Dubbo2.7的Dubbo SPI实现原理细节
原创
总结/朱季谦
本文主要记录我对Dubbo SPI实现原理的理解,至于什么是SPI,我这里就不像其他博文一样详细地从概念再到Java SPI细细分析了,直接开门见山来分享我对Dubbo SPI的见解。
Dubbo SPI的机制比较类似Spring IOC的getBean()加载,当传入一个存在的beanName,就可以返回该beanName对应的对象。同理,在Dubbo SPI中,我们同样传入一个存在的name,Dubbo框架会自动返回该key对应的对象。不难猜测,Dubbo SPI与Spring IOC在底层应该都有一个大致相似的逻辑,简单的说,就是两者都可通过beanName或key值,到框架里的某个map缓存当中,找到对应的class类名,然后对该class类名进行反射生成对象,初始化完成该对象,最后返回一个完整的对象。然而,在这个过程当中,Spirng相对来说会更复杂,它里面还有一堆后置处理器......
简单举一个例子,大概解释一下Dubbo SPI实现原理,然后再进一步分析源码。
首先,我在org.apache.dubbo.test目录下,定义一个@SPI注解到接口:
package org.apache.dubbo.test;
import org.apache.dubbo.common.extension.SPI;
@SPI("dog")
public interface Animal {
void haveBehavior();
}然后,在同一个目录下,创建两个实现该接口的类,分别为Dog,Cat。
Dog——
package org.apache.dubbo.test;
public class Dog implements Animal {
@Override
public void haveBehavior() {
System.out.println("狗会叫");
}
}Cat——
package org.apache.dubbo.test;
public class Cat implements Animal {
@Override
public void haveBehavior() {
System.out.println("猫会抓老鼠");
}
}注意看,Animal接口的类名为org.apache.dubbo.test.Animal,接下来,我们在resource目录的/META_INF/dubbo需新建一个对应到该接口名的File文件,文件名与Animal接口的类名一致:org.apache.dubbo.test.Animal。之所以两者名字要一致,是因为这样只需拿到Animal接口的类名,到resource目录的/META_INF/dubbo,就可以通过该类名,定位到与Animal接口相对应的文件。
在Dubbo中,文件名org.apache.dubbo.test.Animal的文件里,其实存了类似Spring bean那种<bean id="cat" class="org.apache.dubbo.test.Cat"/>的数据,即id对应bean class的形式——
cat=org.apache.dubbo.test.Cat
dog=org.apache.dubbo.test.Dog这两行数据,分别是Animal接口的实现类Cat和Dog的class全限名。
整个的目录结构是这样的——
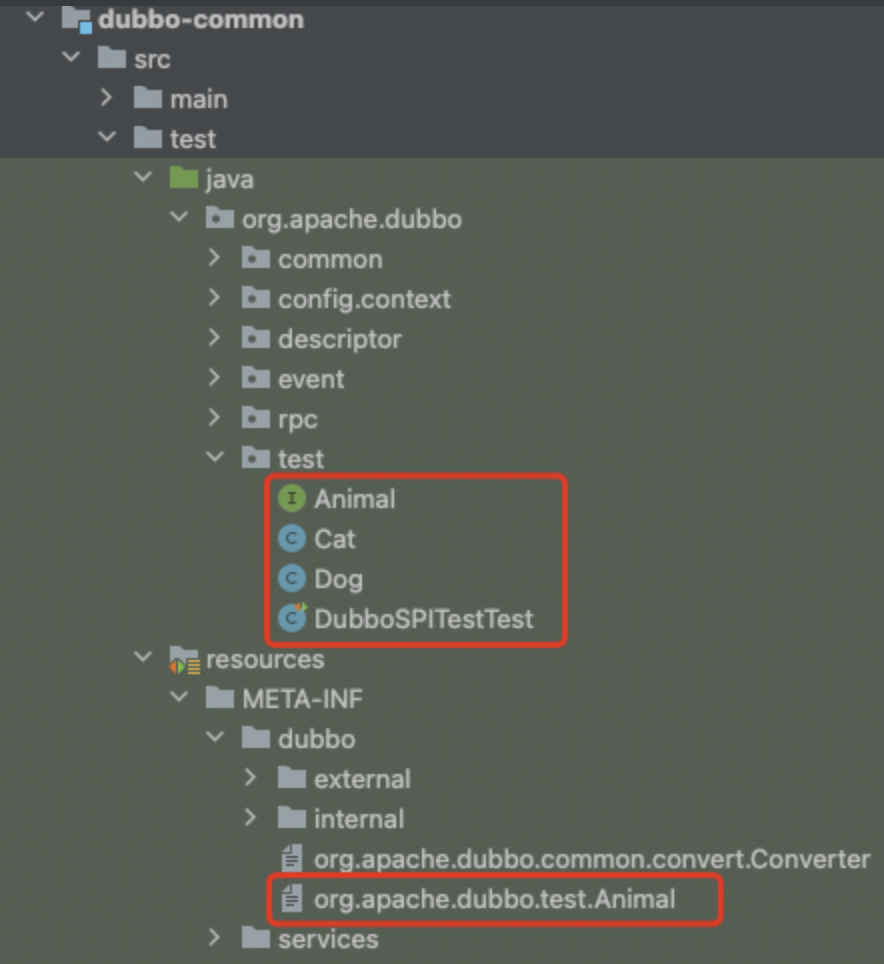
最后写一个测试类DubboSPITestTest演示一下效果——
package org.apache.dubbo.test;
import org.apache.dubbo.common.extension.ExtensionLoader;
import org.junit.jupiter.api.Test;
class DubboSPITestTest {
@Test
public void test(){
Animal dog = ExtensionLoader.getExtensionLoader(Animal.class).getExtension("dog");
dog.haveBehavior();
Animal cat = ExtensionLoader.getExtensionLoader(Animal.class).getExtension("cat");
cat.haveBehavior();
}
}执行结果如下——
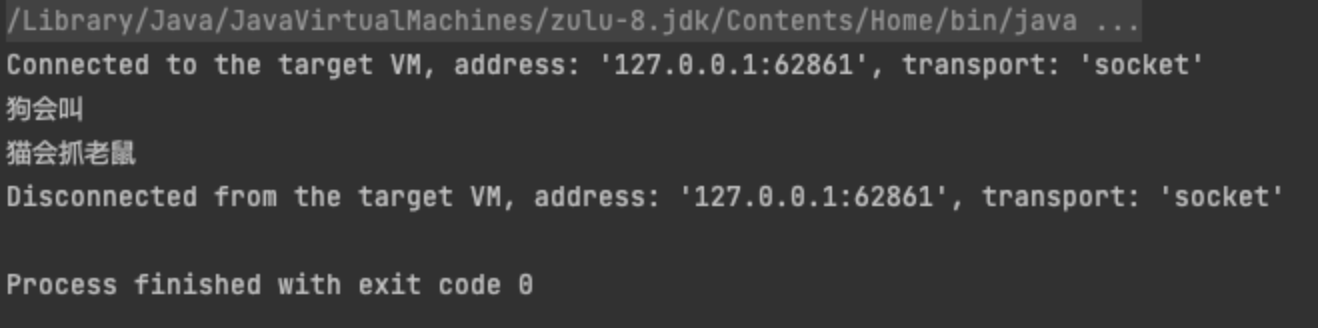
先简单捋一下这个思路是怎么实现的,ExtensionLoader.getExtensionLoader(Animal.class).getExtension("dog")这行代码内部,会根据Animal接口完整名org.apache.dubbo.test.Animal找到某个指定目录下的同名File文件org.apache.dubbo.test.Animal,然后按行循环解析文件里的内容,以key-value形式加载到某个map缓存里。
类似这样操作(当然,源码里会更复杂些)——
Map<String,String> map = new HashMap<>();
map.put("cat","org.apache.dubbo.test.Cat");
map.put("dog","org.apache.dubbo.test.Dog");当然,真实源码里,value存的是已根据类名得到的Class,但其实无论是类名还是Class,最后都是可以反射生成对象的,
