HBase单机实现主主复制(高可用方案)

概述
HBase本身是一个没有单点故障的分布式系统,上层(HBase层)和底层(HDFS层)都通过一定的技术手段保障了服务的可用性,HMaster一般都是高可用部署,如果集群中RegionServer宕机,region的迁移代价并不大,一般在毫秒级就能完成,所以对应用造成的影响也很有限;底层存储依赖于HDFS,数据本身默认也有3副本,数据存储上做到了多副本冗余,而在当前方案中将HBase当做单机使用。
HBase高可用能保证在出现异常时,快速的进行故障转移,为了使故障的时间尽可能的短,我们使用HBase的主主复制方案(Master-Master Replication),本方案中主备数据复制方式为Master-push(即主向备推送),主主方案的优点是在主备服务器发生切换是,HBase的主备可以无需任何操作,跟随VIP的切换对外提供服务。
原理
首先看下官方的一张图:
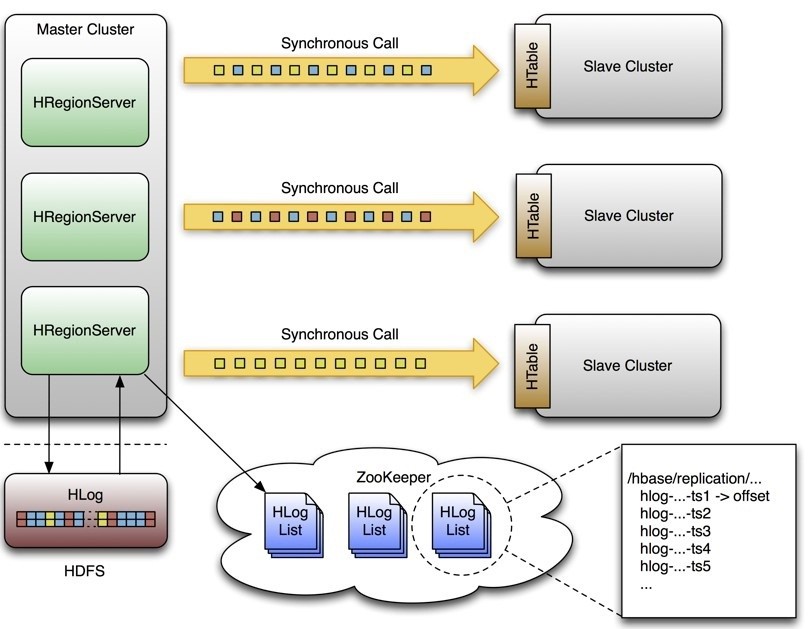
Hbase集群主备复制原理
HBase的replication是以Column Family为单位的,需要针对每个Column Family配置replication scope。
上图中,一个Master对应了3个Slave,Master上每个RegionServer都有一份HLog,在开启Replication的情况下,每个RegionServer都会开启一个线程用于读取该RegionServer上的HLog,并且发送到各个Slave,Zookeeper用于保存当前已经发送的HLog的位置。