Flink运行方式及对比


前言
本文Flink使用版本1.12.7
主从架构
组件 | 主 | 从 |
|---|---|---|
HDFS | NameNode | DataNode |
Yarn | ResourceManager | NodeManager |
Spark | Master | Worker |
Flink | JobManager | TaskManager |
运行方式
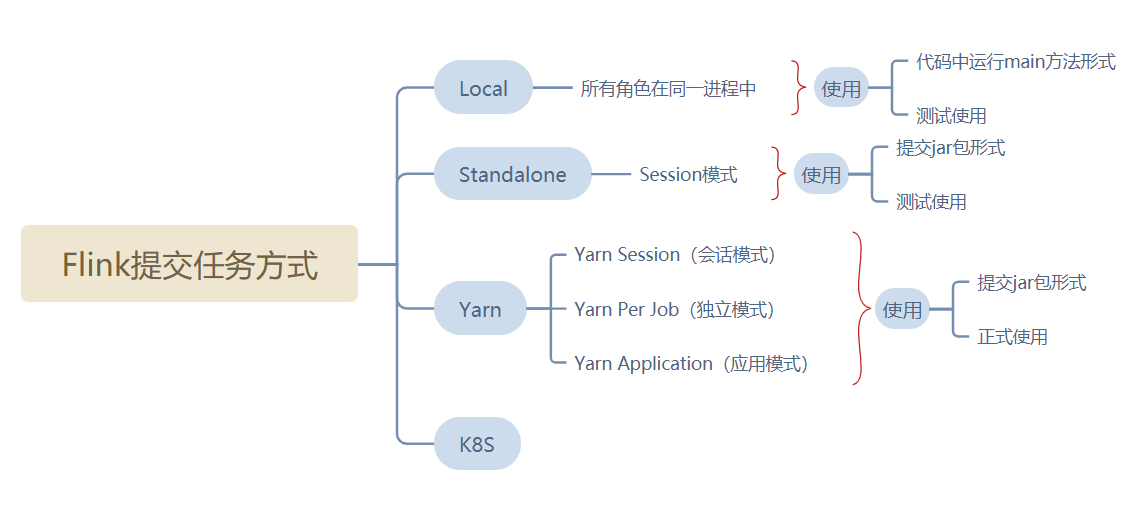
Flink Yarn模式对比
项 | Yarn-session | Per-job | Application |
|---|---|---|---|
启动步骤 | 2步 (1.yarn-session.sh;2.提交任务) | 1步(提交任务) | 1步(提交任务) |
JobManager | 在第一步启动,不会销毁,长期运行 | 随着任务的提交而产生随着任务的销毁而销毁 | 随着任务的提交而产生随着任务的销毁而销毁 |
TaskManager | 在第二步启动,任务运行完之后销毁 | 同上 | 同上 |
客户端进程 | 在客户端节点 | 在客户端节点 | 在集群中某个节点 |
适用范围 | 所有任务都共用一套集群,适合小任务,适合频繁提交场景 | 使用大任务,非频繁提交场景 | 使用大任务,非频繁提交场景 |
Per-Job和Session对比
flink的yarn模式部署项目到集群上有三种:
- yarn-session
- yarn-per-job
- Application
Flink on Yarn-Per Job
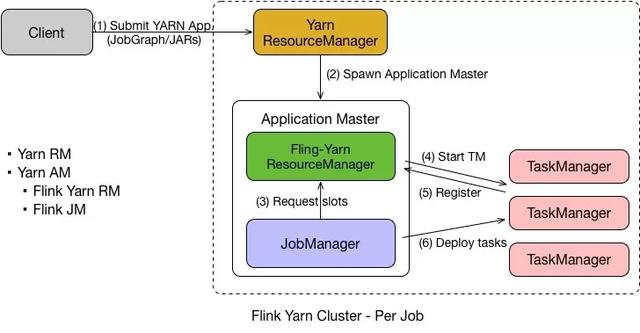
Flink on Yarn 中的 Per Job 模式是指每次提交一个任务,然后任务运行完成之后资源就会被释放。
在了解了 Yarn 的原理之后,Per Job 的流程也就比较容易理解了,具体如下:
- 首先 Client 提交 Yarn App,比如 JobGraph 或者 JARs。
- 接下来 Yarn 的 ResourceManager 会申请第一个 Container。这个 Container 通过 Application Master 启动进程,Application Master 里面运行的是 Flink 程序,即 Flink-Yarn ResourceManager 和 JobManager。
- 最后 Flink-Yarn ResourceManager 向 Yarn ResourceManager 申请资源。当分配到资源后,启动 TaskManager。 TaskManager 启动后向 Flink-Yarn ResourceManager 进行注册,注册成功后 JobManager 就会分配具体的任务给 TaskManager 开始执行。
Flink on Yarn-Session
这种方式需要先启动集群,然后在提交作业,接着会向yarn申请一块空间后,资源永远保持不变。 如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,那下一个作业才会正常提交. 这种方式资源被限制在session中,不能超过。
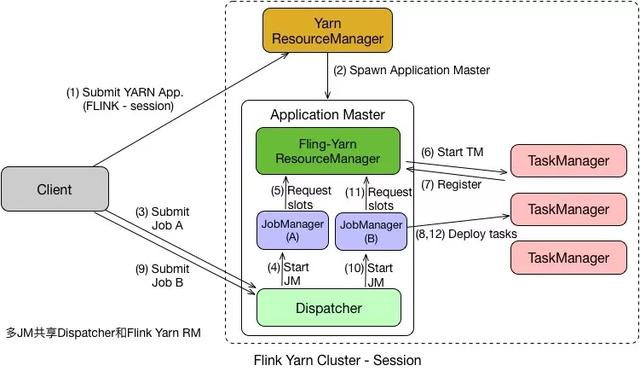
在 Per Job 模式中,执行完任务后整个资源就会释放,包括 JobManager、TaskManager 都全部退出。
而 Session 模式则不一样,它的 Dispatcher 和 ResourceManager 是可以复用的。
Session 模式下,当 Dispatcher 在收到请求之后,会启动 JobManager(A),让 JobManager(A) 来完成启动 TaskManager,接着会启动 JobManager(B) 和对应的 TaskManager 的运行。
当 A、B 任务运行完成后,资源并不会释放。
Session 模式也称为多线程模式,其特点是资源会一直存在不会释放,多个 JobManager 共享一个 Dispatcher,而且还共享 Flink-YARN ResourceManager。
应用场景
Session 模式和 Per Job 模式的应用场景不一样。
Per Job 模式比较适合那种对启动时间不敏感,运行时间较长的任务。
Seesion 模式适合短时间运行的任务,一般是批处理任务。若用 Per Job 模式去运行短时间的任务,那就需要频繁的申请资源,运行结束后,还需要资源释放,下次还需再重新申请资源才能运行。显然,这种任务会频繁启停的情况不适用于 Per Job 模式,更适合用 Session 模式。
