Redis的String类型,原来这么占内存
原创Redis的String类型,原来这么占内存
原创

Redis的String类型,原来这么占内存
存一个 Long 类型这么占内存,Redis 的内存开销都花在哪儿了?
1、场景介绍
假设现在我们要开发一个图片存储系统,要求这个系统能够根据图片 ID 快速查找到图片存储对象 ID。图片 ID 和图片存储对象 ID 的样例数据如下:
photo_id: 1101000060
photo_obj_id: 3302000080在这种场景下,图片 ID 和图片存储对象 ID 刚好是一对一的关系,是典型的“键 - 单值”模式,Redis 的 String 类型提供了“一个键对应一个值的数据”的保存形式,在这种场景下刚好适用。
确定使用 String 类型后,接下来我们通过实战,来看看它的内存使用情况。首先通过下面命令连接上 Redis。
本文我使用的 Redis Server 及下文源码都是 6.2.4 版本。
redis-cli -h 127.0.0.1 -p 6379然后执行下面的命令查看 Redis 的初始内存使用情况。
127.0.0.1:6379> info memory
# Memory
used_memory:871840接着插入 10 条数据:
10.118.32.170:0> set 1101000060 3302000080
10.118.32.170:0> set 1101000061 3302000081
10.118.32.170:0> set 1101000062 3302000082
10.118.32.170:0> set 1101000063 3302000083
10.118.32.170:0> set 1101000064 3302000084
10.118.32.170:0> set 1101000065 3302000085
10.118.32.170:0> set 1101000066 3302000086
10.118.32.170:0> set 1101000067 3302000087
10.118.32.170:0> set 1101000068 3302000088
10.118.32.170:0> set 1101000069 3302000089再次查看内存:
127.0.0.1:6379> info memory
# Memory
used_memory:872528可以看到,存储 10 个图片,内存使用了 688 个字节。一个图片 ID 和图片存储对象 ID 的记录平均用了 68 字节。
