面试系列之-rocketmq高可用
面试系列之-rocketmq高可用

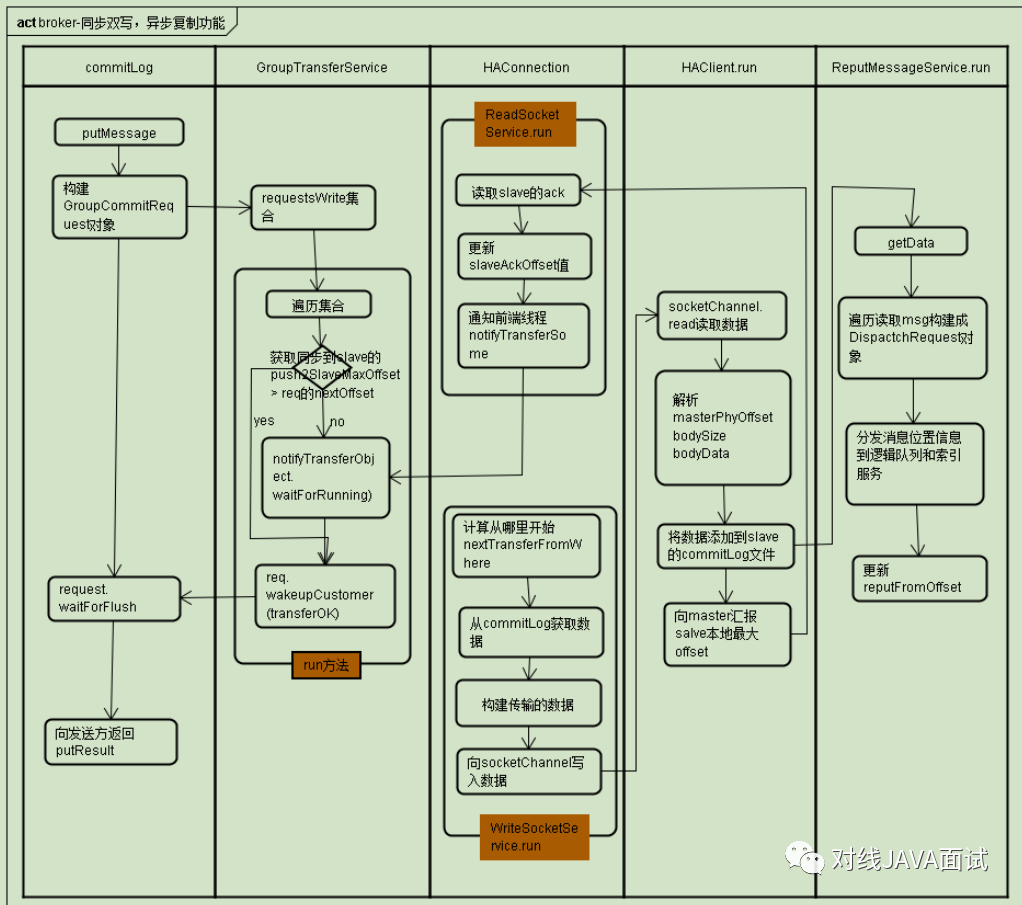
分布式集群高可用
RocketMQ分布式集群是通过Master和Slave的配合达到高可用性的;Master 角色的Broker支持读和写,Slave角色的 Broker仅支持读,也就是Producer只能和Master角色的Broker 连接写入消息;Consumer可以连接Master角色的Broker,也可以连接Slave角色的Broker来读取消息;
主从的高可用原理
在Consumer的配置文件中,并不需要设置是从Master读还是从Slave读,当Master不可用或者繁忙的时候(RocketMQ 服务器的内存不够),Consumer会被自动切换到从Slave读。 有了自动切换Consumer这种机制,当一个Master角色的机器出现故障后,Consumer仍然可以从 Slave 读取消息,不影响Consumer程序,这就达到 了消费端的高可用性;
集群部署模式
在有Slave情况下,Master一旦出现Consumer 访问堆积在磁盘的数据时,会向Consumer下达一个重定向指令,令Consumer从Slave拉取数据,这样正常的发消息不正常消费的Consumer都不会因为消息堆积受影响,因为系统将堆积场景与非堆积场景分割在了两个不同的节点处理;这里会产生另一个问题,Slave会不会写性能下降,答案是否定的,因为Slave的消息写入只追求吞吐量,不追求实时性,只要整体的吞吐量高就可以,而Slave每次都是从Master拉出一批数据,如1M,这种批量顺序写入方式即使堆积情况,整体吞吐量影响相对较小,只是写入RT会变长;
单 master模式
只有一个master节点,称不上是集群,一旦这个master节点宕机,那么整个服务就不可用;
多master模式
一个集群无Slave,全是Master,例如2个Master或者3个Master,这种模式的优缺点如下:
- 优点:配置简单,单个Master宕机或重启维护对应用无影响,在磁盘配置为RAID10时,即使机器宕机不可恢复情况下,由于RAID10磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条不丢),性能最高;
- 缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到影响;
多Master多Slave模式(异步复制)