这时候,就可以根据运行代码去动态获取到该接口对应的实现类了。例如,需要使用的是org.apache.dubbo.test.Cat这个实现类,那么在调用getExtension("cat")方法中,我们传入的参数是"cat",就会从刚刚解析文件缓存的map中,根据map.get("cat")拿到对应org.apache.dubbo.test.Cat。既然能拿到类名了,不就可以通过反射的方式生成该类的对象了吗?当然,生成的对象里可能还有属性需要做注入操作,这就是Dubbo IOC的功能,这块会在源码分析里进一步说明。当对象完成初始化后,就会返回生成的对象指向其接口引用Animal dog = ExtensionLoader.getExtensionLoader(Animal.class).getExtension("dog")。
整个过程,就是可根据代码去动态获取到某个接口的实现类,方便灵活调用的同时,实现了接口和实现类的解耦。
Dubbo SPI是在Java SPI基础上做了拓展,Java SPI中与接口同名的文件里,并不是key- value的形式,纯粹是按行来直接存放各实现类的类名,例如这样子——
org.apache.dubbo.test.Cat
org.apache.dubbo.test.Dog这就意味着,Java SPI在实现过程中,通过接口名定位读取到resource中接口同名文件时,是无法做到去选择性地根据某个key值来选择某个接口的实现类,它只能全部读取,再全部循环获取到对应接口实现类调用相应方法。这就意味着,可能存在一些并非需要调用的实现类,也会被加载并生成对象一同返回来,无法做到按需获取。
因此,Dubbo在原有基础上,则补充了Java SPI无法按需通过某个key值去调用指定的接口实现类,例如上面提到的,Dubbo SPI可通过cat这个key,去按需返回对应的org.apache.dubbo.test.Cat类的实现对象。
下面就来分析一下具体实现的原理细节,以下代码做案例。
Animal cat = ExtensionLoader.getExtensionLoader(Animal.class).getExtension("cat");
cat.haveBehavior();先来分析ExtensionLoader.getExtensionLoader(Animal.class)方法——
public static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
//判断传进来参数是否空
if (type == null) {
throw new IllegalArgumentException("Extension type == null");
}
//判断是否为接口
if (!type.isInterface()) {
throw new IllegalArgumentException("Extension type (" + type + ") is not an interface!");
}
//判断是否具有@SPI注解
if (!withExtensionAnnotation(type)) {
throw new IllegalArgumentException("Extension type (" + type +
") is not an extension, because it is NOT annotated with @" + SPI.class.getSimpleName() + "!");
}
ExtensionLoader<T> loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
if (loader == null) {
EXTENSION_LOADERS.putIfAbsent(type, new ExtensionLoader<T>(type));
loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
}
return loader;
}在这个方法里,若传进来的Class参数为空或者非接口或者没有@SPI注解,都会抛出一个IllegalArgumentException异常,说明传进来的Class必须需要满足非空,为接口,同时具有@SPI注解修饰,才能正常往下执行。我们在这里传进来的是Animal.class,它满足了以上三个条件。
@SPI("cat")
public interface Animal {
void haveBehavior();
}接下来,在最后这部分代码里,主要是创建一个ExtensionLoader对象。
ExtensionLoader<T> loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
if (loader == null) {
EXTENSION_LOADERS.putIfAbsent(type, new ExtensionLoader<T>(type));
loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
}
return loader;最后,返回的也是创建的ExtensionLoader对象,该对象包括了两个东西,一个是type,一个是objectFactory。这两个东西在后面源码里都会用到。
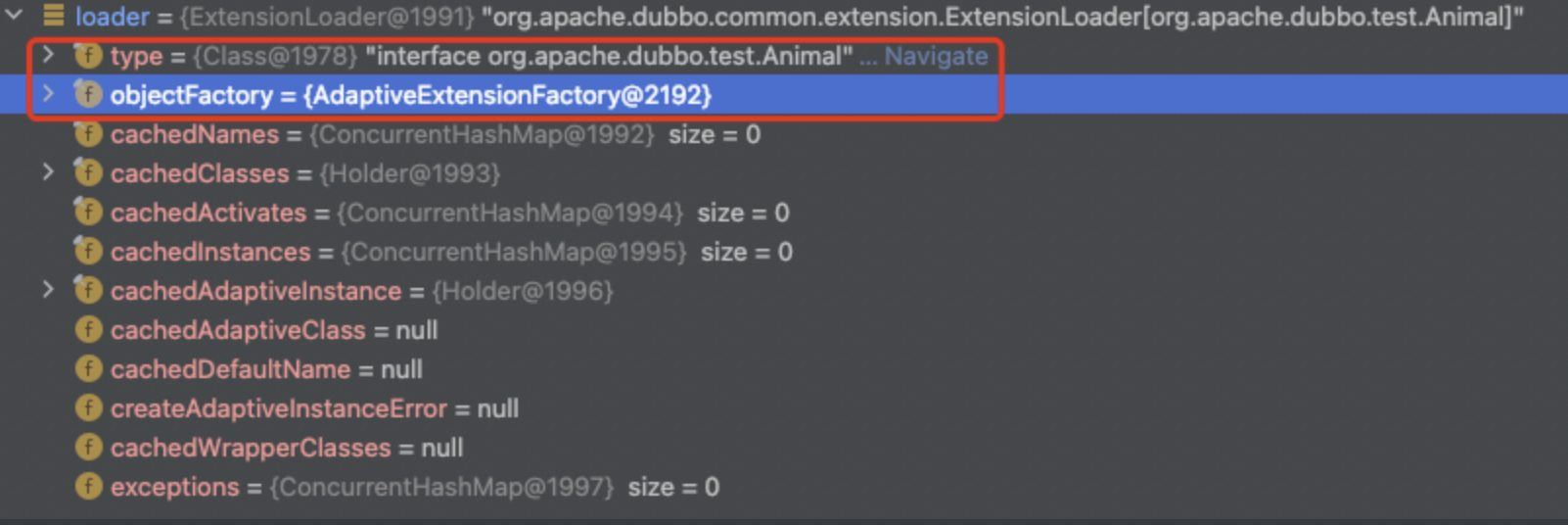
创建完ExtensionLoader对象后,就会开始调用getExtension方法——
Animal cat = ExtensionLoader.getExtensionLoader(Animal.class).getExtension("cat");进入到getExtension("cat")方法当中,内部会调用另一个重载方法getExtension(name, true)。
