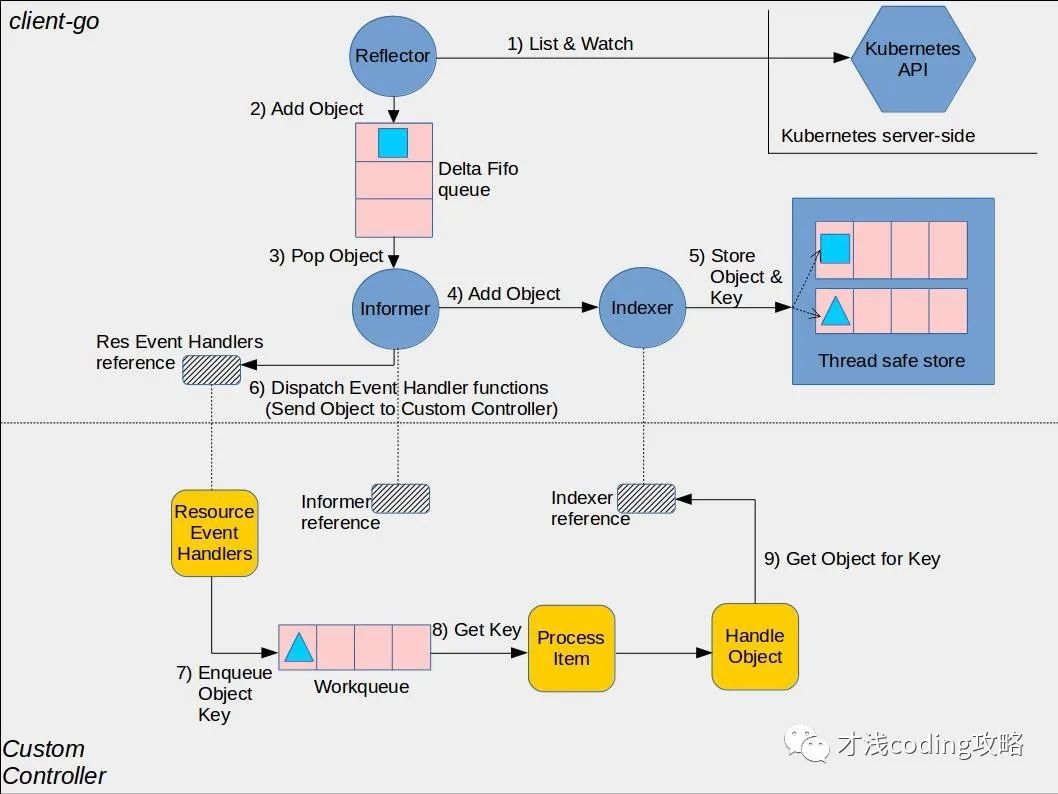
图中下半部分(Custom Controller) 正是 Controller 描述的内容,而上半部分(client-go) 主要是由 Controller Manager 完成的。
informer 机制
client-go 包中最核心的工具就是 informer,k8s的其他组件都是通过 client-go 的 informer 机制与 kube-apiserver 通信的,它保证了组件间进行http通信时消息的实时性、可靠性和顺序性。
我们将上图的 client-go 部分放大,看下 informer运行原理:
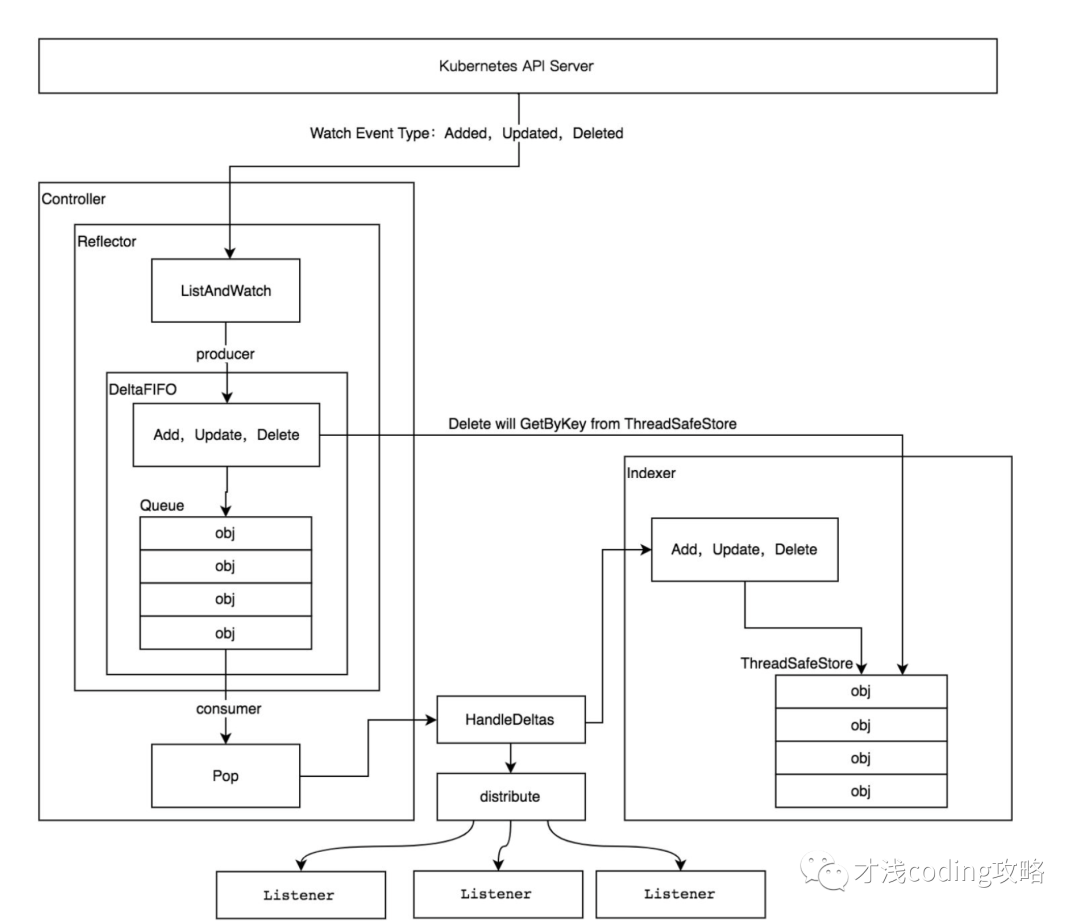
在 informer 的架构设计中,有多个核心组件,分别介绍如下。
Reflector
Reflector用来对 kube-apiserver的资源进行监控,其中资源类型可以是k8s内置资源,也可以是CRD自定义资源。当监控的资源发生变化时,触发相应的变更事件,例如Added(资源添加)事件、Updated(资源更新)事件、Deleted(资源删除)事件,并将其资源对象存放到本地缓存DeltaFIFO中。
通过 NewReflector 实例化 Reflector 对象,实例化过程中须传入ListerWatcher数据接口对象,它拥有 List 和 Watch 方法,其中 List 方法负责获取资源列表,Watch负责监视指定kube-apiserver。只要实现了 List 和 Watch 方法的对象都可以视作 ListerWatcher。
其中List 短连接获取全量数据,Watch 长连接获取增量数据。
type ListerWatcher interface {
Lister
Watcher
}
// Lister is any object that knows how to perform an initial list.
type Lister interface {
// List should return a list type object; the Items field will be extracted, and the
// ResourceVersion field will be used to start the watch in the right place.
List(options metav1.ListOptions) (runtime.Object, error)
}
// Watcher is any object that knows how to start a watch on a resource.
type Watcher interface {
// Watch should begin a watch at the specified version.
