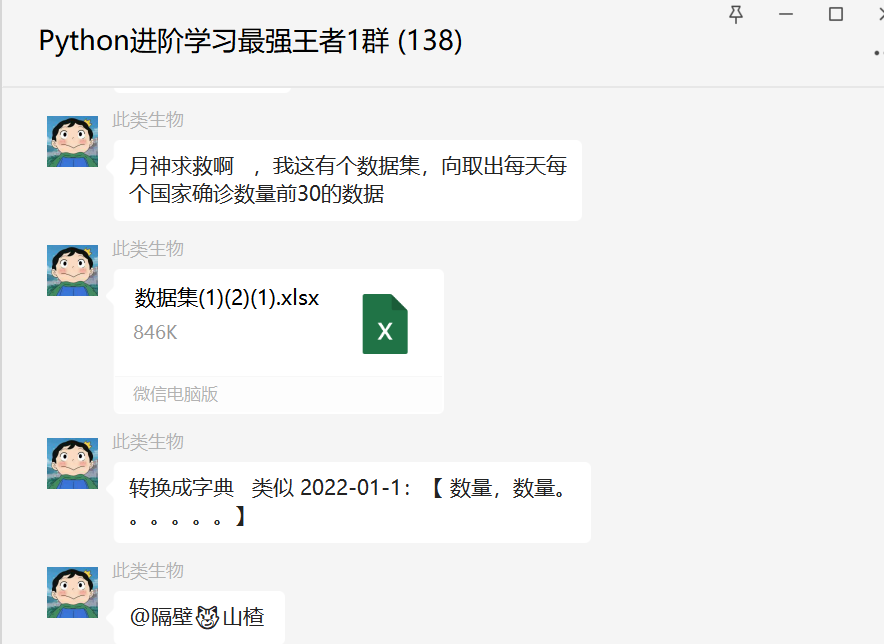
我这有个数据集,向取出每天每个国家确诊数量前30的数据,使用Pandas如何实现?
我这有个数据集,向取出每天每个国家确诊数量前30的数据,使用Pandas如何实现?

前端皮皮
发布于 2022-12-19 20:08:29
发布于 2022-12-19 20:08:29
野老念牧童,倚杖候荆扉。
大家好,我是皮皮。
一、前言
前几天在Python最强王者交流群【此类生物】问了一个Pandas处理的问题,提问截图如下:
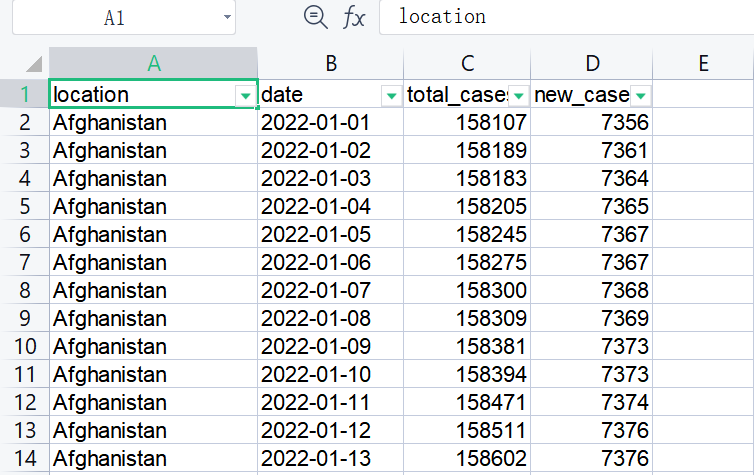
部分数据截图如下所示:
二、实现过程
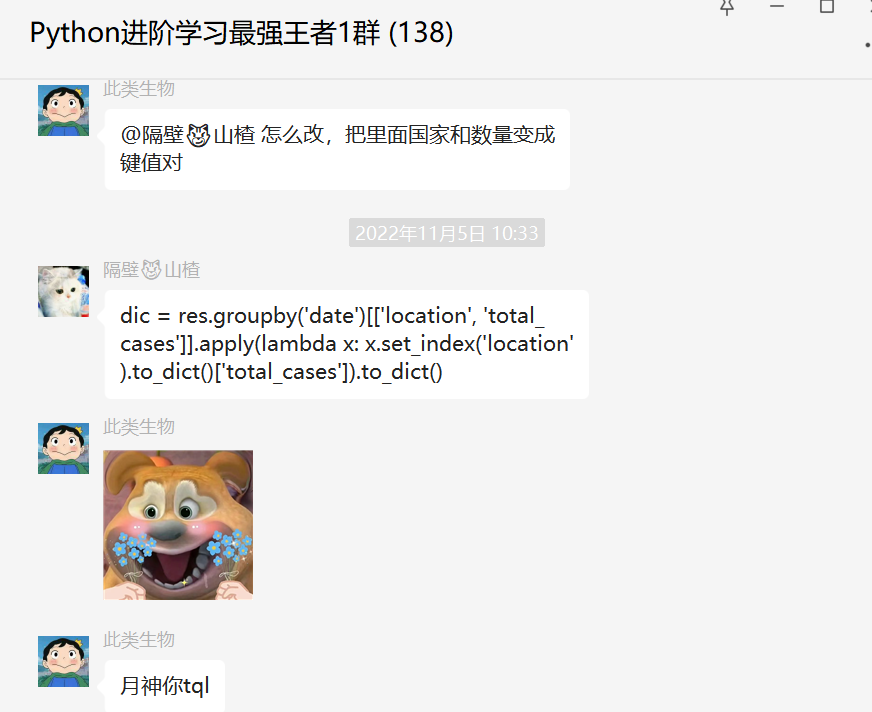
这里【隔壁😼山楂】和【瑜亮老师】纷纷提出,先不聚合location列就可以了。这里【隔壁😼山楂】提供了一个代码,真的太强了!
res = df.loc[df.groupby('date')['total_cases'].nlargest(30).index.get_level_values(1)]
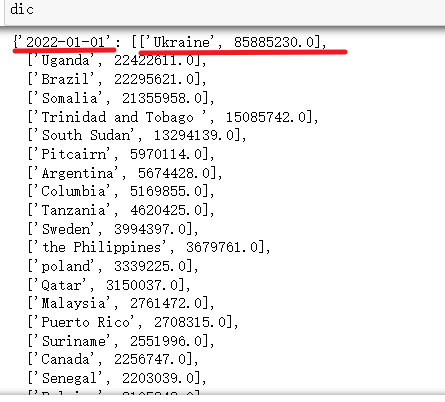
dic = res.groupby('date')[['location', 'total_cases']].apply(lambda x: x.values.tolist()).to_dict()
可以得到如下预期结果:
先取值,最后转成字典嵌套列表的,顺利地帮助粉丝解决了问题。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Pandas处理的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【此类生物】提问,感谢【隔壁😼山楂】、【猫药师Kelly】、【瑜亮老师】给出的思路和代码解析,感谢【Python进阶者】、【Python狗】等人参与学习交流。
本文参与 腾讯云自媒体分享计划,分享自微信公众号。
原始发表:2022-12-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录