Master与Slave之间采用异步通信的方式,保障Master上的性能不会受到Slave的影响。用Zookeeper保存已经发送HLog的位置,主要考虑在Slave复制过程中如果出现问题后重新建立复制,可以找到上次复制的位置。
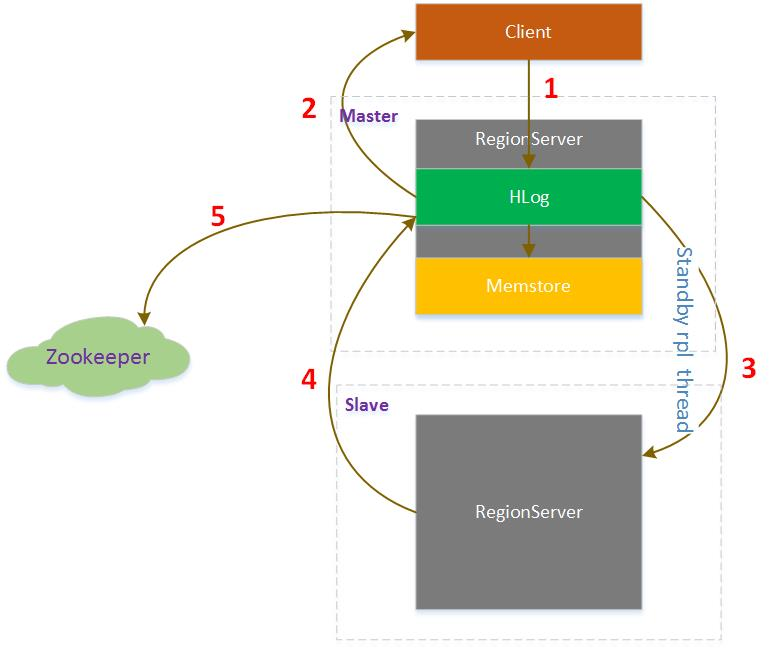
主备复制步骤
HBase Replication步骤
1. HBase Client向Master写入数据
2. 对应RegionServer写完HLog后返回Client请求
3. 同时replication线程轮询HLog发现有新的数据,发送给Slave
4. Slave处理完数据后返回给Master
5. Master收到Slave的返回信息,在Zookeeper中标记已经发送到Slave的HLog位置
环境准备:
172.103.201.105 bogon
172.103.201.103 hadoop8
HBase版本:1.2.6
HBase配置修改:
在hbase-site.xml中增加如下配置,用来开启HBase复制功能:
<property>
<name>hbase.replication</name>
<value>true</value>
</property>
使用场景:
原生HBase主备复制:
以下配置主备都进行配置,add_peer时,zk的ip使用各自对端的ip即可 先进入hbase shell命令行:
[root@bogon bin]# ./hbase shell
