requests库常用函数使用——爬虫基础(1)
requests库常用函数使用——爬虫基础(1)

requests库常用函数使用——爬虫基础(1)
前言
所有的前置环境以及需要学习的基础我都放置在【Python基础(适合初学-完整教程-学习时间一周左右-节约您的时间)】中,学完基础咱们再配置一下Python爬虫的基础环境【看完这个,还不会【Python爬虫环境】,请你吃瓜】,搞定了基础和环境,我们就可以相对的随心所欲的获取想要的数据了,所有的代码都是我一点点写的,都细心的测试过,如果某个博客爬取的内容失效,私聊我即可,留言太多了,很难看得到,本系列的文章意在于帮助大家节约工作时间,希望能给大家带来一定的价值。
示例环境
系统环境:win11 开发工具:PyCharm Community Edition 2022.3.1 Python版本:Python 3.9.6 资源地址:链接:https://pan.baidu.com/s/1UZA8AAbygpP7Dv0dYFTFFA 提取码:7m3e MySQL:5.7,url=【rm-bp1zq3879r28p726lco.mysql.rds.aliyuncs.com】,user=【qwe8403000】,pwd=【Qwe8403000】,库比较多,自己建好自己的,别跟别人冲突。

学习目标:
requests库的使用方法是我们本节课的学习目标,但是为什么学它呢,因为Python自带的urllib库相对来说没有requests更为好用,特别是使用cookie的时候,故而我们后面爬取信息的时候都会去使用requests库。
环境下载:
打开cmd直接使用下面的下载语句即可,不过pip需要是最新的。
下载语句:【pip install requests】
如果不是最新的我们需要升级pip,我这里给了个流程,是先修改镜像地址为HUAWEI的地址,因为是国内的所以相对来说快些。
