基于边缘辅助极线Transformer的多视角场景重建
原创基于边缘辅助极线Transformer的多视角场景重建
原创
童伟, 张苗苗, 李东方, 吴奇, 宋爱国. 基于边缘辅助极线Transformer的多视角场景重建[J]. 电子与信息学报
编辑:一点人工一点智能
01 引言
为计算机视觉领域广泛研究的核心问题之一,多视角立体几何( MVS)通过具有重叠区域的多幅图像以及预先标定的相机参数,旨在重建出稠密的3维场景。该技术正广泛应用于机器人导航、虚拟增强现实、无人搜救、自动驾驶等领域。传统方法[1]通过多个视图间的投影关系恢复3D点,在理想的散射方案下取得了不错的效果,但在镜面反射、弱纹理等区域难以保证准确的密集匹配。
基于深度图的MVS[2-5]利用2D卷积神经网络(CNN)提取多视图的特征,并根据假定的深度采样值将源图像特征映射到参考视角上构建3D代价体,之后对代价体进行正则化从而预测出深度图,最后通过深度图融合重建出场景。基于CNN的方法融合了诸如镜面反射、反射先验之类的全局特征信息,因此其密集匹配更加可靠。
特别地,Gu等人[2]采用级联的方式构建代价体并在更高的特征分辨率上精细深度图,其关键的一步是通过逐步细化深度值的采样范围,确保了计算资源的合理分配。主流的方法大都采用静态或预先设定的深度采样范围来确定深度采样值,然而由于每个像素深度值推断的不确定性不同,因此静态采样假设并不适用于所有的像素。
此外,现有的方法[2,4,6]采用方差操作聚合所有视角的代价体,然而这种方式忽略了不同视角下的像素可见性。为了应对这一问题,文献[7]设计2D 网络模块生成像素可见性图来聚合多视角,文献[8]通过可变形卷积网络聚合跨尺度的代价体以处理弱纹理区域。然而这些方法仅仅从2D局部相似性的角度通过引入繁重的网络模块来学习每个视角下像素的权重,但忽略了深度方向的3D一致性[9]。
为了缓解上述问题,本文提出基于边缘辅助极线Transformer的多阶段深度推断网络。利用极线Transformer的跨注意力机制显式地对不同视角下构建的代价体进行3D建模,并结合辅助的边缘检测分支约束2D底层特征在极线方向的一致性。
此外,本文将深度值回归转换为多个采样深度值的分类问题进行求解,降低深度采样率的数目与显存占用。另一方面,本文利用概率代价体的信息熵生成不确定性图,并以此自适应调整深度值采样的范围,提高深度范围采样在不同区域的适应能力。
本文的主要贡献如下:
(1)提出一种多视图深度推断网络,利用基于边缘辅助的Transformer跨注意力机制有效地学习不同视角下代价体聚合的3D关联性;