执行方式
Standalone
flink run -m hadoop01:8081 $FLINK_HOME/examples/batch/WordCount.jarSession模式
普通申请:
yarn-session.sh -d -nm yarnforflink -jm 512MB -s 1 -tm 512MB这里已经踩过一个坑了
jm 如果设置小于等于512时会报异常,看别人发的帖子说系统底层内存开销不小于512M
2、带有字符集设置的申请: 如果flink程序涉及到向表中插入中文,这里是解决的字符集乱码的好办法
yarn-session.sh -d -jm 512MB -nm yarnforflink -s 1 -tm 512MB -D env.java.opts="-Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8"无论采用哪种方式申请yarn资源,都会输出
JobManager Web Interface: http://hadoop03:41142 2022-11-16 15:02:28,628 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli[] - The Flink YARN session cluster has been started in detached mode. In order to stop Flink gracefully, use the following command: $ echo “stop” | ./bin/yarn-session.sh -id application_1667981758965_0021 If this should not be possible, then you can also kill Flink via YARN’s web interface or via: $ yarn application -kill application_1667981758965_0021
参数说明:
申请2个CPU、1600M内存
- -n 表示申请2个容器,这里指的就是多少个taskmanager
- -tm 表示每个TaskManager的内存大小
- -s 表示每个TaskManager的slots数量
- -d 表示以后台程序方式运行
运行任务
flink run $FLINK_HOME/examples/batch/WordCount.jarYarn监控页面查询:
要想结束
yarn application -kill application_1672654726344_0009Per-job
批处理任务
flink run -t yarn-per-job $FLINK_HOME/examples/batch/WordCount.jarYarn监控页面查询:
流处理任务
监听端口
yum install nc -y
nc -lk 9999运行Flink任务
flink run -t yarn-per-job $FLINK_HOME/examples/streaming/SocketWindowWordCount.jar --hostname hadoop01 --port 9999Application
flink run-application -t yarn-application $FLINK_HOME/examples/batch/WordCount.jarYarn监控页面查询:
查看文件可以访问这个地址
http://hadoop01:50070/explorer.html#/
http://hadoop02:50070/explorer.html#/
因为客户端进程随机分配,所以我们没法在控制台中查看到任务的打印。
flink run-application -t yarn-application $FLINK_HOME/examples/batch/WordCount.jar --output hdfs://hadoop01:9000/bigdata_study/output01获取ApplicationID
命令行返回中获取
2023-01-04 12:55:22,413 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hadoop03:8081 of application 'application_1672710362889_0013'.