public T getExtension(String name) {
return getExtension(name, true);
}让我们来看一下该方法内部实现——
public T getExtension(String name, boolean wrap) {
if (StringUtils.isEmpty(name)) {
throw new IllegalArgumentException("Extension name == null");
}
if ("true".equals(name)) {
return getDefaultExtension();
}
//step 1
final Holder<Object> holder = getOrCreateHolder(name);
Object instance = holder.get();
//step 2
//双重检查
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
//创建扩展实例
instance = createExtension(name, wrap);
//设置实例到holeder中
holder.set(instance);
}
}
}
return (T) instance;
}该方法主要有两部分。
step 1,先从缓存里查找name为“cat”的对象是否存在,即调用getOrCreateHolder(name),在该方法里,会去cachedInstances缓存里查找。cachedInstances是一个定义为ConcurrentMap<String, Holder<Object>>的map缓存。若cachedInstances.get(name)返回null的话,说明缓存里还没有name对应的对象数据,那么就会创建一个key值为name,value值为new Holder<>()的键值对缓存。
private Holder<Object> getOrCreateHolder(String name) {
Holder<Object> holder = cachedInstances.get(name);
if (holder == null) {
cachedInstances.putIfAbsent(name, new Holder<>());
holder = cachedInstances.get(name);
}
return holder;
}想必你一定会有疑惑,为什么这里要创建一个new Holder<>()对象呢?
进到Holder类里,就会发现,其内部用private修饰封装一个泛型变量value,这就意味着,外部类是无法修改该value值,能起到一个封装保护的作用。我们正在通过name='cat'去得到一个org.apache.dubbo.test.Cat实现类对象,该对象若能正常生成,最后就会封装到一个Holder对象里,再将Holder对象存放到cachedInstances缓存里。
public class Holder<T> {
private volatile T value;
public void set(T value) {
this.value = value;
}
public T get() {
return value;
}
}因此,就会有该从缓存里获取Holder的操作——
//根据name为“cat”去缓存里查找封装了org.apache.dubbo.test.Cat对象的Holder对象。
final Holder<Object> holder = getOrCreateHolder(name);
//若能查找到,就从Holder对象取出内部封装的对象
Object instance = holder.get();若holder.get()得到的对象为null,说明还没有生成该“cat”对应的org.apache.dubbo.test.Cat类对象。
那么,就会继续往下执行——
//双重检查
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
//创建扩展实例
instance = createExtension(name, wrap);
//设置实例到holeder中
holder.set(instance);
}
}
}这里用到了一个双重检查的操作,避免在多线程情况里出现某一个线程创建了一半,另一个线程又开始创建同样对象,就会出现问题。
这行instance = createExtension(name, wrap)代码,主要实现的功能,就是得到“cat”对应的org.apache.dubbo.test.Cat类对象,然后将返回的对象通过holder.set(instance)封装在Holder对象里。
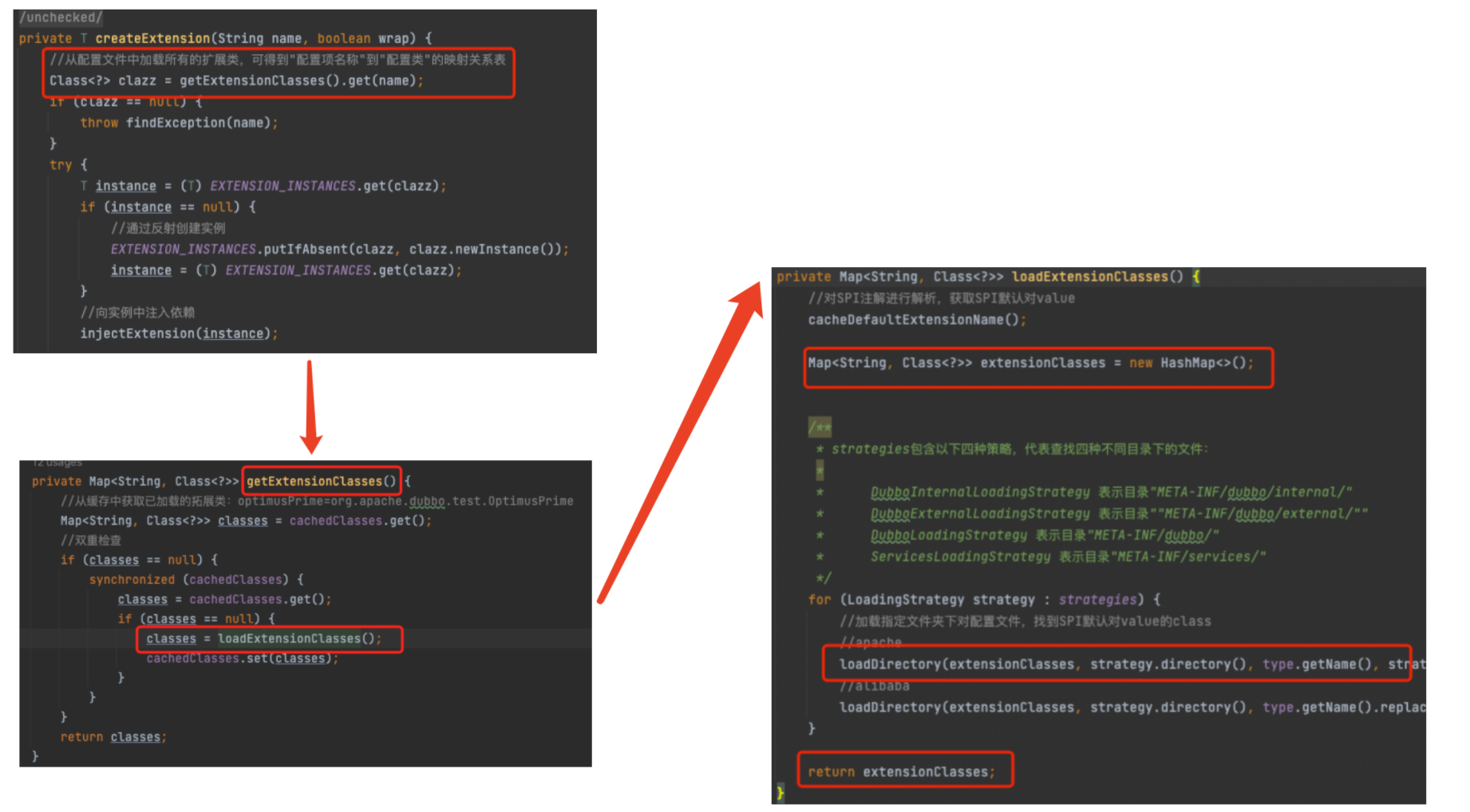
private T createExtension(String name, boolean wrap) {
// step 1从配置文件中加载所有的扩展类,可得到"配置项名称"到"配置类"的映射关系表
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
throw findException(name);
}
try {
T instance = (T) EXTENSION_INSTANCES.get(clazz);
if (instance == null) {
//step 2 将得到的clazz通过反射创建实例对象。
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
