深入Android Runtime:并发复制GC

深入Android Runtime:并发复制GC

天天P图攻城狮
发布于 2023-02-27 11:40:31
发布于 2023-02-27 11:40:31
对很多人来说,GC的概念都停留在分代回收的时候。Android从最初的版本开始,就逐渐引入了多种GC,并不断优化,最终在Android 8.0的时候,切换到了并发复制GC(Concurrent Copying GC)。
并发复制到底是怎么样的一种GC,我们结合Android 8.1的源码讨论一下。
首先我们从Java的对象说起。
对象
Java的类型
根据《The Java™ Language Specification》中Chapter 4介绍:
The primitive types (§4.2) are the boolean type and the numeric types. The numeric types are the integral types byte, short, int, long, and char, and the floating-point types float and double. The reference types (§4.3) are class types, interface types, and array types. There is also a special null type.
我们可以知道,java中包含2种类型和:
- 值类型(primitive types):int、float、long…
- 引用类型(reference types):array、interface、Class
而object则是通过class动态创建的实例:
An object (§4.3.1) is a dynamically created instance of a class type or a dynamically created array.
那么java中作为数据载体的object在内存中到底是什么样的存在呢?
Java对象的本质
Java中的object存储在Heap(堆)上,堆实际上是多块特定的内存区域。
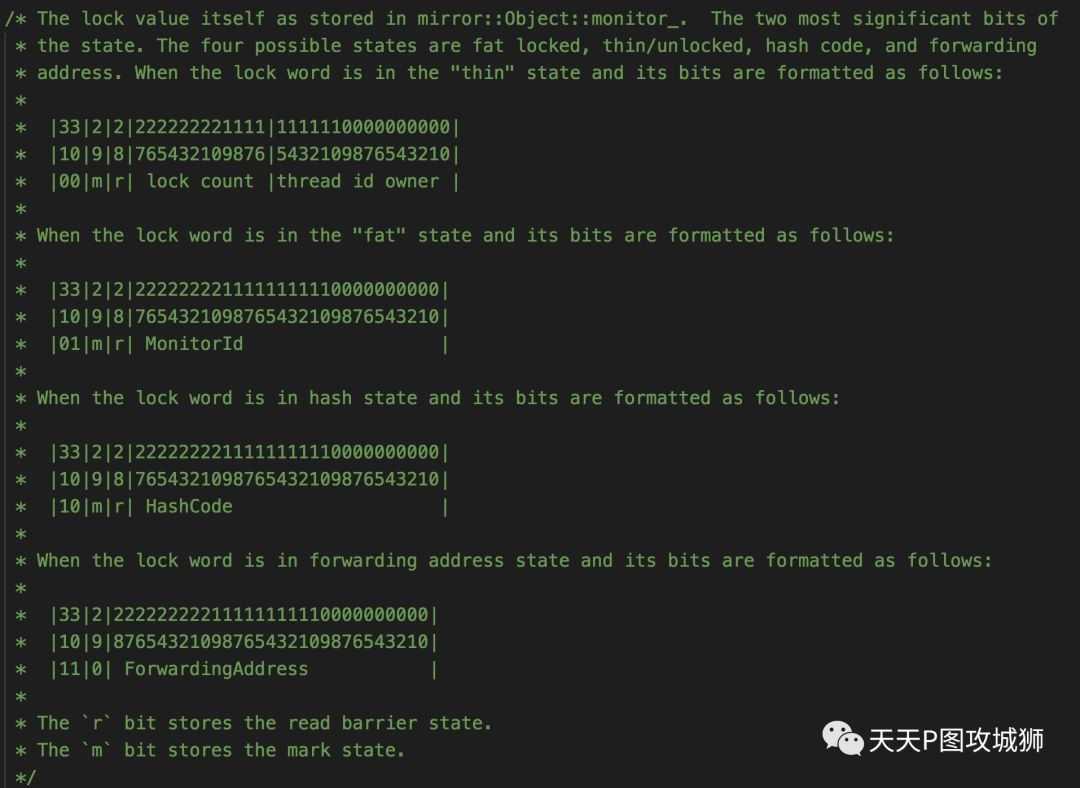
通常Java object包含对象头+实例数据+(对齐填充)。对象头包括:类型信息(type word)+同步字(sync word)。
在Android ART中对object的数据结构定义代码片段如下:
// The Class representing the type of the object.
