国际计费系统基于Sharding-Proxy大数据迁移方案实践

Tech 导读 本文主要介绍基于shardingproxy对大数据的迁移实践过程。通过本文读者可以对数据迁移全流程有一定了解,其中重点记录了shardingproxy全流程的搭建,对想要了解和即将要做数据迁移的读者们有一定的帮助意义。
01
背景
在今年的敏捷团队建设中,我通过Suite执行器实现了一键自动化单元测试。Juint除了Suite执行器还有哪些执行器呢?由此我的Runner探索之旅开始了!
1. 计费数据量剧增,需要将老库进行数据拆分到多个分库,数据分片;
2. 拆分规则为收付款对象(或ID)字段,进行HASH,取模(32),分32个库。
02
目标
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕
1. 实现数据从老库,按照分片规则,迁移到分库中
2. 保证数据平滑迁移,尽量停产时间最小
3. 支持回滚,同步失败,支持回滚单库
03
方案
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。从设计稿出发,提升页面搭建效率,亟需解决的核心问题有:
3.1 基于开源中间件(shardin-proxy)
基于dts+shardingproxy实现大数据迁移到32个分库中的实现原理如下图所示:
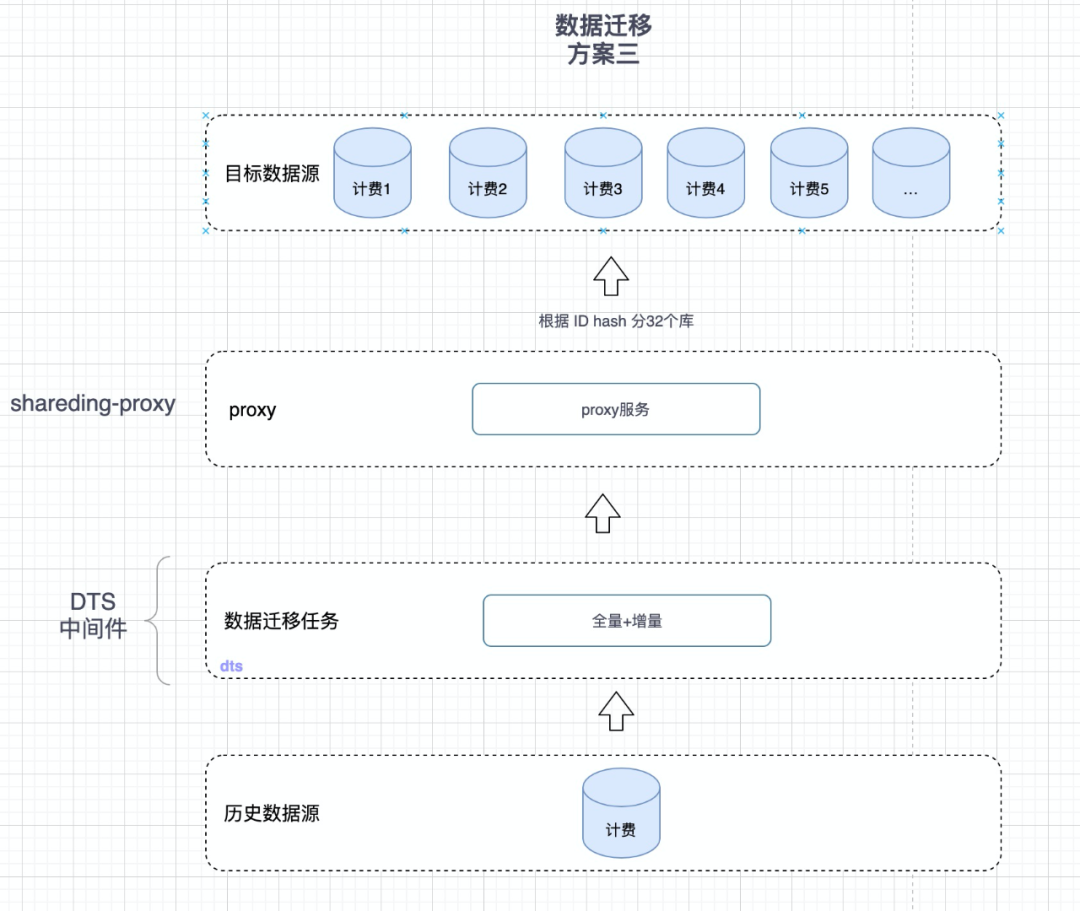
图1 开源中间件原理图
3.2 基于蜂巢中间件
基于蜂巢中间件实现数据分库分表迁移的方案原理如下图所示:
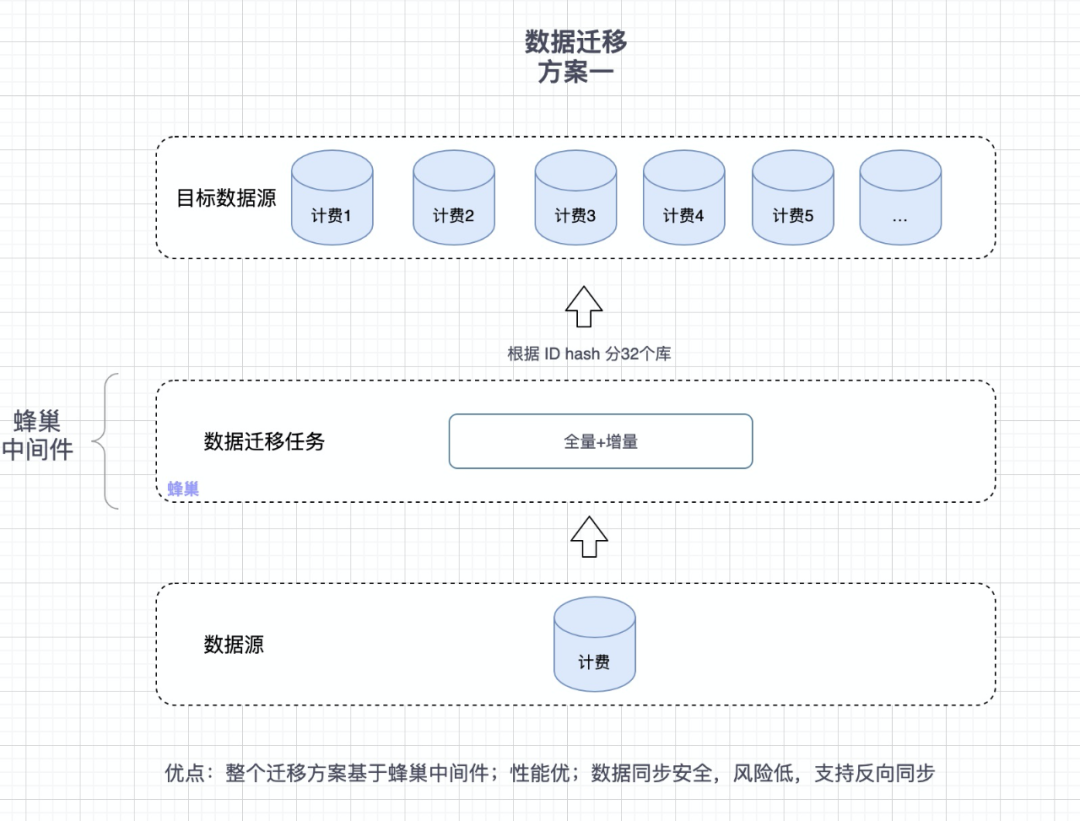
图2 蜂巢中间原理
3.3 基于半自主研发程序
1.开发数据处理程序,消费历史数据MQ;消费增量数据MQ
2. 基于dts同步历史数据(指定时间位点,同步历史)