//step 3 对实例对象的属性做依赖注入,即Dubbo IOC逻辑。
injectExtension(instance);
if (wrap) {
List<Class<?>> wrapperClassesList = new ArrayList<>();
if (cachedWrapperClasses != null) {
wrapperClassesList.addAll(cachedWrapperClasses);
wrapperClassesList.sort(WrapperComparator.COMPARATOR);
Collections.reverse(wrapperClassesList);
}
if (CollectionUtils.isNotEmpty(wrapperClassesList)) {
for (Class<?> wrapperClass : wrapperClassesList) {
Wrapper wrapper = wrapperClass.getAnnotation(Wrapper.class);
if (wrapper == null
|| (ArrayUtils.contains(wrapper.matches(), name) && !ArrayUtils.contains(wrapper.mismatches(), name))) {
//将当前instance作为参数传给Wrapper的构造方法,并通过反射创建Wrapper实例
//然后向Wrapper实例注入依赖,最后将Wrapper实例再次赋值给instance变量
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
}
}
initExtension(instance);
//step 4 返回初始化完成的对象
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance (name: " + name + ", class: " +
type + ") couldn't be instantiated: " + t.getMessage(), t);
}
}createExtension(String name, boolean wrap)方法里主要实现了以下
step 1 从配置文件中加载所有的扩展类,可得到"配置项名称"到"配置类"的映射关系表。
step 2 将得到的clazz通过反射创建实例对象。
step 3 对实例对象的属性做依赖注入,即Dubbo IOC逻辑。
step 4 返回初始化完成的对象
先来看第一步的代码分析——
// step 1从配置文件中加载所有的扩展类,可得到"配置项名称"到"配置类"的映射关系表
Class<?> clazz = getExtensionClasses().get(name);其中getExtensionClasses()方法是获取返回一个解析完接口对应Resource里文件的Map<String, Class<?>>缓存,代码最后部分get(name)在这个案例里,就是根据“cat”获得“org.apache.dubbo.test.Cat”的Class。方法内部cachedClasses.get()返回的这个Map<String,Class<?>> classes正是存放了接口对应Resource文件里key- value数据,即car=org.apache.dubbo.test.Cat和dog=org.apache.dubbo.test.Dog这类。
private Map<String, Class<?>> getExtensionClasses() {
//从缓存中获取已加载的拓展类:car=org.apache.dubbo.test.Cat
Map<String, Class<?>> classes = cachedClasses.get();
//双重检查
if (classes == null) {
synchronized (cachedClasses) {
classes = cachedClasses.get();
if (classes == null) {
classes = loadExtensionClasses();
cachedClasses.set(classes);
}
}
}
return classes;
}当然,首次调用cachedClasses.get()返回值classes肯定为null。这里在classes==null时,同样使用了一个双重检查的操作,最后会去调用loadExtensionClasses()方法,该方法主要做的一件事,就是去读取到Resource中接口对应的文件进行解析,然后将解析的数据以key-value缓存到Map<String, Class<?>>里,最后通过cachedClasses.set(classes)存入到cachedClasses里,这里的cachedClasses同样是一个final定义的Holder对象,作用与前文提到的一致,都是封装在内部以private修饰,防止被外部类破坏。
主要看下loadExtensionClasses()内部逻辑——
private Map<String, Class<?>> loadExtensionClasses() {
//step 1 对SPI注解进行解析,获取SPI默认对value
cacheDefaultExtensionName();
Map<String, Class<?>> extensionClasses = new HashMap<>();
/**
* step 2 strategies包含以下四种策略,代表查找四种不同目录下的文件:
*