但问题是,一组图片 ID 及其存储对象 ID 的记录,实际只需要 16 字节就可以了。图片 ID 和图片存储对象 ID 都是 10 位数,而 8 字节的 Long 类型最大可以表示 2 的 64 次方的数值,肯定可以表示 10 位数。这样算下来只需 16 字节就可以了,为什么 String 类型却用了 68 字节呢?
为了一探究竟,我们不得不从 String 类型的底层实现扒起。
2、String 类型的底层实现
当你保存的数据中包含字符时,String 类型就会用简单动态字符串(Simple Dynamic String,SDS)结构体来保存。
2.1 SDS
SDS 的结构定义在sds.h文件中,在 Redis 3.2 版本之后,SDS 由一种数据结构变成了 5 种数据结构。
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) hisdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) hisdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) hisdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) hisdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) hisdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};这 5 种数据结构依次存储不同长度的内容,Redis 会根据 SDS 存储的内容长度来选择不同的结构。
- sdshdr5:存储大小为 32 字节(2 的 5 次方),只被应用在了 Redis 中的 key 中。
- sdshdr8:存储大小为 256 字节(2 的 8 次方)。
- sdshdr16:存储大小为 64KB(2 的 16 次方)。
- sdshdr32:存储大小为 4GB(2 的 32 次方)。
- sdshdr64:存储大小为 2 的 64 次方字节。
以 sdshdr8 为例。
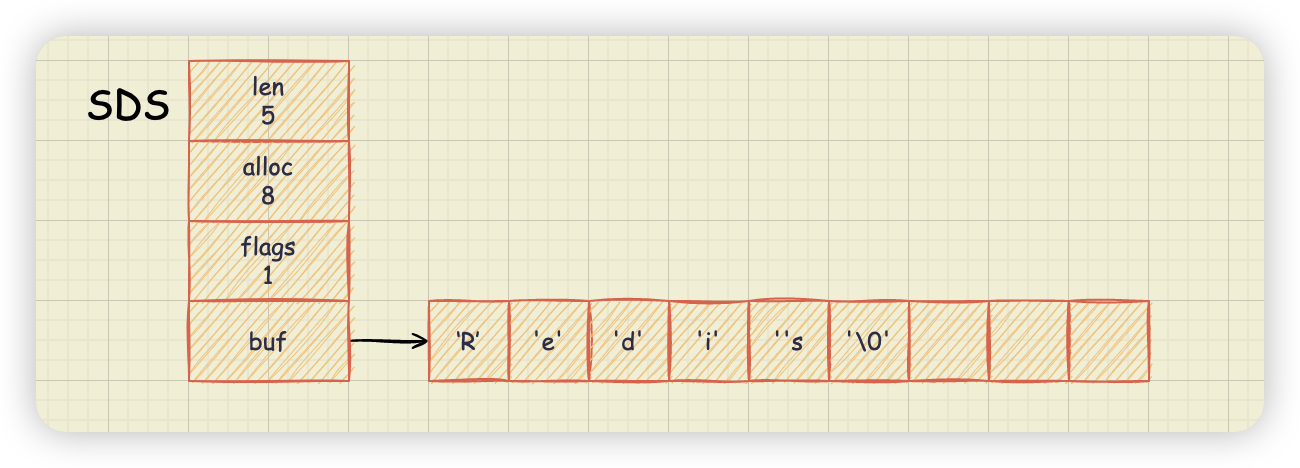
- buf:字节数组,保存实际数据。为了表示字节数组的结束,Redis 会自动在数组最后加一个
'\0',这就会额外占用 1 个字节的开销。 - len:占 4 个字节,表示 buf 的已用长度,不包括
'\0'。 - alloc:也占 4 个字节,表示 buf 的实际分配长度,不包括