3. 基于JDQ同步实时数据(指定时间位点,恢复实时同步)
下图简述了DTS+研发开发的数据同步方案,基于全量历史数据同步,以及实时数据同步的一种策略方案。
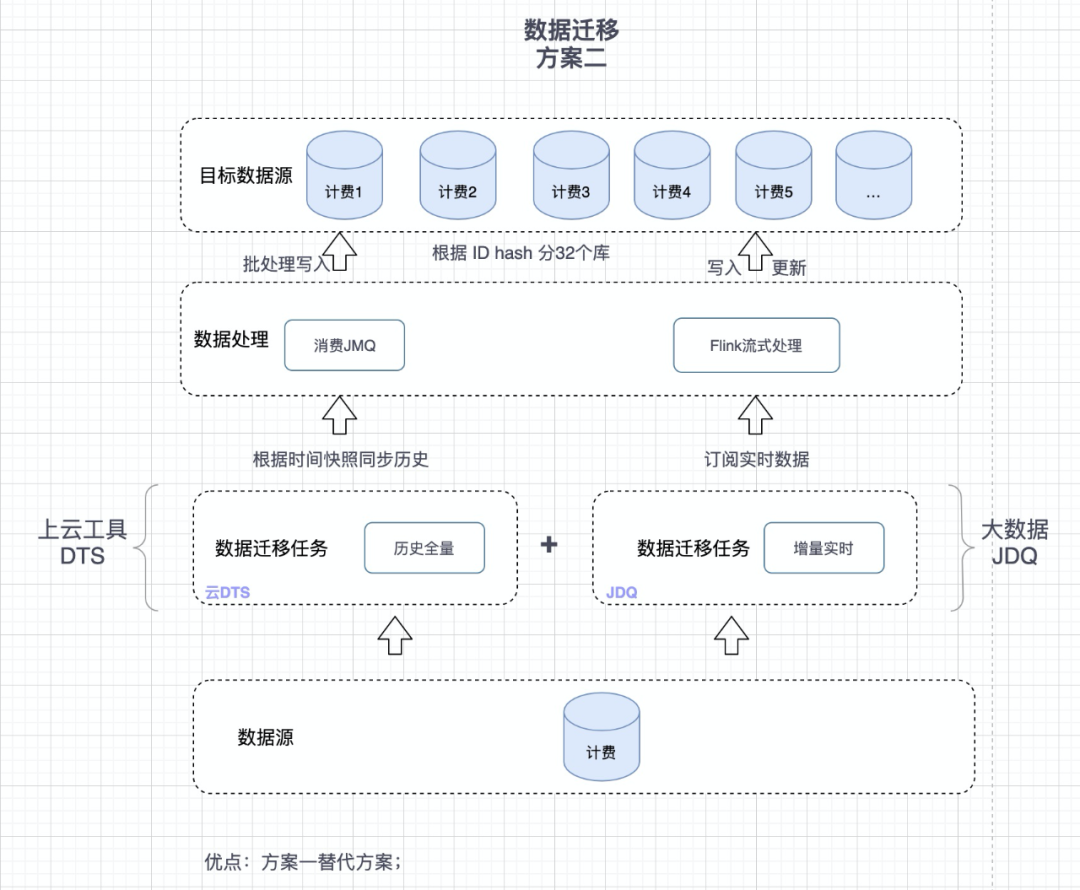
图3 半自研同步程序
3.4 基于完全自研程序
1. 开发数据查询程序,历史数据查询发送MQ写入
2. 实时数据双写
3. 统一发送MQ,由MQ异步处理写入
其主要流程为查询历史数据发送MQ同步历史数据,实时数据通过双写实现:
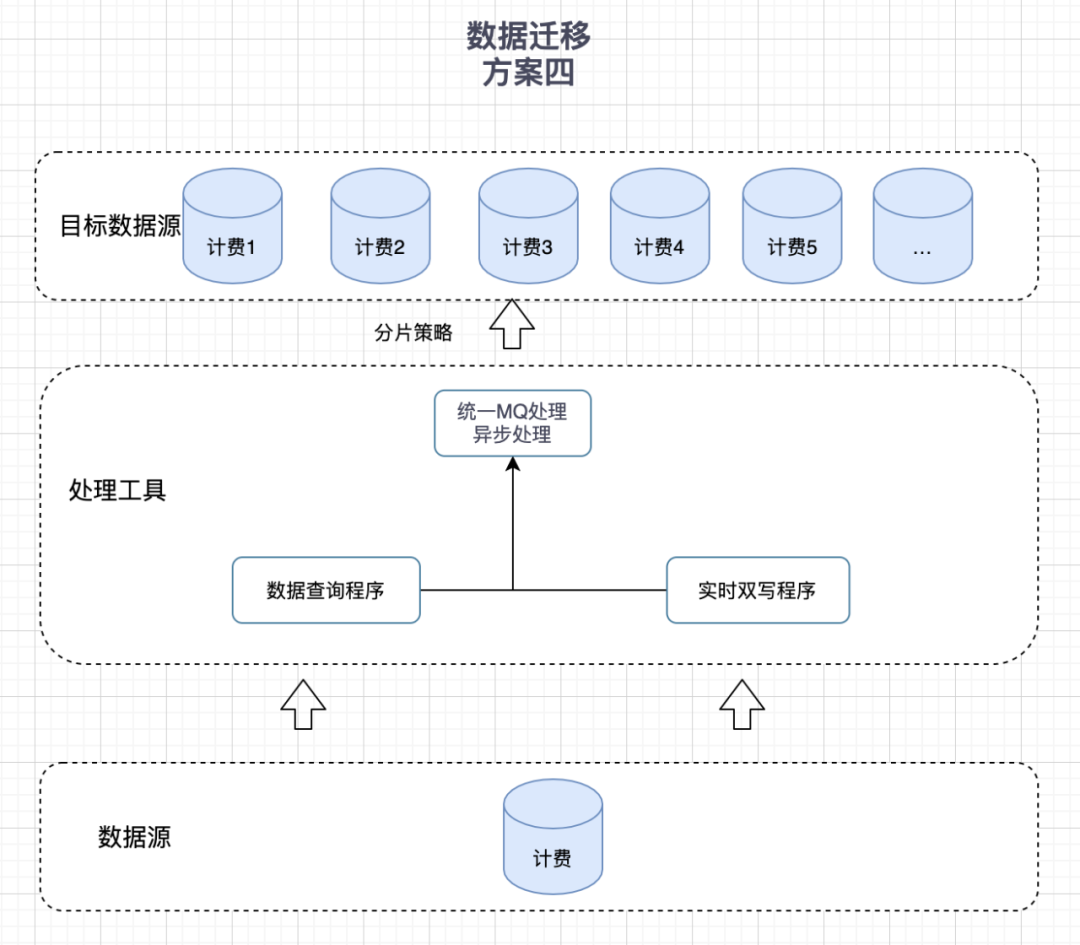
图4 自研开发程序
3.5 方案对比
方案 | 正向 | 逆向 | 高可用 | 性能 | 优缺点 |
|---|---|---|---|---|---|
基于开源中间件(sharding-proxy) | 支持 | 支持 | 高 | 高 | 优点: 基于sharding-proxy服务,无需要开发;基于成熟的中间件DTS,保证全量和增量数据的传输,支持异常位点续传。缺点: 相比蜂巢,有一定的学习成本,门槛相对高,且需要个人维护。 |
基于蜂巢中间件 | 支持 | 支持 | 高 | 高 | 优点: 整个迁移方案基于蜂巢中间件,无任何开发工作,蜂巢团队支持;数据同步安全,支持双向同步,回滚方案,风险低,整体工作量最小,支持异常位点续传。缺点: 基于蜂巢,需要蜂巢团队支持,且目前已不接新任务。 |
基于半自主研发程序 | 支持 | 否 | 低 | 中 | 优点: 同步逻辑自研,自主开发,直观按照个人理解存储分片规则;基于成熟的中间件DTS、以及大数据实时同步JDQ,保证数据同步稳定性。缺点: 数据同步存储程序自研,丢失数据、存储失败方案难以保证;工作量大,除配置工作,有大量开发工作量;缺乏反向同步方案。 |