pip config set global.index-url https://repo.huaweicloud.com/repository/pypi/simple
pip config list
pip install -U piprequests库位置:
例如:cookie的操作,我们可以直接保存浏览器中的cookie,使用【CookieJar】即可。
步骤1、先输出,根据输出保存一个【cookies.txt】文件
import http.cookiejar
import urllib.request
cookie = http.cookiejar.CookieJar() # 必须声明一个CookieJar对象
handler = urllib.request.HTTPCookieProcessor(cookie) # 用于处理Cookies,利用HTTPCookieProcessor来构建一个Handler
opener = urllib.request.build_opener(handler) # 利用build_opener()方法构建出Opener
response = opener.open('输入你已经登录好的网站主页即可,注意这个主页的cookie已经可以查到。') # 执行open()函数
# 输出了每条Cookie的名称和值
for item in cookie:
print(item.name + '=' + item.value)这是输出的Cookie样式
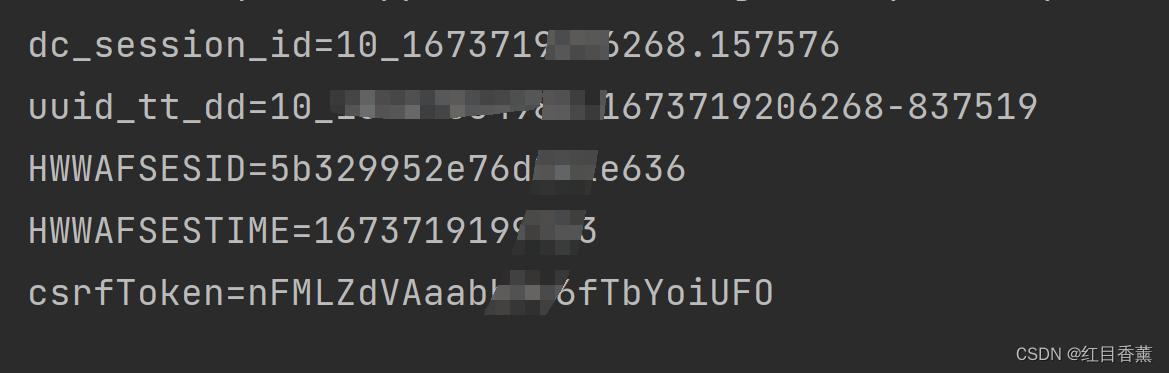
我们把这个输出内容保存到一个【cookies.txt】中。
步骤二、更换格式
import http.cookiejar
import urllib.request
# 这里是根据步骤1所保存的文件
filename = 'cookies.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('还是你的网站')