每个Master至少配置一个Slave,有多对Master-Slave,HA采用异步复制方式,主备有短暂消息延迟(毫秒级),这种模式的优缺点如下:
- 优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,同时Master宕机后,消费者仍然可以从Slave消费,而且此过程对应用透明,不需要人工干预,性能同多Master模式几乎一样;
- 缺点:Master宕机,磁盘损坏情况下会丢失少量消息;使用异步复制的同步方式有可能会有消息丢失的问题。(Master 宕机后,生产者发送的消息没有消费完,同时到Slave节点的数据也没有同步完);
多Master多Slave模式(同步双写)+ 异步刷盘(最优推荐)
每个Master至少配置一个Slave,有多对Master-Slave,HA采用同步双写方式,即只有主备都写成功,才向应用返回成功,主从同步复制方式,保存数据热备份,通过异步刷盘方式,保证rocketMQ高吞吐量。这种模式的优缺点如下:
- 优点:数据与服务都无单点故障,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高;
- 缺点:性能比异步复制模式略低(大约低10%左右),发送单个消息的RT会略高,且目前版本在主节点宕机后,备机不能自动切换为主机;RocketMQ目前不支持把 Slave 自动转成 Master,如果机器资源不足, 需要把Slave转成 Master,则要手动停止Slave角色的Broker,更改配置文件, 用新的配置文件启动Broker;
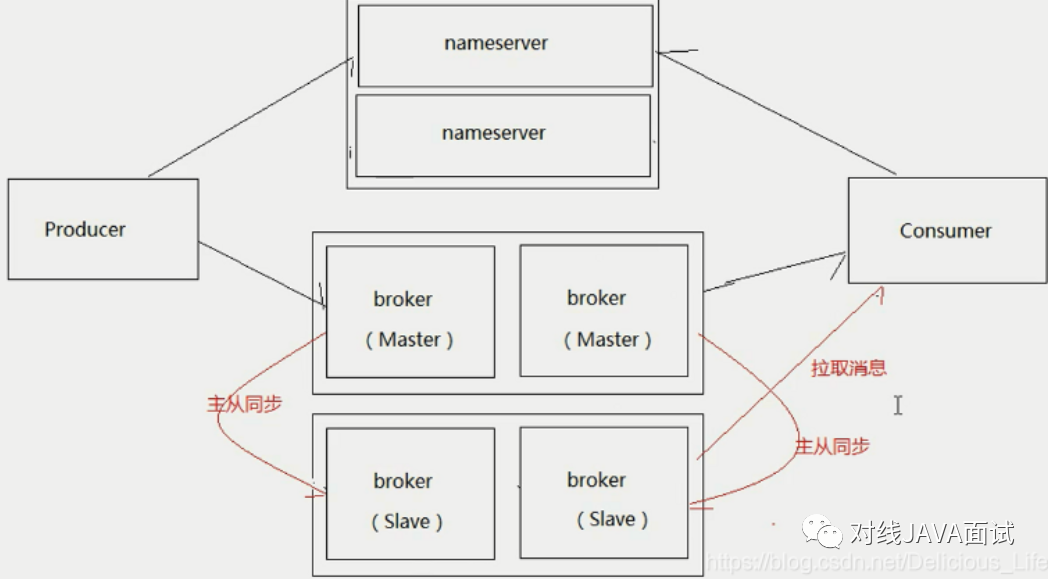
生产者高可用消息
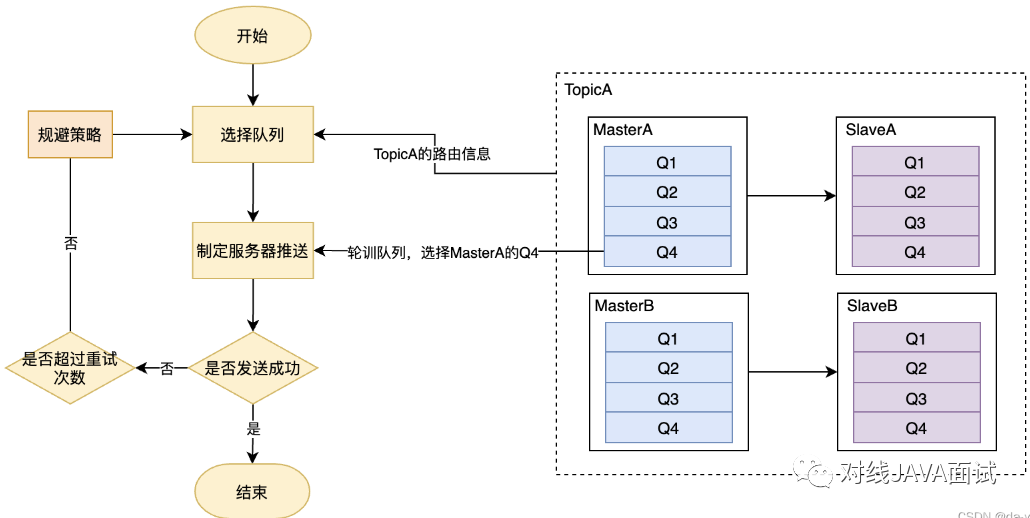
- TopicA创建在双主中,BrokerA和BrokerB中,每一个Broker中有4个队列;
- 选择队列是,默认是使用轮训的方式,比如发送一条消息A时,选择BrokerA中的Q4;
- 如果发送成功,消息A发结束;
- 如果消息发送失败,默认会采用重试机制,默认重试2次;
- 如果发生了消息发送失败,会有故障规避机制,默认生效;
故障规避机制
如果是BrokerA宕机,上一次路由选择的是BrokerA中的Q4,那么再次重发的队列选择是BrokerA中的Q1,这里的问题就是消息发送很大可能再次失败。即尽管会重试2次,但都是发送给同一个Broker处理,此过程会显得不那么靠谱,即大概率还是会失败,那这样重试的意义将大打折扣;