基于完全自研程序 | 支持 | 否 | 低 | 低 | 优点: 相比蜂巢,开源中间件等,此方案无需依赖外部同步中间件;小数据量同步相对其他方案比较简单。缺点: 基于自主研发工具,开发工作量大,改造成本相当高;高可用性能无法保证,出错需要重新删数同步;同步效率低,完全依靠自己查询和写入效率。 |
04
Proxy介绍与搭建
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。从设计稿出发,提升页面搭建效率,亟需解决的核心问题有:
4.1 简介
4.1.1 设计意义
Proxy定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。目前提供 MySQL 和 PostgreSQL(兼容 openGauss 等基于 PostgreSQL 的数据库)版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作数据,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。
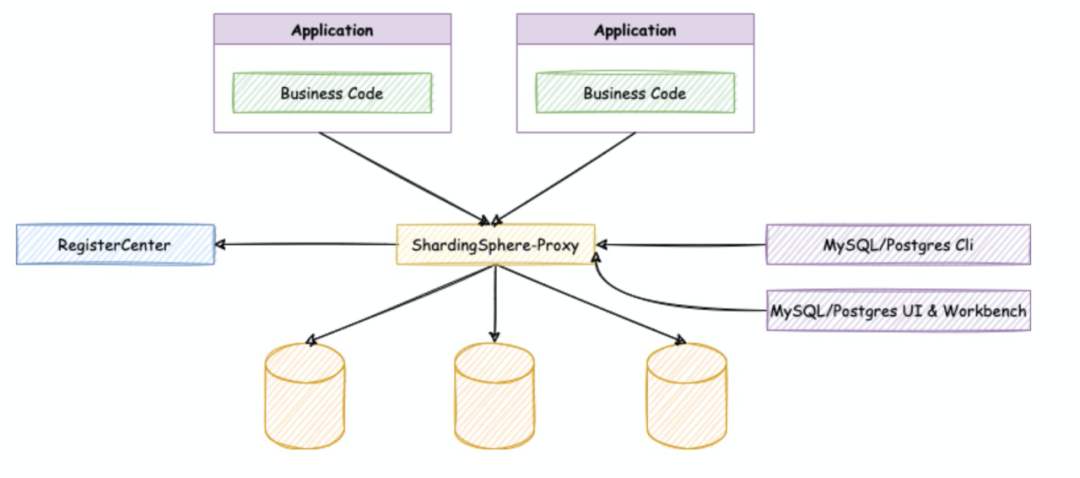
图5 shardingproxy的设计意义
数据库的代理(数据库)既可以通过客户端连接,也可以通过应用程序连接。
4.1.2 整体架构
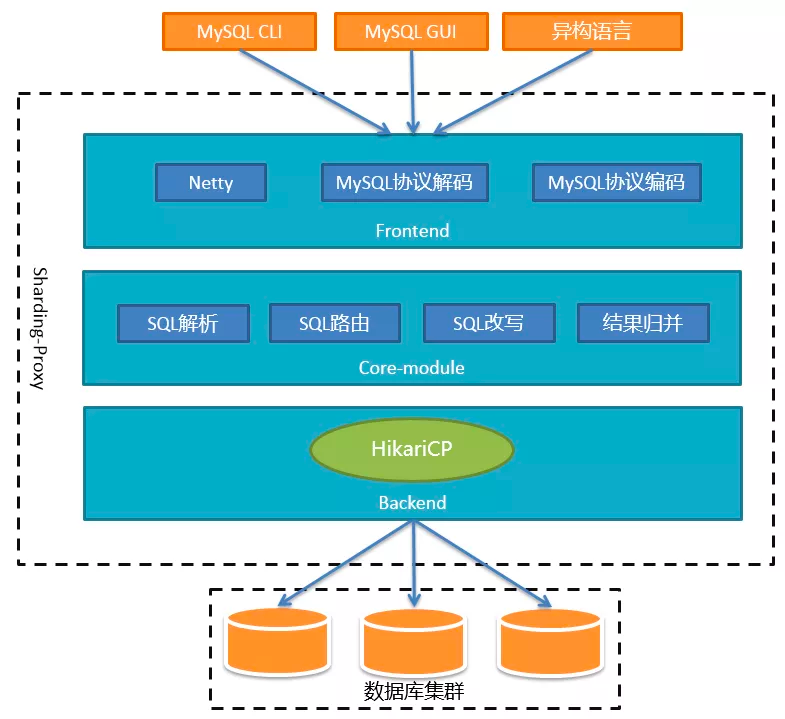
图6 sharding-proxy架构层次(官网亦可查看)
整个架构可以分为前端、后端和核心组件三部分。前端负责与客户端进行网络通信,采用的是基于NIO的客户端/服务器框架,在Windows和Mac操作系统下采用NIO模型,Linux系统自动适配为Epoll模型。通信的过程中完成对MySQL协议的编解码。核心组件得到解码的MySQL命令后,开始调用Sharding-Core对SQL进行解析、路由、改写、结果归并等核心功能。后端与真实数据库的交互目前借助于Hikari连接池。
