基于Flink+Hudi在兴盛优选营销域实时数仓的实践
基于Flink+Hudi在兴盛优选营销域实时数仓的实践

1.前言
什么是流处理?引用Streaming1011里面的一句话:一种数据处理引擎,设计时考虑了无限数据集。(为了完整性,这个定义包括真正的流式传输系统(Apache Flink、Apache Storm)和微批处理系统(Apache Spark旗下的两款微批流处理引擎SparkStreming、Structured Streaming))。
流处理系统的出现在大数据领域是一件大事,基于流处理系统的编程能够更加及时的处理数据,而且有充分的理由相信每个企业都会好好的使用,因为大部分的企业都渴望更及时的数据,以便于开展更快的战略决策。并且现代商业中越来越普遍的海量、无限数据集,比如埋点日志,此类是适合使用流处理系统来做清洗加工计算,因为流处理系统是在数据到达时对其进行处理,这既能保证时间的时延,也能保证资源的平滑使用,从而产生更一致的和可预测的资源消耗,所以实时数仓的建设是离不开流处理系统的。
2.背景
随着电商业务的快速发展和运营的精细化要求,传统的批处理(t+1、h+1模式)已经不太能满足业务运营的需求,尤其在营销领域,对于实时数据的获取变得更加急迫,他们想能在更短的时间内(分钟)获取最新的数据,方便他们动态的调整运营策略,从而获得更好的运营效果和GMV增长。同时由于现阶段流处理系统愈发成熟,尤其是Apache Flink的快速发展,对电商的某些复杂场景也能保证数据的精准一次处理,从而保证数据的准确性,使得高质量可应用的实时数仓成为可能。
3.技术方案
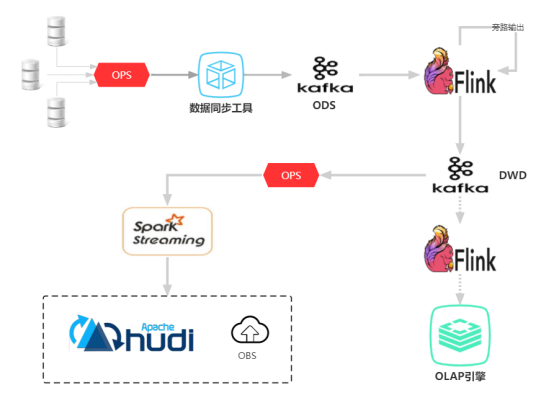
图表1 实时数仓架构图
图1就是兴盛优选的实时数仓基本架构,除了埋点日志这种走append hive的方式外,其它的业务域数仓(包含营销域)均是走这一套upsert架构,这套架构可以分为三个部分;
第一部分,数据同步。数据的接入是借助深圳研发团队的数据同步功能(ops),通过cannal实时监控各个业务线生产数据库的binlog日志,然后发送到kafka消息队列里面(本层的kafka可以看做实时数仓ODS层,数据跟ODS层的hudi表数据是一致的),以供数仓开发或者其他业务线开发订阅kafka消息进行实时的流处理;
第二部分,数据的加工。数据的加工目前数仓团队都是用的flink进行数据上的加工打宽,然后回写到kafka里面(本层的kafka可以看做实时数仓 dwd层),方便数据的复用以及流量削峰和数据的统一规范。其中数据开发借助datastudio平台用flinksql的方式能实现一些场景比较简单的业务,比如:营销的实时发券表。如果场景过于复杂,需要多条流进行join,用flinksql实现可能会由于上游数据延迟,导致双流join的数据没有关联上,进而导致实时数仓丢失数据或者字段值缺省。一般遇到这种多流join的场景我们会基于flink的DataStream API的方式进行实现,DataStream API的方式相对sql比较灵活,但是更底层一点,细节考虑多一些。sql的话是比较上层的抽象,底层细节已经封装好了,灵活性也大打折扣,无法满足一些特殊的复杂场景。营销实时核销表的就是一个这样的多流join的案例,下面会重点调这个场景讲下怎么实现的;
第三部分,数据的落地。数据的落地也是借助中间件团队的数据同步功能(ops),通过SparkStreaming写入到hudi,hudi是支持upsert写入的、是幂等的、是支持事务的,所以hudi是很适合电商这块的业务,目前数仓的hudi表都是merge on read格式的表,mor表支持快照查询、增量查询、读优化,一个表落地到hudi一般分为以ro/rt,比如营销核销实时表,它落地到hudi就分成以ro结尾、rt结尾的两个表,fct_marketing_xxx_rt、fct_marketing_xxxx_ro,ro结尾的是Read Optimized的缩写,读取ro表执行效率高,rt可以理解成realtime,但是官网6提供的的是Snapshot这个语义,对应前面提到的快照读,rt表的优势是实时性高,能读取最新的commit数据。