Watch(options metav1.ListOptions) (watch.Interface, error)
}DeltaFIFO
DeltaFIFO 可以分开理解,FIFO是一个先进先出的队列,拥有队列的基本操作方法;Delta是一个资源对象的存储,它可以保存资源对象的操作类型,例如Added(添加)操作类型、Updated(更新)操作类型、Deleted(删除)操作类型、Sync(同步)操作类型等。
DeltaFIFO与其他队列的最大不同点在于,它会保留所有关于资源对象(obj)的操作类型,队列中会存在拥有不同操作的同一个资源对象。消费者在处理该资源对象时能够了解该资源对象所发生的事情。其中生产者是Reflector调用的Add方法,消费者是Controller调用的Pop方法。
DeltaFIFO 存储结构如下,queue中存储资源对象的key,items 通过 map 方式存储,它的 value 存储对象的 Delta 数组。

Indexer
Indexer 是 client-go 用来存储资源对象并自带索引功能且线程安全的本地存储。Reflector从DeltaFIFO中将消费出来的资源对象存储至Indexer。Indexer 中的数据与 Etcd 集群中的数据保持完全一致,client-go 可以从本地存储中读取相应资源对象数据,以减轻 Etcd 集群和 kube-apiserver 压力。
indexer的底层存储实现是threadSafeMap。threadSafeMap是并发安全的存储,curd都会加锁处理。该存储是一个内存中的存储,不会落盘。indexer在此基础上封装了索引index的功能,方便用户通过自己写的索引函数,高效地按需获取数据。
informer 工厂
了解了informer 架构中的核心组件后,我们再回到之前 client-go 的架构图,看看如何创建 Informer。
在Controller Manager 启动时,会创建一个单例工厂 SharedInformerFactory,为什么要用单例模式呢?因为每个 Informer 都会与 API Server 维持一个 watch 长连接,所以 Informer 工厂通过为所有 Controller 提供唯一获取 Informer 的入口,来保证每种类型的 Informer 只被初始化一次。
func NewSharedInformerFactoryWithOptions(client versioned.Interface, defaultResync time.Duration, options ...SharedInformerOption) SharedInformerFactory {
factory := &sharedInformerFactory{
client: client,
namespace: v1.NamespaceAll,
defaultResync: defaultResync,
informers: make(map[reflect.Type]cache.SharedIndexInformer),
startedInformers: make(map[reflect.Type]bool),
customResync: make(map[reflect.Type]time.Duration),
}
// Apply all options
