会员权益核心引擎ZCube原理与实践

Tech 导读 目前会员权益业务已经步入成熟期,自有场用户已经趋于饱和状态,而新的突破口是利用权益和积分杠杆来撬动商城场的用户,达到金融App用户增长,能撬动多少用户就要联合金融各业务线、利用权益来进行用户的渗透,而每个业务线对权益的渗透过程,都有着各自的利益点和独到之处。因此权益系统能否支持“业务规则类需求”的灵活定制占据举足轻重的地位。如何解决规则开发的效率问题,最大化解放开发团队成为目前最大的技术挑战点。规则引擎作为特定领域工具,顺理成章的成为这个挑战点的“关键解法”。 有了明确的目标和诉求后,本文调研了常见的规则引擎系统,对Drools、Urule、Aviator、QLExpress等功能做了深入的源码研究,结合目前的业务场景开发了一款适合自身业务功能的规则引擎:ZCube,它既包含了丰富的可视化规则建模设计器,如:脚本式、向导式等,又支持高可用易扩展的架构体系。支持将多个规则打包为知识包文件,在管控平台和业务系统之间进行灰度发布推送、全量发布推送、推送轨迹管理、版本管理、历史版本回退以及知识包执行告警、健康度监控等,实现了让业务规则以知识的形式保存在知识库中,可以在规则发生变动时轻易做出修改,结合后管下发能力实现规则热插拔和热更新。同时可视化界面更易于理解,可以有效地弥补业务分析师和开发人员之间的沟通问题。
01
ZCube规则引擎在我的优惠券中的应用
在今年的敏捷团队建设中,我通过Suite执行器实现了一键自动化单元测试。Juint除了Suite执行器还有哪些执行器呢?由此我的Runner探索之旅开始了!
1.1 现状
营销中台作为券的“供应链端”,控制券的所有类型。我的优惠券作为工具,提供用户已有优惠券的展示列表,不同类型的券利益点不同,运营会提供各自展示规则。谋略作为用户触达方,为了提高券的核销率,会对用户做过期提醒push,同时触达文案要求跟券的营销文案一致。
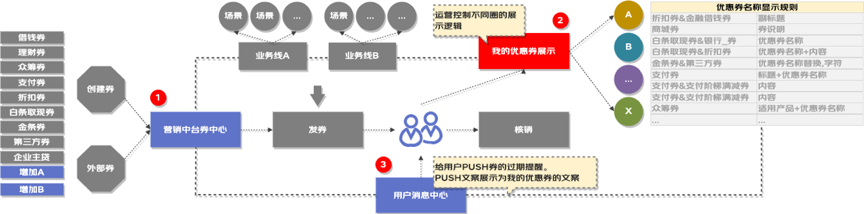
图1 营销中台控制所有券类型
1.2 挑战点
1. 营销中台每次新增券类型,都需要运营指定营销文案后,由研发硬编码实现。能不能支持业务运营人员根据需求灵活扩展,动态配置营销文案,并且能够及时生效呢?
2. 消息中心的push提醒文案需要跟营销展示文案一致,那就由业务侧研发硬编码实现一套,消息中心侧实现一套,并且还得保证两处的规则逻辑一致才可以。
能不能将这种相同的规则抽取出来,以订阅的方式下发到订阅者上去,既保证规则的唯一性,也能够做到规则共享?
1.3 解决方案
鉴于上述场景的痛点,本文将接入ZCube平台来解决。
1.3.1接入ZCube
首先,在ZCube平台接入我的优惠券应用。

图2 ZCube平台中接入我的优惠券应用
其次,搭建优惠券运营玩法规则。
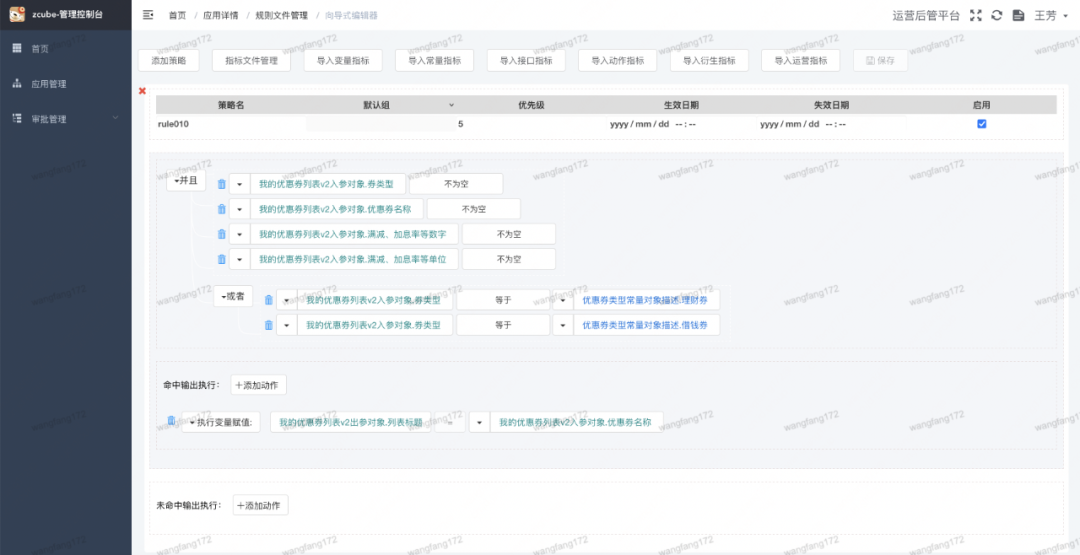
图3 搭建优惠券运营玩法规则
最后,发布知识包。
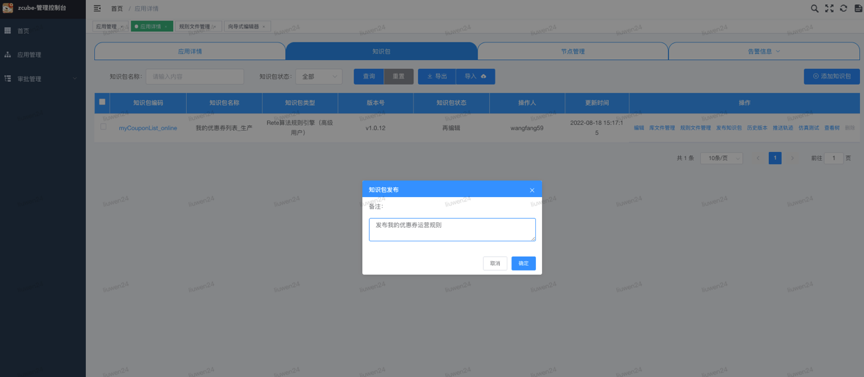
图4 发布知识包
1.3.2应用系统接入SDK
maven坐标依赖:
<!--规则引擎客户端SDK -->
<dependency>
<groupId>***.rule.*</groupId>
<artifactId>rule-core-client-spring</artifactId>
<version>1.0.1-SNAPSHOT</version>
</dependency>api调用:
RuleExecutionResultruleExecutionResult = ruleExecuteService.fireRules(knowPackageName, param);1.3.3AB方式灰度上线
为了保证现有功能的稳定,需采用AB方式灰度上线,配置在白名单内的用户走规则引擎执行的逻辑,否则走原硬编码逻辑。