一般写入hudi数据延迟基本是在3~5分钟。同步到hudi的数据,业务方可以实现10分钟级别、小时级别、天级别的离线任务调度,也可以利用OLAP引擎(presto)做即席查询,灵犀有一部分数据就是通过presto的访问数仓的数据直接展示到看板上的,极大减少了其他数据团队的开发成本,避免了重复造轮子;如果业务方需要更快速的响应跟查询下,分钟级别满足不了他们需求,也可以将可复用的实时数仓dwd的kafka数据通步到华为的Gaussdb,同步到Gaussdb的时延基本为秒级,由于该款OLAP引擎是存储计算一体化的,所以查询性能相比presto来说也更优。
4.数据流向图
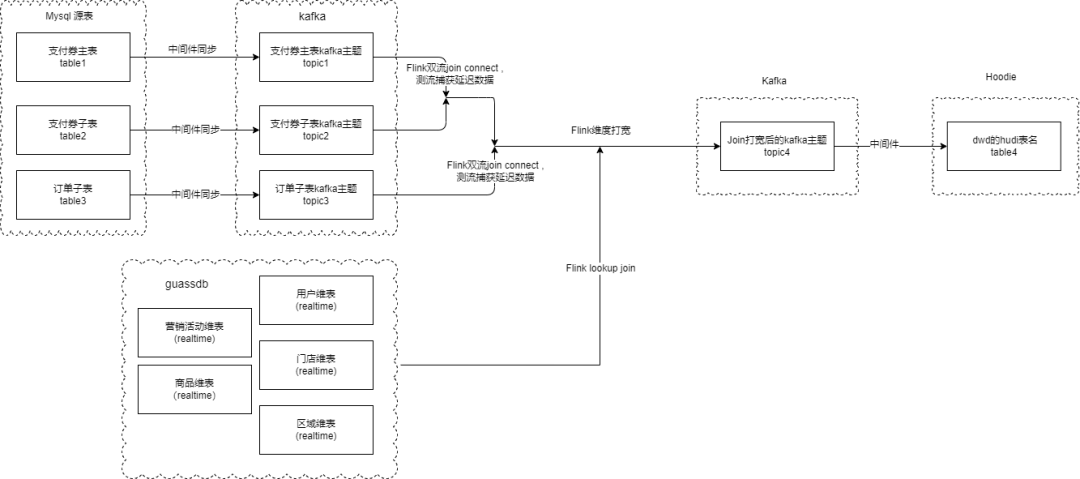
图表2 数据流向图
图2是营销实时核销的一个数据流向,其中支付券主表、支付券子表、订单子表这三个都是接的生产的业务库的实时产生的binlog消息,然后通过数据同步组件同步到kafka,后面flink先对支付券两条流进行双流join,同时迟到的数据我们会在代码里面的测流捕获到,等这支付的两条流合并成一条流,我们在跟子订单的流进行双流join,同时两边迟到的数据我们都会在测流捕获到,等三条流都join完毕,我们就获取Gaussdb的实时维度表数据,确保关联的维度信息是最新的,然后回写到dwd层kafka,最后同步到hudi或者Gaussdb的dwd层供业务方使用。
5.实现细节
针对flink的自身的几个双流join的缺点以及实时订单以及遇到的难点痛点:
1.Interval Join的缺点:
a.针对历史数据处理。Interval Join是基于EventTime事件时间来处理数据的,没有考虑重新消费历史数据会导致数据关联不上丢失数据的情况,因为Interval Join设置的窗口长度不能满足消费历史数据的时间跨度,但是如果将Interval Join的窗口长度设置很大,一旦消费的历史数据时间跨度长加上数据量也大,这样会导致flink的缓存的状态会很大,导致影响checkpoint的完成,进而影响程序的稳定性;
b.针对正在进行实时数据处理。Interval Join的窗口边界不好确定,如果数据一旦延迟超过了设置的边界,这样会导致数据关联不上进而会导致丢数据,过大的窗口长度会影响程序稳定性,同第一点;
2.Region Join(Inner Join、Left Join)会存储流进数据的所有状态,会导致flink程序的状态太大,并且同Interval join,消费历史数据会导致状态瞬间膨胀很大,导致checkpoint时间过长导致任务失败重启,进而会被压导致flink程序崩溃。
3.之前订单生产的双流join就是用的Interval Join,一旦订单kafka数据有延迟,超过了设置的窗口长度,就要通过很麻烦的补数方式来修复订单数据,不能通过重置kafka的offset至出问题之前的点位来回放数据,从而导致补数方式流程多而复杂,每次补数都浪费不少人力精力。
针对以上的缺点,我们数仓团队内部想抛弃之前的Interval Join的方式,来用全新的双流join的方式解决数据丢失、恢复回溯数据困难麻烦、缓存状态过大的问题。
这里举例是实时营销核销的场景,实时营销核销有3条流需要关联,分别是t_payment_ticket(支付券主表)、t_payment_ticket_item(支付券子表)、t_trade_order_item_area(订单子表)。
图3是t_payment_ticket跟t_payment_ticket_item进行双流join代码块,首先,我们是用了两个比较底层的算子,第一个是connet算子把两条流连接起来,Interval Join跟Region Join底层也是用connet将两条流连接起来的,然后通过业务主键分组KeyBy,最后用process算子对两条流进行计算。