for _, opt := range options {
factory = opt(factory)
}
return factory
}
当 Controller Manager 启动时,通过该工厂方法的 Start 方法运行所有的 informer。
func (f *sharedInformerFactory) Start(stopCh <-chan struct{}) {
f.lock.Lock()
defer f.lock.Unlock()
for informerType, informer := range f.informers {
if !f.startedInformers[informerType] {
go informer.Run(stopCh)
f.startedInformers[informerType] = true
}
}
}informer 的创建及运行
直接粘贴源码一块块分析比较晦涩,这里以 Deployment Controller为例, 将整个流程的各个阶段的核心方法用图解形式进行阐释。
下图是仅关注 Deployment 资源的 Informer 的创建过程:
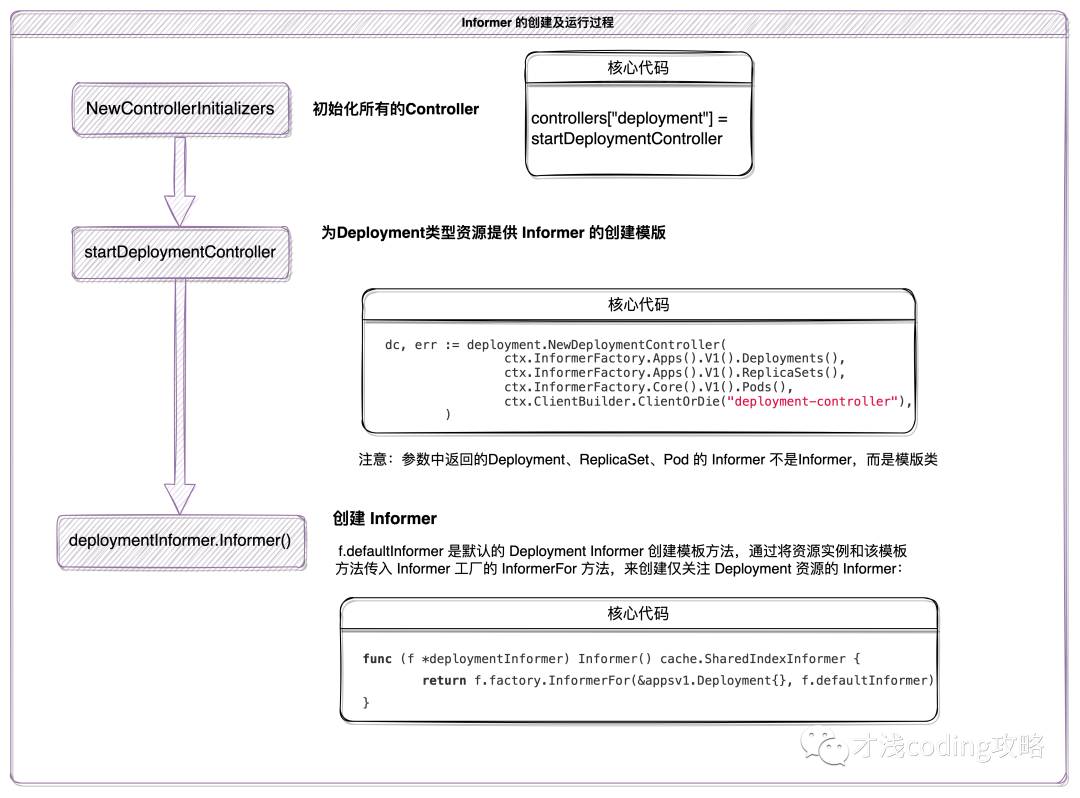
简单概括下:
- 首先通过 Informer 工厂获得特定类型的 Informer 模板类;
- Informer 模板类的 Informer() 方法创建该特定资源 Informer;
- Informer() 方法通过对应资源类型工厂的 InformerFor 方法 来创建 Informer。
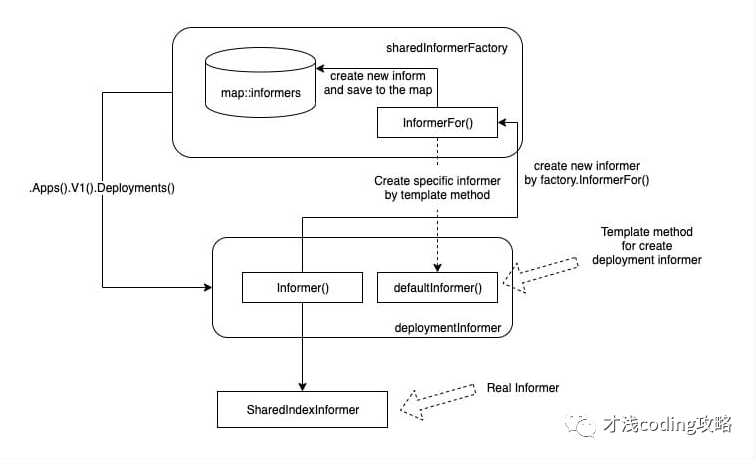
我们看到创建过程的代码最后返回值是 cache.SharedIndexInformer,即 sharedIndexInformer 结构体将被实例化,成为真正的 Informer 实例。
那么当 Informer 工厂启动时(执行 Start 方法),被真正运行起来的也就是 sharedIndexInformer。运行代码如下:
func (s *sharedIndexInformer) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
if s.HasStarted() {
klog.Warningf("The sharedIndexInformer has started, run more than once is not allowed")
return
}
// 创建FIFO队列
fifo := NewDeltaFIFOWithOptions(DeltaFIFOOptions{
KnownObjects: s.indexer,
EmitDeltaTypeReplaced: true,
})
cfg := &Config{
Queue: fifo,
ListerWatcher: s.listerWatcher,
ObjectType: s.objectType,
FullResyncPeriod: s.resyncCheckPeriod,
RetryOnError: false,
ShouldResync: s.processor.shouldResync,
Process: s.HandleDeltas,
