操作系统大赛:基于 eBPF 的容器监控工具 Eunomia 初赛报告(容器信息收集、安全规则与 seccomp)

操作系统大赛:基于 eBPF 的容器监控工具 Eunomia 初赛报告(容器信息收集、安全规则与 seccomp)

云微
发布于 2023-02-24 19:57:17
发布于 2023-02-24 19:57:17
项目仓库:https://github.com/yunwei37/Eunomia
4.5. 容器追踪模块设计
4.5.1. 容器信息数据结构
目前我们的容器追踪模块是基于进程追踪模块实现的,其数据结构为:
struct container_event {
struct process_event process;
unsigned long container_id;
char container_name[50];
};容器追踪模块由container_tracker实现
struct container_tracker : public tracker_with_config<container_env, container_event>
{
struct container_env current_env = { 0 };
struct container_manager &this_manager;
std::shared_ptr<spdlog::logger> container_logger;
container_tracker(container_env env, container_manager &manager);
void start_tracker();
void fill_event(struct process_event &event);
void init_container_table();
void print_container(const struct container_event &e);
void judge_container(const struct process_event &e);
static int handle_event(void *ctx, void *data, size_t data_sz);
};同时我们添加了一个manager类来控制tracker。
struct container_manager
{
private:
struct tracker_manager tracker;
std::mutex mp_lock;
std::unordered_map<int, struct container_event> container_processes;
friend struct container_tracker;
public:
void start_container_tracing(std::string log_path)
{
tracker.start_tracker(std::make_unique<container_tracker>(container_env{
.log_path = log_path,
.print_result = true,
}, *this));
}
unsigned long get_container_id_via_pid(pid_t pid);
};4.5.2. 容器追踪实现
容器追踪模块的ebpf代码服用了process追踪模块的ebpf代码,因此这里我们只介绍用户态下对数据处理的设计。
当内核态捕捉到进程的数据返回到用户态时,我们调用judge_container()函数,判断该进程是否归属于一个container,其具体实现为:
void container_tracker::judge_container(const struct process_event &e)
{
if (e.exit_event)
{
this_manager.mp_lock.lock();
auto event = this_manager.container_processes.find(e.common.pid);
// remove from map
if (event != this_manager.container_processes.end())
{
event->second.process.exit_event = true;
print_container(event->second);
this_manager.container_processes.erase(event);
}
this_manager.mp_lock.unlock();
}
else
{
/* parent process exists in map */
this_manager.mp_lock.lock();
auto event = this_manager.container_processes.find(e.common.ppid);
this_manager.mp_lock.unlock();
if (event != this_manager.container_processes.end())
{
struct container_event con = { .process = e, .container_id = (*event).second.container_id };
strcpy(con.container_name, (*event).second.container_name);
this_manager.mp_lock.lock();
this_manager.container_processes[e.common.pid] = con;
print_container(this_manager.container_processes[e.common.pid]);
this_manager.mp_lock.unlock();
}
else
{
/* parent process doesn't exist in map */
struct process_event p_event = { 0 };
p_event.common.pid = e.common.ppid;
fill_event(p_event);
if ((p_event.common.user_namespace_id != e.common.user_namespace_id) ||
(p_event.common.pid_namespace_id != e.common.pid_namespace_id) ||
(p_event.common.mount_namespace_id != e.common.mount_namespace_id))
{
std::unique_ptr<FILE, int (*)(FILE *)> fp(popen("docker ps -q", "r"), pclose);
unsigned long cid;
/* show all alive container */
pid_t pid, ppid;
while (fscanf(fp.get(), "%lx\n", &cid) == 1)
{
std::string top_cmd = "docker top ", name_cmd = "docker inspect -f '{{.Name}}' ";