HeapReference<Class> klass_;
// Monitor and hash code information.
uint32_t monitor_;可以看出类型信息是对Heap上Class的引用(HeapReference)。而同步字使用uint32_t monitor_进行描述,也叫做LockWord,包含锁信息、Hash Code等。
按照Android中对LockWord的注释,LockWord的值存在monitor_中,使用了最重要的2个bit进行描述,可以表示4种状态。LockWord的4种状态为:fat locked, thin/unlocked, hash code, 以及 forwarding address。也就是说,LockWord根据不同的场景被复用为不同的容器,比如用来存储锁信息、HashCode以及GC时的转发地址等。
我们可以通过gdb查看到obj的真实内存:

除了对象头,其他部分在内存中的存储方式入下图所示:
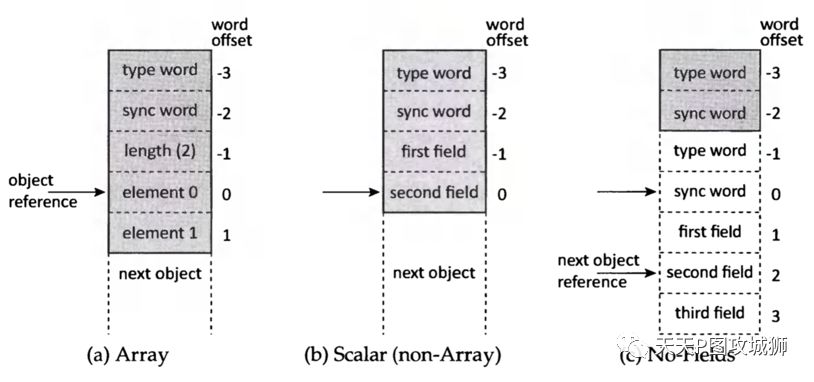
如果对象是一个数组,存储方式为对象头+数组长度+对象元素引用。因为数组也是引用类型,其内部的元素,都是具体对象的引用,具体代码如下:
class MANAGED Array : public Object {
...
// The number of array elements.
int32_t length_;
// Marker for the data (used by generated code)
uint32_t first_element_[0];
...
};其中first_element_指向数组元素起始地址,由于长度为0,实际并不占用内存空间,但是可以使得array成为变长的数据结构。数组的存储方式,也可以通过对数组元素地址计算的代码知道:
void** ElementAddress(size_t index, PointerSize ptr_size) REQUIRES_SHARED(Locks::mutator_lock_) {
DCHECK_LT(index, static_cast<size_t>(GetLength()));
return reinterpret_cast<void**>(reinterpret_cast<uint8_t*>(this) +
Array::DataOffset(static_cast<size_t>(ptr_size)).Uint32Value() +
static_cast<size_t>(ptr_size) * index);
}对于非数组的对象,存储结构为对象头+Field+Field…。也就是说,内部的field都是在对象头之后排布。field可以是值类型,也可以是引用类型,如果是值类型,直接存储数值,如果是引用类型,则存储地址。
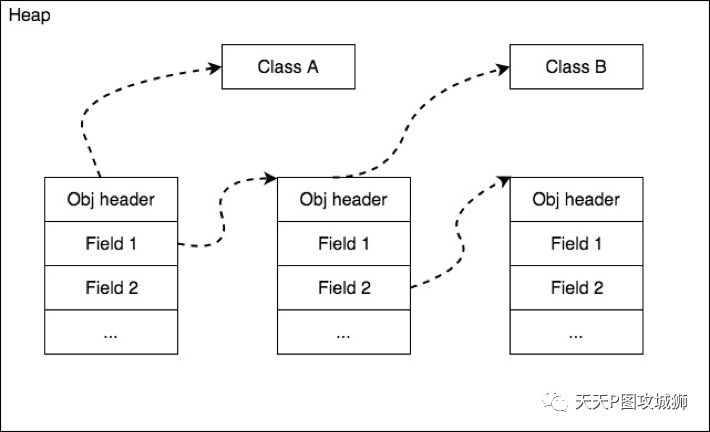
我们知道了对象内部的存储结构,那么对象之间是如果存储的?实际上,对象在内存中紧挨着排布,进行字节对齐,这样可以增加空间局部性,尽可能减少缺页造成的性能影响。对象之间通过引用保持关系,基本结构如下:

另外,我们知道,Class也是一种特殊的对象。在ART中,Class也是继承自Object的。
堆Heap