4.2 搭建
4.2.1 关键字解读
下载,解压,安装mysql驱动,启动,完成。
4.2.2 安装shareding-proxy
安装包下载,选择合适版本(本文选用4.1.1),在官网进行下载,官网地址为
https://shardingsphere.apache.org/document/current/cn/downloads
图7 官网下载proxy版本
安装包解压(自动解压,或是命令解压),解压目录可随意指定(有权限目录均可)。
图8 proxy解压名利
解压后shareding-proxy目录:

图9 sharding-proxy目录结构
shareding-proxy配置目录conf:

图10 proxy的配置目录
4.2.3 安装mysql驱动
下载地址为
https://dev.mysql.com/downloads/connector/j/
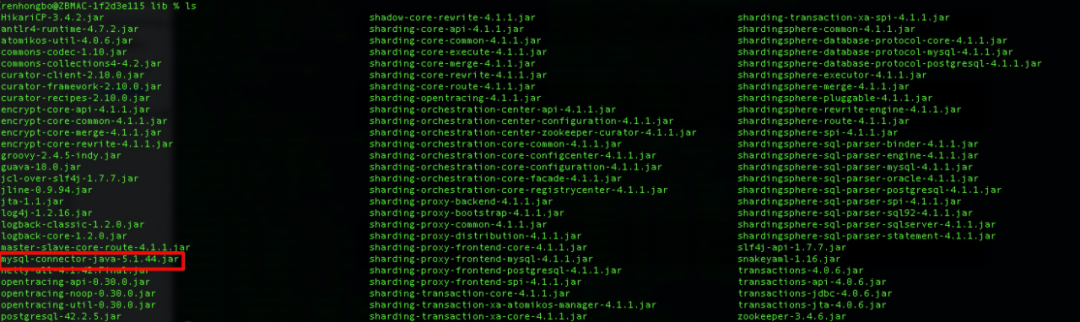
图11 mysql驱动安装
将mysql的驱动jar包(mysql-connector-java-5.1.44.jar )放在shareding-proxy的lib目录下,ShardingSphere-Proxy不带mysql驱动jar包,需要手动下载。
4.2.4 proxy启动

图12 proxy启动命令
在bin目录下,通过./start.sh启动。
4.2.5 Remark
Sharding-Proxy默认的启动端口是3307,可以修改其他端口。
4.3 配置
4.3.1 关键字解读
六大配置分别是日志配置(logback.xml),基础服务配置(server.yaml),逻辑配置(四个conf配置文件,分片(核心)/影子/读写分离/加密配置)。