WatchErrorHandler: s.watchErrorHandler,
}
// 创建一个controller实例
func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.controller = New(cfg)
s.controller.(*controller).clock = s.clock
s.started = true
}()
// Separate stop channel because Processor should be stopped strictly after controller
processorStopCh := make(chan struct{})
var wg wait.Group
defer wg.Wait() // Wait for Processor to stop
defer close(processorStopCh) // Tell Processor to stop
// 启动cacheMutationDetector
wg.StartWithChannel(processorStopCh, s.cacheMutationDetector.Run)
// 启动processor
wg.StartWithChannel(processorStopCh, s.processor.run)
defer func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.stopped = true // Don't want any new listeners
}()
s.controller.Run(stopCh)
}
在这里我们发现它创建了一个 controller 实例,这是一个承上启下的事件控制器,主要作用就两个:
- 通过 List-Watch 从 Api Server 获得事件、并将该事件推入 DeltaFIFO 中;
- 将 sharedIndexInformer 的 HandleDeltas 方法(HandleDeltas 调用了 processor.distribute 完成事件的分发)作为参数,来调用 DeltaFIFO 的 Pop 方法。
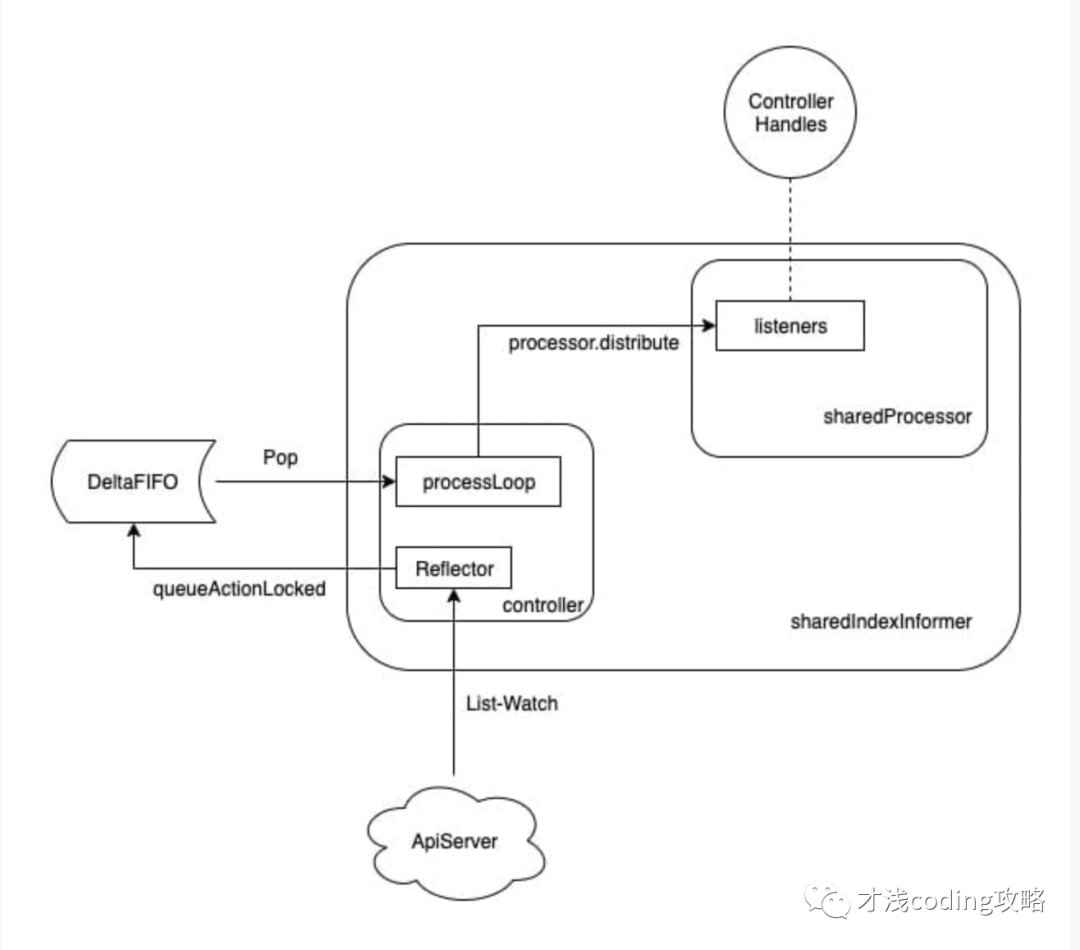
sharedIndexInformer 是一个共享的 Informer 框架,不同的 Controller 只需要提供一个模板类(比如上文提到的 deploymentInformer ),便可以创建一个符合自己需求的特定 Informer。
我们再来看看 SharedIndexInformer 下包含了哪些内容,即NewSharedIndexInformer 方法。
func NewSharedIndexInformer(lw ListerWatcher, exampleObject runtime.Object, defaultEventHandlerResyncPeriod time.Duration, indexers Indexers) SharedIndexInformer {
realClock := &clock.RealClock{}
sharedIndexInformer := &sharedIndexInformer{