Java中,对象存储在堆(Heap)上,堆实际上不只是一块连续的虚拟内存,而是会根据不同的需要进行不同功能的划分,比如按照对象大小,分为小对象空间和大对象空间(Large object spaces),以及根据对象的可移动性分为移动空间(Moving space)和不可移动空间(Non-moving space)。
堆在虚拟机创建的时候被创建,创建Heap的调用栈如下:
#0 art::gc::Heap::Heap at art/runtime/gc/heap.cc:299
#1 art::Runtime::Init(art::RuntimeArgumentMap&&) at art/runtime/runtime.cc:1162
#2 art::Runtime::Create(art::RuntimeArgumentMap&&) at art/runtime/runtime.cc:617
#3 art::Runtime::Create at art/runtime/runtime.cc:630
#4 JNI_CreateJavaVM at art/runtime/java_vm_ext.cc:1047
#5 art::dalvikvm at art/dalvikvm/dalvikvm.cc:177
#6 main at art/dalvikvm/dalvikvm.cc:212在Android O中,ART运行所需的内存空间被划分为不同的区域,除了堆内存,还有包括Reference Table、GC Mark Stack之内的运行时所需的内存区域。其中堆内存布局如下:
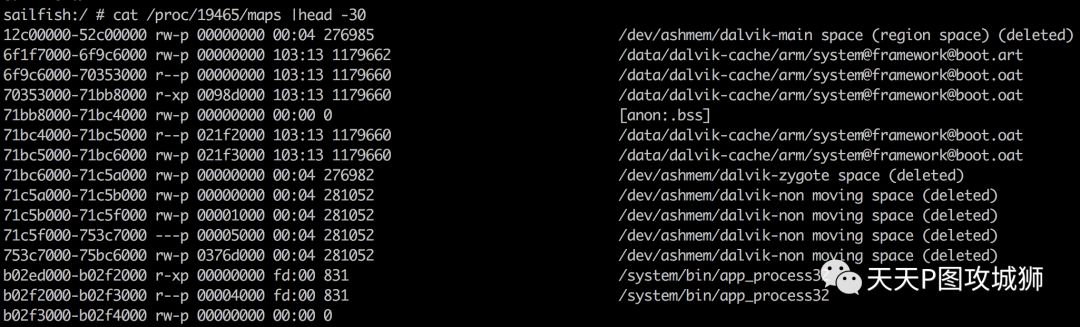
首先是从300M(0x12c00000)开始的2个512M的main space(因为内部使用region space方式进行内存分配,因此也叫做region space),用来作为并发复制GC的from space和to space,之后是boot.art,也就是启动类相关的内存镜像文件,内部存储了预加载的class,可以直接使用,这些class在framework/base/preloaded-classes中定义。之后就是zygote space和non moving space,其中zygote space是zygote启动时创建,其他app通过fork继承这块内存,zygote space也属于non moving space。non moving space主要用于存储加载之后不变的class对象。
堆的布局大致如此。前面提到会创建2个512M的main space,这个512M是Xmx指定的大小,也就是属性dalvik.vm.heapsize设置的大小,属于堆的最大物理内存容量,如果APP实际使用的物理内存超过heapsize,就会出现OOM(当然,如果没有设置APP为largeheap模式,达到dalvik.vm.heapgrowthlimit就会出现OOM)。除了Xmx,还有其他几个堆的参数,比如初始堆大小dalvik.vm.heapstartsize,即虚拟机创建时的初始物理内存大小。另外还有堆的目标利用率0.75,每次做完GC之后,都会根据堆的利用率等参数进行堆的大小的调整,使得空闲内存保持在一个合理的水平。如果这个空闲的内存被用完,就会触发下一次GC,因此这个过程有可能出现频繁GC的现象。

更详细的堆增长算法,可以参考art/runtime/gc/heap.cc的代码。