本例基于server.yaml、config-sharding.yaml配置分片策略。
4.3.2 server.yaml
基础服务配置由三部分组成:
1. shareding-jdbc的编排治理配置,提供数据治理功能
图13 sharding-jdbc的编排治理配置
包含配置集中化与动态化(支持数据源,表与分片读写分离策略的动态切换)、数据治理(提供熔断数据库访问程序对数据库的访问和禁用从库的访问的能力)、支持Zookeeper和etcd的注册中心。
2. 权限配置,配置用户名和密码以及授权数据库

图14 用户权限配置
分别为:root/root和sharding/sharding,其中root默认授权所有的数据库,而sharding用户则授权sharding_db数据库。在这里的数据库(schema)是逻辑数据库,在config-*.yaml中配置对应分库映射。
3. 代理数据源参数配置
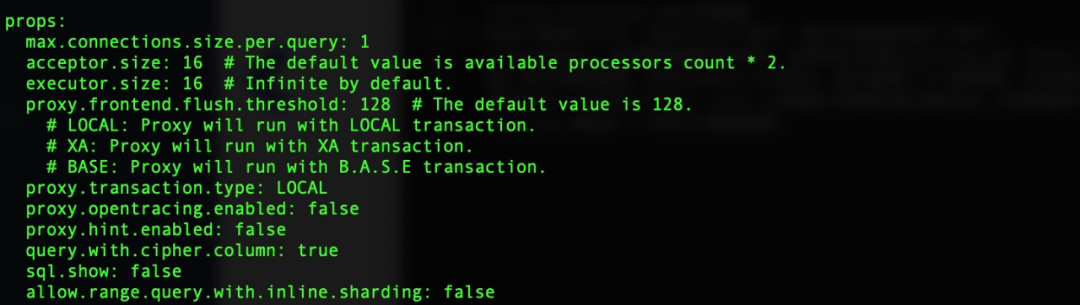
图15 数据源配置
4.3.3 config-sharding.yaml
shareding-proxy核心配置,分片规则相关配置,包含schemaName、dataSources、shardingRule三部分。
1. 逻辑库对应分库数据源的映射配置
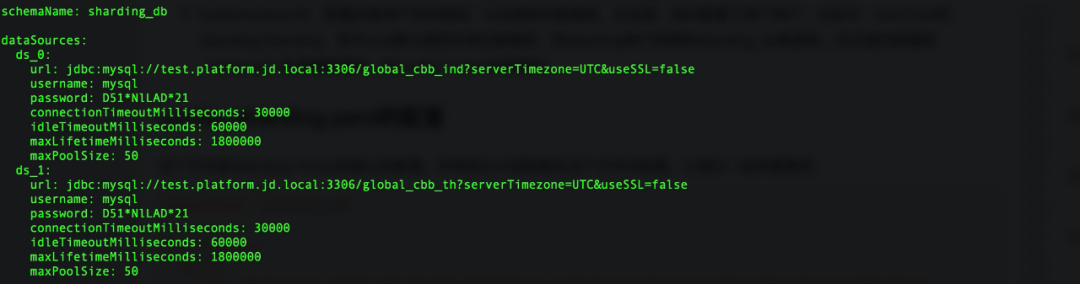
图16 逻辑库与真实库映射
schemaName逻辑库名,在server.yaml声明的授权的schema就是这里的schemaName,dataSources为数据源配置,本例映射俩个分库(ds_0,ds_1),ds_${0..1}对应逻辑分库名,url填写实际库。
4.3.4 logback.xml