cookie.save(ignore_discard=True, ignore_expires=True)格式类似于这样
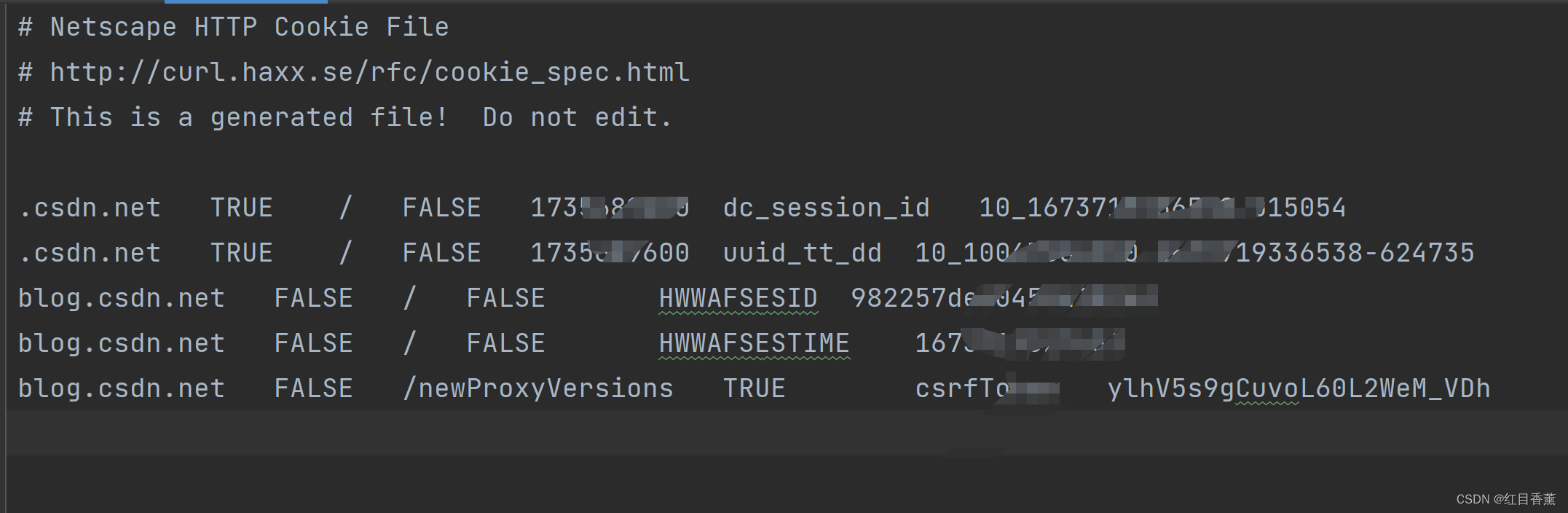
步骤三、#LWP-Cookies-2.0格式
import http.cookiejar as cookielib
import http
import urllib
filename = 'cookies.txt'
cookie = http.cookiejar.LWPCookieJar(filename) # LWPCookieJar同样可以读取和保存Cookies,它会保存成libwww-perl(LWP)格式的Cookies文件。
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('https://blog.csdn.net/feng8403000')
cookie.save(ignore_discard=True, ignore_expires=True)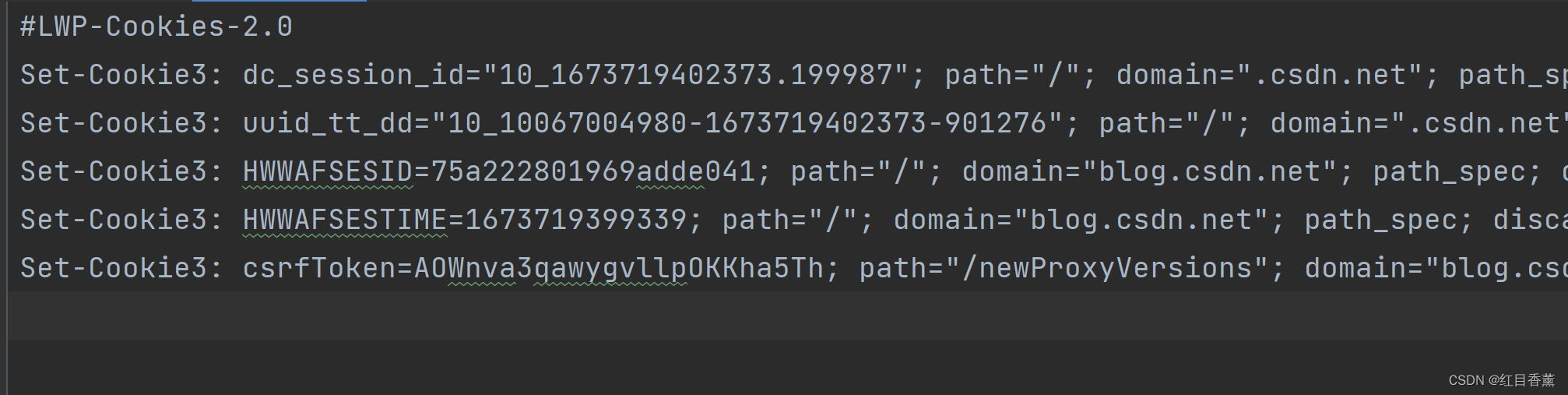
这里只是个示例,是否测试都一样。
演示代码
实验前提,项目创建的时候我们选择系统库的位置。
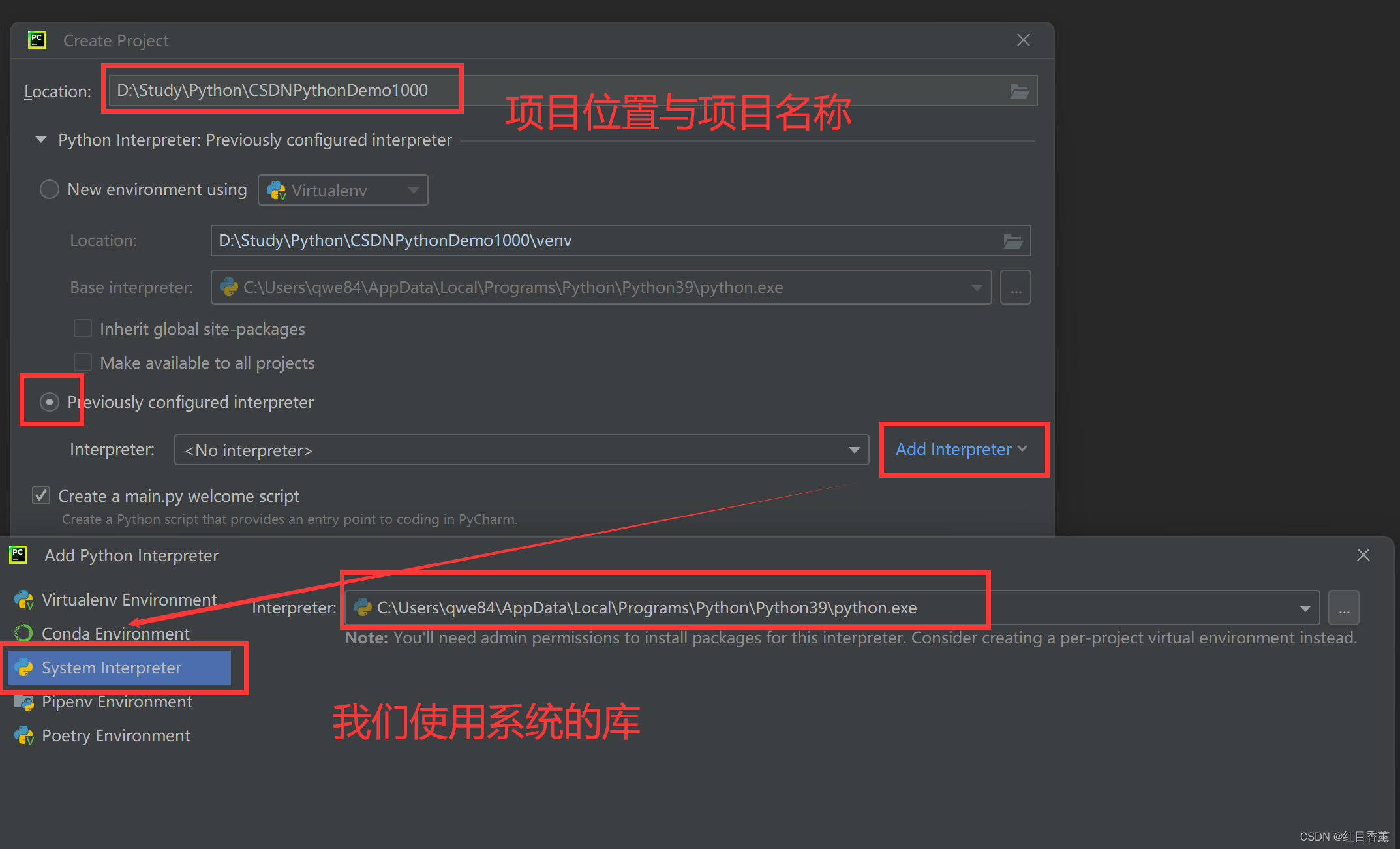
使用系统库我们就能在cmd下载完成后直接导入到项目中,可以大大的节约咱们的项目所占空间。
requests基本使用
引入【requests库】,我们下载完成后直接使用【import requests】引入即可。
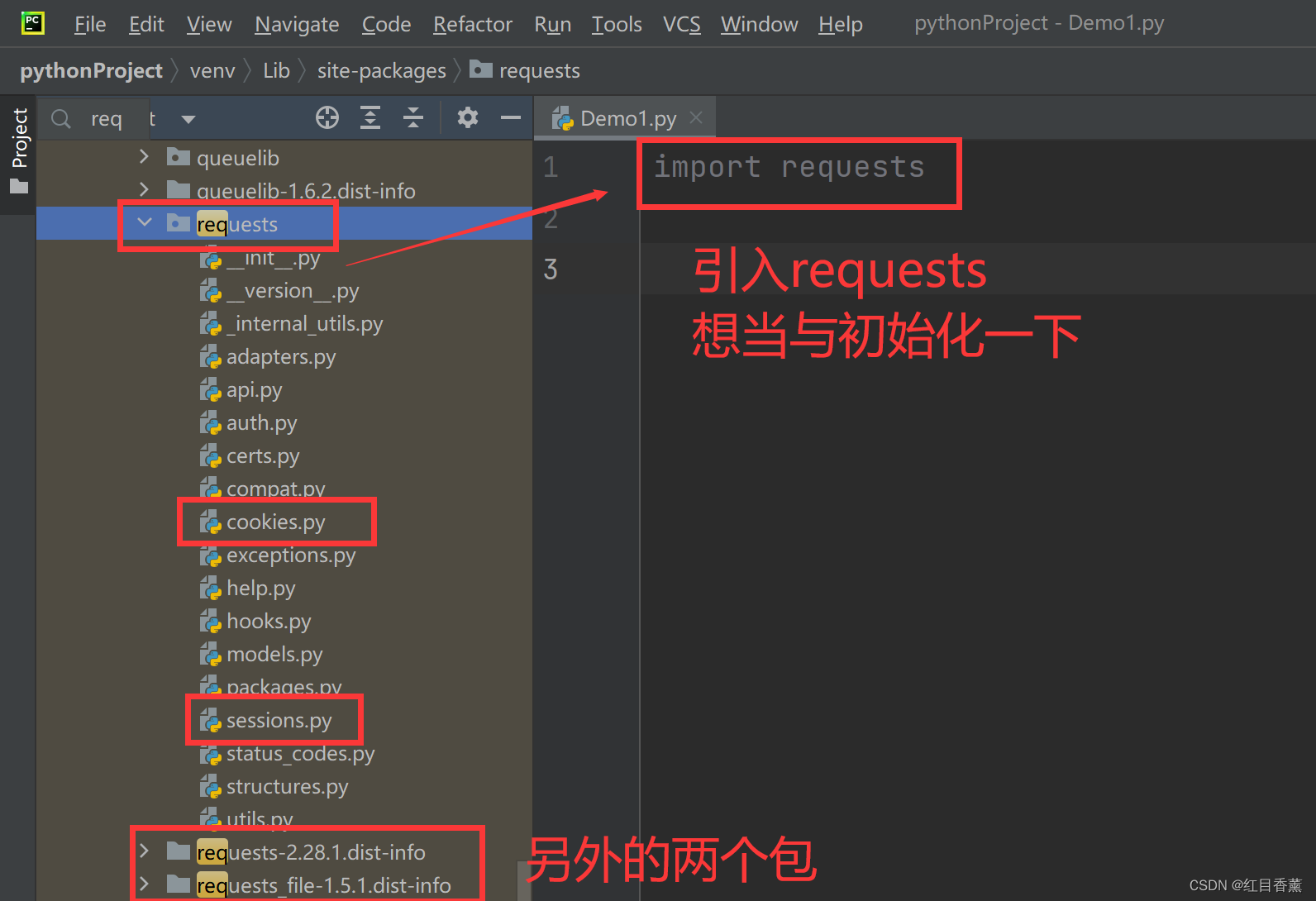
requests基础请求
这里使用【requests.request】来做测试。