processor: &sharedProcessor{clock: realClock},
indexer: NewIndexer(DeletionHandlingMetaNamespaceKeyFunc, indexers),
listerWatcher: lw,
objectType: exampleObject,
resyncCheckPeriod: defaultEventHandlerResyncPeriod,
defaultEventHandlerResyncPeriod: defaultEventHandlerResyncPeriod,
cacheMutationDetector: NewCacheMutationDetector(fmt.Sprintf("%T", exampleObject)),
clock: realClock,
}
return sharedIndexInformer
}
}
- processor:提供了 EventHandler 注册和事件分发的功能
- indexer:提供了资源缓存的功能
- listerWatcher:由模板类提供,包含特定资源的 List 和 Watch 方法
- objectType:用来标记关注哪种特定资源类型
- cacheMutationDetector:监控 Informer 的缓存
总结
至此,我们将之前介绍的各个核心组件串起来梳理下整个过程:
Informer 会不断读取 DeltaFIFO 队列中的 Object,在触发事件回调之前先更新本地的 store,如果是操作 Object,即事件类型是 Added(资源添加)事件、Updated(资源更新)事件、Deleted(资源删除),那么 Informer 会通过 Indexer 的库把这个增量里的 API 对象保存到本地的缓存中,并为它创建索引。之后通过 Lister 对资源进行 List / Get 操作时会直接读取本地的 store 缓存,通过这种方式避免对 kube-apiserver 的大量不必要请求,缓解其访问压力。
在注册的 ResourceEventHandler 回调函数中,在做了一些简单的过滤后,将关心变更的 Object 放到 workqueue 里。之后 Controller 从 workqueue 里面取出 Object,启动一个 worker 来执行自己的业务逻辑,通常是对比资源的当前运行状态与期望状态,做出相应的处理,实现运行状态向期望状态的收敛。
参考:
《Kubernetes源码剖析》
《深入剖析kubernetes》
https://blog.yingchi.io/posts/2020/7/k8s-cm-informer.html
https://blog.ihypo.net/15763910382218.html
https://kubernetes.io/zh-cn/docs/concepts/overview/components/#kube-controller-manager
k8s系列往期文章列表:
图解K8s源码 - kube-apiserver下的RBAC鉴权机制
持续更新中……
END
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-11-28,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号