基于logback的日志配置。
4.3.5 剩余三项配置
config-shadow.yaml/config-master_slave.yaml/config-encrypt.yaml分别为影子库配置,主从配置,数据字段加密配置。
05
调试
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
基于搭建ShardingSphere-Proxy代理选择直连工具客户端
1. 用Navicat或者mysql命令直连
2. 手动mysql命令链接如下




图17 proxy调试
基于本地测试查询不带拆分键默认搜全库,新增默认根据拆分键路由对应真实库。
06
数据迁移
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
迁移三步
1. 线上安装sharding-proxy
2. 数据同步:创建迁移任务,启动同步,原理即是创建DTS任务
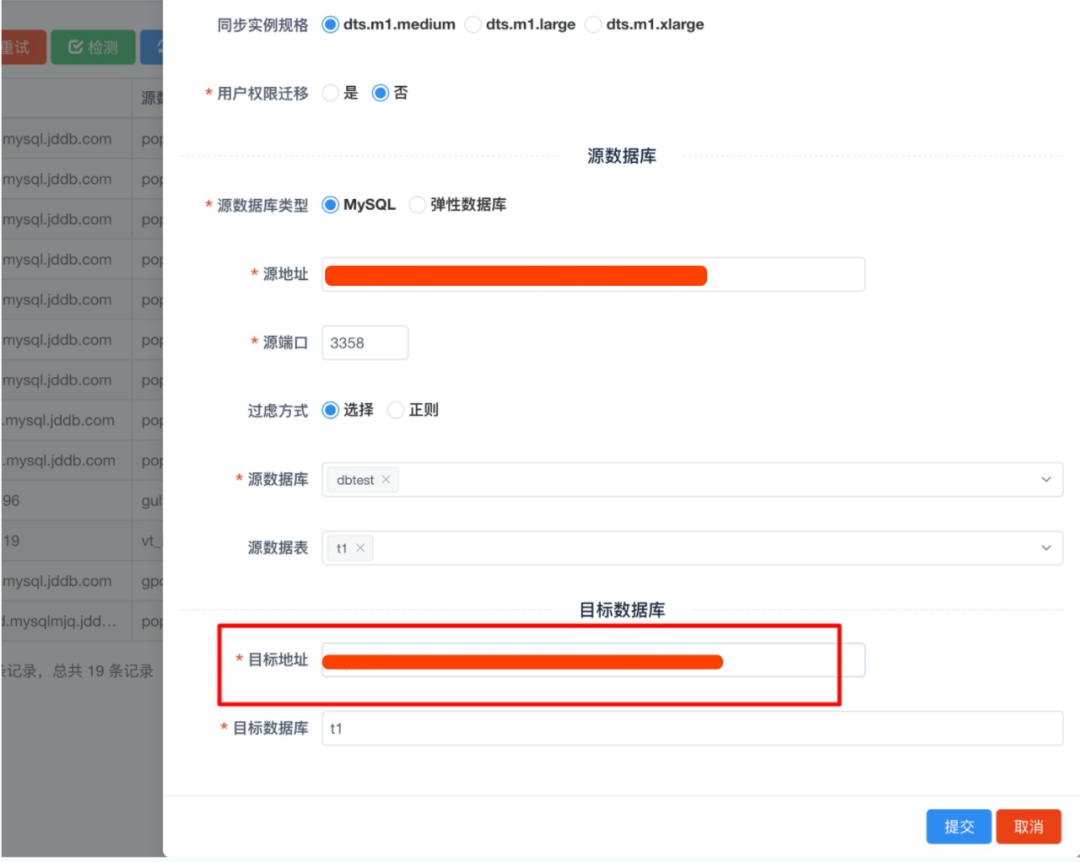
图18 基于dts创建迁移任务

图19 建立多个dts任务
3. 数据完整性校验
(1)全量比对,整体同步进度查询(2)时间分段比对,按照各个时间段抽样进行新库老库总量比对,手动校验。

(2)时间分段比对,按照各个时间段抽样进行新库老库总量比对,手动校验。
基于proxy查询数据总量与老数据库总量进行比对校验数据


图20 全量数据比对
(3)随机抽样比对:随机新库某个时间段的数据逐条进行比对,手动工具校验。手动根据开发工具分别抽样查询,并查询出的数据与老库进行比对。
(4)全量数据校验:对比同步数据进行全量数据校验,根据DTS工具进行校验,耗时较长。

图21 基于dbs数据比对任务
07
配置查询机