请求的方式有七种:get、post、put、delete、delete、patch、options。
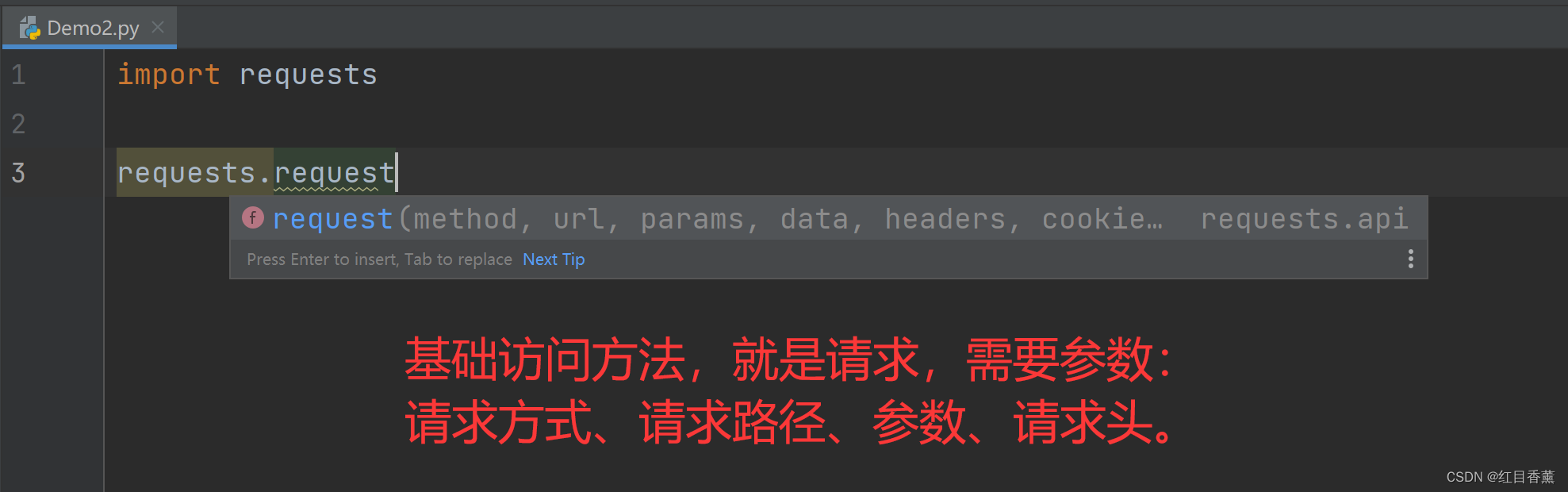
请求效果:
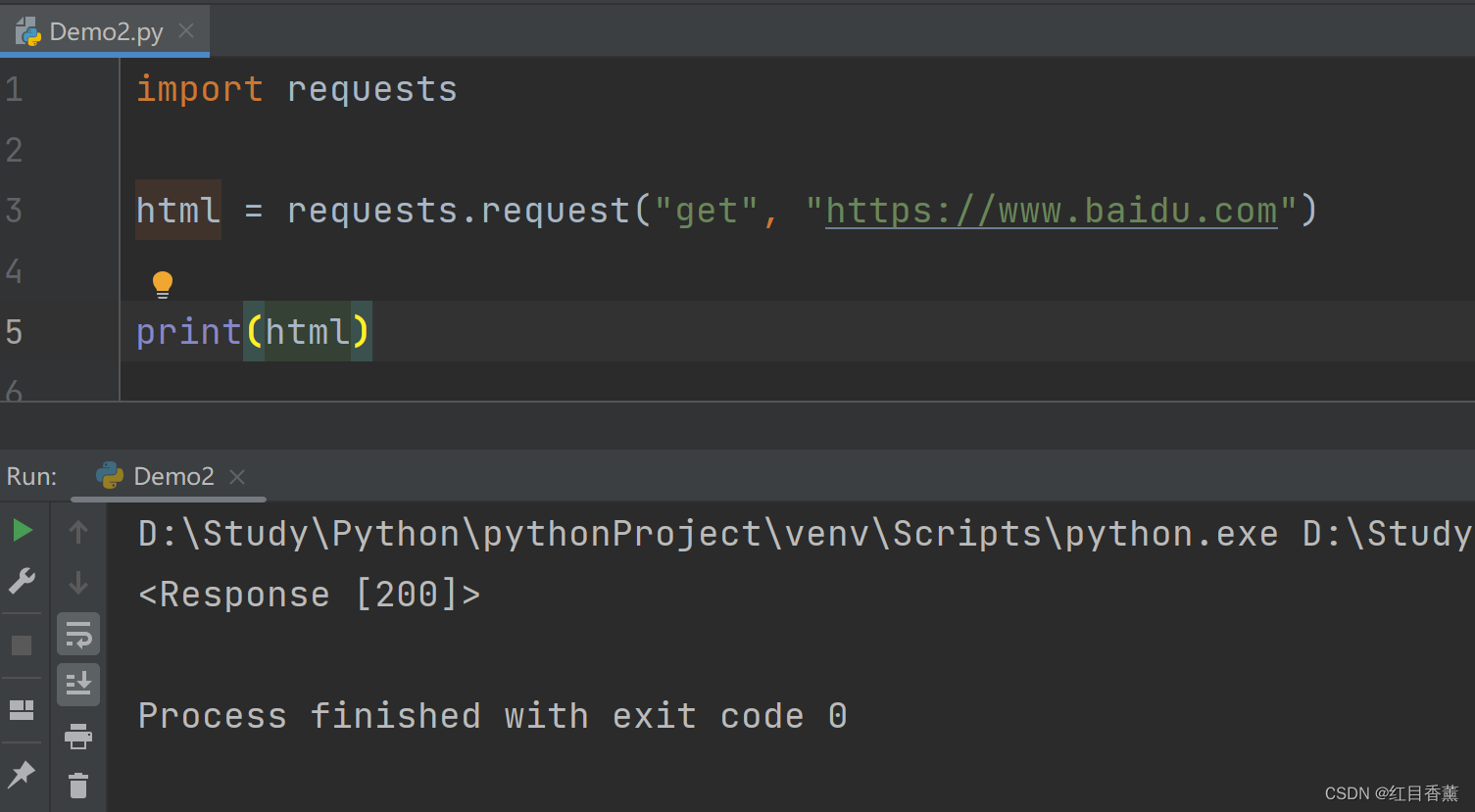
我们一般不使用这里请求,我也不是很喜欢用,我一般就直接使用get/post的方式直接访问了,免得单独输入一遍,一共七种方式都可以直接使用。
requests请求测试
基础请求我们使用get就行,get请求相对来说所有的链接都能直接使用浏览器打开,测试起来很方便,因为如果使用post你在测试的时候需要使用工具进行模拟测试。但是我们如果传递了data就不需要传递params了。
示例代码:
import requests
url = "http://japi.juhe.cn/qqevaluate/qq"
data = {"qq": "372699828",
"key": "输入自己的key"}
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
}
html = requests.get(url, data, headers=headers)
print(html.content.decode("utf-8"))测试成功
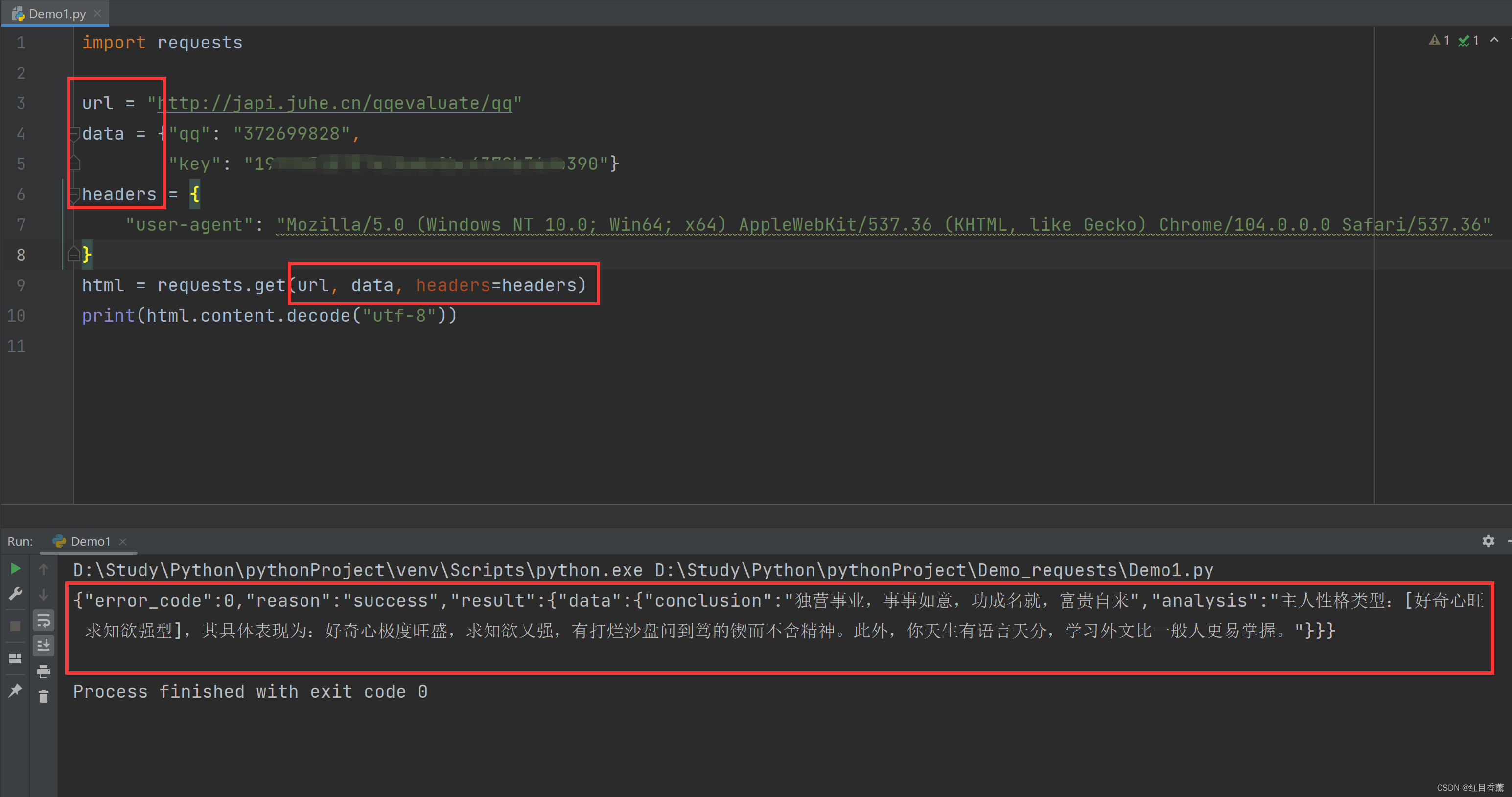
我们在基础的测试中一共传递了三个参数,第一个参数是访问链接的字符串,第二个我们传递了data就不需要传递params了,第三个是传递的请求头,这里一定要添加请求头,否则很多接口是无法正常访问的。
headers解析
在请求网页爬取的时候,输出的返回信息中会出现抱歉,无法访问等字眼,这就是禁止爬取,需要通过反爬机制去解决这个问题。 headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据,如果有IP代理器那就更好了。 对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。