* DubboInternalLoadingStrategy 表示目录"META-INF/dubbo/internal/"
* DubboExternalLoadingStrategy 表示目录""META-INF/dubbo/external/""
* DubboLoadingStrategy 表示目录"META-INF/dubbo/"
* ServicesLoadingStrategy 表示目录"META-INF/services/"
*/
for (LoadingStrategy strategy : strategies) {
//加载指定文件夹下对配置文件,找到SPI默认对value的class
//apache
loadDirectory(extensionClasses, strategy.directory(), type.getName(), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
//alibaba
loadDirectory(extensionClasses, strategy.directory(), type.getName().replace("org.apache", "com.alibaba"), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
}
return extensionClasses;
}首先,执行cacheDefaultExtensionName()方法,该方法是对接口修饰的@SPI进行解析,获取注解里的value值。例如,在该例子里,Animal的注解@SPI("cat"),那么,通过cacheDefaultExtensionName()方法,即能获取到注解@SPI里的默认值“cat”。之所以获取该注解的值,是用来当做默认值,即如果没有传入指定需要获取的name,那么就返回cat对应的类对象。
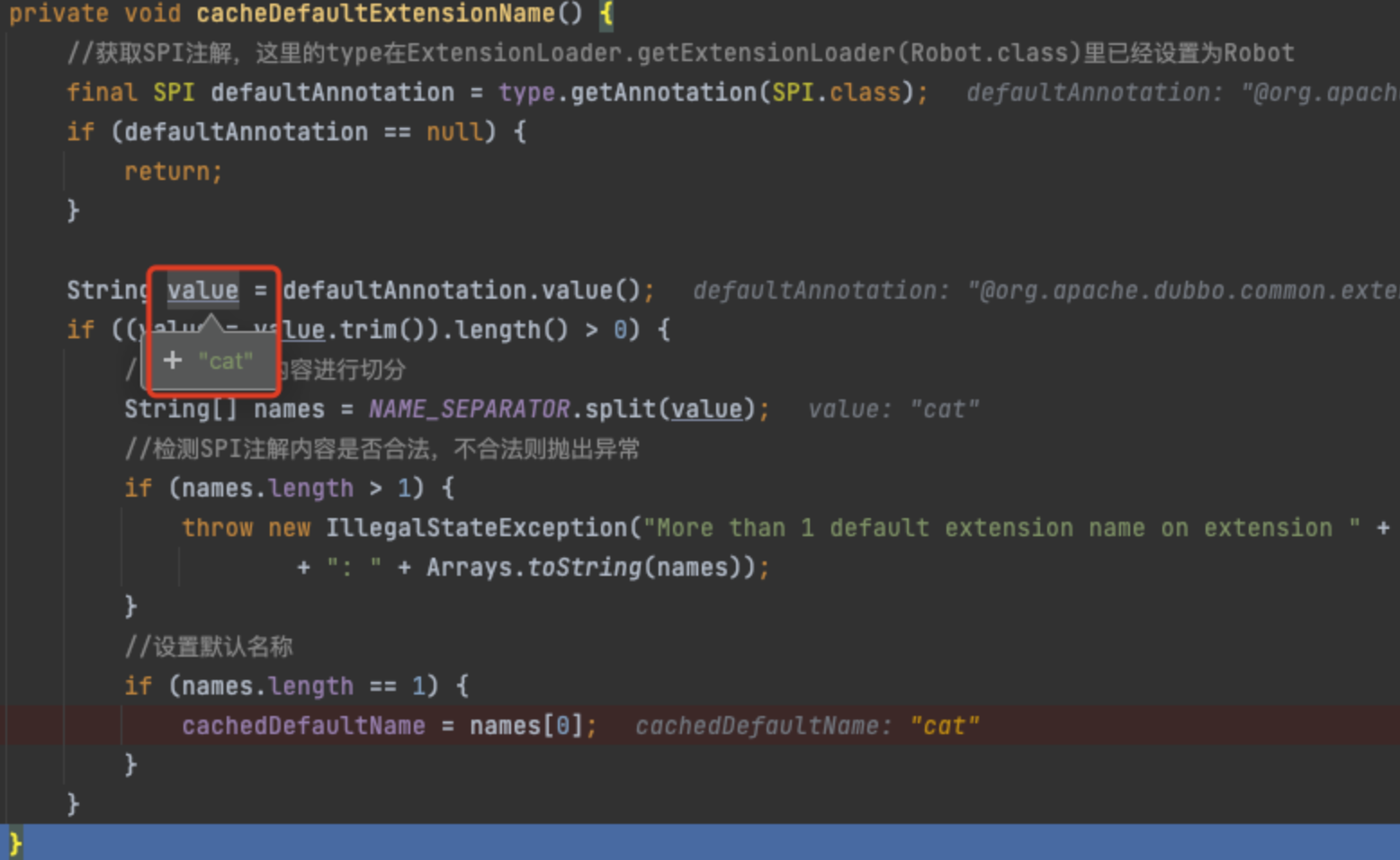
接着,就是遍历四种不同目录,查找是否有与接口Animal对应的文件。这里的strategies是一个数组,里面包含四种对象,每个对象代表查找某个目录,包括"META-INF/dubbo/internal/"、"META-INF/dubbo/external/"、"META-INF/dubbo/"、"META-INF/services/",表示分别到这四种目录去查看是否有满足的文件。
for循环里调用了两次loadDirectory方法,群分就是一个是查找apache版本的,一个是查找alibaba版本的,两方法底层其实都是一样,只需要关注其中一个实现即可。
/**
* step 2 strategies包含以下四种策略,代表查找四种不同目录下的文件:
*
* DubboInternalLoadingStrategy 表示目录"META-INF/dubbo/internal/"
* DubboExternalLoadingStrategy 表示目录"META-INF/dubbo/external/"
* DubboLoadingStrategy 表示目录"META-INF/dubbo/"
* ServicesLoadingStrategy 表示目录"META-INF/services/"
*/
for (LoadingStrategy strategy : strategies) {
//加载指定文件夹下对配置文件,找到SPI默认对value的class
//apache
loadDirectory(extensionClasses, strategy.directory(), type.getName(), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
//alibaba
loadDirectory(extensionClasses, strategy.directory(), type.getName().replace("org.apache", "com.alibaba"), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
}在loadDirectory方法里,就是定位到接口对应的File文件,获取文件的路径,然后调用loadResource方法对文件进行解析——
private void loadDirectory(Map<String, Class<?>> extensionClasses, String dir, String type,
boolean extensionLoaderClassLoaderFirst, boolean overridden, String... excludedPackages) {
//文件夹路径+type 全限定名:META-INF/dubbo/internal/org.apache.dubbo.test.Animal
String fileName = dir + type;
try {
Enumeration<java.net.URL> urls = null;
ClassLoader classLoader = findClassLoader();
// try to load from ExtensionLoader's ClassLoader first
if (extensionLoaderClassLoaderFirst) {
ClassLoader extensionLoaderClassLoader = ExtensionLoader.class.getClassLoader();
if (ClassLoader.getSystemClassLoader() != extensionLoaderClassLoader) {