(2)将深度回归转换为多深度值分类模型进行训练,并引入基于概率代价体分布的不确定性模块,动态调整深度采样间隔以提高弱纹理区域的深度推断精度;
(3)与主流方法在公开数据集DTU和Tanks&Temples的实验对比表明,给定有限的内存占用与运行时间,所提出的方法可以实现密集准确的场景重建。
本文其余部分组织如下:第2节介绍MVS的相关工作;第3节详细介绍所提出的MVS网络;第4节开展了与主流方法的实验对比;第5节进行总结。
02 相关工作
2.1 基于深度学习的MVS
深度学习强大的特征提取能力,推动MVS领域取得了显著发展。基于深度学习的MVS[10,11]场景重建的完整性与准确性质量更高,逐渐取代传统的方法。Yao等人[4]提出了MVSNet模型,利用可微的单应性映射构建成本代价体,并利用3D卷积模块对局部信息与多尺度上下文信息进行正则化,实现端对端的深度推断。为了缓解3D卷积显存占用高的问题,Yao等人[5]提出了R-MVSNet,利用GRU(Gate Recurrent Unit)结构对代价体进行正则化,有效降低了显存占用,并解决了MVSNet难以估计高分辨率场景的问题。为了提高深度推断在不同场景与光照条件下的适应性能力,文献[7]通过自适应聚合多视角的局部特征,生成不同视角的代价体权重图。Zhang等人[12]设计一种概率代价体不确定性估计的像素可见性模块,并以此聚合多视角代价体。Xi等人[13]通过沿每条相机光线直接优化深度值,模拟激光扫描仪深度范围查找,仅使用稀疏的代价体就预测出准确的深度图。
2.2 深度采样范围设定
为了开发计算效率高的网络,一些工作提出了由粗到精的多阶段MVS框架。在这些方法中,初始阶段设定的深度采样范围覆盖了输入场景的整个深度值,根据当前预测的深度值缩短下一阶段深度采样的范围。Cas-MVSNet[2]通过缩减因子手动缩小深度范围,实现高分辨率高质量的深度图推断。Cheng等人[7]利用深度分布的方差逐渐缩小深度扫描范围,在有限的显存占用下保证了场景重建的质量。Yu等人[14]使用稀疏代价体推断初始的低分辨率深度图,并采用高斯-牛顿层逐阶段优化稀疏的深度图。Wang等人[15]融合了传统的立体声算法与多尺度深度推断框架。
2.3 基于Transformer的特征匹配
Transformer[16]最初应用于自然语言处理任务,其强大的远程建模能力,受到了计算机视觉领域研究学者的青睐。在3D视觉任务中,借助Transformer捕获全局上下文信息方面的天然优势,Li等人[17]从序列到序列的角度建模,使用位置编码、自注意力和跨视角注意力机制捕获代价体的特征,实现密集的双目估计。