headers位置
F12打开->网络->找到主页->查看标头->查看请求标头,这就是我们的请求头,一般我们添加【user-agent】就行,赋值的时候不需要赋值【:】开头的那几个。
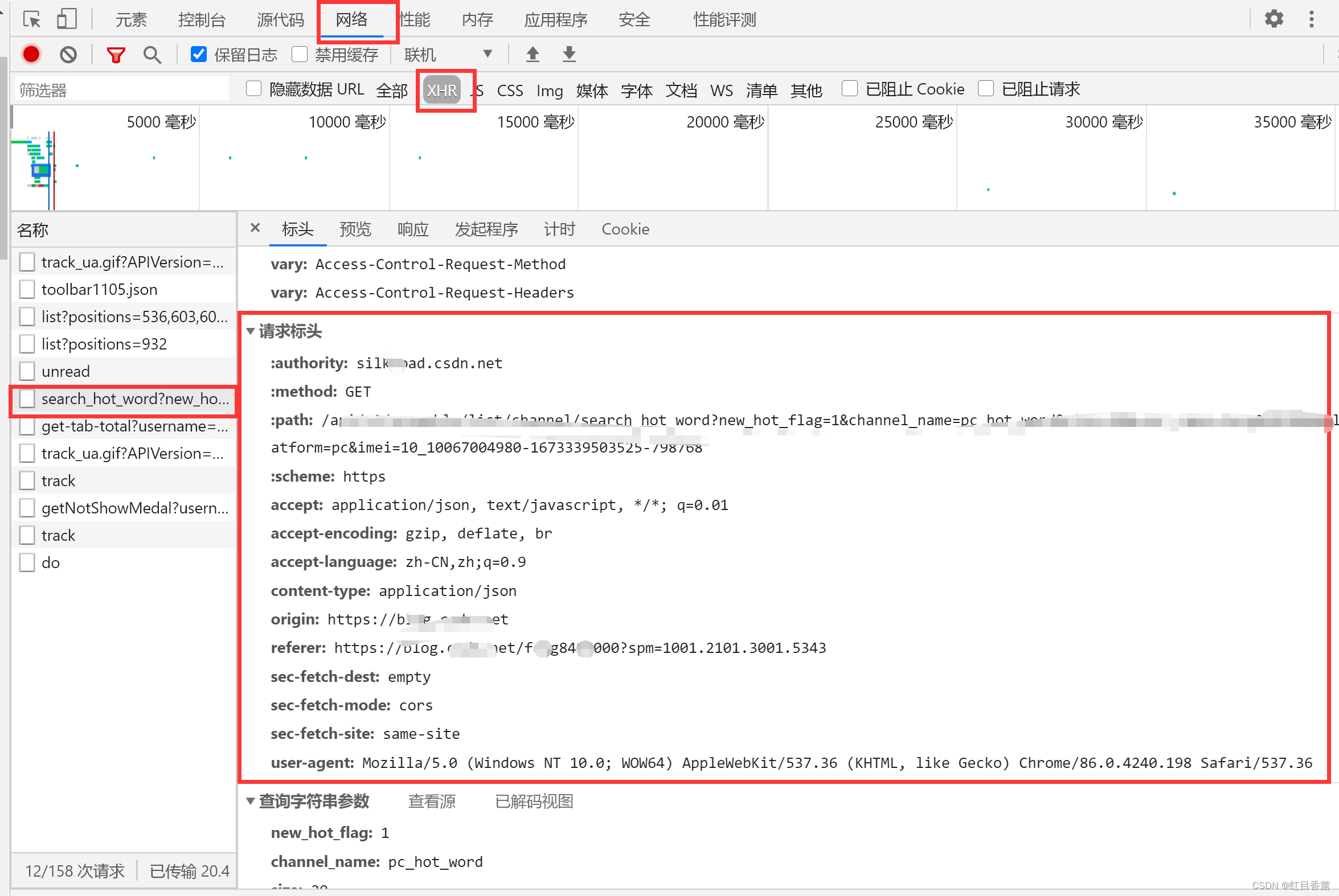
复制后有一些符号其实我们不会用,所以我们需要替换一下,下面是替换代码,我这里没有复制【:】开头的那几个。
import re
# 下方引号内添加替换掉请求头内容
headers_str = """
accept: application/json, text/javascript, */*; q=0.01
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9
content-type: application/json
origin: https://blog.csdn.net
referer: https://blog.csdn.net/feng8403000?spm=1001.2101.3001.5343
sec-fetch-dest: empty
sec-fetch-mode: cors
sec-fetch-site: same-site
user-agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36
"""
pattern = '^(.*?):(.*)$'
for line in headers_str.splitlines():
print(re.sub(pattern, '\'\\1\':\'\\2\',', line).replace(' ', ''))requests返回结果
返回字符串