char hex_cid[20], container_name[50];
sprintf(hex_cid, "%lx", cid);
top_cmd += hex_cid;
name_cmd += hex_cid;
std::unique_ptr<FILE, int (*)(FILE *)> top(popen(top_cmd.c_str(), "r"), pclose),
name(popen(name_cmd.c_str(), "r"), pclose);
fscanf(name.get(), "/%s", container_name);
char useless[150];
/* delet the first row */
fgets(useless, 150, top.get());
while (fscanf(top.get(), "%*s %d %d %*[^\n]\n", &pid, &ppid) == 2)
{
this_manager.mp_lock.lock();
/* this is the first show time for this process */
if (this_manager.container_processes.find(pid) == this_manager.container_processes.end())
{
struct container_event con = {
.process = e,
.container_id = cid,
};
strcpy(con.container_name, container_name);
this_manager.container_processes[pid] = con;
print_container(this_manager.container_processes[pid]);
}
this_manager.mp_lock.unlock();
}
}
}
}
}
}首先,如果进程处于退出状态,那么该函数会直接判断其数据是否已经存在于container_processes这一哈希map中。该哈希map专门用于存储归属于容器的进程的信息。如果已经存在这直接输出并删除,否则跳过。如果进程处于执行状态,我们首先会检查该进程的父进程是否存在于container_processes中,如果存在则认为此进程也是容器中的进程,将此进程直接加入并输出即可。如果不存在则检查其namespace信息和其父进程是否一致,如果不一致我们会认为此时可能会有一个新的容器产生。对于Docker类容器,我们会直接调用Docker给出的命令的进行观测。首先调用docker ps -q命令获得现有在运行的所有容器id,之后调用docker top id命令获取容器中的进程在宿主机上的进程信息,如果这些信息没有被记录到哈希map中,那么就将他们添加到其中并输出。
由于这一方式无法捕捉到在本追踪器启动前就已经在运行的容器进程,因此我们会在程序启动伊始,调用一次init_container_table()函数,其实现为:
void container_tracker::init_container_table()
{
unsigned long cid;
pid_t pid, ppid;
std::string ps_cmd("docker ps -q");
std::unique_ptr<FILE, int (*)(FILE *)> ps(popen(ps_cmd.c_str(), "r"), pclose);
while (fscanf(ps.get(), "%lx\n", &cid) == 1)
{
std::string top_cmd("docker top "), name_cmd("docker inspect -f '{{.Name}}' ");
char hex_cid[20], container_name[50];
sprintf(hex_cid, "%lx", cid);
top_cmd += hex_cid;
name_cmd += hex_cid;
std::unique_ptr<FILE, int (*)(FILE *)> top(popen(top_cmd.c_str(), "r"), pclose),
name(popen(name_cmd.c_str(), "r"), pclose);
fscanf(name.get(), "/%s", container_name);
/* delet the first row */
char useless[150];
fgets(useless, 150, top.get());
while (fscanf(top.get(), "%*s %d %d %*[^\n]\n", &pid, &ppid) == 2)
{
struct process_event event;
event.common.pid = pid;
event.common.ppid = ppid;
fill_event(event);
struct container_event con = {
.process = event,
.container_id = cid,
};
strcpy(con.container_name, container_name);
print_container(con);
this_manager.mp_lock.lock();
this_manager.container_processes[pid] = con;
this_manager.mp_lock.unlock();
}
}
}该函数的实现逻辑与judge_contaienr()函数类似,但是它会将已经在运行的容器进程存入哈希map中,以方便后续追踪。
4.6. 安全规则设计
目前安全告警部分还未完善,只有一个框架和 demo,我们需要对更多的安全相关规则,以及常见的容器安全风险情境进行调研和完善,然后再添加更多的安全分析。
安全分析和告警
目前我们的安全风险等级主要分为三类(未来可能变化,我觉得这个名字不一定很直观):
include\eunomia\sec_analyzer.h
enum class sec_rule_level
{
event,
warnning,
alert,
// TODO: add more levels?
};安全规则和上报主要由 sec_analyzer 模块负责:
struct sec_analyzer
{
// EVNETODO: use the mutex
std::mutex mutex;
const std::vector<sec_rule_describe> rules;
sec_analyzer(const std::vector<sec_rule_describe> &in_rules) : rules(in_rules)
{
}
virtual ~sec_analyzer() = default;
virtual void report_event(const rule_message &msg);
void print_event(const rule_message &msg);
static std::shared_ptr<sec_analyzer> create_sec_analyzer_with_default_rules(void);