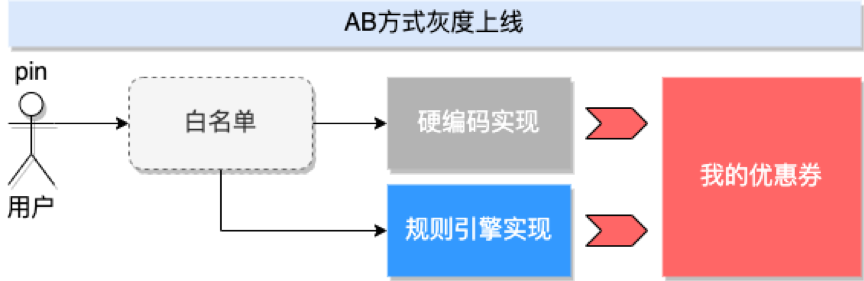
图5 采用AB方式灰度上线
1.3.4结果展示
C端页面展示:

图6 C端页面
SGM执行方法监控,tp99基本在1ms,cpu及内存较稳定,对系统原业务逻辑基本无影响。
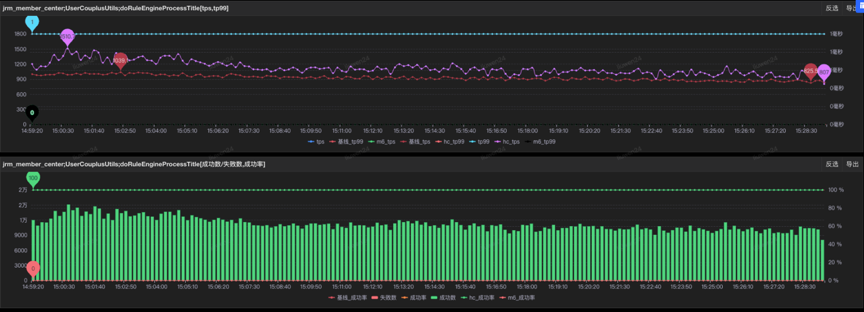
图7 tp99基本在1ms
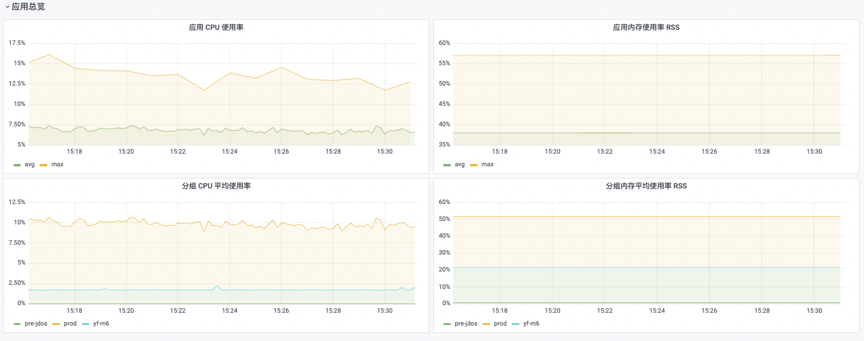
图8 cpu及内存较稳定
通过以上案例可以了解到ZCube可以利用可视化配置、订阅等功能解决业务灵活配置和规则共享输出的能力。为了更灵活的使用这个平台,接下来本文会对平台的核心功能做详细分析。
02
ZCube核心原理介绍
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
首先来了解一下ZCube有哪些核心功能,如下图:
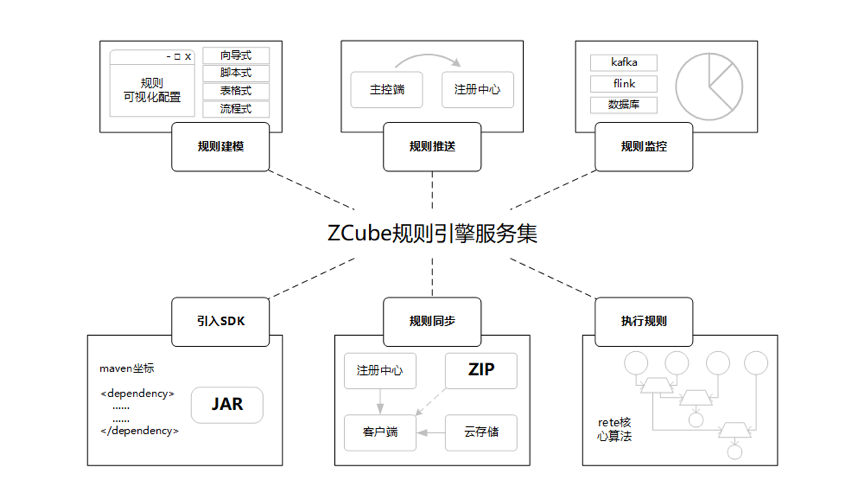
图9 ZCube核心功能
接下来本章将重点介绍其中两块核心功能:
1. 规则建模:根据规则设计器,解释成描述业务规则关系的RETE算法网络。
2. 规则执行:将RETE算法网络实例化并用事实数据进行验证,做模式匹配找出命中的规则并执行相应动作。
2.1 规则建模
提到建模,就必须先了解ZCube提供了哪些规则设计器。目前ZCube支持了脚本式、向导式两种可视化配置的规则设计器。
1. 脚本式:抽象出业务专家的领域模型,将常用的领域语言抽象成DSL:即非程序员的编程语言,让业务人员可以利用其熟悉的领域语言去描述特定领域的业务规则。
2. 向导式:让业务人员可以通过拖拉拽的可视化配置形式,操作成自己需要的业务规则逻辑。
二者描述的规则建模过程,具体抽象为:
步骤 | 脚本式 | 向导式 |
|---|---|---|
1 | 抽象领域语言编写DSL即:利用ANRTL定制规则脚本 | 定义XML规范,根据用户可视化配置操作,形成XML规范文件 |
2 | 利用ANTLR插件生成DSL对应的抽象语法树 | XML解析为Element对象 |
3 | 根据抽象语法树对应的类,提取成统一的Rule集合对象 | Element解释成Rule集合对象 |
4 | Rule集合对象解释编码成对应的RETE算法网络 | |
差异点:
规则文件建模的原理不一样,一个是利用DSL,另一个是利用XML,所以这两种文件的解析模式不同。
共同点:
1. 均需要各自解析为Rule集合对象,统一对象来描述规则。
2. 均需要根据Rule集合对象生成RETE算法网络。
2.1.1相关知识点介绍
在上述描述中,涉及到了几个核心的知识点,如果没有相应知识储备,可能对接下来的理解有一定困难,所以这里将做一下简单介绍:
1. 什么是DSL、哪些场景适合用DSL、如何设计DSL。
2. 什么是ANTLR、如何使用。
3. 什么是RETE算法。
首先,什么是DSL
(1)DSL定义
DSL的全称是Domain Specific Language,即领域特定语言,一种为特定领域所设计的编程语言。可以简单的理解为可以通过设计DSL来设计一套语法,用来描述某些领域的一系列相关行为。
举个最常见的DSL例子:SQL解决的是从特定格式的磁盘文件中查找数据的特有领域的DSL。Mysql、SqlServer等不同数据库厂商数据文件存储格式不同,对应的DSL也不同。之所以不直接使用机器指令编写代码,就是因为抽象后的DSL比编程语言更加直观,相对而言门槛更低,更容易上手。
(2)什么场景适合用DSL?
简单来说当用户不是系统的开发者,但又需要定制逻辑的时候,就需要一门DSL。比如:风控规则引擎系统,需要业务运营定制一些列复杂的风控逻辑。再比如权益营销系统,需要运营指定一系列营销工具的用户参与逻辑、发奖逻辑等等。
(3)如何设计DSL?