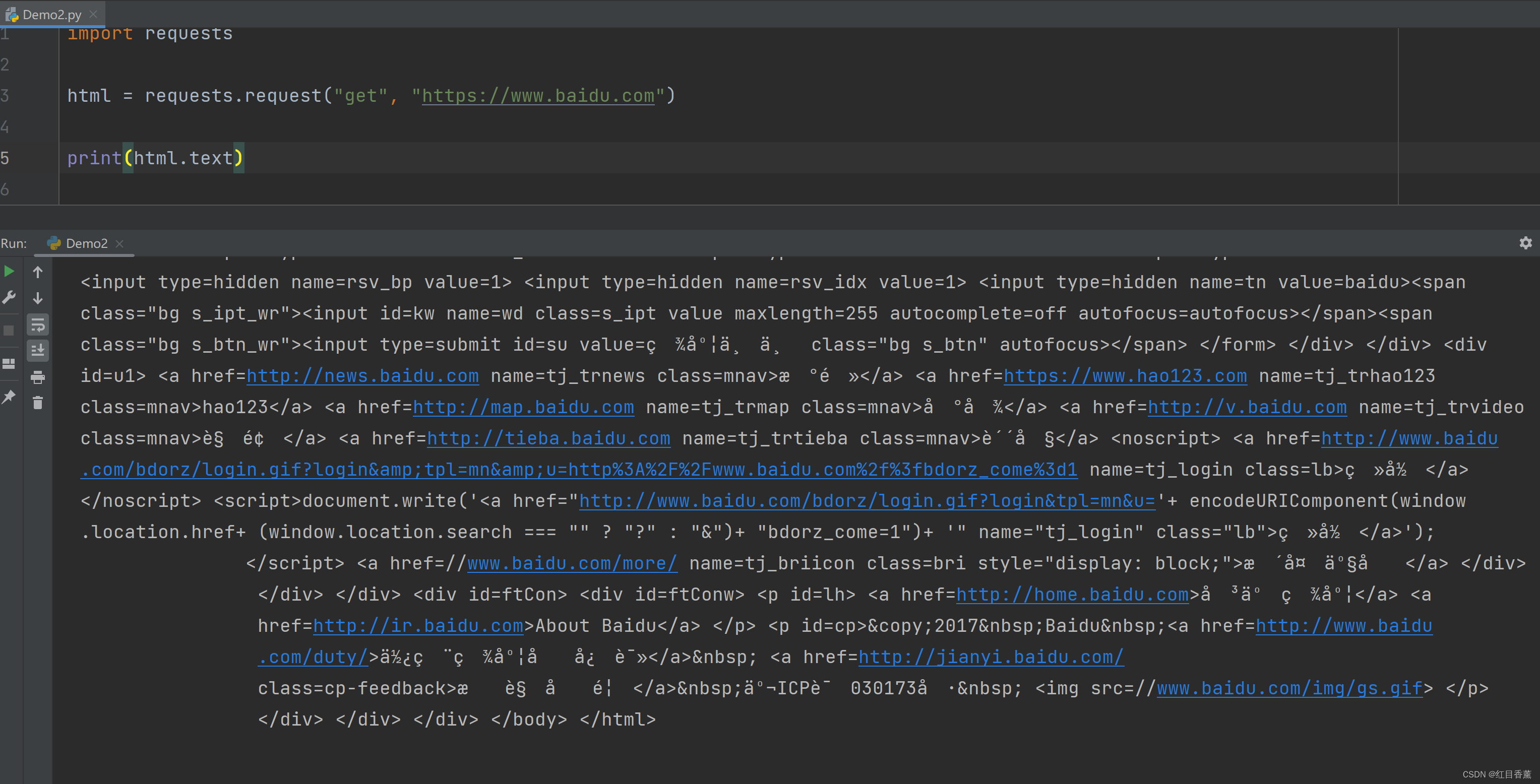
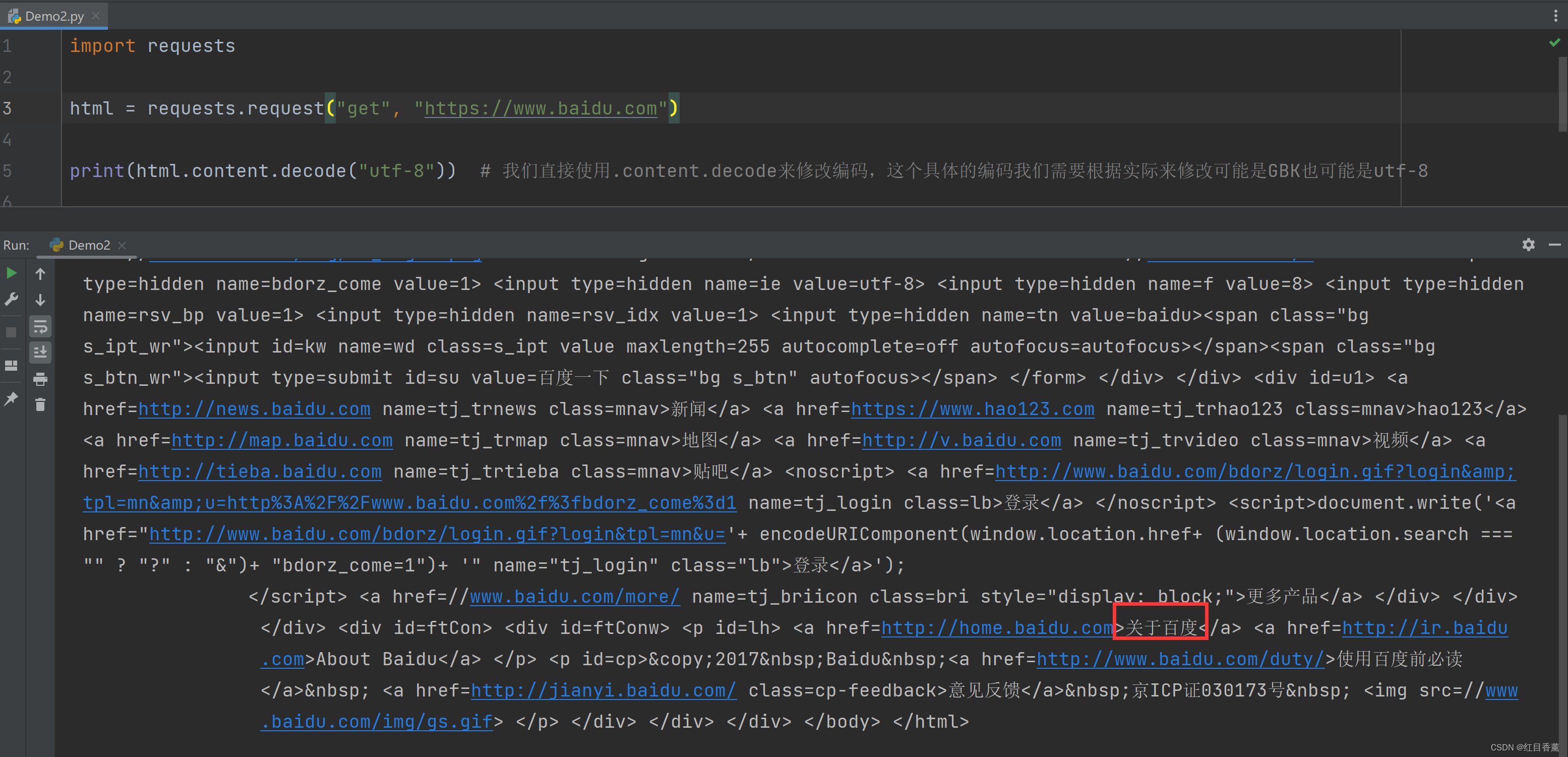
import requests
html = requests.request("get", "https://www.baidu.com")
print(html.text)这里返回的字符串格式是有问题的,我们能看到编码格式有问题。
修改返回字符串编码格式
我们直接使用.content.decode来修改编码,这个具体的编码我们需要根据实际来修改可能是GBK也可能是utf-8。
import requests
html = requests.request("get", "https://www.baidu.com")
print(html.content.decode("utf-8")) # 我们直接使用.content.decode来修改编码,这个具体的编码我们需要根据实际来修改可能是GBK也可能是utf-8可以看到,现在的编码格式就没有问题了。
响应结果涉及函数
我这里将常用的函数都举例出来了,我们可以根据我们的需求进行选用。
import requests
html = requests.request("get", "https://www.baidu.com")
# 输出返回类型与结果
print(type(html.text), "\n输出前200字符串做测试:", html.text[0:200], "\n")
# 响应内容(bytes类型)
print(type(html.content), "\n输出前200字符串做测试:", html.content[0:200], "\n")
# 状态码
print(type(html.status_code), "\n输出状态码:", html.status_code, "\n")