'\0'。 - flags:占 1 个字节,标记当前字节数组的属性,是
sdshdr8还是sdshdr16等。(flags 值的定义可以看下面代码)
在源码sds.h中,flags 值定义如下:
#define HI_SDS_TYPE_5 0
#define HI_SDS_TYPE_8 1
#define HI_SDS_TYPE_16 2
#define HI_SDS_TYPE_32 3
#define HI_SDS_TYPE_64 42.2 RedisObject
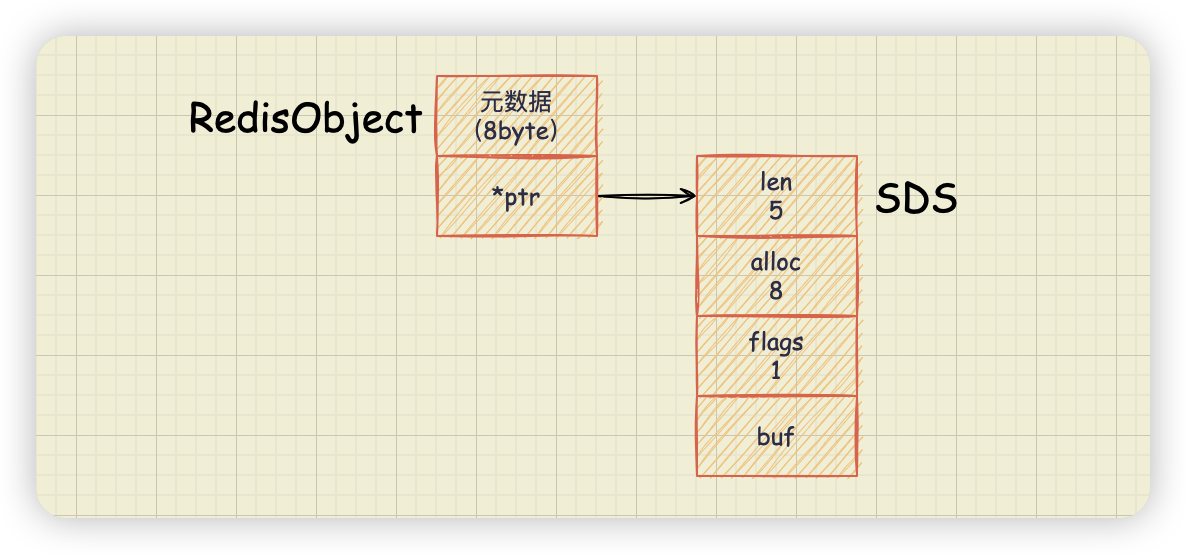
因为 Redis 的数据类型有很多,而且,不同数据类型都有些相同的元数据要记录,所以,值对象并不是直接存储,而是被包装成redisObject对象,它的定义如下。
typedef struct redisObject {
unsigned type:4;//对象类型(4位=0.5字节)
unsigned encoding:4;//编码(4位=0.5字节)
unsigned lru:LRU_BITS;//记录对象最后一次被应用程序访问的时间(24位=3字节)
int refcount;//引用计数。等于0时表示可以被垃圾回收(32位=4字节)
void *ptr;//指向底层实际的数据存储结构,如:sds等(8字节)
} robj;下面可以帮助我们理解:
为了节省内存空间,Redis 还做了一些优化。
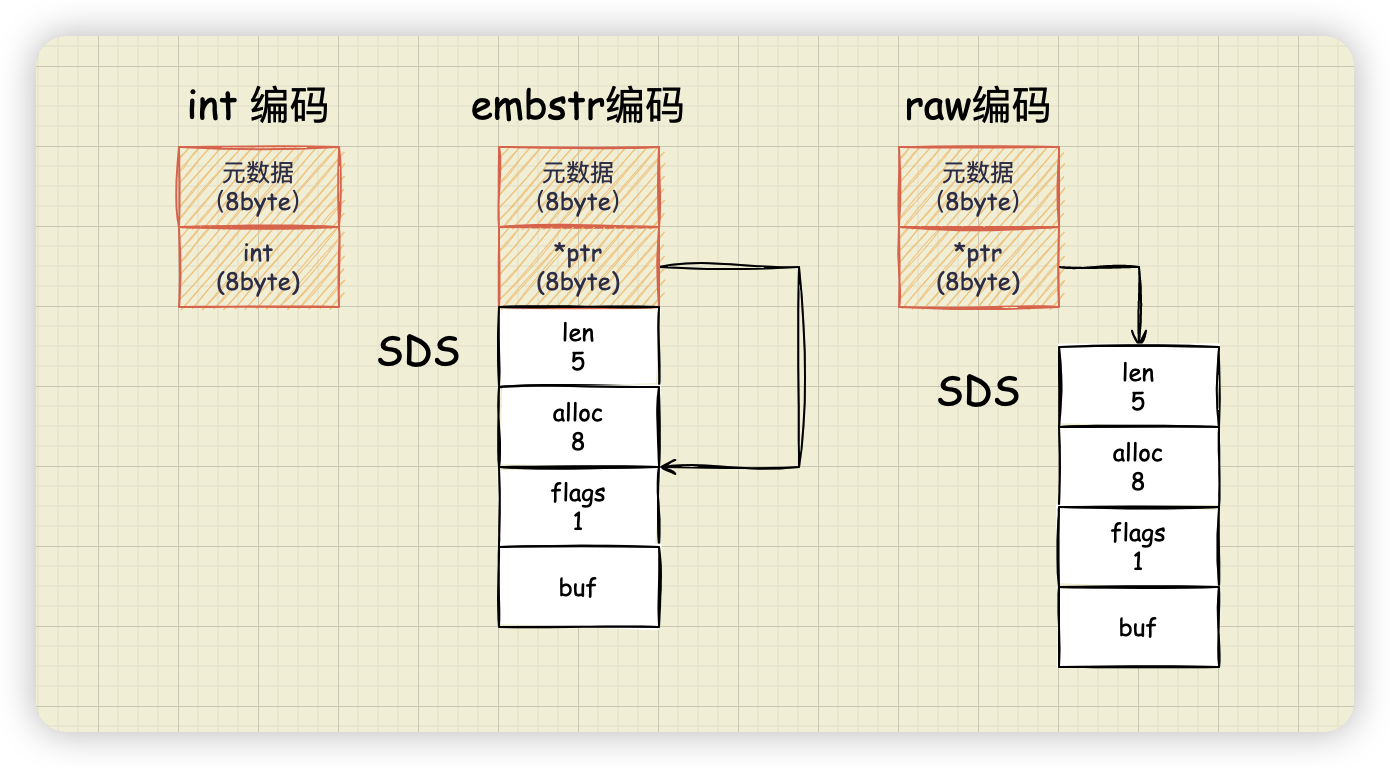
当保存的是 Long 类型整数时,RedisObject 中的指针就直接赋值为整数数据了,这样就不用额外的指针再指向整数了。这种保存方式通常也叫作 int 编码方式。
当保存的是字符串数据,并且字符串小于等于 44 字节时,RedisObject 中的元数据、指针和 SDS 是一块连续的内存区域,这样就可以避免内存碎片。这种布局方式也被称为 embstr 编码方式。
当字符串大于 44 字节时,SDS 的数据量就开始变多了,Redis 就不再把 SDS 和 RedisObject 布局在一起了,而是会给 SDS 分配独立的空间,并用指针指向 SDS 结构。这种布局方式被称为 raw 编码模式。
使用 OBJECT ENCODING 命令可以查看一个数据库键的值对象的编码:
127.0.0.1:6379> SET msg "hello world"
OK
127.0.0.1:6379> OBJECT ENCODING msg
"embstr"
127.0.0.1:6379> SET story "long long long ago..."