学过编程原理的读者都知道高级语言转机器指令需要经过一系列的过程,根据与机器的相关性大体分为前、后两端:
前端:与源语言有关而与机器无关,即仅与编译的源代码相关,将源代码转换为中间代码。包括:
- 词法分析(Token):将一些文本序列进行识别,识别出一个一个Token,并确认其词类型。
- 语法分析(Parser):将Token流进行分析组合形成语句,如果语法分析通过,就可以得到一颗以树状的形式表现编程语言语法结构的抽象语法树AST。
- 语义分析:是对结构上正确的源程序进行上下文有关性质的审查,比如类型审查等。
后端:与机器有关,即将中间代码适用于(不同类型的)机器上。包括:
- 字节码。
- 目标代码。
其次,什么是ANTLR?
ANTLR是前人造出来的很好用的DSL语言解析框架,能够大幅度减少编写DSL的时间,可以根据自己定义的语法(符合EBNF即:扩展巴科斯范式)自动生成语法解析器,允许使用Visitor模式和Listener模式访问生成好的AST。具体使用步骤如下:
(1)在Idea的插件库里先安装ANTLR插件
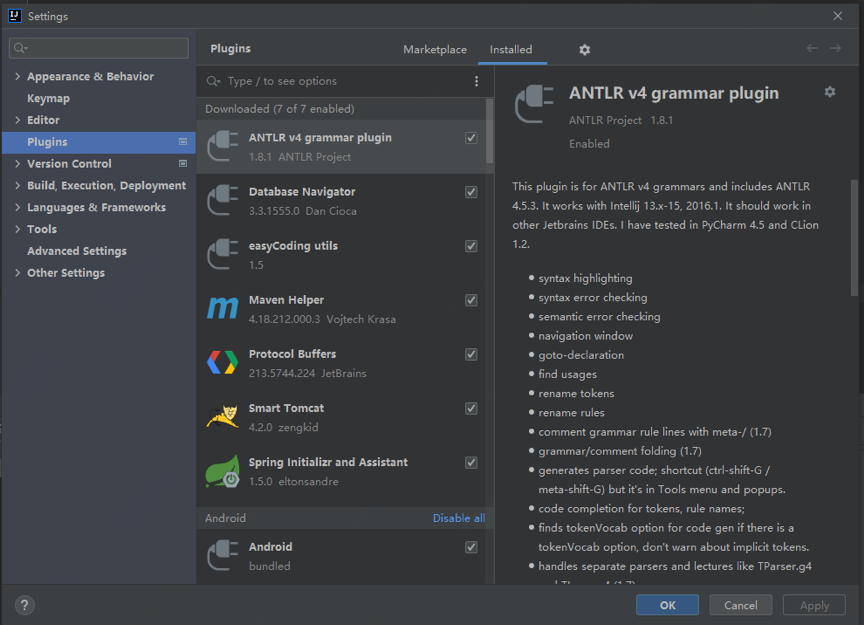
图10 在Idea的插件库里安装ANTLR插件
(2)定义词法
lexergrammar ZCubeLexer;
//常用函数
COUNT : 'count';
AVG : 'avg';
....
//数据类型
Datatype : 'String'
| 'int'
| 'Integer'
| 'double'
...
;
//操作符
GreaterThen : '>'|'\u5927\u4e8e';
GreaterThenOrEquals : '>='|'\u5927\u4e8e\u7b49\u4e8e';
LessThen : '<'|'\u5c0f\u4e8e';
LessThenOrEquals : '<='|'\u5c0f\u4e8e\u7b49\u4e8e';
Equals : '=='|'\u7b49\u4e8e';
...
//运算符
ARITH
:
'+'
| '-'
| '*'
| '/'
| '%'
;
...(3)定义语法
grammarZCubeParser;
import ZCubeLexer;
Def : ('rule'|'\u89c4\u5219') STRING
attribute*
left
right
other?
('end'|'\u7ed3\u675f') ';'?
;
attribute :loopAttribute
| salienceAttribute
| effectiveDateAttribute
| expiresDateAttribute
...
;
left :
('if'|'\u5982\u679c')
condition?
;
condition : leftParen condition rightParen #parenConditions
...
;
leftParen : '(';
rightParen : ')';
right : ('then'|'\u90a3\u4e48')
action*
;
other : ('else'|'\u5426\u5219')
action*
;
action : outAction ';'?
| methodInvoke ';'?
...
;
outAction : 'out''(' complexValue ')';
methodInvoke : beanMethod'('actionParameters?')';
...(4)在编写好的DSL上配置生成项
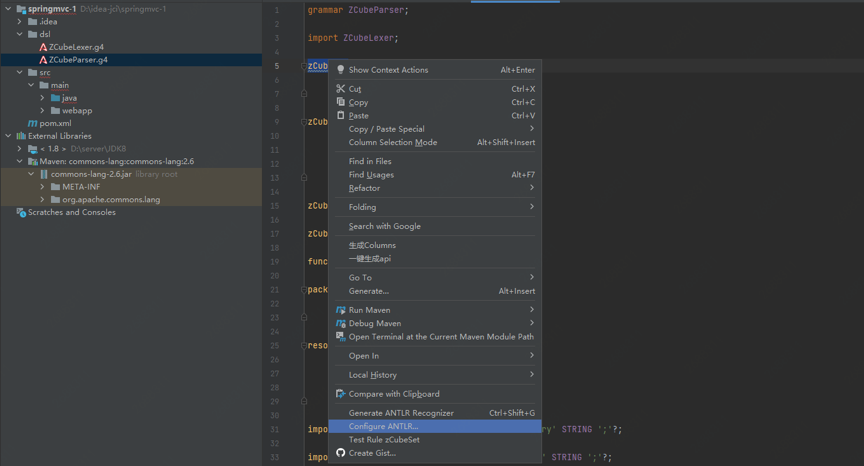
图11 配置生成项
配置生成路径、包名、生成代码的语言类型以及AST的访问模式,默认Listener。
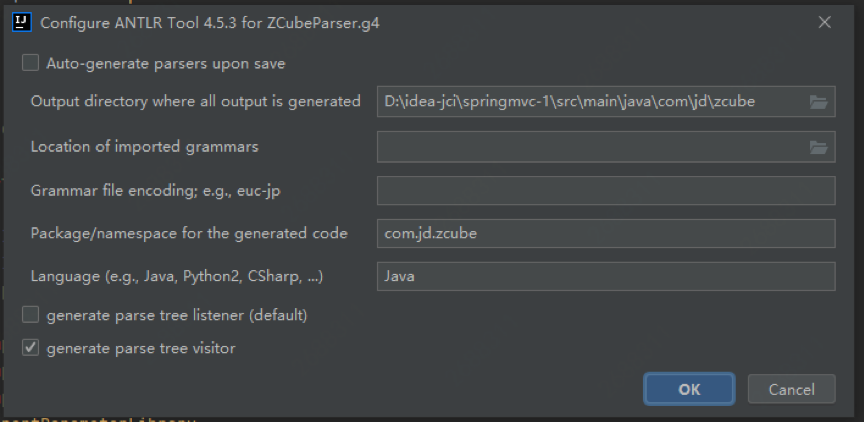
图12 配置生成路径、包名、生成代码的语言类型以及AST的访问模式
(5)生成DSL对应的Java代码
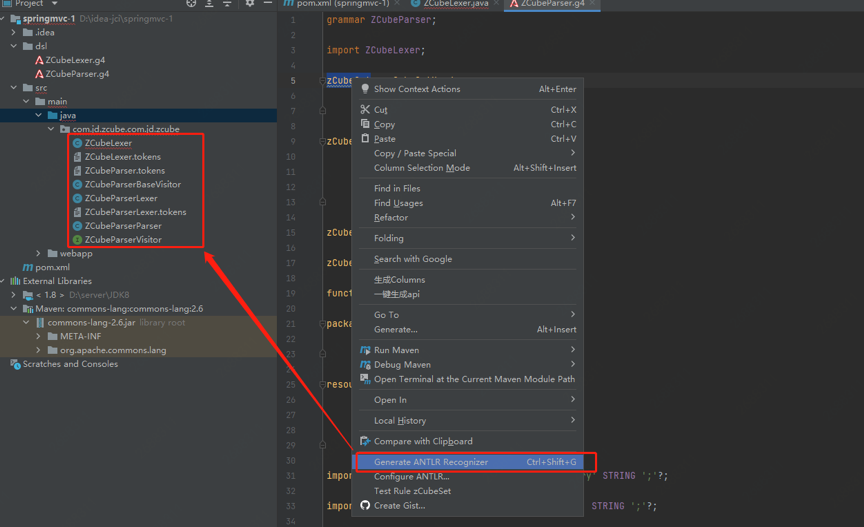
图13 生成DSL对应的Java代码
(6)验证ANTLR
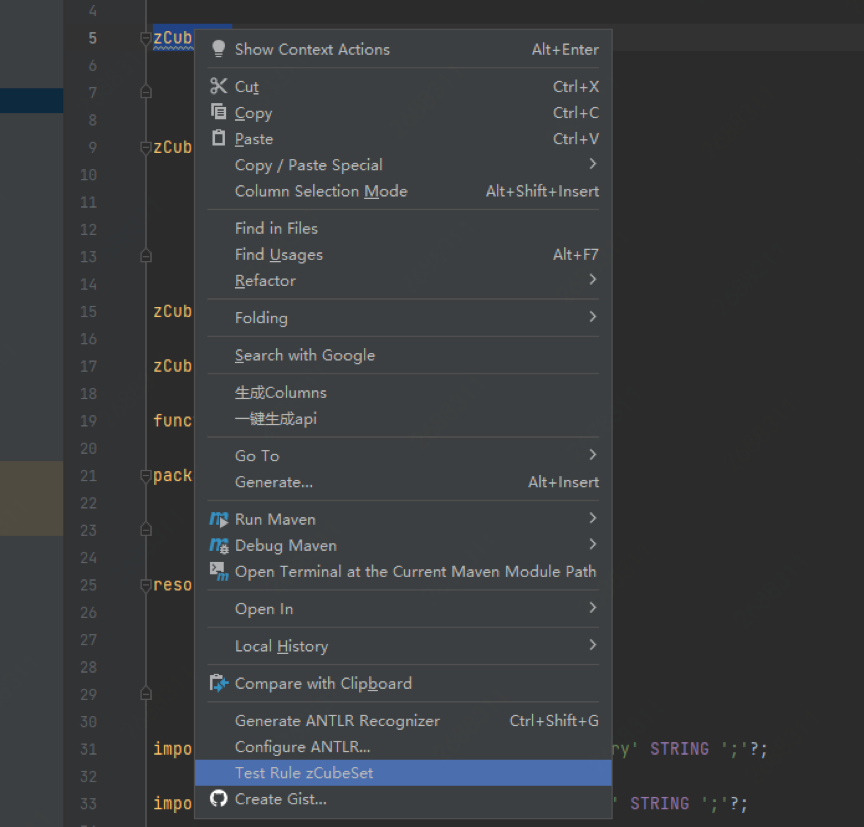
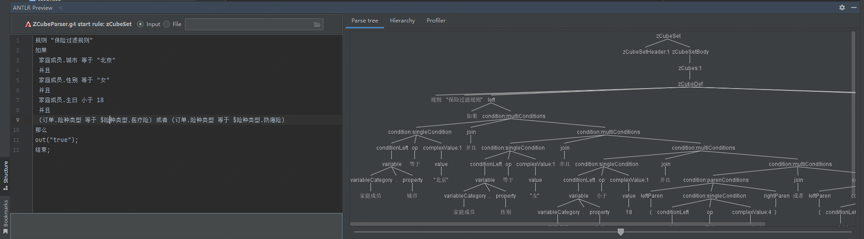
图14、15 验证ANTLR