Job has been submitted with JobID a75ef787517f0a846117df555717ecc9代码中获取
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ConfigOptions;
import org.apache.flink.core.execution.JobClient;
import org.apache.flink.core.execution.JobListener;
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getJobListeners().add(new JobListener() {
/**
* 监听flink应用提交成功事件
*/
@Override
public void onJobSubmitted(JobClient jobClient, Throwable throwable) {
// applicationId 配置项
ConfigOption<String> applicationId = ConfigOptions.key("yarn.application.id")
.stringType()
.noDefaultValue();
try {
// 获取flink应用的配置
Field configurationField = StreamExecutionEnvironment.class.getDeclaredField("configuration");
if (!configurationField.isAccessible()) {
configurationField.setAccessible(true);
}
org.apache.flink.configuration.Configuration configuration = (org.apache.flink.configuration.Configuration)configurationField.get(env);
// 从配置中获取applicationId
String appId = configuration.get(applicationId);
System.out.println("flink applicationId: " + appId);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void onJobExecuted(JobExecutionResult jobExecutionResult, Throwable throwable) {
}
});Rest Api
官方文档 https://nightlies.apache.org/flink/flink-docs-release-1.12/zh/ops/rest_api.html
这所有的接口我们都可以通过网页上的F12查看。
配置
flink-conf.yaml 新增配置
rest.port: 8081
rest.address: 0.0.0.0
web.submit.enable: true分发
distribution.sh $FLINK_HOME启动集群
yarn-session.sh -d -nm yarnforflink停止
yarn application -kill application_1672710362889_0049获取Flink Rest接口地址
我们先从Yarn Rest Api中获取Flink Rest Api的地址
进入Yarn管理界面查看applicationid
获取Rest Api地址
${Yarn地址}/ws/v1/cluster/apps/${applicationid}示例
任何一个Yarn服务都可以,它会自动重定向
http://hadoop02:8088/ws/v1/cluster/apps/application_1672710362889_0049 http://hadoop03:8088/ws/v1/cluster/apps/application_1672710362889_0049
其中amHostHttpAddress是运行任务所在的服务器
查看配置信息
查看 Web UI 的配置信息:
查看集群配置信息:
集群信息
查看集群信息:
返回如下
{"taskmanagers":0,"slots-total":0,"slots-available":0,"jobs-running":0,"jobs-finished":2,"jobs-cancelled":0,"jobs-failed":0,"flink-version":"1.12.7","flink-commit":"88d9950"}查看Jar
所有的Jar
JobManager
查看 JobManager 上所有日志文件列表:
查看 JobManager 的 Metrics 信息:
查看配置
查看实时输出
Job信息
查看所有的Job基本信息
查看所有的Job详细信息
返回
{"jobs":[{"jid":"793aba69a57ee166b000b38cf3f12c75","name":"Flink Java Job at Wed Jan 04 11:12:36 CST 2023","state":"FINISHED","start-time":1672801957678,"end-time":1672801969053,"duration":11375,"last-modification":1672801969053,"tasks":{"total":9,"created":0,"scheduled":0,"deploying":0,"running":0,"finished":9,"canceling":0,"canceled":0,"failed":0,"reconciling":0}}]}查看某个job信息
查看作业的数据流执行计划:
http://hadoop01:8081/jobs/793aba69a57ee166b000b38cf3f12c75/plan
其他
在这简单罗列了一部分 API,更详细的可以参阅 Monitoring REST API:
API | 说明 | 参数 |
|---|---|---|
/jobs/:jobid/accumulators | 查看具体某个作业所有任务的累加器 | jobid |
/jobs/:jobid/checkpoints | 查看具体某个作业的Checkpoint信息 | jobid |
/jobs/:jobid/checkpoints/config | 查看具体某个作业的Checkpoint配置信息 | jobid |
/jobs/:jobid/checkpoints/details/:checkpointid | 查看具体某个作业的某个Checkpoint信息 | jobid、checkpointid |
/jobs/:jobid/config | 查看具体某个作业的配置信息 | jobid |
/jobs/:jobid/exceptions | 查看具体某个作业的已发现异常信息。truncated为true表示异常信息太大,截断展示。 | jobid |
/jobs/:jobid/savepoints | 触发生成保存点,然后有选择地取消作业。此异步操作会返回 triggerid,可以作为后续查询的唯一标识。 | jobid |
/taskmanagers/metrics | 查看 Taskmanager 的 Metrics 信息 | |
/taskmanagers/:taskmanagerid | 查看具体某个 Taskmanager 的详细信息 | taskmanagerid |
/taskmanagers/:taskmanagerid/logs | 查看具体某个 Taskmanager 的所有日志文件列表 | taskmanagerid |
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-01-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号