对象存活性判断
讲完了对象和堆。那么在并发复制GC中对象是如何判断是否存活的呢?实际上,我们知道,尽管引用计数可以即使时地、渐进地回收内存,但是无法对环形垃圾进行存活性判断,现代GC大都使用标记+可达性分析的方式进行存活性判断。也就是说,一个对象从GC root开始,如果不可达的话,就认为已经死亡,可以被标记为需要回收的对象。
根据这里描述,可以做为GC root的对象一般有:
- Class - class loaded by system class loader. Such classes can never be unloaded. They can hold objects via static fields. Please note that classes loaded by custom class loaders are not roots, unless corresponding instances of
java.lang.Classhappen to be roots of other kind(s). - Thread - live thread
- Stack Local - local variable or parameter of Java method
- JNI Local - local variable or parameter of JNI method
- JNI Global - global JNI reference
- Monitor Used - objects used as a monitor for synchronization
- Held by JVM - objects held from garbage collection by JVM for its purposes. Actually the list of such objects depends on JVM implementation. Possible known cases are: the system class loader, a few important exception classes which the JVM knows about, a few pre-allocated objects for exception handling, and custom class loaders when they are in the process of loading classes. Unfortunately, JVM provides absolutely no additional detail for such objects. Thus it is up to the analyst to decide to which case a certain "Held by JVM" belongs.
当然,对于ART来说,根据art/runtime/gc_root.h的描述,可以知道,有以下几种GC root:
enum RootType {
kRootUnknown = 0,
kRootJNIGlobal,
kRootJNILocal,
kRootJavaFrame,
kRootNativeStack,
kRootStickyClass,
kRootThreadBlock,