通过以上方式就可以生成所需代码,接下来继续编写需要的业务逻辑就可以实现自定义DSL。
最后,什么是RETE算法?
RETE算法是Charles Forgy在1979年的论文中首次提出的,针对基于规则知识表现的一种高效的模式匹配算法,它通过缓存避免了相同条件多次评估的情况,利用空间换时间,用内存换取匹配速度;它通过规则条件生成了一个网络,每个规则条件是网络中的一个节点,再将数据送入推理网络进行匹配筛选。与之相关的概念包括:
- Fact(事实):对象之间及对象属性之间的关系。
- Rule(规则):是由条件和结论构成的推理语句,一般表示为If…Then。一个规则的If部分称为LHS(left-hand-side)左手树,Then部分称为RHS(right hand side)右手树。
- Module(模式):就是指IF语句的条件。这里IF条件可能是有几个更小的条件组成的大条件。模式就是指的不能在继续分割下去的最小的原子条件。
- 节点类型:RETE网络的节点可以分为五类:根节点(Root)、类型节点(TypeNode)、Alpha节点、Beta节点、Terminal节点。
- 根结点:是一个虚拟节点,是构建RETE网络的入口。
- 类型节点:用来存储事实的各种类型,各个事实从对应的类型节点进入RETE网络。
- Alpha节点:也称单输入节点,即简单理解为规则中的模式。
- Beta节点:也称双输入节点,又分别表示And节点、Or节点等。
- Terminal节点:是一条规则的末尾节点,它代表一个规则匹配结束,当事实或元组传递到Terminal节点时,表示该Terminal节点对应的规则已被激活。
对应于RETE算法的介绍,网上已有大量的相关文章,在这里推荐一篇介绍比较详细的文章:RETE算法,感兴趣的读者可以查阅。
在了解这些基础概念后,下节将结合示例具体分析脚本式、向导式的建模过程。
2.1.2脚本式建模原理介绍
首先,基于ANTLR定制词法规范、语法规范、生成词法解析器、语法解析器等代码。
文件名称 | 文件描述 |
|---|---|
ZCubeLexer.java | 此文件由ZCubeLexer.g4文件生成,描述公用的词法符号。 |
ZCubeLexer.tokens | 此文件由ZCubeLexer.g4文件生成,的词法符号。 |
ZCubeParser.tokens | ANTLR会给每个我们定义的词法符号指定一个数字形式的类型,然后将它们的对应关系存储于该文件中。有时,我们需要将一个大型语法切分为多个更小的语法,在这种情况下,这个文件就非常有用了,可以很方便划分不同规则或者功能的词法。 |
ZCubeParserLexer.tokens | |
ZCubeParserLexer.java | ANTLR能够自动识别出我们的语法中的文法规则和词法规则。这个文件包含的是词法分析器的类定义,词法分析器的作用是将输入字符序列分解成词汇符号。 |
ZCubeParserParser.java | 该文件包含一个语法分析器类的定义,这个语法分析器专门用来识别我们的“数组语言”的语法ArrayInit。在该类中,每条规则都有对应的方法,除此之外,还有一些其他的辅助代码在后续的listener、visitor类中访问。 |
ZCubeParserVisitor.java | Antlr提供了listener、visitor两种访问器,目前我们采用自定义更加灵活的visitor方式。此类是根据我们的ZCubeParser.g4文件,针对访问我们的规则及定义的访问点生成的接口类。 |
ZCubeParserBaseVisitor.java | 它是针对ZCubeParserVisitor接口默认生成的实现类,所有实现方式都是用antlr默认的继续执行。要想改变针对规则及当前访问点的执行数据,需要我们新建类来继承此父类,并覆盖其中的方法。保证修改点与生成点分离。 |
该表中是ANTLR生成的Java类以及每个类用途的具体介绍。
其次,自定义语法树的遍历策略,提取Rule集合对象。
public ZCubeSet build(String script) throws IOException{
ANTLRInputStream antlrInputStream=new ANTLRInputStream(script);
ZCubeParserLexer lexer=new ZCubeParserLexer(antlrInputStream);
