万变不离其宗|大规模优化必然要决策变量分组

万变不离其宗|大规模优化必然要决策变量分组

演化计算与人工智能
发布于 2023-02-23 11:49:47
发布于 2023-02-23 11:49:47
等核酸结果打入校申请的过程中,网红丁翻了一下TEVC的新文章,非常有趣的看到两篇很近的文章,他们都在做大规模优化的决策变量分组,这么巧的事当然值得快速过一下。
- M. Chen, W. Du, Y. Tang, Y. Jin and G. G. Yen, "A Decomposition Method for Both Additively and Non-additively Separable Problems," in IEEE Transactions on Evolutionary Computation, 2022, doi: 10.1109/TEVC.2022.3218375.
- M. M. Komarnicki, M. W. Przewozniczek, H. Kwasnicka and K. Walkowiak, "Incremental Recursive Ranking Grouping for Large Scale Global Optimization," in IEEE Transactions on Evolutionary Computation, 2022, doi: 10.1109/TEVC.2022.3216968.
进化优化的一个大瓶颈呢其实是黑箱问题的大规模决策变量,也就是说搜索空间大了,在没有任何导数信息的情况下搜索变得异常艰难。同行们常见的方法就是决策变量分组了啦,也就是grouping,这是一个非常朴素的想法,大问题我求解不了我就分解成小问题分来求解(参见“分而治之”这种算法设计技术),但一个非常要命的问题就是怎么分不影响原来大问题的搜索。如果决策变量分成若干组,每组的子函数搜索不影响其他组子函数,不就好了么,这当然是基于决策变量组是可分的才可以,但是找到这些可分的变量组往往需要额外的函数评价,有些时候可能还有点得不偿失,所以很多人直接用随机分组(高维特征选择其实是一个昂贵0-1优化问题)。
这两篇文章呢,做的事情是一个,就是到底怎么能把可分的决策变量组给分对了。
第一篇文章里面定义了加型可分、乘性可分、复合可分、强可分、弱可分变量,关系图如下。
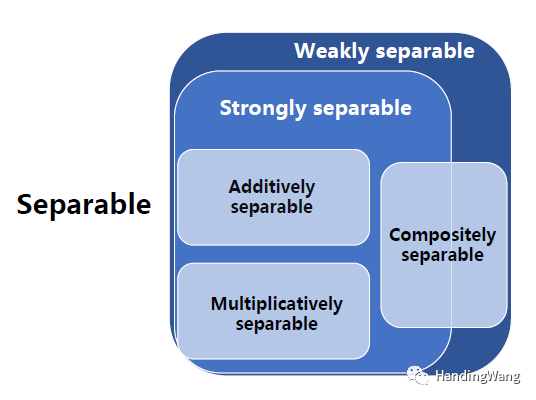
然后有两个重要的定理来做分组,这里是网红丁不严谨的理解,如果一组变量的全局/局部最小点会受另一组变量的影响而变化,那么这两组变量中存在应该划分在一组的不可分变量,如下图。
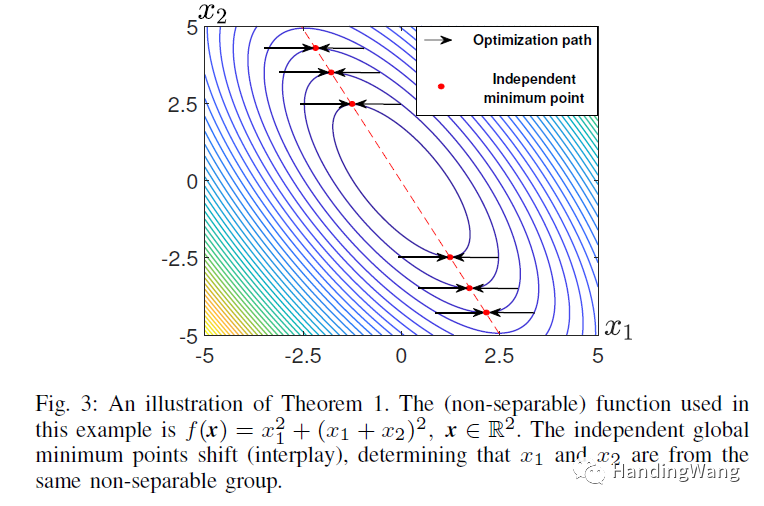
所以这篇文章中的算法呢就是先对每个变量找一个最小点,然后对其他变量抖动,看最小点是否变化,那么就说明两个变量是不可分的,进而不断迭代进行变量合并。
第二篇文章其实还是基于Differential Grouping(DG)思想的,其中FVIL方法就是下面两个公式来检验两组决策变量是否相互影响。
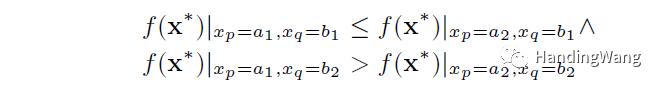
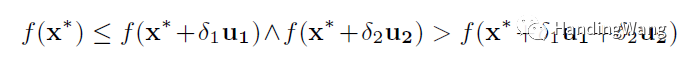
但是由于问题的复杂性,会误判,文中也给出了例子,这篇文章的方法呢,其实是增加了ns采样点,然后看ranking的变化来判断的,当然算法里面也是一个迭代的过程。
讲真这两篇文章是比较干的,好在作者放了代码出来,还是得下了大的再研究研究。想要看原文的同学移步TEVC上去看吧,今天文末“阅读原文”不埋连接了。
- https://github.com/MinyangChen/Code-of-GSG
- https://github.com/kommar/IRRG
最后,欢迎转载,欢迎留言,欢迎扔砖,欢迎吐槽,欢迎提问,还有欢迎关注。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-11-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号