# 响应头
print(type(html.headers), "\n输出响应头:", html.headers, "\n")
# Cookies
print(type(html.cookies), "\n输出Cookies:", html.cookies, "\n")
# URL
print(type(html.url), "\n输出路径:", html.url, "\n")对应的六个输出:

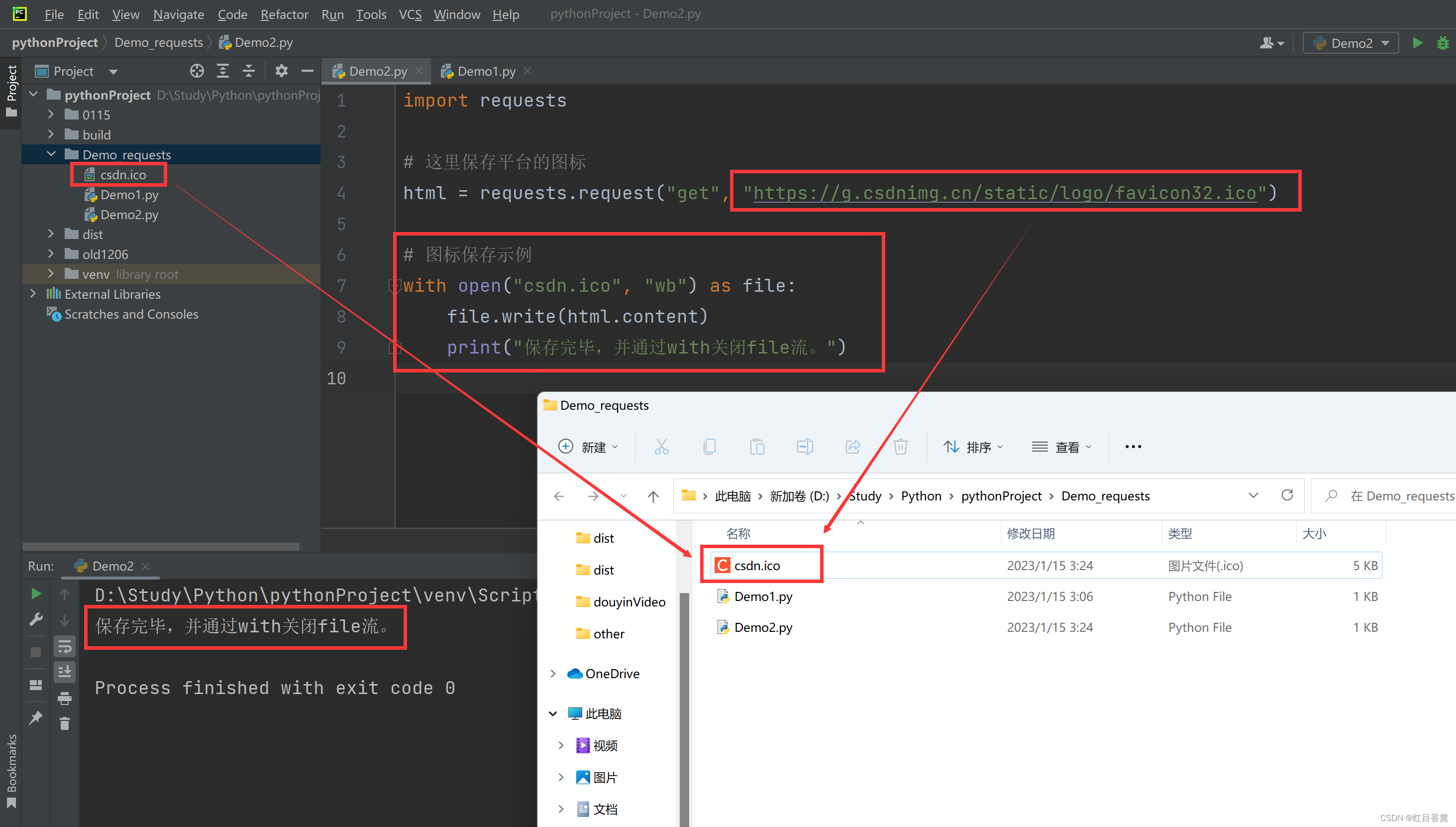
文件保存
这里我们先保存一个ico文件测试。
import requests
# 这里保存平台的图标
html = requests.request("get", "https://g.csdnimg.cn/static/logo/favicon32.ico")
# 图标保存示例
with open("csdn.ico", "wb") as file:
file.write(html.content)
print("保存完毕,并通过with关闭file流。")保存效果:
基础HTML格式访问成功后我们去试试json。
返回json
我们返回的数据直接json进行格式化,格式化的数据是json数据类型的,可以直接进行json操作。
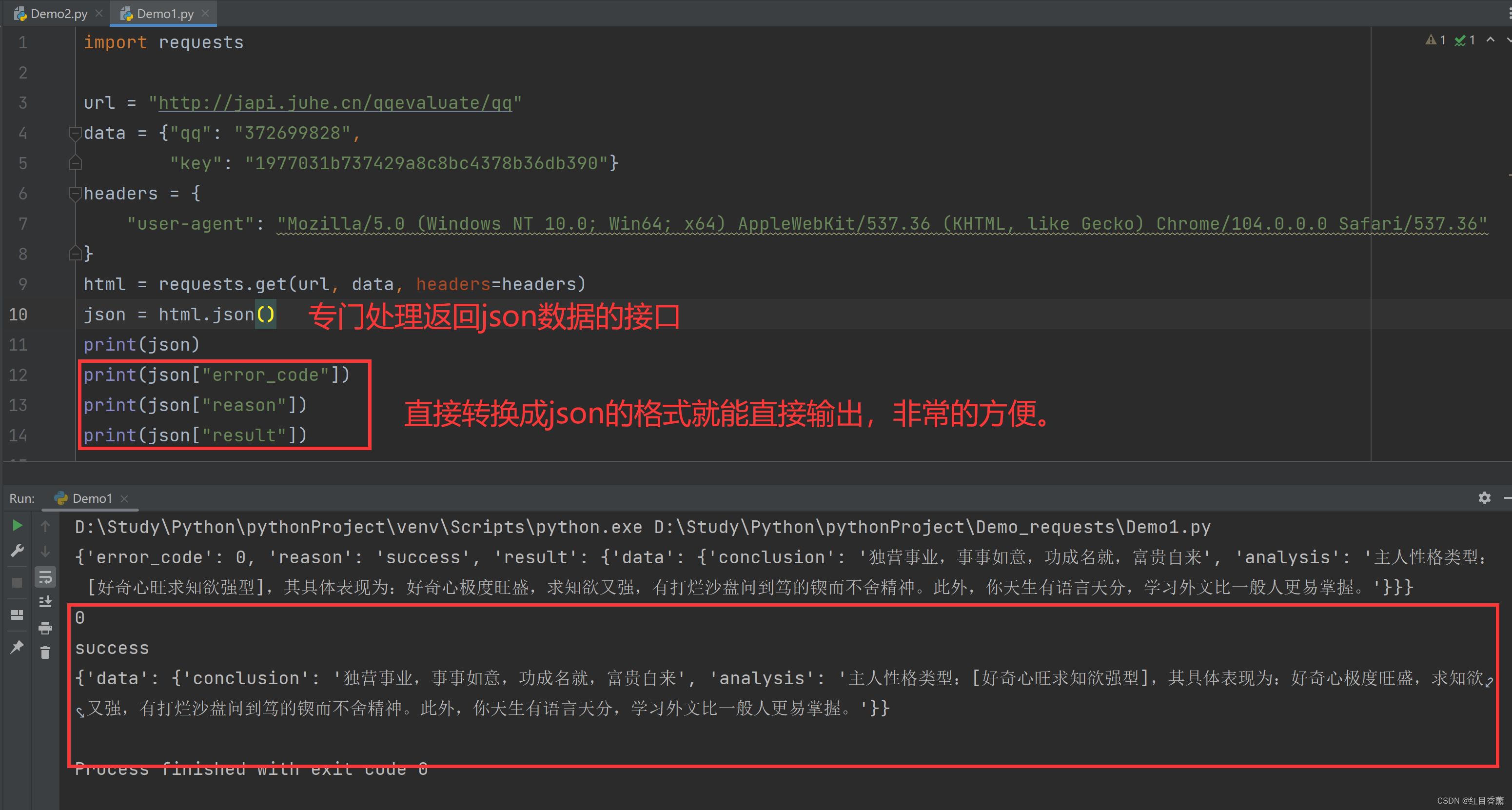
我们可以通过在F12中查找到我们需要的json接口来进行信息的获取,方便很多。
https证书异常
import requests
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
}
html = requests.get('https://www.12306.cn', headers=headers, verify=False)
print(html.status_code)这里能看到虽然是200,但是报错【Unverified HTTPS】 也就是证书有问题了。