CommonTokenStream tokenStream=new CommonTokenStream(lexer);
ZCubeParserParser parser=new ZCubeParserParser(tokenStream);
BuildZCubesVisitor visitor=new BuildZCubesVisitor(contextBuilders,tokenStream);
ZCubeSet ZCubeSet=visitor.visitZCubeSet(parser.ZCubeSet());
rebuildZCubeSet(ZCubeSet);
String error=errorListener.getErrorMessage();
if(error!=null){
throw new ZCubeException("Script parse error:"+error);
}
return ZCubeSet;
}其中VisitZCubeSet就是继承自ZCubeParserBaseVisitor.java后需要重写的方法,在此方法中自定义实现Rule集合对象的逻辑封装过程。
Rule对象,例举几个重要字段:
属性 | 类型 | 功能 |
|---|---|---|
name | String | 规则名称 |
lhs | Lhs | 左手树:规则中的if部分 |
rhs | Rhs | 右手树:规则中的then部分 |
other | Other | 其他:规则中的else部分 |
其中最主要的是LHS、RHS、Other三个部分的组成。
LHS:包含3种节点
Criteria | 原子节点 |
|---|---|
Junction-And | “与”节点 |
Junction-Or | “或”节点 |
Other、RHS: 包含可执行的Action动作。
接着,根据Rule集合对象生成RETE算法网络。
简单来说,就是通过串联各节点之间的From、To关系形成一个树形网络。具体过程将通过以下两部分进行详细介绍:
- 各节点的核心属性。
- RETE网络的形成过程。
先来介绍一下每个节点对应的核心属性:
类型节点 | ObjectTypeNodes |
|---|---|
原子节点 | CriteriaNode |
关联节点 | AndNode |
终端节点 | TerminalNode |
在了解完每个节点的基础属性后,下面就是RETE网络树的形成过程:
- 1. 遍历Rule集合对象。
- 2. 拿到规则N,从规则N中取出“跟对象”。
- a) 判断对象类型。根据类型创建RETE网络中对应的节点。
- 如果是“与”类型,取出当前对象的子对象集合,遍历该集合。
- i) 根据PreNode、子对象,递归a)直到返回结果为原子节点:Node-N。
- ii) PreNode的孩子节点中是否包含Node-N,否:创建And节点,是:把PreNode置为Node-N。
- 重复 i) 直到子对象集合遍历完毕。
- 如果And节点不为空:返回该节点,否则:返回Node-N。
- 如果是“或”类型,取出当前对象的子对象集合,遍历该集合。
- i) 根据子对象,递归a)直到返回结果为原子节点:Node-N
- 重复 i) 直到子对象集合遍历完毕。
- 如果是原子类型:
- 检查模式1中的参数类型,如果是新类型:添加一个类型节点,否则:找到该类型节点。
- 检查在该类型节点下对应的原子节点是否存在,如果存在:记录下节点的位置,如果没有:将模式1作为一个原子节点加入到网络中。
- 如果是“与”类型,取出当前对象的子对象集合,遍历该集合。
- b) 获取到 a) 的执行结果,并在此节点上创建绑定规则N的终端节点,至此规则N处理完毕。
- a) 判断对象类型。根据类型创建RETE网络中对应的节点。
3. 重复2,直到所有规则处理完毕。
通过逻辑处理生成的RETE网络如图:
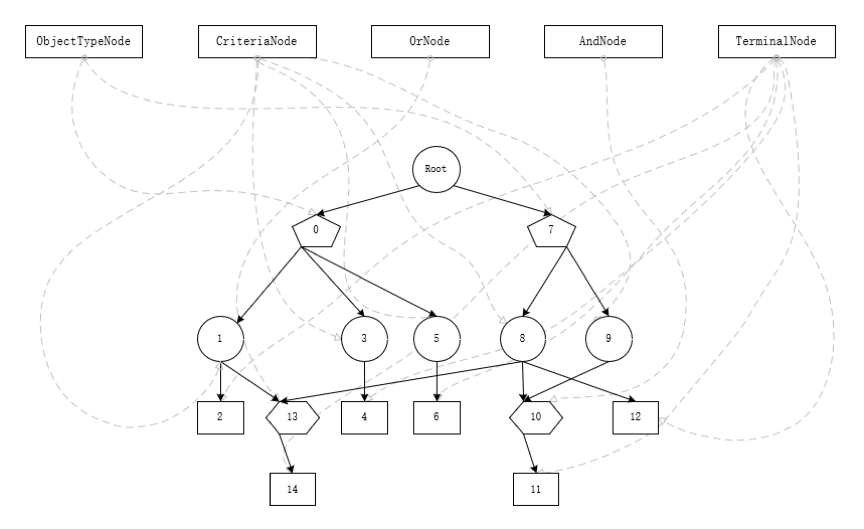
图16 通过逻辑处理生成的RETE网络
最后,结合示例分析上述原理过程。
若规则脚本如:
规则"保险过滤规则"
如果
家庭成员.城市 等于 "北京"
并且
家庭成员.性别 等于 "女"
并且
家庭成员.生日 小于 18
并且
(订单.险种类型 等于 $险种类型.医疗险) 或者 (订单.险种类型 等于 $险种类型.防癌险)
那么
out("true");
结束;示例中AST里提取的Rule中的LSH/RHS/Other如下图所示:
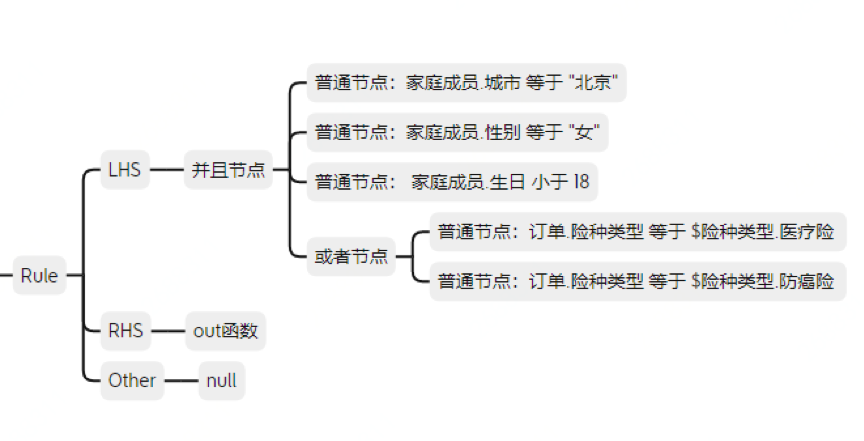
图17 AST里提取的Rule中的LSH/RHS/Other
根据Rule集合对象生成的RETE网络如下图:
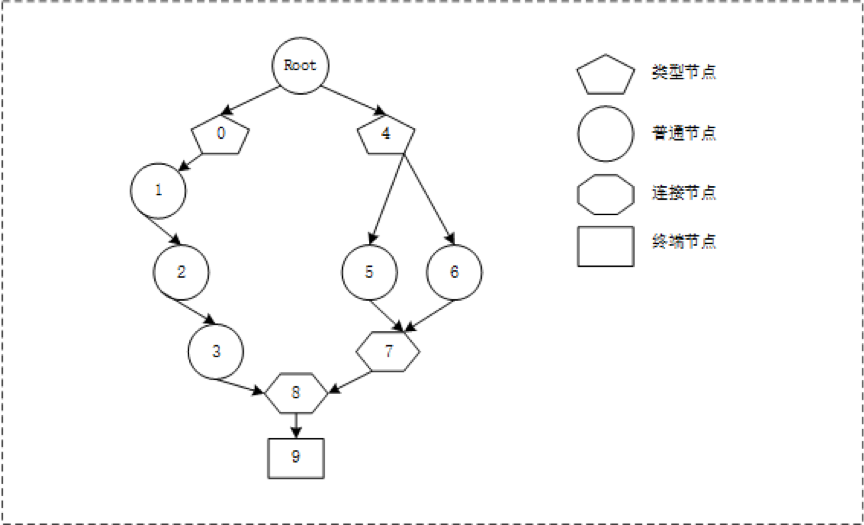
图18 根据Rule集合对象生成的RETE网络
序号 | 节点类型 | 规则 |
|---|---|---|
0 | 类型节点 | 家庭成员 |
1 | 原子节点 | "家庭成员.城市 等于 ""北京""" |
2 | 原子节点 | "家庭成员.性别 等于 ""女""" |
3 | 原子节点 | 家庭成员.生日 小于 18 |
4 | 类型节点 | 订单 |
5 | 原子节点 | 订单.险种类型 等于 $险种类型.医疗险 |
6 | 原子节点 | 订单.险种类型 等于 $险种类型.防癌险 |
7 | 关联节点 | 或者 |
8 | 关联节点 | 并且 |
9 | 终端节点 | 规则“保险过滤规则” |
以上是脚本式建模的核心流程,接下来介绍向导式过程,前面讲过二者建模区别,其中,由Rule集合对象到RETE网络的执行过程相同,因此,本文将着重介绍差异点,即:XML到Rule集合对象的解析过程,以及XML元素的自定义规范。
2.1.3向导式建模原理介绍
所谓向导式是通过可视化配置一步步地引领用户操作,把复杂的任务进行拆解并有步骤地完成,而每一个步骤都是在拼接XML的元素,通过一步步操作完成规则设计后,完整的XML对象也拼接完成。所以向导式的关键在于XML元素的自定义规范。
XML元素属性 | ||
|---|---|---|
LHS | <if></if> | 无属性 |
<and></and> | ||
<or></or> | ||
<atom></atom> | op操作符属性表 | |
<left></left> | 见Value类型表 | |
<value></value> | ||
RHS | <then></then> | 无 |
<execute-function></execute-function> | 见Action类型表 | |
...... | ||
OTHER | ...... | 同RHS |
见op操作符属性表 | |
|---|---|
GreaterThen | 大于 |
GreaterThenEquals | 大于或等于 |
LessThen | 小于 |
LessThenEquals | 小于或等于 |
Equals | 等于 |
EqualsIgnoreCase | 等于(不分大小写) |
...... | |
见Value类型表 | ||
|---|---|---|
Variable | var | 变量中的字段名 |
var-label | 变量中的标题 | |
datatype | 变量中的数据类型 | |
...... | ||
Constant | const-label | 常量中的标题 |
const-category | 常量中的名称 | |
Input | content | 为页面输入的常量值 |
...... | ||
见Action类型表 | ||
|---|---|---|
execute-function | function-name | 功能名称 |
function-label | 功能标签 | |
function-parameter | 数组,包含了功能参数数据 | |
...... | ||
console-print | value子标签 | if条件中value标签的值对应的解析流程 |
...... | ||
有了这些元素属性的自定义规范后,根据向导式设计器的可视化操作,就能生成对应的XML文件,然后再根据Element解释执行成Rule集合对象,最后根据Rule集合对象解释成RETE网络。
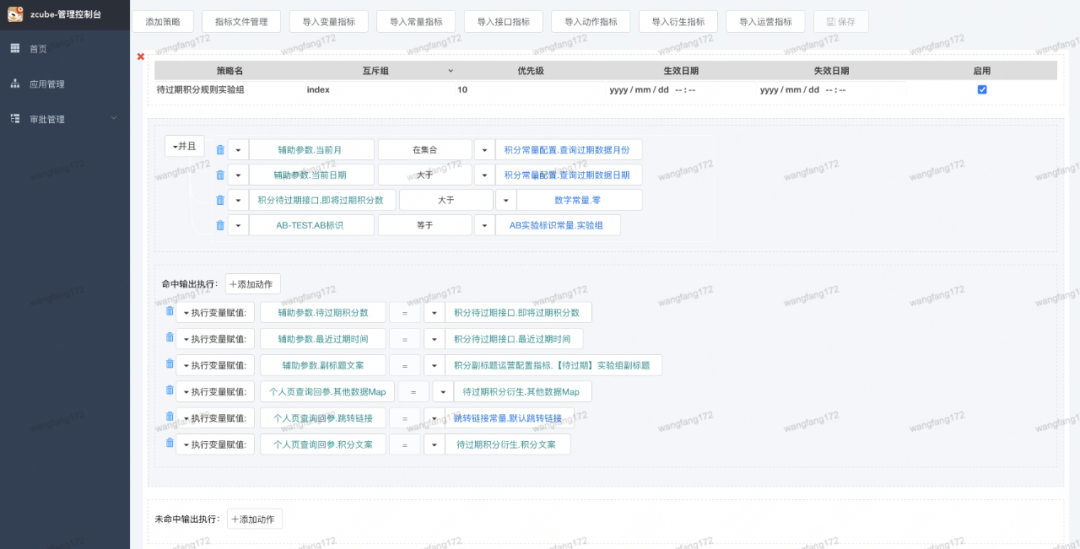
图19 根据Rule集合对象解释成的RETE网络
2.2 规则执行
前提条件:已经依据ZCube语法,定义好业务规则脚本,通过规则建模生成对应的知识文件。
规则"保险过滤规则"
如果
家庭成员.城市 等于 "北京"
并且
家庭成员.性别 等于 "女"
并且
家庭成员.生日 小于 18
并且
(订单.险种类型 等于 $险种类型.医疗险) 或者 (订单.险种类型 等于 $险种类型.防癌险)
那么