Sun等人[18]提出了基于Transformer的局部特征匹配方法,使用注意力机制获得图像的特征描述符以建立精确的匹配,并证明这种密集匹配在弱纹理区域依然有效。最近,Transformer也应用到了MVS中。例如文献[19]仅利用Transformer的跨视角注意力机制,有效融合了不同视角的代价体。Ding等人[20]以及文献[21]分别引入了一种全局上下文Transformer,实现了密集鲁棒的特征匹配。
03 实验方法
3.1 多视角3D代价体构建
如图1所示,为了实现高分辨率图像语义特征的编码,给定输入图像I \in R^{H\times W\times 3} ,本文使用金字塔特征网络(Feature Pyramid Network, FPN)提取多尺度特征。该网络经过多次卷积层处理与上采样操作,输出3个尺度的特征图尺寸分别是输入图像的1/4,1/2和1。给定采样的深度值,本文通过前向平行平面将源视角的特征映射到参考图像的视角,建立多视角代价体。给定采样的深度值d,跨视角可微矩阵变换表示为
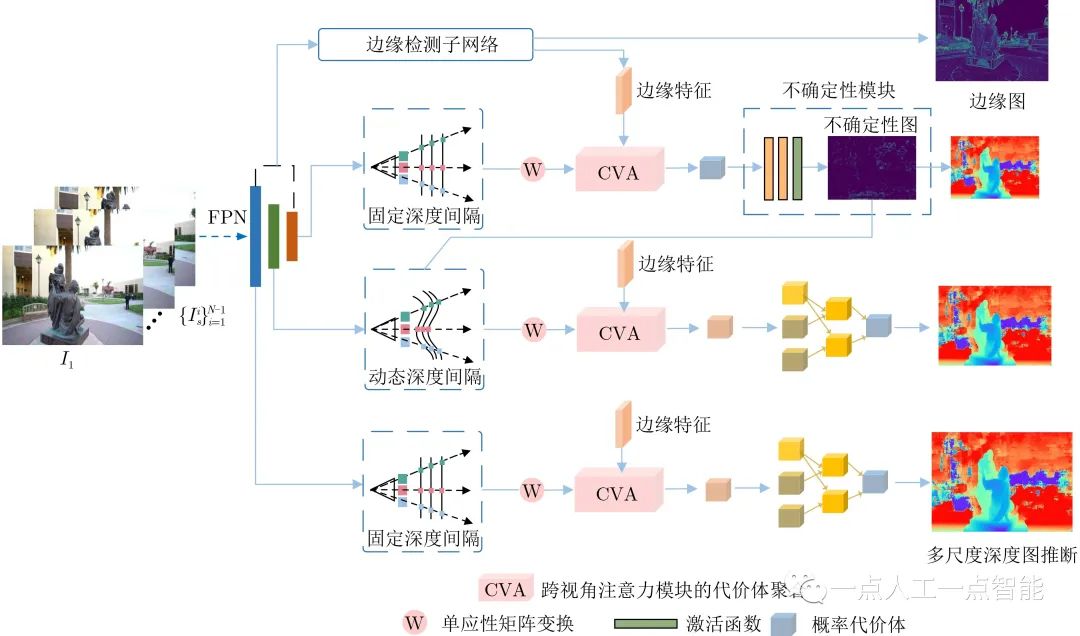
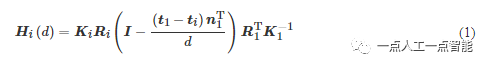
其中,K_i,R_i,t_i分别表示第i个视角相机的内参、旋转参数、平移参数,n_1 表示参考相机的主轴。特别地,3个阶段假定的深度采样数目分别是16, 8和4。
3.2 基于边缘辅助极线Transformer的代价体聚合
3.2.1 基于Transformer的代价体聚合
直接使用基于方差的机制对映射至参考视角的代价体进行聚合,通常包含很多噪声。为了防止噪声导致代价体正则化模块产生过拟合现象,本文利用Transformer注意力机制探索跨视角代价体的极线几何以及不同空间位置的全局相关性。以参考视角代价体作为Query特征,与源视角代价体进行特征匹配,生成注意力图以聚合多视角的代价体。最后使用3D卷积模块正则化聚合后的代价体,输出概率代价体以推断深度。
图2为所提跨视角代价体聚合模块,C_{ref} 表示参考视角的代价体,C^i_{source} 表示第i个源视角代价体,特征图尺寸是H×W×C×D,C和D分别表示特征通道数和深度采样数。由于代价体中包含了丰富的语义特征,本文采用多重线性投影计算跨视角特征向量的相似度。如式(2)和式(3)所示,首先将每对参考视角-源视角的代价体映射到不同的子空间,即得到Query特征\varphi_q 、Value特征\varphi_v 和Key特征\varphi_k ;之后在子空间使用Softmax作为T(·) 的归一化函数来计算跨视角嵌入向量的重要性;最后沿着深度方向使用投影函数\rho(·) 进行线性投影,输出用于跨视角代价体聚合的注意力图