创建表:
hbase(main):001:0> create 'test', 'cf'
添加复制对端ip,根据情况输入,用来实现互相同步:
hbase(main):001:0>add_peer '1','172.103.201.103:2181:/hbase'
追加复制表:
hbase(main):001:0>append_peer_tableCFs '1', 'test'
修改表结构,将cf列簇的REPLICATION_SCOPE修改为1:
hbase(main):001:0>disable 'test'
hbase(main):001:0>alter 'test',{NAME => 'cf',REPLICATION_SCOPE => '1'}
hbase(main):001:0>enable 'test'
在任意一台插入数据:
hbase(main):011:0> put 'test', 'r1', 'cf:a', 'aaa'
hbase(main):012:0> scan 'test'
ROW COLUMN+CELL
r1 column=cf:a, timestamp=1562668712158, value=aaa
1 row(s) in 0.0300 seconds
效果如下:

建表后

修改表结构

添加对端复制zk

在任意一台put一条数据

对端中查询可见
使用Phoenix操作HBase,并进行主备复制(主要测试数据同步和索引数据同步):
使用Phoenix插件作为客户端连接HBase服务,将HBase中配置文件hbase-site.xml拷贝到Phoenix中,启动执行apache-phoenix-4.13.1-HBase-1.2-bin/bin/sqlline.py脚本,首次启动会创建Phoenix相关系统表:
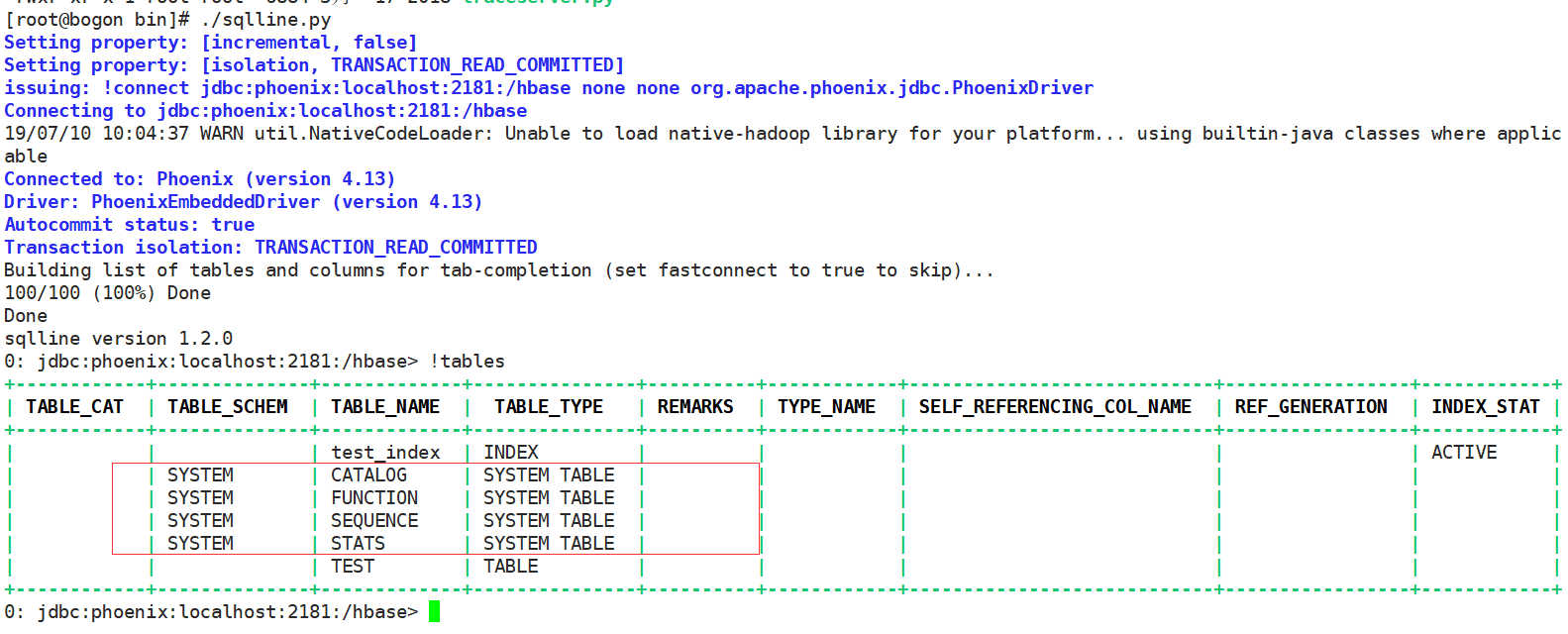
Phoenix创建的系统表
这些表主要用于存储并管理用户表,将用户表表现为关系型数据库的形式。
以下执行操作:
建表,建索引,创建同步关系:
CREATE TABLE IF NOT EXISTS test(id bigint primary key, name varchar, age bigint, addr varchar); create local index "test_index" on "TEST"("NAME", "AGE"); create index "test_index2" on "TEST"("NAME", "AGE");
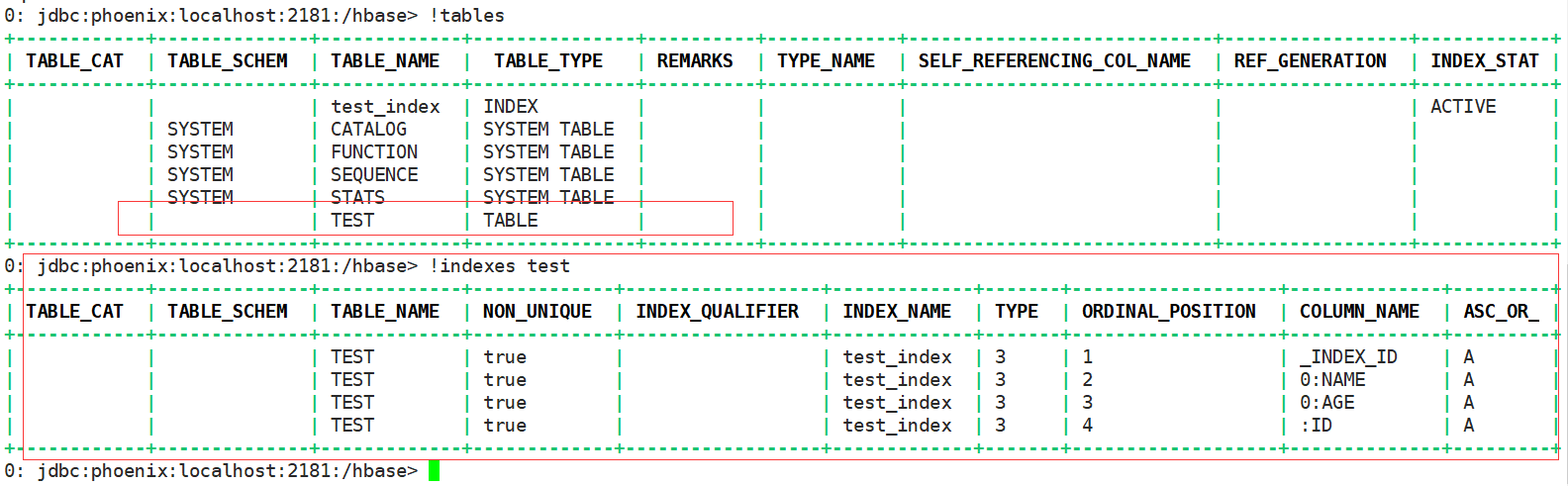
创建表,本地索引
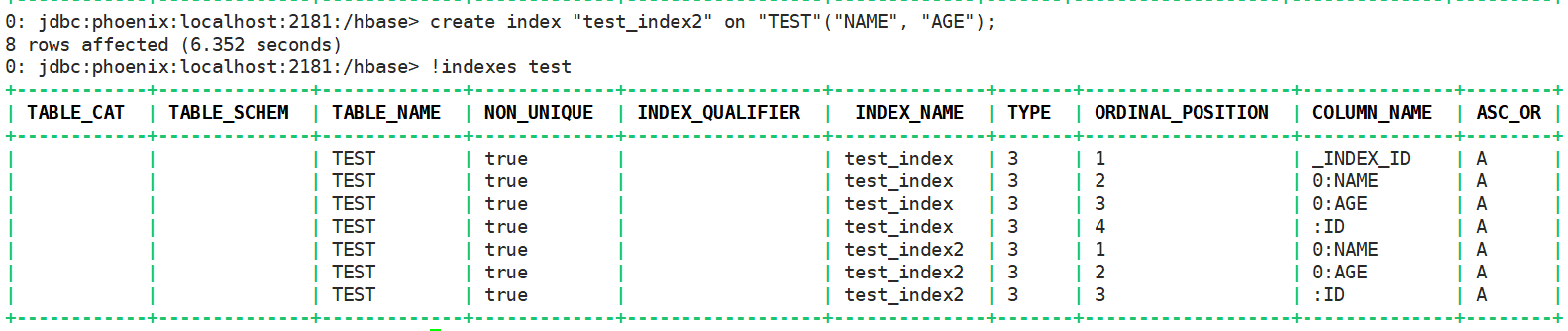
创建全局索引
在hbase shell命令行中执行:
disable 'TEST' alter 'TEST',{NAME => '0',REPLICATION_SCOPE => '1'} alter 'TEST',{NAME => 'L#0',REPLICATION_SCOPE => '1'} enable 