static std::shared_ptr<sec_analyzer> create_sec_analyzer_with_additional_rules(const std::vector<sec_rule_describe> &rules);
};
struct sec_analyzer_prometheus : sec_analyzer
{
prometheus::Family<prometheus::Counter> &eunomia_sec_warn_counter;
prometheus::Family<prometheus::Counter> &eunomia_sec_event_counter;
prometheus::Family<prometheus::Counter> &eunomia_sec_alert_counter;
void report_prometheus_event(const struct rule_message &msg);
void report_event(const rule_message &msg);
sec_analyzer_prometheus(prometheus_server &server, const std::vector<sec_rule_describe> &rules);
static std::shared_ptr<sec_analyzer> create_sec_analyzer_with_default_rules(prometheus_server &server);
static std::shared_ptr<sec_analyzer> create_sec_analyzer_with_additional_rules(const std::vector<sec_rule_describe> &rules, prometheus_server &server);
};我们通过 sec_analyzer 类来保存所有安全规则以供查询,同时以它的子类 sec_analyzer_prometheus 完成安全事件的上报和告警。具体的告警信息发送,可以由 prometheus 的相关插件完成,我们只需要提供一个接口。由于 rules 是不可变的,因此它在多线程读条件下是线程安全的。
安全规则实现
我们的安全风险分析和安全告警规则基于对应的handler 实现,例如:
include\eunomia\sec_analyzer.h
// base class for securiy rules
template<typename EVNET>
struct rule_base : event_handler<EVNET>
{
std::shared_ptr<sec_analyzer> analyzer;
rule_base(std::shared_ptr<sec_analyzer> analyzer_ptr) : analyzer(analyzer_ptr) {}
virtual ~rule_base() = default;
// return rule id if matched
// return -1 if not matched
virtual int check_rule(const tracker_event<EVNET> &e, rule_message &msg) = 0;
void handle(tracker_event<EVNET> &e)
{
if (!analyzer)
{
std::cout << "analyzer is null" << std::endl;
}
struct rule_message msg;
int res = check_rule(e, msg);
if (res != -1)
{
analyzer->report_event(msg);
}
}
};这个部分定义了一个简单的规则基类,它对应于某一个 ebpf 探针上报的事件进行过滤分析,以系统调用上报的事件为例:
// syscall rule:
//
// for example, a process is using a dangerous syscall
struct syscall_rule_checker : rule_base<syscall_event>
{
syscall_rule_checker(std::shared_ptr<sec_analyzer> analyzer_ptr) : rule_base(analyzer_ptr)
{}
int check_rule(const tracker_event<syscall_event> &e, rule_message &msg);
};其中的 check_rule 函数实现了对事件进行过滤分析,如果事件匹配了规则,则返回规则的 id,否则返回 -1:关于 check_rule 的具体实现,请参考:src\sec_analyzer.cpp
除了通过单一的 ebpf 探针上报的事件进行分析之外,通过我们的 handler 机制,我们还可以综合多种探针的事件进行分析,或者通过时序数据库中的查询进行分析,来发现潜在的安全风险事件。
其他
除了通过规则来实现安全风险感知,我们还打算通过机器学习等方式进行进一步的安全风险分析和发现。
4.7. seccomp: syscall准入机制
Seccomp(全称:secure computing mode)在2.6.12版本(2005年3月8日)中引入linux内核,将进程可用的系统调用限制为四种:read,write,_exit,sigreturn。最初的这种模式是白名单方式,在这种安全模式下,除了已打开的文件描述符和允许的四种系统调用,如果尝试其他系统调用,内核就会使用SIGKILL或SIGSYS终止该进程。Seccomp来源于Cpushare项目,Cpushare提出了一种出租空闲linux系统空闲CPU算力的想法,为了确保主机系统安全出租,引入seccomp补丁,但是由于限制太过于严格,当时被人们难以接受。
尽管seccomp保证了主机的安全,但由于限制太强实际作用并不大。在实际应用中需要更加精细的限制,为了解决此问题,引入了Seccomp – Berkley Packet Filter(Seccomp-BPF)。Seccomp-BPF是Seccomp和BPF规则的结合,它允许用户使用可配置的策略过滤系统调用,该策略使用Berkeley Packet Filter规则实现,它可以对任意系统调用及其参数(仅常数,无指针取消引用)进行过滤。Seccomp-BPF在3.5版(2012年7月21日)的Linux内核中(用于x86 / x86_64系统)和Linux内核3.10版(2013年6月30日)被引入Linux内核。
seccomp在过滤系统调用(调用号和参数)的时候,借助了BPF定义的过滤规则,以及处于内核的用BPF language写的mini-program。Seccomp-BPF在原来的基础上增加了过滤规则,大致流程如下:
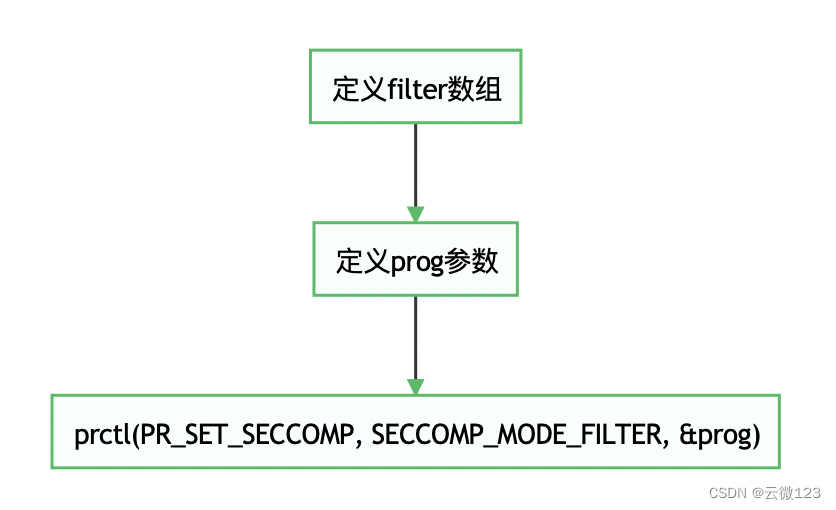
项目仓库:https://github.com/yunwei37/Eunomia
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2022-07-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号