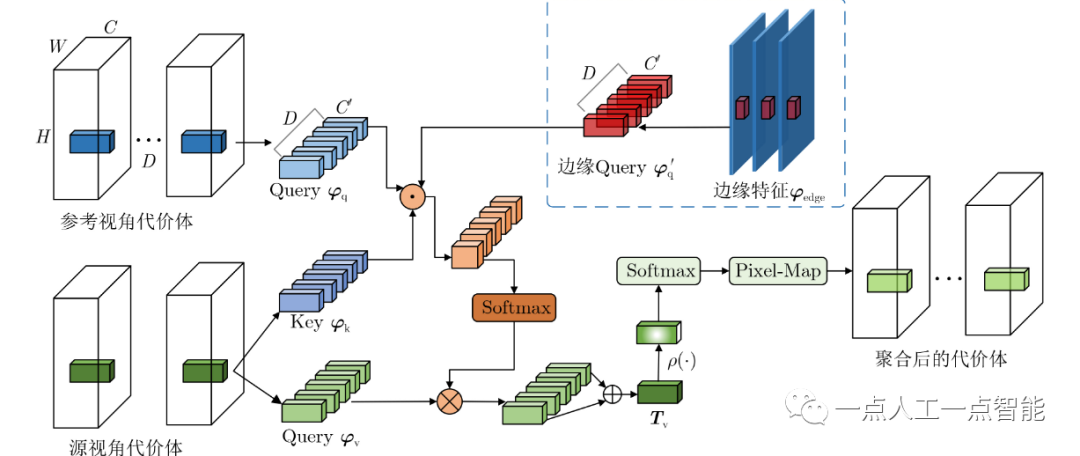
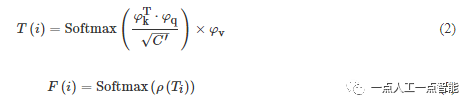
特别地,本文采用文献[2]的代价体编码方式对跨视角的特征C_{ref} 和C^i_{source} 进行编码,得到每对跨视角代价体C^i_{group} ,其尺寸是H×W×G×D,G表示当前尺度的特征通道数。进一步,区别于先前工作使用方差机制来聚合多视角代价体,本文采用式(4)聚合跨视角的特征,得到聚合后的代价体C_{agg}
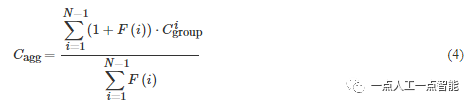
深度推断网络在普通区域能够捕获密集的特征匹配线索,而物体边界附近由于缺乏几何特性与约束,难以保证深度推断的可靠性,为此本文进一步引入边缘特征以调整跨视角代价体的聚合。如图1所示,边缘检测子网络分支的输入是金字塔特征提取网络(FPN)输出的特征图,经过多个卷积层、上采样层以及多尺度特征的融合,得到用于后续跨视角代价体聚合的边缘特征\varphi _{edge} 。之后使用1×1的卷积层和Softmax激活层输出尺度为1/2的边缘图,表示每个像素疑似边缘的概率。
为了约束跨视角代价体的2D底层特征在深度方向的3D一致性,如图2所示,对提取到的表达能力丰富的边缘特征\varphi _{edge} ,辅助用于跨视角代价体的聚合,从而提高在物体边界的深度推断可靠性。将\varphi _{edge} 作为源视角参考视角代价体Query特征的辅助输入\varphi _{q'} ,并计算跨视角特征向量的相似性
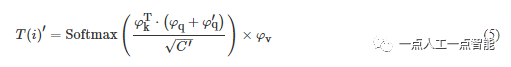
3.3 动态深度范围采样
对多尺度深度推断网络而言,合适的深度采样范围对于生成高质量的深度图至关重要。给定前一阶段的概率代价体,之前的方法仅仅关注单个像素的概率体分布以调整当前阶段的深度采样范围,然而上下文信息以及邻域像素的特征与当前像素的深度采样范围具有一定的相关性。受到文献[12]利用概率体的信息熵融合多视角代价体的启发,本文以当前阶段概率体的信息熵作为不确定性子模块的输入,评测深度推断的可靠性。该模块由5个卷积层和激活函数层组成,输出值介于0~1之间。该输出值越大,说明当前深度估计的不确定性高,应该扩大下一阶段的采样范围以覆盖真实的深度值,反之亦然。
给定概率体的信息熵图E_{est} ,使用式(6)来确定下一阶段的深度采样范围,λ是确定置信区间的超参数
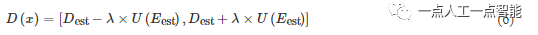