urls = extensionLoaderClassLoader.getResources(fileName);
}
}
if (urls == null || !urls.hasMoreElements()) {
if (classLoader != null) {
//根据文件名加载读取所有同名文件
urls = classLoader.getResources(fileName);
} else {
urls = ClassLoader.getSystemResources(fileName);
}
}
if (urls != null) {
while (urls.hasMoreElements()) {
java.net.URL resourceURL = urls.nextElement();
//加载资源进行解析
loadResource(extensionClasses, classLoader, resourceURL, overridden, excludedPackages);
}
}
} catch (Throwable t) {
logger.error("Exception occurred when loading extension class (interface: " +
type + ", description file: " + fileName + ").", t);
}
}loadResource方法主要是读取File文件资源,然后循环遍历文件里的每一行记录,跳过开头为#的注释记录,对cat=org.apache.dubbo.test.Cat形式的行记录进行切割。通过这行代码int i = line.indexOf('=')定位到等于号=的位置,然后以name = line.substring(0, i).trim()来截取等于号前面的字符串作为key, 以 line = line.substring(i + 1).trim()截取等于号=后面的字符串作为value,形成key-value键值对形式数据,进一步传到 loadClass方法进行相应缓存。
private void loadResource(Map<String, Class<?>> extensionClasses, ClassLoader classLoader,
java.net.URL resourceURL, boolean overridden, String... excludedPackages) {
try {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(resourceURL.openStream(), StandardCharsets.UTF_8))) {
String line;
//按行循环读取配置内容
while ((line = reader.readLine()) != null) {
//定位到 # 字符
final int ci = line.indexOf('#');
if (ci >= 0) {
//截取 # 之前的字符串,#之后的内容为注释,需要忽略
line = line.substring(0, ci);
}
line = line.trim();
if (line.length() > 0) {
try {
String name = null;
int i = line.indexOf('=');
if (i > 0) {
//以等于号 = 为界,读取key健 value值
name = line.substring(0, i).trim();
line = line.substring(i + 1).trim();
}
if (line.length() > 0 && !isExcluded(line, excludedPackages)) {
//加载类,通过loadClass对类进行缓存
loadClass(extensionClasses, resourceURL, Class.forName(line, true, classLoader), name, overridden);
}
} catch (Throwable t) {
IllegalStateException e = new IllegalStateException("Failed to load extension class (interface: " + type + ", class line: " + line + ") in " + resourceURL + ", cause: " + t.getMessage(), t);
exceptions.put(line, e);
}
}
}
}
} catch (Throwable t) {
logger.error("Exception occurred when loading extension class (interface: " +
type + ", class file: " + resourceURL + ") in " + resourceURL, t);
}
}以cat=org.apache.dubbo.test.Cat数据为例子,debug可以看到,最后解析得到的为——
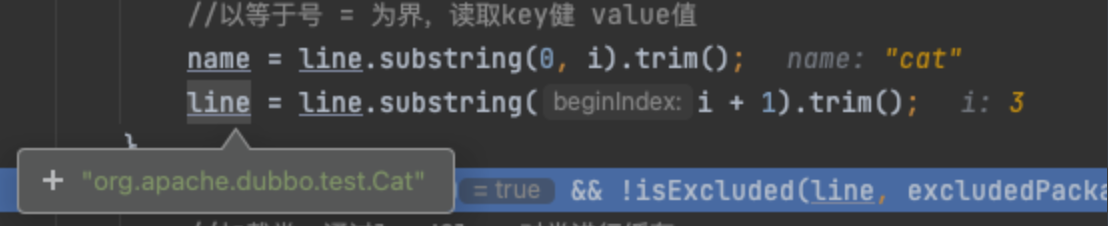
最后,到loadClass看一下是怎么对从文件里解析出来的key-value数据进行缓存,注意一点是,在执行该方法时,已将上文拿到的line="org.apache.dubbo.test.Cat"通过Class.forName(line, true, classLoader)生成了对应的Class。