OK
127.0.0.1:6379> OBJECT ENCODING story
"raw"
127.0.0.1:6379> SADD numbers 1 3 5
(integer) 3
127.0.0.1:6379> OBJECT ENCODING numbers
"intset"
127.0.0.1:6379> SADD numbers "seven"
(integer) 1
127.0.0.1:6379> OBJECT ENCODING numbers
"hashtable"注意这个命令
SET story "long long long ago...",省略号指的是省略了很多字符。
知道了 SDS 和 RedisObject 额外元数据开销,现在,我们就可以计算 String 类型的内存使用量了。
图片存储对象 ID 是 Long 类型整数,所以可以直接用 int 编码的 RedisObject 保存。每个 int 编码的 RedisObject 元数据部分占 8 字节,指针部分被直接赋值为 8 字节的整数了。图片 ID 使用 sdshdr5 数据结构来保存,会为 10 位的图片 ID 分配 16 个字节,结束符 '\0' 占 1 个字节。
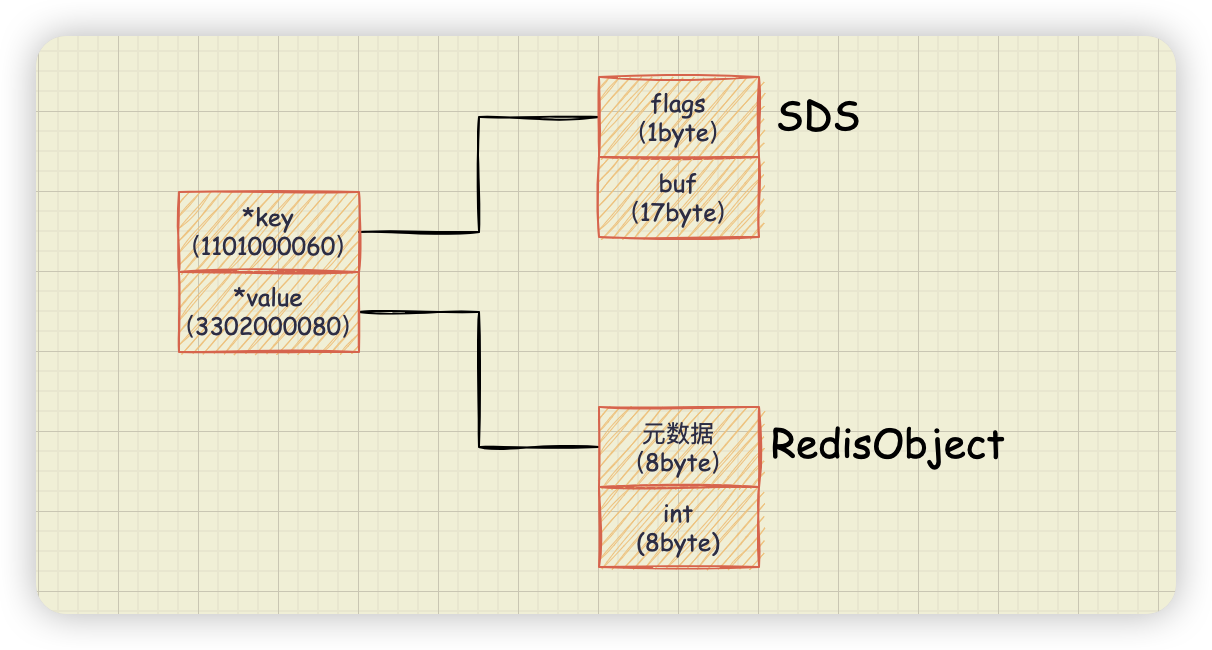
共占用 34 个字节。与上文所说的一个图片 ID 和图片存储对象 ID 的记录平均用了 68 字节相差有点大啊,另外的开销去哪儿了?