3.4 模型训练损失
区别于现有工作使用Smooth L1损失最小化预测值与真实值的差异,本文将深度估计转换为多采样深度值下的分类进行求解,交叉熵损失如式(7)所示
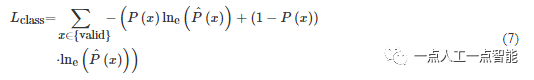
其中,\hat{P}(x) 表示当前像素x处预测深度值的概率分布,P(x) 表示真实的深度值分布,validvalid表示掩模。
考虑到本文较低的深度采样率,因此仅在初始阶段根据概率代价体分布的不确定性动态调整第2阶段的深度采样范围。为了联合学习深度值分类及其不确定性U(⋅),本文对初始阶段的损失添加负对数似然最小化的约束
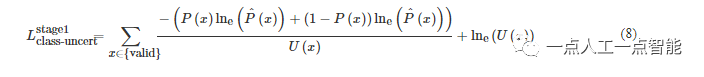
此外,本文使用交叉熵函数约束边缘检测分支的输出,真实的边缘是通过对原始图像使用Sobel算子提取得到的。多阶段深度推断的总损失定义为
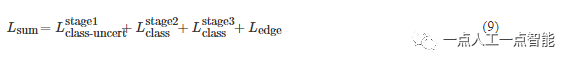
04 实验结果与分析
4.1 数据集
DTU数据集:作为大规模的MVS数据集,该数据集共包括124个场景,每个场景包含了49个视角,并在7种不同的照明条件下扫描得到。本文采用与Cas-MVSNet相同的训练集、验证集划分方式。
Tanks&Templates数据集:该基准数据集包含了室内外不同分辨率的场景。本文在包含8个场景的Intermediate数据集上,使用在DTU数据集上已训练好的模型,验证模型的生成能力。
4.2 实验细节
在训练阶段,迭代次数是12,初始学习率为0.001,并分别在第6、第8和第10个迭代进行权重衰减,以避免模型陷入局部最优。模型在单个NVIDIA RTX3090显卡上训练,多阶段的深度采样数目分别是16, 8和4,深度范围介于425~935 mm之间。特别地,在测试阶段,DTU评估集的源图像数量NN同样设置为4,输入图像分辨率为864×1152。在Tanks&Templates数据集的源图像数量NN是6,输入图像的分辨率为1080×2048。
4.3 DTU数据集对比结果
为了验证所提模型的有效性,本文在DTU数据集上开展了定量与定性实验对比。表1所示为不同方法在DTU测试集的定量对比,可以看出Gipuma[1]方法在准确性上最优,而本文重建的点云在综合性上明显优于其他主流的方法。此外,图3(a)表示不同方法在DTU测试集的显存占用对比,可以看出,本文的GPU显存占用仅为3311 MB,明显低于其他主流方法。
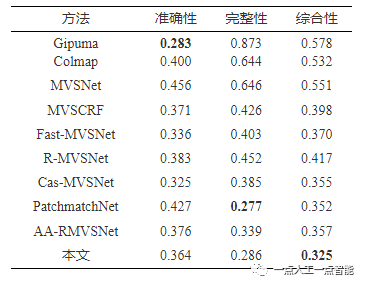