out("true");
结束;2.2.1规则执行核心原理
ZCube的执行过程大概分为5个关键步骤,接下来分别对每个步骤进行详细介绍:

图20 ZCube的执行过程
首先,创建会话:根据知识包文件生成本次执行的会话。
会话内容为根据RETE网络生成本次执行的实例化网络,执行的实例化网络也分4个节点,分别是:
- 类型节点
- 原子节点
- 关联节点:又分为与节点、或节点
- 终端节点
不难发现,实例化网络的节点构成和RETE网络节点构成一样,实例化的过程就是根据RETE网络生成各个节点的实例化节点,同时通过Lines串联各实例节点的关系。大体和编译RETE网络的过程一致。
找到RETE树形网络,其中每个节点通过Line形成网络关系,因此需要根据Lines遍历该网络关系。
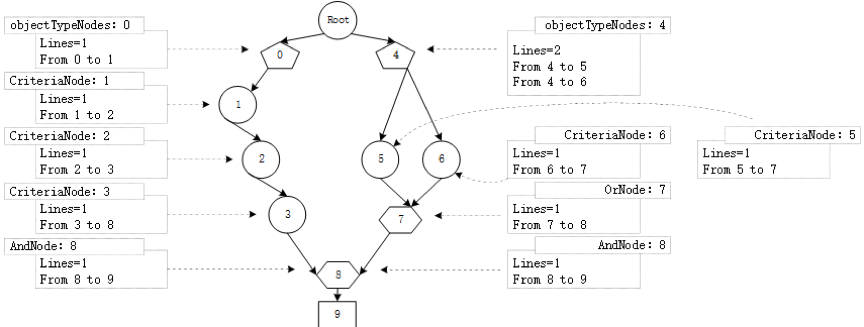
图21 根据Lines遍历该网络关系
根据Line的脉络生成每个节点的实例化节点。同时生成每个实例节点Paths即该节点的路径,类似链表,包括Passed(当前路径对应节点是否模式匹配通过,初始实例化时默认为false)、To标注该节点的下游节点的实例,Paths为集合表示当前节点允许存在多个下游节点,终端节点的Paths为Null。除了Paths之外每个节点还有其特有属性(上面表格已经介绍过)。
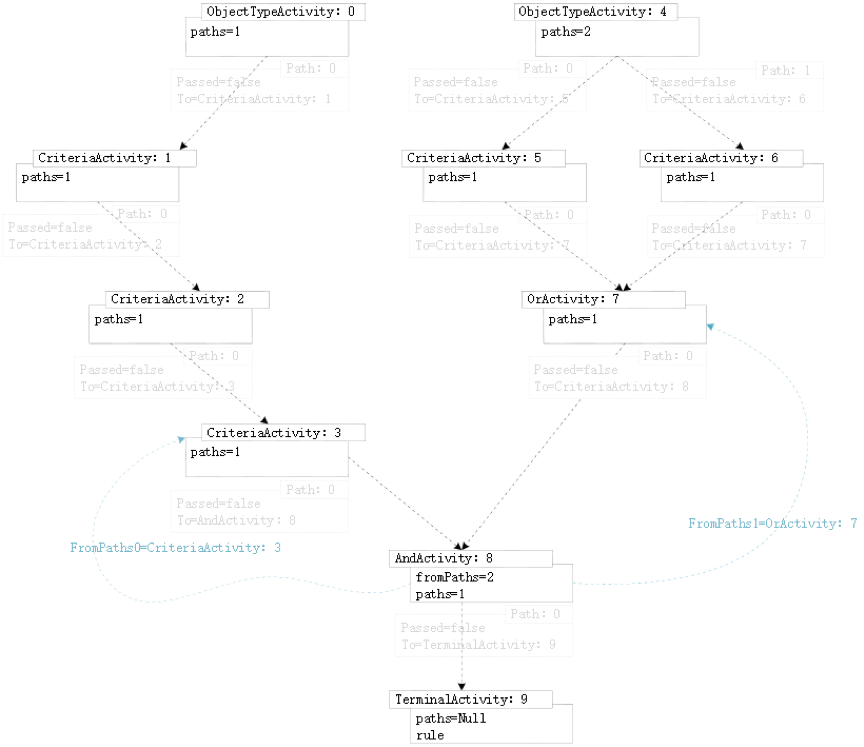
图22 每个节点的实例化节点
其次,事实数据:创建好会话后处理事实数据,即:Facts。
接着,LSH模式匹配:循环Facts数据对RETE实例的每个节点进行模式匹配:
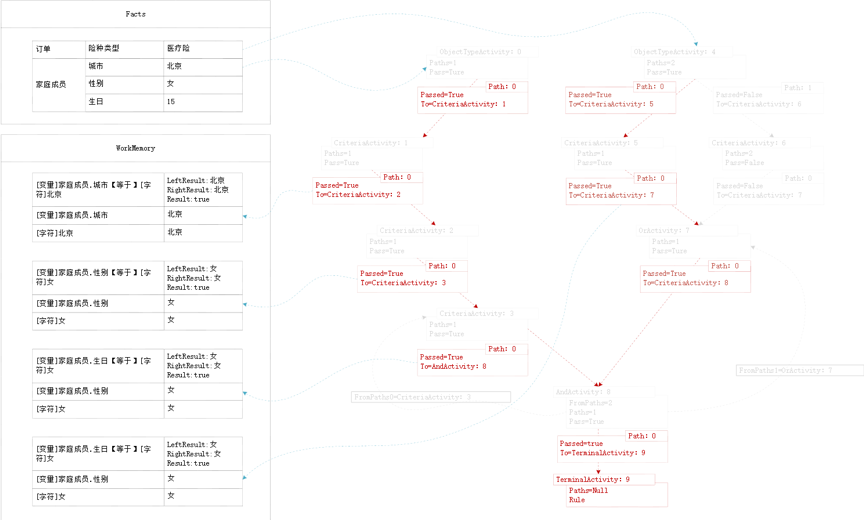
图23 对每个节点进行模式匹配
如图,当Facts进入到实例网络后,分析其匹配过程。大概分为3个步骤:
1. 事实数据会根据类型进入对应的ObjectTypeActivity节点。
2. 遍历当前节点的Paths,根据循环中每个Path的To属性所指向的节点类型分别进行处理。
(1)如果To为CriteriaActivity,进入该节点进行模式匹配。
首先从WorkMemory中根据该节点的CriteriaActivityID获取本地内存中的匹配结果,有:则直接返回,没有:则进入模式匹配,同时将CriteriaActivityID作为Key,将匹配结果作为Value,存储到WorkMemory中,具体匹配过程:
- 获取该模式LeftPart值:优先根据LeftPartID获取本地内存中的值,没有则从事实对象中获取对应的值,即规则中配置的LeftPart对应的Facts值,同时将LeftPartID作为Key,将LeftValue作为Value,存储到WorkMemory中。
- 获取该节点RightPart值:优先根据RightPartID获取本地内存中的值,即规则中配置的RightPart,通常RightPart可能是以下类型:
- Input:输入值。
- Variable:变量值。
- Constant:常量值。
- Method:SpringBean方法。
- CommonFunction:常用函数。
根据值的类型,分别以不同方式(见【Action类型表】)获取该RightPart的Value。并且将RightPartID作为Key,将LeftValue作为Value,存储到WorkMemory中。
- 根据LeftPart.Value和RightPart.Value以及该节点的OP即:操作对象见【op操作符属性表】,获取匹配结果,Result为True或者False。
- 如果CriteriaActivity的模式匹配为False:则结束当前Path的匹配,返回Null【回到上一节点】,否则为True时:将该节点的Pass置为True,同时继续遍历该节点的Paths【重复b】并返回To节点对应的结果。
(2)如果To为OrActivity,将该节点的Pass置为True,同时继续遍历该节点的Paths。【重复b】并返回To节点对应的结果。
(3)如果To为AndActivity,遍历该节点所有的FromPaths,如果有一个为False:则返回Null【回到上一节点】,否则:如果每一个FromPaths的Passed都为true:则将该节点的Pass置为True,同时继续遍历该节点的Paths【重复b】并返回To节点对应的结果。