'TEST' append_peer_tableCFs '1', "test_index2" alter 'test_index2',{NAME => '0',REPLICATION_SCOPE => '1'} //配置系统表数据主备复制 set_peer_tableCFs '1',"SYSTEM.CATALOG; SYSTEM.FUNCTION; SYSTEM.MUTEX; SYSTEM.SEQUENCE; SYSTEM.STATS" alter 'SYSTEM.CATALOG',{NAME => '0',REPLICATION_SCOPE => '1'} alter 'SYSTEM.FUNCTION',{NAME => '0',REPLICATION_SCOPE => '1'} alter 'SYSTEM.MUTEX',{NAME => '0',REPLICATION_SCOPE => '1'} alter 'SYSTEM.SEQUENCE',{NAME => '0',REPLICATION_SCOPE => '1'} alter 'SYSTEM.STATS',{NAME => '0',REPLICATION_SCOPE => '1'}
只有全局索引才会在hbase中创建一个表用于存储索引数据,因此只有全局索引才能以表复制的形式进行主备复制,如下图,配置索引表的主备复制:
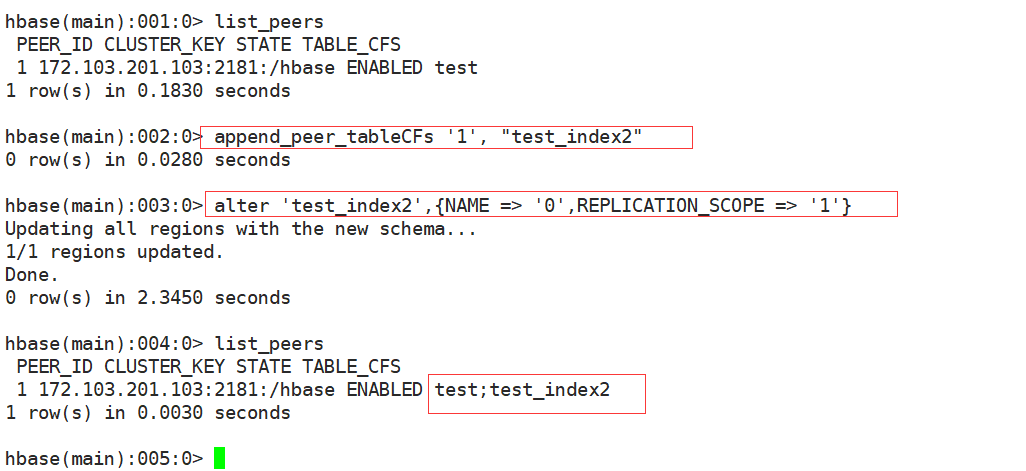
同步全局索引表
在Phoenix客户端命令行执行插入数据:
upsert into test values(1, 'aaa', 1, 'aaa'); upsert into test values(2, 'bbb', 2, 'bbb'); upsert into test values(3, 'ccc', 3, 'ccc'); upsert into test values(4, 'ddd', 4, 'ddd'); upsert into test values(5, 'eee', 5, 'eee'); upsert into test values(6, 'fff', 6, 'fff'); ...
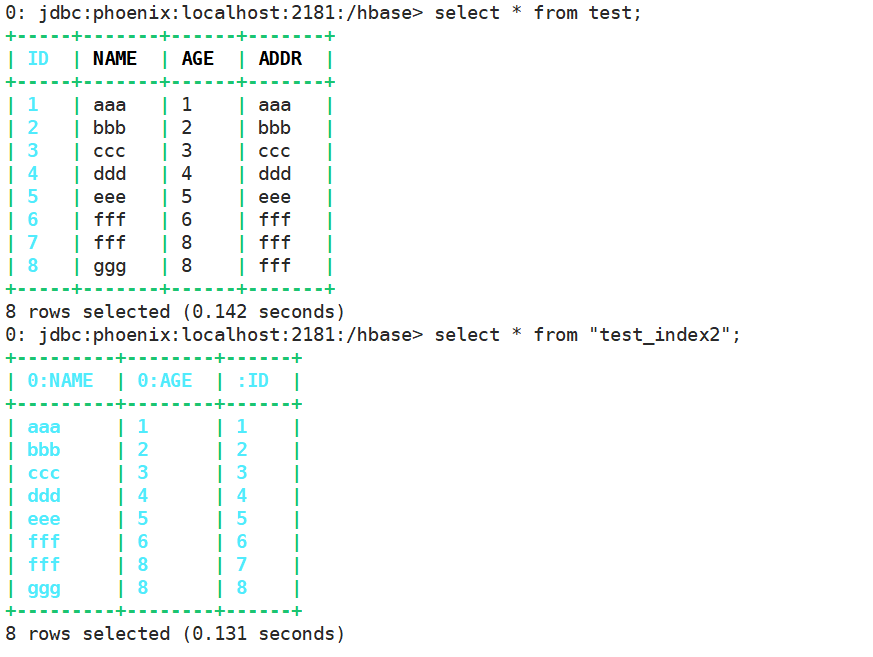
表数据,全局索引数据
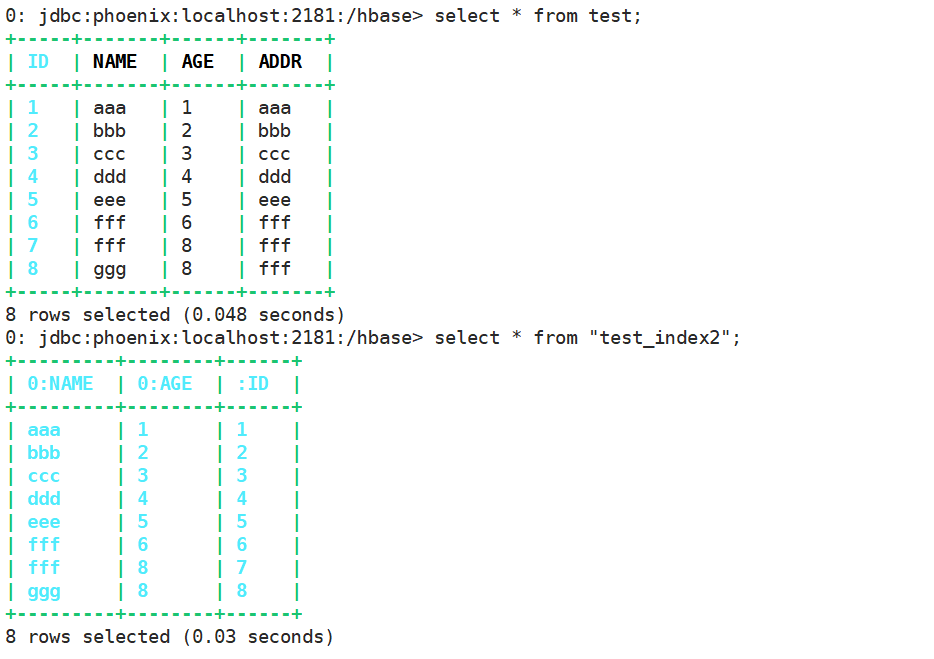
对端中表数据和索引数据
此处注意索引表名需要用双引号括起来,否则会报找不到表的错误。
由于本地索引是以列簇的形式存储在数据表中,列簇名为:L#0,如图:
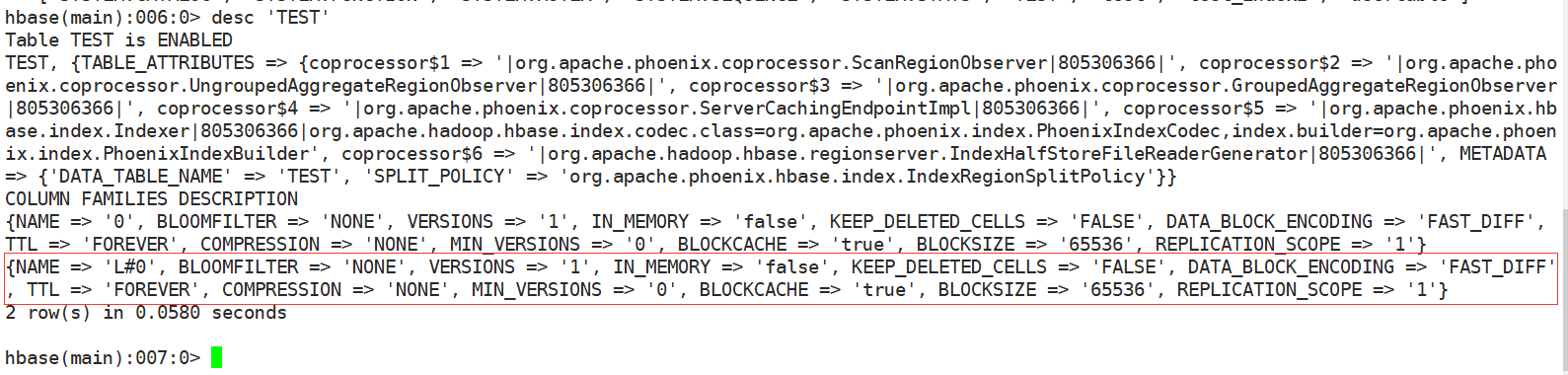
test表结构
虽然通过hbase命令对test表的本地索引列簇L#0做了主备复制的配置,理论上test表数据变更时应该同步到对端,但不知什么原因这个列簇数据未同步到对端(本人对Hbase研究有限,不太了解这种数据为什么无法同步,有了解的朋友可以评论下原因或者探讨怎么解决此问题)。目前只有全局索引可以实现主备同步,但是全局索引会在HBase中创建一个实体的索引表,这样会占用更大的磁盘,这是一个缺点,但同时也更加可靠。