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name,
boolean overridden) throws NoSuchMethodException {
if (!type.isAssignableFrom(clazz)) {
throw new IllegalStateException("Error occurred when loading extension class (interface: " +
type + ", class line: " + clazz.getName() + "), class "
+ clazz.getName() + " is not subtype of interface.");
}
//检测目标类上是否有Adaptive注解
if (clazz.isAnnotationPresent(Adaptive.class)) {
//设置cachedadaptiveClass缓存
cacheAdaptiveClass(clazz, overridden);
} else if (isWrapperClass(clazz)) {
cacheWrapperClass(clazz);
} else {
//程序进入此分支,表明class是一个普通的拓展类
//检测class是否有默认的构造方法,如果没有,则抛出异常
clazz.getConstructor();
if (StringUtils.isEmpty(name)) {
//如果name为空,则尝试从Extension注解中获取name,或使用小写的类名作为name
name = findAnnotationName(clazz);
if (name.length() == 0) {
throw new IllegalStateException("No such extension name for the class " + clazz.getName() + " in the config " + resourceURL);
}
}
//names = ["cat"]
String[] names = NAME_SEPARATOR.split(name);
if (ArrayUtils.isNotEmpty(names)) {
cacheActivateClass(clazz, names[0]);
for (String n : names) {
//存储Class到名称的映射关系
cacheName(clazz, n);
//存储名称到Class的映射关系
saveInExtensionClass(extensionClasses, clazz, n, overridden);
}
}
}
}这里只需要关注最后的saveInExtensionClass方法,可以看到,最后将从文件里解析出来的“cat”-->org.apache.dubbo.test.Cat存入到Map<String, Class<?>> extensionClasses缓存当中。
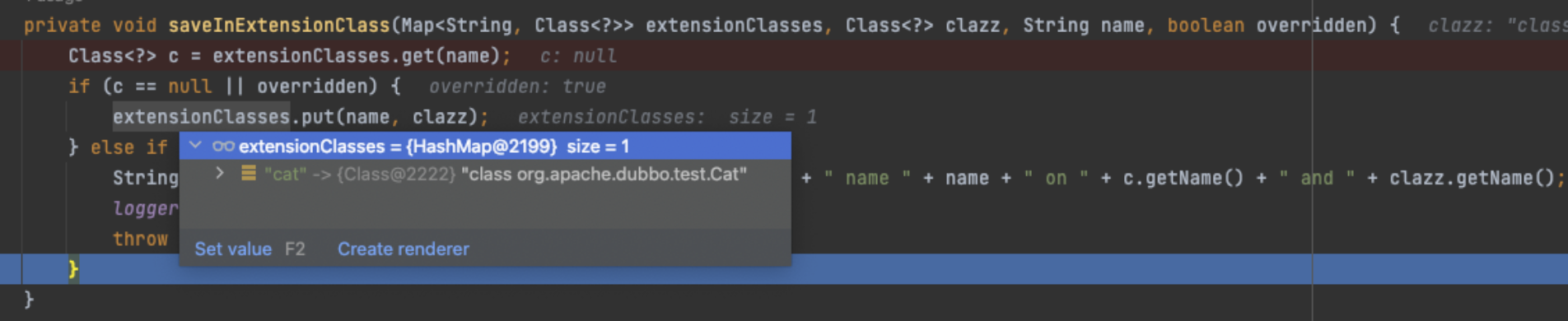
这个Map<String, Class<?>> extensionClasses缓存是在loadExtensionClasses()方法里创建的,该loadExtensionClasses方法最后会将extensionClasses进行返回。
private Map<String, Class<?>> loadExtensionClasses() {
......
//创建用来缓存存储解析文件里key-value数据
Map<String, Class<?>> extensionClasses = new HashMap<>();
for (LoadingStrategy strategy : strategies) {
loadDirectory(extensionClasses, strategy.directory(), type.getName(), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
......
return extensionClasses;
}到这一步,就完成了Animal接口对应的resource/META-INF/dubbo/org.apache.dubbo.test.Animal文件的解析,解析出来的数据存放到了extensionClasses这个Map缓存里。
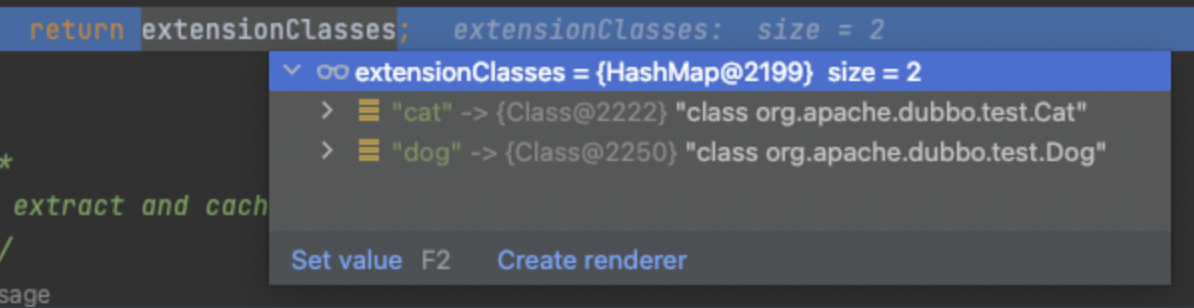
回顾先前的方法调用,可以看到,最终得到extensionClasses的map缓存,会返回到getExtensionClasses()方法,因此,在createExtension调用getExtensionClasses().get(name),就相当于是调用extensionClasses.get(name)。因为传到方法里的参数name="cat",故而返回的Class即org.apache.dubbo.test.Cat。
接着往下执行,到代码EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance())就是通过clazz.newInstance()反射创建了一个暂时还是空属性的对象,同时缓存到EXTENSION_INSTANCES缓存里,这是一个ConcurrentMap<Class<?>, Object>缓存,避免反复进行反射创建对象。
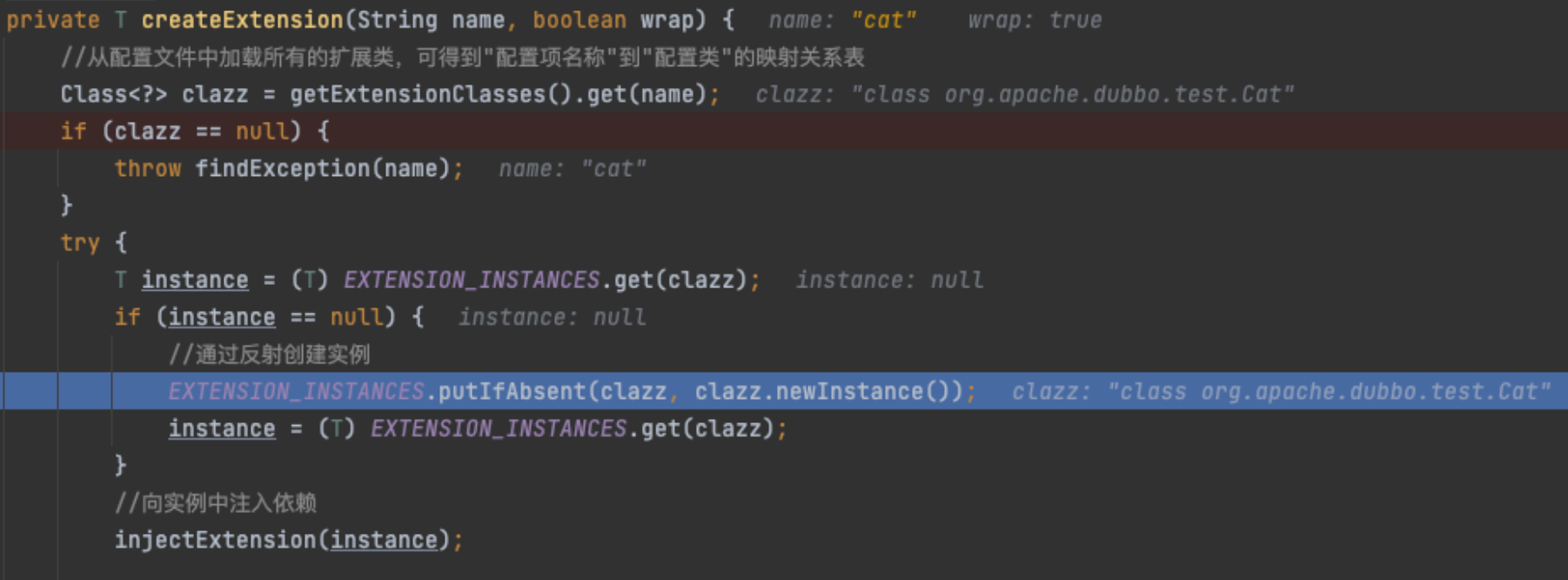