2.3 全局哈希表
为了实现从键到值的快速访问,Redis 使用了一个哈希表来保存所有键值对。因为这个哈希表保存了所有的键值对,所以,也称为全局哈希表。哈希表的每一项是一个 dictEntry 的结构体,用来指向一个键值对。dictEntry 结构中有三个 8 字节的指针,分别指向 key、value 以及下一个 dictEntry,三个指针共 24 字节,如下图所示:
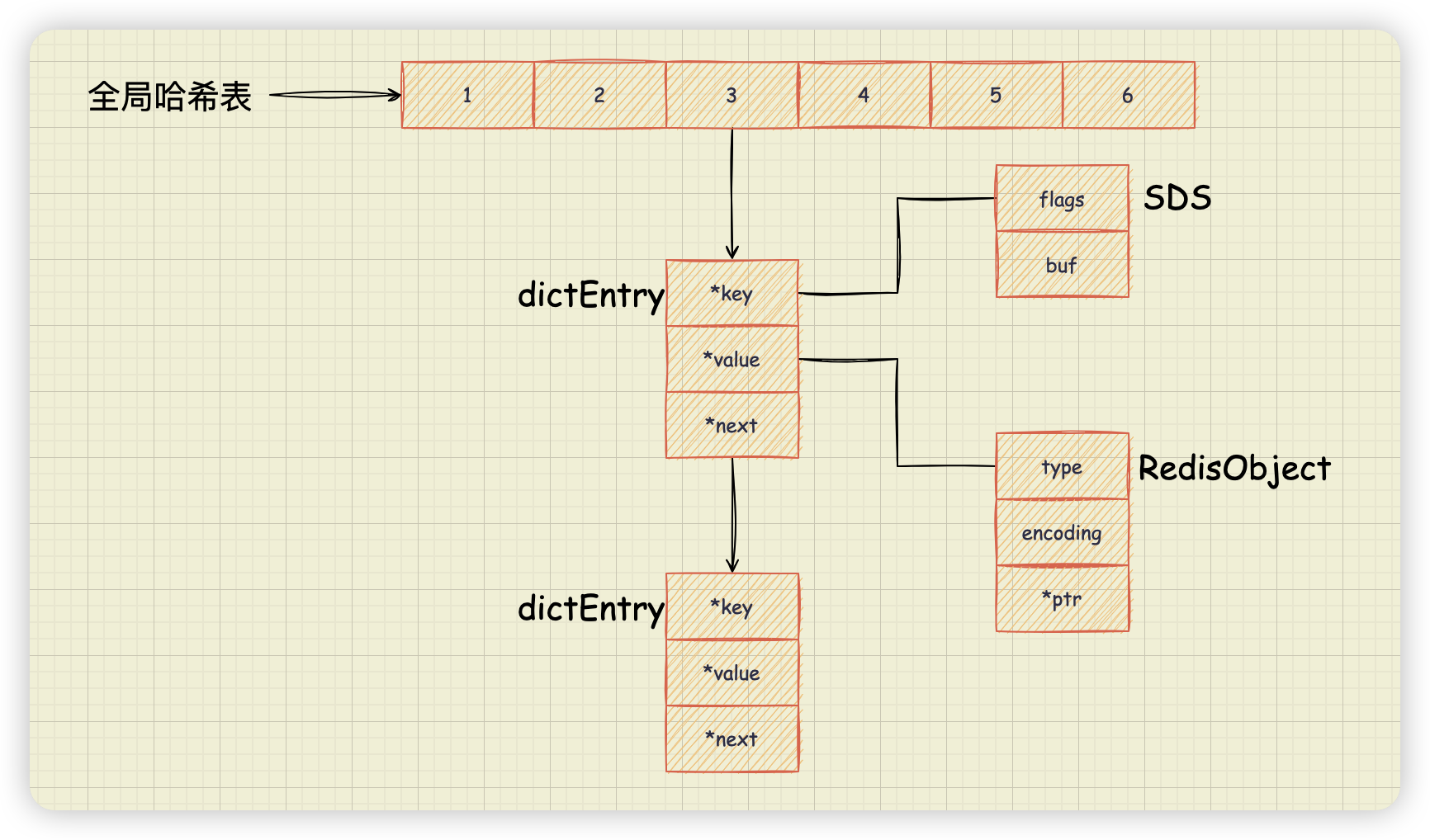
jemalloc 在分配内存时,会分配一个最接近 2 的 N 次方的数值。举个例子。如果你申请 6 字节空间,jemalloc 实际会分配 2 的 4 次方即 8 字节空间;如果你申请 24 字节空间,jemalloc 则会分配 32 字节。
最终我们分析出来的内存开销,为 66 字节,比较接近上文场景中的平均值 68 了。
最后
既然 String 类型这么占内存,那么你有好的方案来节省内存吗?
参考资料
- 文中的一些命令,参考菜鸟教程:https://www.runoob.com/redis/redis-tutorial.html
- Redis 的 key 也是 SDS 类型的,参考:https://www.cnblogs.com/lonely-wolf/p/14261486.html
- SDS 的定义,参考:https://juejin.cn/post/6844903936520880135#heading-6
- 文章大纲,参考极客时间《Redis核心技术与实战》
- 《Redis设计与实现》
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。