为了解决该问题,引入了故障规避机制,在消息重试的时候,会尽量规避上一次发送的Broker。回到上述示例,当消息发往BrokerA Q4队列时返回发送失败,那重试的时候,会先排除BrokerA中所有队列,选择BrokerB Q1队列,以增大消息发送的成功率;
由参数sendLatencyFaultEnable控制,默认关闭:
sendLatencyFaultEnable设置为false:默认值,不开启,**延迟规避策略只在重试时生效。**例如在一次消息发送过程中如果遇到消息发送失败,重试时规避BrokerA,但是在下一次消息发送时,还是会选择BrokerA的队列进行发送,只有继续发送失败后,重试时才规避BrokerA;
sendLatencyFaultEnable设置为true:开启延迟规避机制。一旦消息发送失败会将BrokerA“悲观”地认为在接下来的一段时间内都不可用,在未来某一段时间内所有的客户端不会向该Broker发送消息。这个延迟时间就是通过 notAvailableDuration、latencyMax共同计算的,就首先计算本次消息发送失败所耗的时延,然后对应latencyMax 中哪个区间,即计算在latencyMax的下标,然后返回notAvailableDuration同一个下标对应的延迟值;
如果所有的Broker都触发了故障规避,并且 Broker 只是那一瞬间压力大,那岂不是明明存在可用的Broker,但经过这样规避,反倒是没有Broker可用来,那岂不是更糟糕了;所以 RocketMQ默认不启用Broker故障延迟机制;
消费者高可用消息
消费端如果发生消息失败,没有提交成功,消息默认情况下会进入重试队列中;
顺序消息的重试
对于顺序消息,当消费者消费消息失败后,消息队列RocketMQ会自动不断进行消息重试(每次间隔时间为1秒),这时,应用会出现消息消费被阻塞的情况。因此,在使用顺序消息时,务必保证应用能够及时监控并处理消费失败的情况,避免阻塞现象的发生;所以对于顺序消息,consume消费消息失败时,不能返回reconsume_later,这样会导致乱序,应该返回 suspend_current_queue_a_moment,意思是先等一会,一会儿再处理这批消息,而不是放到重试队列里;
无序消息的重试
无序消息(普通、定时、延时、事务消息),当消费者消费消息失败时,可以通过设置返回状态达到消息重试的结果。无序消息的重试只针对集群消费方式生效;广播方式不提供失败重试特性,即消费失败后,失败消息不再重试,继续消费新的消息;
注意:如果消息重试16次后仍然失败,消息将不再投递。如果严格按照上述重试时间间隔计算,某条消息在一直消费失败的前提下,将会在接下来的4小时46分钟之内进行16次重试,超过这个时间范围消息将不再重试投递; 一条消息无论重试多少次,这些重试消息的Message ID不会改变;