实例化完成org.apache.dubbo.test.Cat对象的创建,接下来就是通过injectExtension(instance)对对象进行依赖注入了。主要功能就类似Spring IOC里bean存在@Resource或者@Autowired注解的属性时,该bean在实例化创建完对象后,需要对属性进行补充,即将@Resource或者@Autowired注解的属性通过反射的方式,指向另外的bean对象。在Dubbo IOC里,同样是类似的实现。首先,会过滤掉那些非setXxx()的方法,只对setXxx()方法处理。这种处理方式,就是截取set后面的字符,例如,存在这样一个setHitInformService (HitInformService hitInformService)方法,那么就会截取set后面的字符,并且对截取后的第一个字符做小写处理,得到“hitInformService”。注意一点是,同时,会获取参数里的类型HitInformService,如果类型为数组、String、Boolean、Character、Number、Date其中一个,则不会对其进行注入操作。反之,就会继续往下执行。
/**
* Dubbo IOC目前仅支持setter方式注入
* @param instance
* @return
*/
private T injectExtension(T instance) {
if (objectFactory == null) {
return instance;
}
try {
//遍历目标类的所有方法
for (Method method : instance.getClass().getMethods()) {
//检测方法是否以set开头,且方法仅有一个参数,且方法访问级别为public
if (!isSetter(method)) {
continue;
}
/**
* Check {@link DisableInject} to see if we need auto injection for this property
*/
if (method.getAnnotation(DisableInject.class) != null) {
continue;
}
//获取setter方法参数类型
Class<?> pt = method.getParameterTypes()[0];
//判断该对象是否为数组、String、Boolean、Character、Number、Date类型,若是,则跳出本次循环,继续下一次循环
if (ReflectUtils.isPrimitives(pt)) {
continue;
}
try {
//获取属性名,比如 setName方法对应属性名name
String property = getSetterProperty(method);
/**
* objectFactory 变量的类型为 AdaptiveExtensionFactory,
* AdaptiveExtensionFactory 内部维护了一个 ExtensionFactory 列表,用于存储其他类型的 ExtensionFactory。
*
* Dubbo 目前提供了两种 ExtensionFactory,分别是 SpiExtensionFactory 和 SpringExtensionFactory。
* 前者用于创建自适应的拓展,后者是用于从 Spring 的 IOC 容器中获取所需的拓展。
*
*/
//从ObjectFactory中获取依赖对象
Object object = objectFactory.getExtension(pt, property);
if (object != null) {
//通过反射调用setter方法依赖
method.invoke(instance, object);
}
} catch (Exception e) {
logger.error("Failed to inject via method " + method.getName()
+ " of interface " + type.getName() + ": " + e.getMessage(), e);
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
return instance;
}执行 Object object = objectFactory.getExtension(pt, property)到行代码,就是去获取HitInformService hitInformService引用对应的对象,这里获取有两种方式,一种是通过SpringExtensionFactory去通过getBean(name)走Spring加载bean的方式获取对象,另一种是通过本文的Dubbo SPI方式,根据name去解析文件里对应的接口实现类Class反射生成返回。
无论是通过哪种方式,最后都需获取返回一个对象,然后通过method.invoke(instance, object)反射去执行对应的setXxx()方法,将对象进行属性注入到前文SPI创建的对象cat里。
到这里,就完成了接口Animal对应cat这个实现类的创建了,这个过程,就是Dubbo SPI的底层实现细节。最后,将得到的org.apache.dubbo.test.Cat对象向上指向其接口Animal引用,通过接口就可以调用该实现类重写的haveBehavior方法了。
Animal cat = ExtensionLoader.getExtensionLoader(Animal.class).getExtension("cat");
cat.haveBehavior();原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。