kRootMonitorUsed,
kRootThreadObject,
kRootInternedString,
kRootFinalizing, // used for HPROF's conversion to HprofHeapTag
kRootDebugger,
kRootReferenceCleanup, // used for HPROF's conversion to HprofHeapTag
kRootVMInternal,
kRootJNIMonitor,
};在真正标记的时候,会从这些GC roots开始,以类似深度优先的方式对对象及其引用的对象进行遍历,能被访问到的对象,则标记为存活。这样,剩下的未标记的对象,可以回收掉。
标记的过程,实际上使用了一种叫做标记栈(Mark Stack)的数据结构,每次标记器visitor访问了一个对象并对其进行标记之后,就将这个对象的子节点(也就是field object)push到标记栈中,表示这些对象存活但是还未进行标记。通过标记栈实现显示地递归,从而可以提升对象遍历的性能以及防止系统栈溢出。并发复制GC中的ConcurrentCopying::PushOntoMarkStack函数就是用来进行压栈的。
由于遍历对象的复杂性,一般对对象的标记过程进行三色抽象(the tricolour abstraction)[2]。也就是,在访问对象的过程中,对象可以处于三种不同的状态:未标记、自身已标记但是Filed还未标记完、自身及Field节点都已经标记完。在遍历的过程中,对象都处于白色,如果扫描到某个对象的时,将这个对象标记为灰色,如果已经处理完该对象及其子节点,那么就会被标记为黑色。这样,遍历时就会看到可达的对象会从白色过渡到灰色,然后最终变成黑色。我们需要注意2个事实,1是对象不会从黑色变成白色,2是任何可达的白色对象都必须是从灰色对象可达的。如果这2个事实中有一个不成立,那么整个GC就会出现错误,也就是说,对象会被错误地标记和回收。
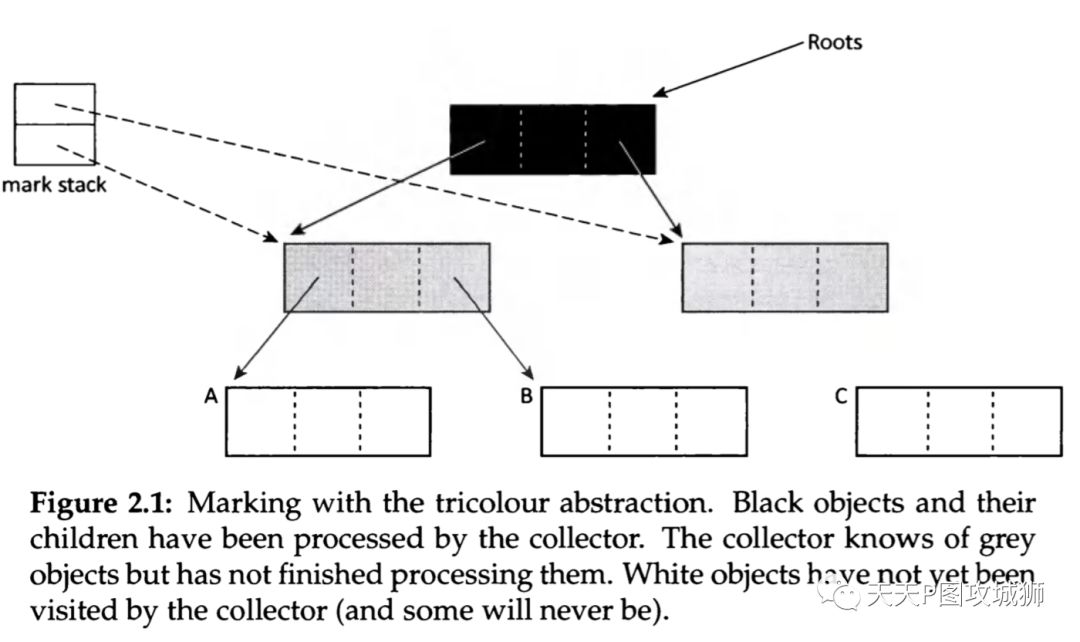
并发复制GC
Concurrent Copying
Android 8.0以后引入了并发复制GC,简单地说,就是通过分配2个space,用来将已被标记的对象全部拷贝到另外一个space,这个space就作为下一次进行内存分配的空间,然后循环往复,两个space不断交换。
Google在Google IO 2017上声称引入该GC之后,性能大幅提升,以下是暂停时间的对比结果:
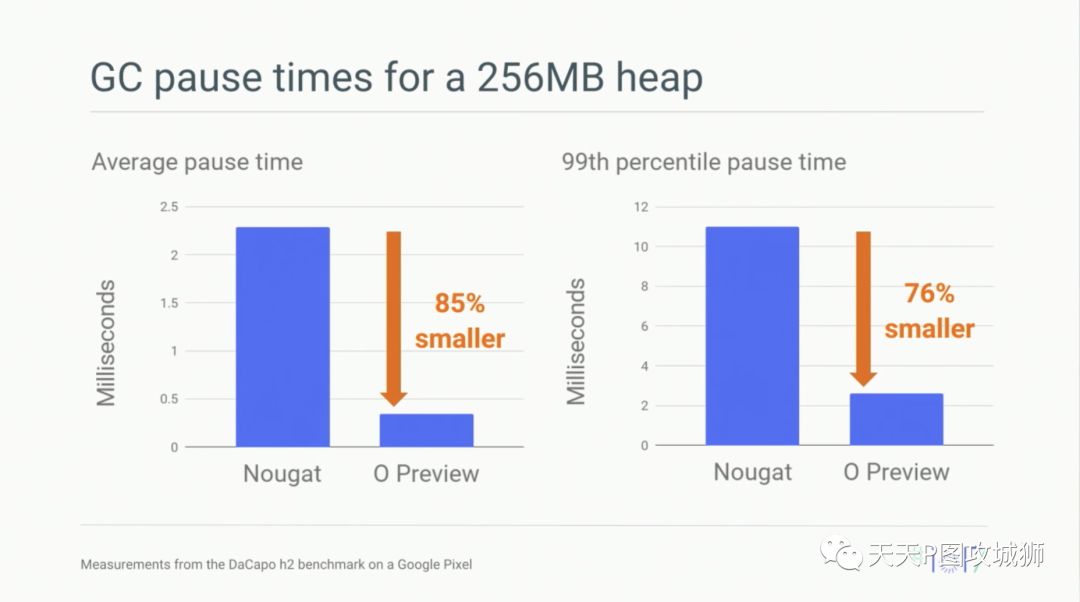
以及对象分配时间的大幅减少:

根据本文前面对堆布局的介绍,从300M开始,有2个512M的main space(region space),这两个space就是from space和to space,ART中art/runtime/gc/space/region_space.h定义了这个space的数据结构。
实际上,这2个space的内存分配算法,是基于region的。region是一个更小的内存单元。每个region是256K大小的单元,而且分为不同的类型:
// The region size.
static constexpr size_t kRegionSize = 256 * KB;
...