(4)如果To为TerminalActivity,则将该节点对应的Rules放入Tracker,并返回Tracker。
3. 判断模式匹配的结果,如果不为Null,则将匹配的结果放入Agenda中等待执行。
至此,模式匹配的过程已经结束,命中的规则进入Agenda议程等待分组执行。
然后,RHS执行:分组执行议程中的规则。
1. 议程中规则的分组逻辑
议程中存在3各组,分别是执行组、互斥组、默认组,且三个组的优先级为:执行组>互斥组>默认组。模式匹配后,会将命中的规则放入议程中。存放逻辑为:
- 每个规则只能隶属于一个分组:执行组>互斥组>默认组。
- 进入某一分组的顺序是按规则的优先级属性由大到小存存入,如未设置优先级,则随机排序。
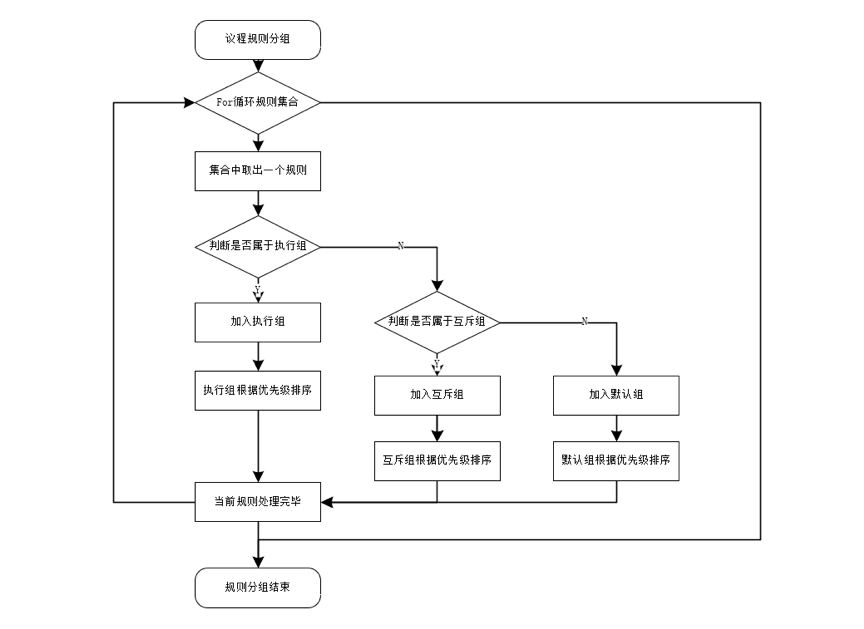
- 图24 分组逻辑
2. 议程中分组的执行逻辑
- 执行组:进入改组的规则,只有设置了获取焦点属性为True的规则才会被执行,且这些规则按组内优先级由大到小执行。
- 互斥组:进入改组的规则,只会执行其中一个规则,即:组内优先级最大的规则。
- 默认组:进入改组的规则,会按组内优先级由大到小执行全部规则。
总结一下最终的执行规则:

图25 最终的执行规则
最后,关闭会话。
1. 会话的实例网络的中的每个节点的Pass:置为False,每个节点的Path集合中的每条路径的passed:置为False。
2. 清空会话中的所有事实数据。
3. 按顺序清空每个议程分组,即:执行组->互斥组->默认组。
至此,一次完整的规则执行完毕。会话的结果会返回本次Fact在执行过程中命中了哪些规则,以及规则的执行顺序。
2.2.2结合示例分析上述原理
为了更好的理解规则在议程中是如何分组,且分组后如何执行,本节将上文中的实际案例稍作调整,如下所示:
1. 将根据规则建模创建好对应的会话
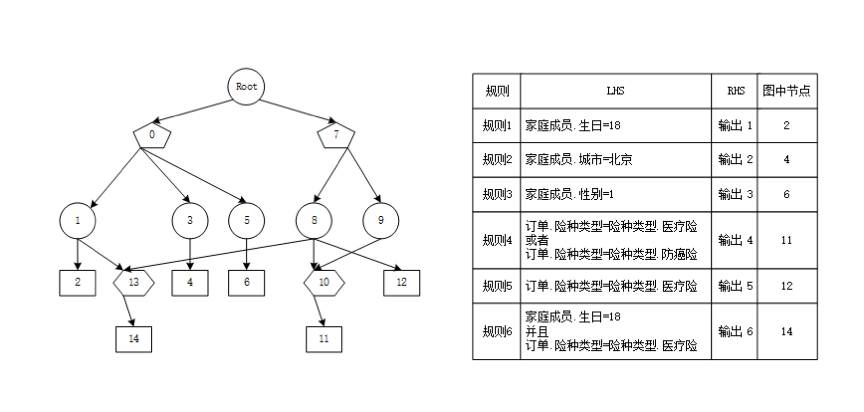
图26 根据对应规则创建会话
2. 将事实数据传入会话
事实 | 属性值 |
|---|---|
家庭成员.生日 | 18 |
家庭成员.城市 | 北京 |
家庭成员.性别 | 1 |
订单.险种类型 | 1 |
3. 按事实类型为主体,循环进行模式匹配3
图27 循环模式匹配
按以上事实默认命中所有规则,本文重点关注命中后议程中的执行逻辑。
4. 将议程中的规则,通过设置不同的分组、优先级、焦点等属性进行试验。
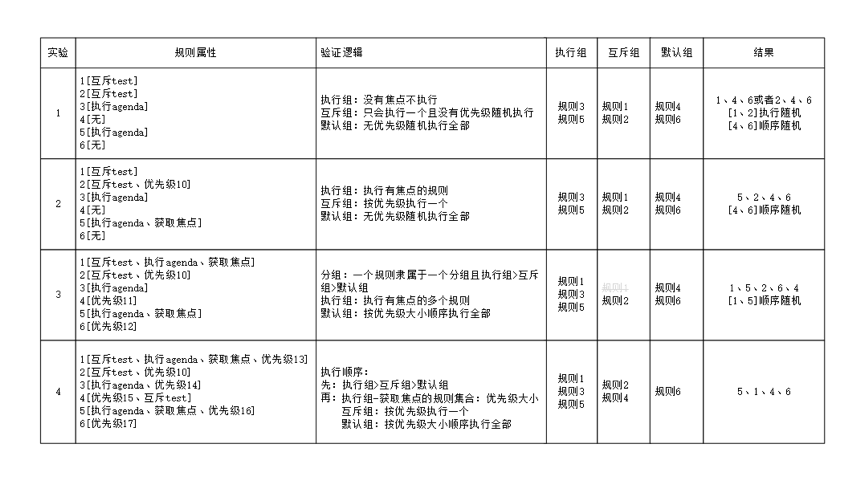
图28 设置不同的分组、优先级、焦点等属性进行试验
可见在针对规则的执行过程中,议程分组到执行的逻辑做了一一试验,结果符合预期。
5. 关闭会话
对ZCube规则关于建模引擎、执行引擎两部分核心功能的介绍已经结束,希望通过对上述规则执行核心逻辑的讲解,能对读者们在之后的业务功能的规则设计中起到一定的帮助。
03
总结
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
通过上述对ZCube的建模、执行,核心原理介绍,不难发现几个特点:
1. 不论有多少规则,最终都将生成RETE算法网络。
2. ZCube模式匹配,是对RETE网络进行遍历,匹配复合Facts的规则,同时Facts只有在满足本节点时才会继续向下沿网络传递,因此其匹配速度与规则数目无关。
3. 当Facts事实数据改变后,会对改变后的事实进行重新匹配。并影响最终的匹配结果。
4. ZCube在模式匹配过程中,利用空间换取性能,会将匹配过的每个节点的LeftPart、RightPart,以及整个模式节点CriteriaActivity缓存在WorkMemory中,以此来提高匹配效率。
由此可见,模式匹配算法是否高效,取决于事实数据是否存在较大的时间冗余,以及规则的模式间结构相似性的多少。
- 时间冗余性:大部分的事实数据,在规则的推理过程中,事实的变化是”缓慢的“即事实本身基本不太会改变,也就是在规则执行周期中,只有少数的事实数据可能发生变化进而重新匹配规则,因此受事实变化影响到的规则也只占很小的比例,
- 结构相似性:实际工作中,从业务逻辑抽象出来的规则,常常包含类似的模式和模式组。
至此,ZCube的核心原理及落地场景分析基本已经介绍完毕,在了解到这些逻辑及特点后,向未来在应用场景的技术选型或是规则使用和设计中,读者们可以尽量多考虑引擎的编译、执行原理,通过理论基础来判断是否适合使用规则引擎,以及使用后如何提升系统性能。