图表3 支付券主表跟支付券子表join代码块
Process Function里面的核心功能可以分为四部分:
1.缓存两条流的数据到状态里面。
在process function的procesElement1方法里面图4,支付券主表的数据一进来我们会缓存到定义的ValueState图5的状态里面,与此同时在process function的procesElement2方法里面图6,支付券子表的数据一进来会缓存在定义的MapState图5里面,因为支付券子表主键是子订单id跟券id所以定义了一个MapState,防止同一个券的不同子订单的数据丢失。
2.从相对流的状态里面找到同一个key的数据,然后join输出。
在procesElement1方法里面图4,支付券主表会去支付券子表存储的状态数据,如果能在状态里找到对应的支付券子表数据,我们就把它们关联起来然后输出出去,并通过迭代器把已经找的支付券子表数据从状态中移除。同理procesElement2方法里面图6,唯一不同的是支付券子表通过在状态里面找到的支付券主表数据不能移除,因为他们之间的关联关系是一对多,如果一但某条流数据发生延迟,那个一对多关系的一是总是要往下游输出,数据才能在第二次加工时关联上。

图表 4支付券主表数据处理代码块

图表5 state初始化代码块

图表6 支付券子表数据处理代码块
3.注册定时器,触发定时器,在OnTimer方法里测流输出延迟数据。
在procesElement1、procesElement2方法里面都注册了一个定时器,两个定时器共享一个状态数据图5,定时器时间是根据业务理论上会产生多大的延迟自定义的,然后通过ProcessTime注册定时器,然后更新定时器的状态数据。最后等到达指定的定时器时间会回调onTimer方法图7,
onTimer方法里面的功能就是输出延迟数据跟清空状态,通过flink的侧流输出,输出支付券主表或者支付券子表延迟数据到下游,下游通过获取代码中的OutPutTag设置的Name。在已经确定迟到的数据往下游发了,我们会把之前定义的state图5里面的所有状态数据都清除。
4.捕获延迟数据再加工
我们会在main方法里面捕获在定时器OnTimer方法作了tag标记的延迟数据,然后调用同样的逻辑图1然后再处理一遍,只是定时器的时间长短不一样,第二道逻辑处理的时候可以根据数量大小灵活设置定时器时间大小,以免状态过大导致程序不稳定,通过从现有生产跑的任务观察来看,流入第二道处理逻辑的数据量不会太多,经过两道程序最后我们把正常双流join的数据跟迟到的双流join数据union起来成一条新的完整的流跟订单子表关联,跟订单子表关联的逻辑基本跟之前概述的是一样的,后面不做过多介绍。

图表7 定时器处理代码块

图表8 侧流输出二次加工代码块
通过Datastream API的方式,解决了上面提到的状态过大,窗口时间边界不好确定,因为Flink 自带的Interval Join采用的是EventTime事件时间,而代码的方案是ProcessTime处理时间,两者的区别就是EventTime是数据产生的时间,比如消费3天前的数据,窗口必须开3天;而ProcessTime是flink程序处理的时间,同样消费3天前的数据,比如我开窗2个小时,我只要保证我的数据能在2个小时之内消费完历史数据并赶上正常的流数据,就不会发生丢失数据的情况,所以第三个问题数据回溯问题也一起解决了。
6.总结
在业务对于实时数据指标需求的驱动下,建设数据指标更加及时的实时数仓是一个非常重要的方向,目前数仓团队的实时数仓建设已经覆盖了订单、日志、营销、售后、门店、用户、物流、商品这几大域。建设实时数仓的难点就在于面对复杂处理逻辑情况下如何保证数据的准确性,数据准确性是考核数仓非常重要的一个指标,所以无论离线还是实时我们都尽最大的努力保证数据的准确性,尤其是在实时数仓这块,我们团队探索了很多方法,也遇到不少问题和补过很多次数,经过不断的总结和分析,我们当前初步探索出一些针对复杂场景的解决办法。后续我们团队将会根据业务需求针对更多的业务域和通用场景输出的更多的实时宽表,在保证准确性及时性的前提下,保证有更多的业务可以使用到实时的指标数据。
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。