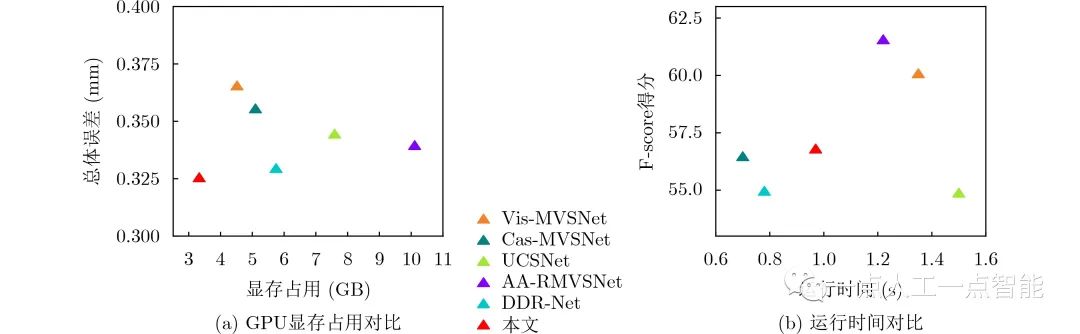
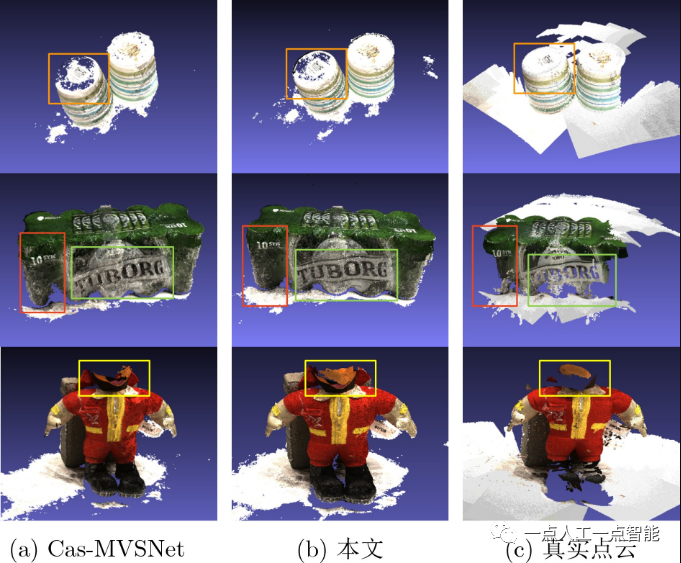
图4所示为本文方法与Cas-MVSNet关于场景重建的定性对比。尽管本文方法基于Cas-MVSNet框架,但在给定较低的深度采样率下,本文方法在弱纹理区域的重建更加稠密准确。此外,部分区域的重建完整性优于真实点云,这可能是由于引入基于Transformer的代价体聚合模块,捕获了鲁棒的上下文感知特征,减少了挑战区域中的匹配模糊和误匹配。
4.4 Tanks & Temples数据集对比结果
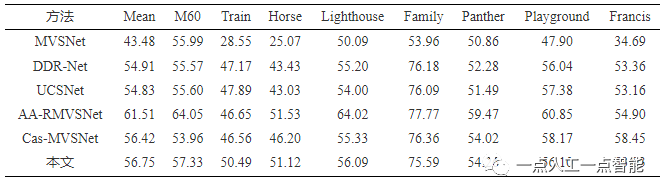
为了验证本文方法在不同场景下的生成能力,将DTU训练好的模型不经过任何微调直接在Tanks数据集上测试。表2所示为不同方法的定量对比结果,相比于主流的方法,在给定非常低的深度采样率下,本文方法重建的性能仍然具有竞争力,在8个场景的平均F-score得分仅低于AA-RMVSNet[22]。如图5所示,本文方法可以重建出相对完整的场景,这验证了所提模型的泛化能力。图3(b)是不同方法在输入分辨率为1080×2048的单帧深度图预测时间对比,可以看出本文方法的实时性仅低于Cas-MVSNet与DDR-Net[23]。

4.5 消融实验对比
4.5.1 基于分类的深度图推断
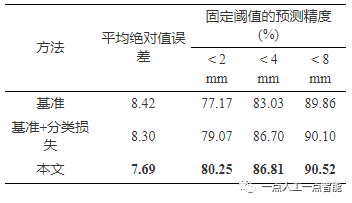
为了验证该模块的有效性,本文在DTU测试集上进行了定量实验对比,并以平均绝对误差与固定阈值(2mm, 4mm, 8mm)下的预测精度评测深度图的质量。如表3所示,为了公平地对比,本文以深度采样率为16, 8和4的Cas-MVSNet作为基准模型。可以看出,将深度回归转换为多深度值分类进行求解,模型的平均绝对误差从8.42降低到了8.30,而在固定的距离阈值内,预测精度也进一步提高。此外,如表4所示,相比于基准模型,引入分类损失使DTU数据集上综合性指标从0.372降低至0.357,已经接近表1中原始Cas-MVSNet(深度采样数目为48, 32, 8)的综合性指标0.355,进一步验证了该模块的有效性。

4.5.2 动态深度值采样
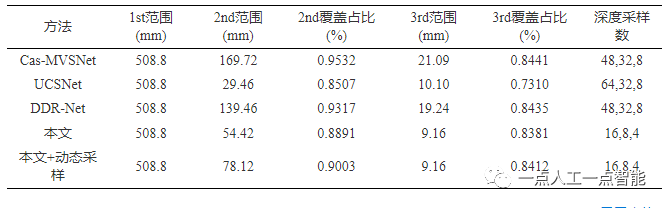
表5所示为多阶段的深度范围比较,其第5行和第6行显示采用动态深度范围采样机制的差异。可以看出,利用首阶段概率代价体的数值特性自适应调整次阶段的深度值采样范围,最大采样范围从54.42 mm扩大到78.12 mm,而覆盖真实深度值的比率从0.8891提高到0.9003。这表明在低采样率下,一些信息熵值较大的区域的深度估计不确定性高,而通过扩大相应的采样范围能够进一步覆盖真实的深度值,有效提高了弱纹理和物体边界的预测精度。