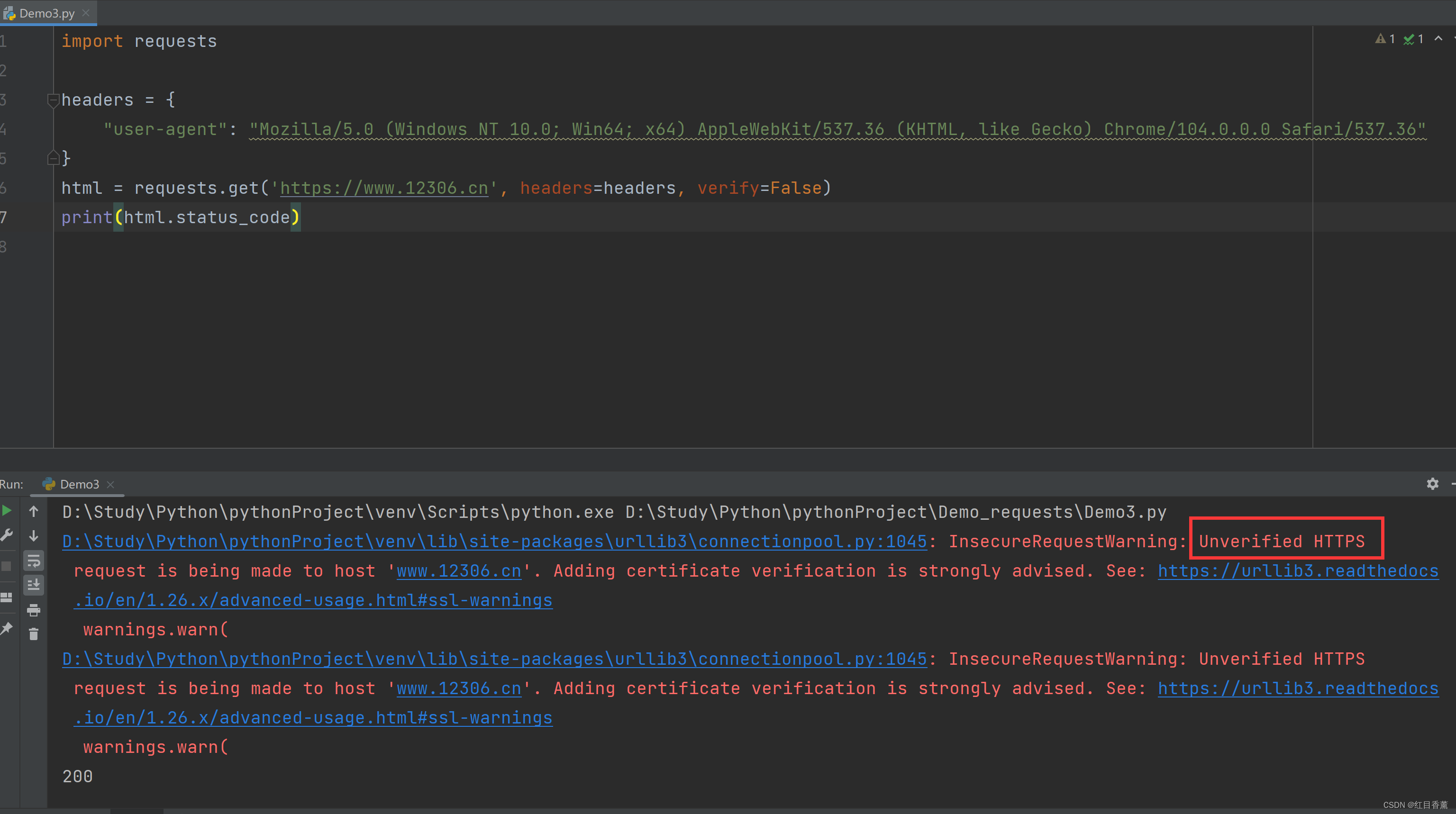
由于没有证书故而报这个错。
import logging
import requests
# 我们过滤一下就好了
logging.captureWarnings(True)
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
}
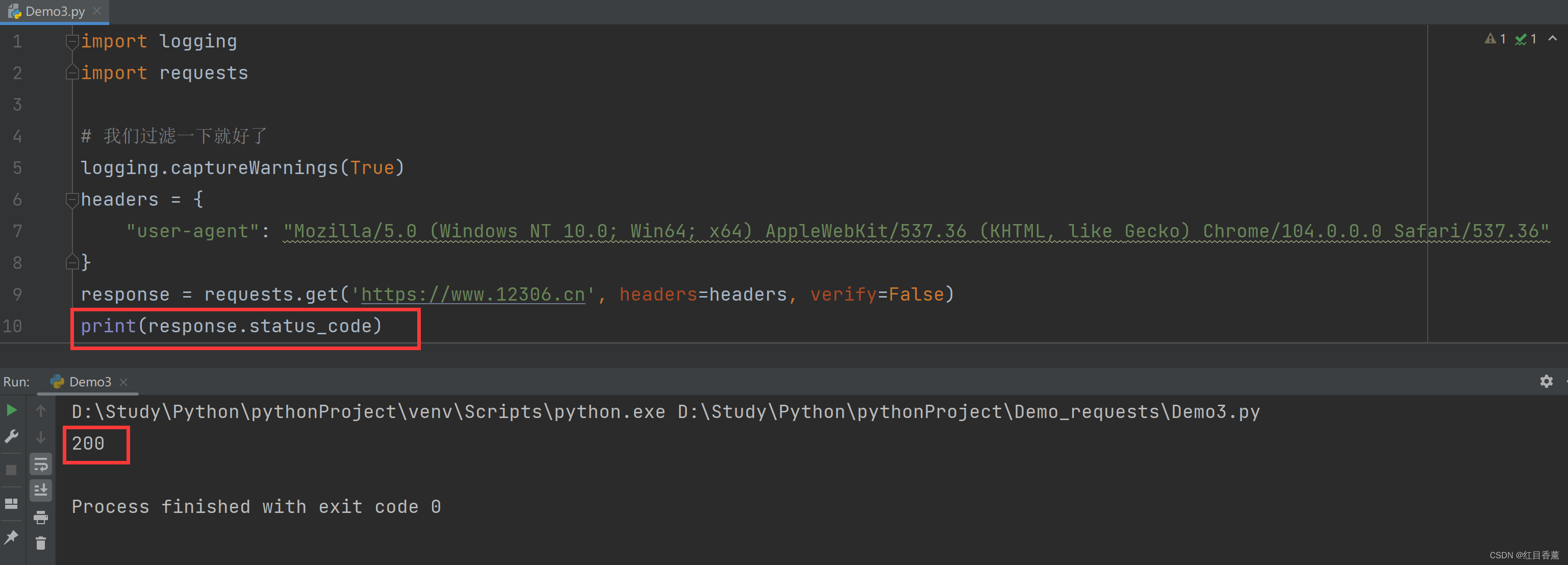
response = requests.get('https://www.12306.cn', headers=headers, verify=False)
print(response.status_code)我们直接过滤一下这个异常提示就行了:
动态IP代理
这里主要就是设置:【proxies】的值,配置到requests的访问上就能改变请求的ip与端口号了。
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
}
autoId = "42.54.83.73:39050"
proxies = {
'http': autoId,
'https': autoId
}
html = requests.get(readUrl, headers=headers, proxies=proxies)代理效果:
总结:
本文章我们把整个requests常用的函数都讲解过了,其实没有说的就是超时设置了,超时设置就是timeout的设置,我们可以设置一个元组是时间范围,例如:(5,30)这是5~30秒,如果超过30s后就会显示超时。
我们将本文章的常用内容掌握之后基本的访问是没有什么问题了,如果是post的接口我们直接将get改成post即可。希望孩子们能用心搞定这个库的知识,会对后面的获取数据有很大的帮助。