enum class RegionType : uint8_t {
kRegionTypeAll, // All types.
kRegionTypeFromSpace, // From-space. To be evacuated.
kRegionTypeUnevacFromSpace, // Unevacuated from-space. Not to be evacuated.
kRegionTypeToSpace, // To-space.
kRegionTypeNone, // None.
};如果我们要在region space中分配一个对象,那么会先根据需要分配的字节数进行8字节对齐,如果是一个小于256k的小对象,就会分配一个region来存储,否则需要在region space中找到一块连续的内存,这块内存能分成多个连续region用来存储这个大的对象(比如一个元素很多的数组)。当然,这里的大的对象不是真正的large object,真正的large object存储在large object space中,一般采用FreeList/Map方式管理。当然,region space的内存分配算法细节很多,这里就不再赘述。
并发复制的过程
根据Google IO 2017上的介绍,并发复制GC可以分为以下几个阶段:
- 暂停阶段
- 复制阶段
- 回收阶段
实际上代码实现上,并不是严格按照这三个阶段进行清晰的划分。并发复制GC的整个GC过程,并不是都需要stop the world,只是在MarkingPhase的特定的操作时才需要暂停。而复制对象的操作也是在MarkingPhase就完成了。
并发复制的代码art/runtime/gc/collector/concurrent_copying.cc代码中有完成的GC执行流程:
void ConcurrentCopying::RunPhases() {
CHECK(kUseBakerReadBarrier || kUseTableLookupReadBarrier);
CHECK(!is_active_);
is_active_ = true;
Thread* self = Thread::Current();
thread_running_gc_ = self;
Locks::mutator_lock_->AssertNotHeld(self);
{
ReaderMutexLock mu(self, *Locks::mutator_lock_);
InitializePhase();
}
if (kUseBakerReadBarrier && kGrayDirtyImmuneObjects) {
// Switch to read barrier mark entrypoints before we gray the objects. This is required in case
// a mutator sees a gray bit and dispatches on the entrypoint. (b/37876887).
ActivateReadBarrierEntrypoints();
// Gray dirty immune objects concurrently to reduce GC pause times. We re-process gray cards in
// the pause.