重试配置
集群消费方式下,消息消费失败后期望消息重试,需要在消息监听器接口的实现中明确进行配置(三种方式任选一种):
- 返回RECONSUME_LATER (推荐)
- 返回Null
- 抛出异常
集群消费方式下,消息失败后期望消息不重试,需要捕获消费逻辑中可能抛出的异常,最终返回CONSUME_SUCCESS,此后这条消息将不会再重试;
自定义消息最大重试次数

消息队列RocketMQ允许Consumer 启动的时候设置最大重试次数,重试时间间隔将按照如下策略:
- 最大重试次数小于等于16次,则重试时间间隔同上表描述;
- 最大重试次数大于16次,超过16次的重试时间间隔均为每次2小时;
消息最大重试次数的设置对相同Group ID下的所有Consumer实例有效;如果只对相同Group ID下两个Consumer实例中的其中一个设置了MaxReconsumeTimes,那么该配置对两个Consumer 实例均生效。 配置采用覆盖的方式生效,即最后启动的Consumer实例会覆盖之前的启动实例的配置;
负载均衡
Producer负载均衡
Producer 端每个实例在发消息的时候,默认会轮询所有的message queue发送,以达到让消息平均落在不同的queue上。而由于queue可以散落在不同的broker,所以消息就发送到不同的broker下;
Consumer负载均衡
集群模式
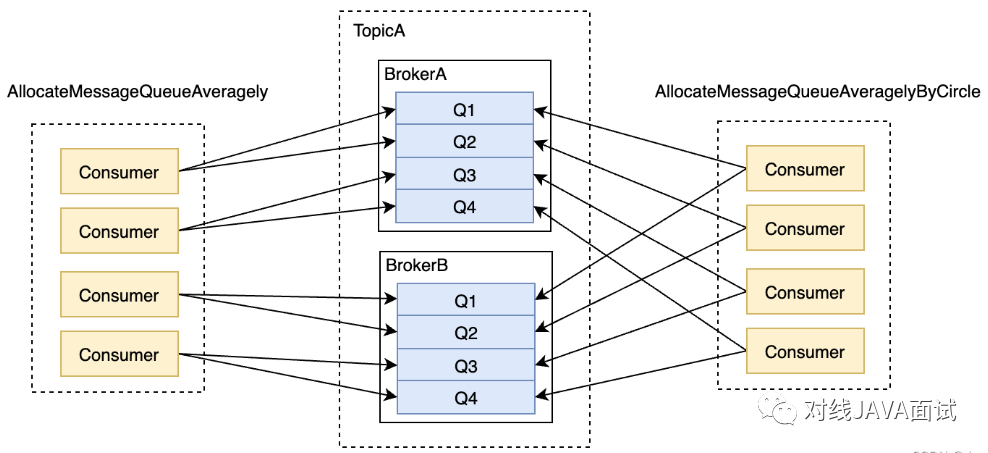
在集群消费模式下,每条消息只需要投递到订阅这个topic的Consumer Group下的一个实例即可。RocketMQ采用主动拉取的方式拉取并消费消息,在拉取的时候需要明确指定拉取哪一条message queue;
而每当实例的数量有变更,都会触发一次所有实例的负载均衡,这时候会按照queue的数量和实例的数量平均分配queue 给每个实例。 默认的分配算法是AllocateMessageQueueAveragely;
还有另外一种平均的算法是AllocateMessageQueueAveragelyByCircle,也是平均分摊每一条queue,只是以环状轮流分 queue的形式;
广播模式
由于广播模式下要求一条消息需要投递到一个消费组下面所有的消费者实例,所以也就没有消息被分摊消费的说法; 在实现上其中一个不同就是在consumer分配queue的时候,所有consumer都分到所有的queue;