4.5.3 跨视角代价体聚合
为了验证基于极线Transformer的跨视角代价体聚合的有效性,本文对参考视角与任一源视角所构建的代价体的特征图进行可视化。如图6所示,以文献[2]采用的Group-wise聚合参考视角-源视角代价体作为基准模型,所提出的跨视角代价体聚合机制由于约束了参考视角和源视角的2D几何特征在深度方向上的一致性,弱纹理区域聚合后的特征细节更加清晰,因此聚合后的代价体抗噪能力更强。如表3所示,加入本文所提代价体聚合模块,平均绝对误差从8.30降低到了7.69,固定的距离阈值内的预测精度也相应提高。此外,如表4所示,在代价体聚合模块中引入边缘辅助信息,DTU数据集的综合性指标从0.331降低至0.327,这可能是由于边缘底层信息的约束,进一步提高了图像边界的深度推断的精度。
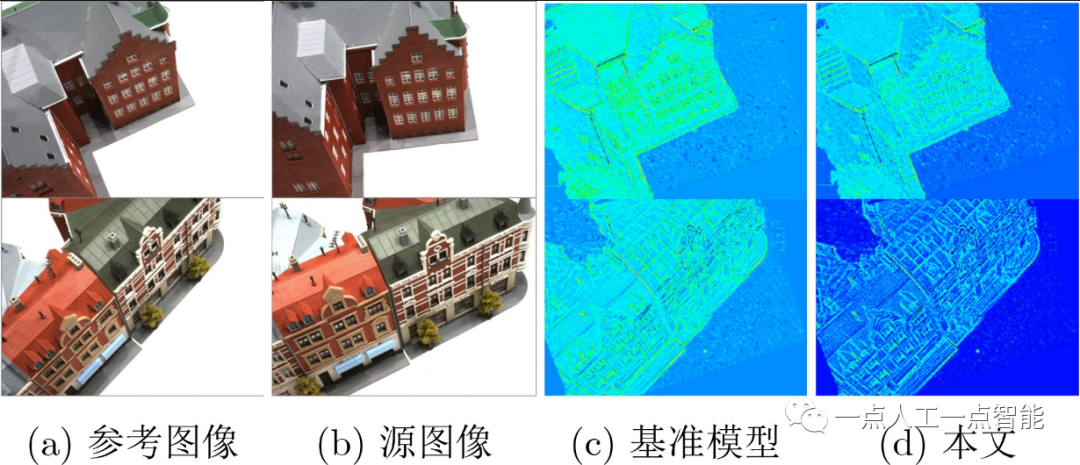
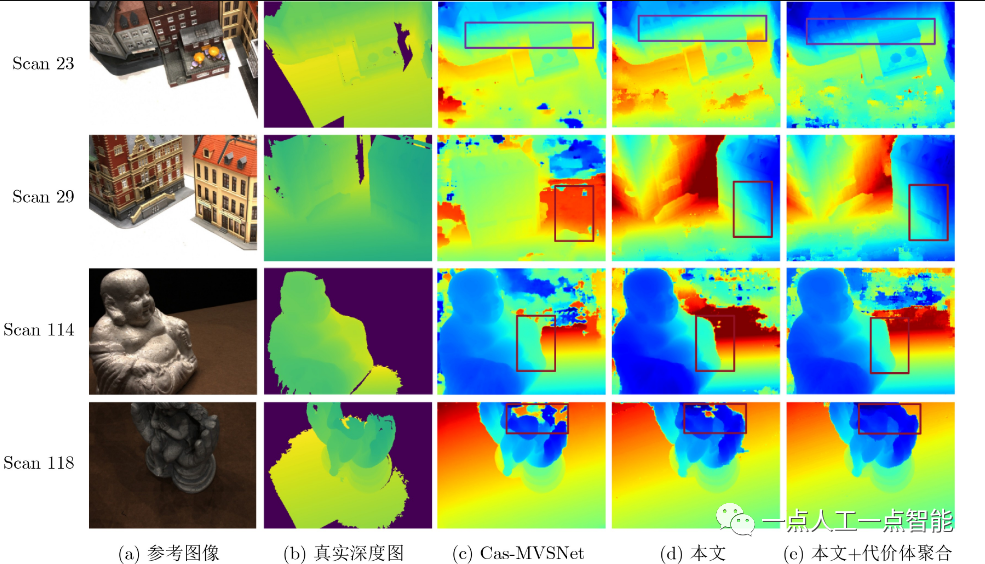
图7所示为深度图的定性对比,可以看出,相比于原始的Cas-MVSNet(深度采样率48, 32, 8),加入分类损失模块与动态深度采样模块后,图7(d)预测的深度图更加完整,且在弱纹理区域的深度值剧烈变化的现象较少。而本文在加入所提出的基于边缘辅助极线Transformer的代价体聚合模块,图7(e)预测的深度图在弱纹理区域具有更好的抗噪能力,且在物体边界处的预测更加清晰。
05 结束语
本文提出一种基于边缘辅助极线Transformer的多视图深度推断网络。
首先将深度回归转换为多深度值的分类进行求解,可以在有限的深度采样率下保证深度推断的准确性。
其次,采用基于边缘辅助极线Transformer的跨视角代价体聚合模块捕获全局上下文特征以及3D几何一致性特征,提高弱纹理区域的密集匹配。
为了进一步提高深度推断的精度,采用基于概率代价体的数值特性的自适应深度范围采样机制。
相比于现有的基于CNN的MVS网络,在DTU和Tanks & Temples数据集的综合实验表明本文方法在有限的显存和运行时间下,能够实现稠密准确的场景重建,且模型具有良好的泛化能力。
在未来的工作中,希望进一步探索基于Transformer的密集特征匹配,替代3D CNN对代价体进行正则化处理,降低模型对于高显存的依赖,并提高模型在移动端部署的实用性。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。