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
基于easyops或者myops配置物流指定查询机,通过查询机查询proxy代理实现。
08
问题总结与案例
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
整体数据迁移过程中遇到的最大的问题即是数据不可测,针对各种历史数据问题导致数据迁移中断造成返工,清理垃圾数据,重新迁移。
8.1 拆分键为空
拆分键为空默认不支持
记录真实迁移中拆分键为空场景:

图22 拆分键为空场景
8.2 更新拆分键
更新语句默认不支持更新拆分键(实际4.x不支持更新带拆分键,5.x已经支持更新带拆分键不改的情况下)。
Unknown exception: [INSERT INTO .... ON DUPLICATE KEY UPDATE can not support update for sharding column.]8.3 针对以上两种异常的解决方法
拆分键不能为空,设置默认拆分键;更新带拆分键,升级sharding-proxy到5.x或配置同步DTS去掉拆分键更新。
8.4 sharding配置多从案例
在数据迁移,配置sharding-proxy的分库分表规则,以及主从规则,此处遇到了多主多从问题。
针对sharding-jdbc或者sharding-proxy配置多从,在网上很少有一些明确的案例,在此,本文基于sharding-jdbc代码完善多从的配置如下:
【plain】
spring.shardingsphere.datasource.names= defaultmaster,slave0,slave1(省略其他分库)
spring.shardingsphere.sharding.default-data-source-name=groupname1
spring.shardingsphere.sharding.master-slave-rules.groupname1.master-data-source-name=defaultmaster
spring.shardingsphere.sharding.master-slave-rules.groupname1.slave-data-source-names[0]=slave0
spring.shardingsphere.sharding.master-slave-rules.groupname1.slave-data-source-names[1]=slave1
spring.shardingsphere.sharding.master-slave-rules.groupname1.load-balance-algorithm-type=round_robin、
09
参考资料
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
以下为读者可以参考的资料:
https://www.jianshu.com/p/20c0d4114632
https://shardingsphere.apache.org/document/current/cn/overview/#shardingsphere-proxy
https://shardingsphere.apache.org/document/current/cn/features/shadow/concept/
https://shardingsphere.apache.org/document/current/cn/downloads/
https://dev.mysql.com/downloads/connector/j/
https://logback.qos.ch/