ReaderMutexLock mu(self, *Locks::mutator_lock_);
GrayAllDirtyImmuneObjects();
}
FlipThreadRoots();
{
ReaderMutexLock mu(self, *Locks::mutator_lock_);
MarkingPhase();
}
// Verify no from space refs. This causes a pause.
if (kEnableNoFromSpaceRefsVerification) {
TimingLogger::ScopedTiming split("(Paused)VerifyNoFromSpaceReferences", GetTimings());
ScopedPause pause(this, false);
CheckEmptyMarkStack();
if (kVerboseMode) {
LOG(INFO) << "Verifying no from-space refs";
}
VerifyNoFromSpaceReferences();
if (kVerboseMode) {
LOG(INFO) << "Done verifying no from-space refs";
}
CheckEmptyMarkStack();
}
{
ReaderMutexLock mu(self, *Locks::mutator_lock_);
ReclaimPhase();
}
FinishPhase();
CHECK(is_active_);
is_active_ = false;
thread_running_gc_ = nullptr;
}Google IO 2017中介绍的暂停阶段对应的图如下:
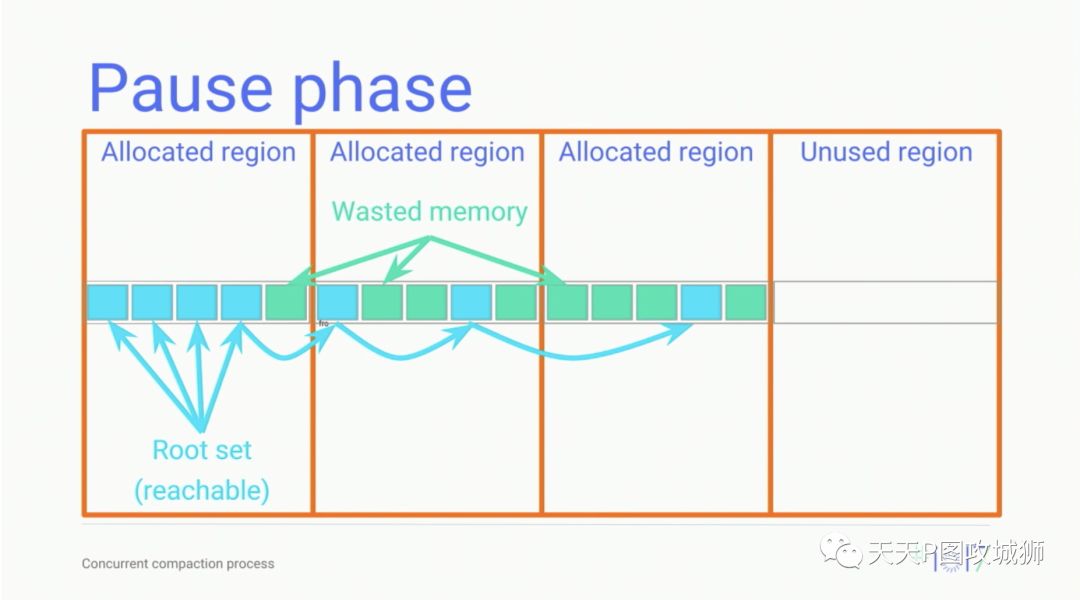
暂停用户线程(mutator线程)是通过mutator_lock_来实现的。mutator_lock_是一把读写锁,主要用于GC线程(collector线程)与mutator线程之间的同步。因为是读写锁,读操作是共享的,写操作是独占的。如果GC线程需要挂起其他mutator线程,就会将所有mutator线程的suspend_count加一,当mutator线程运行到GC check point(比如jni函数执行结束)的时候,就会检查这个标志,如果是一就会使用futex将自己挂起(线程状态为kSuspended)。直到所有需要挂起的线程pass了挂起的barrier,GC线程就知道,所有mutator线程都已经挂起了。GC线程与mutator线程之间的关系可以通过以下代码注释描述来了解:
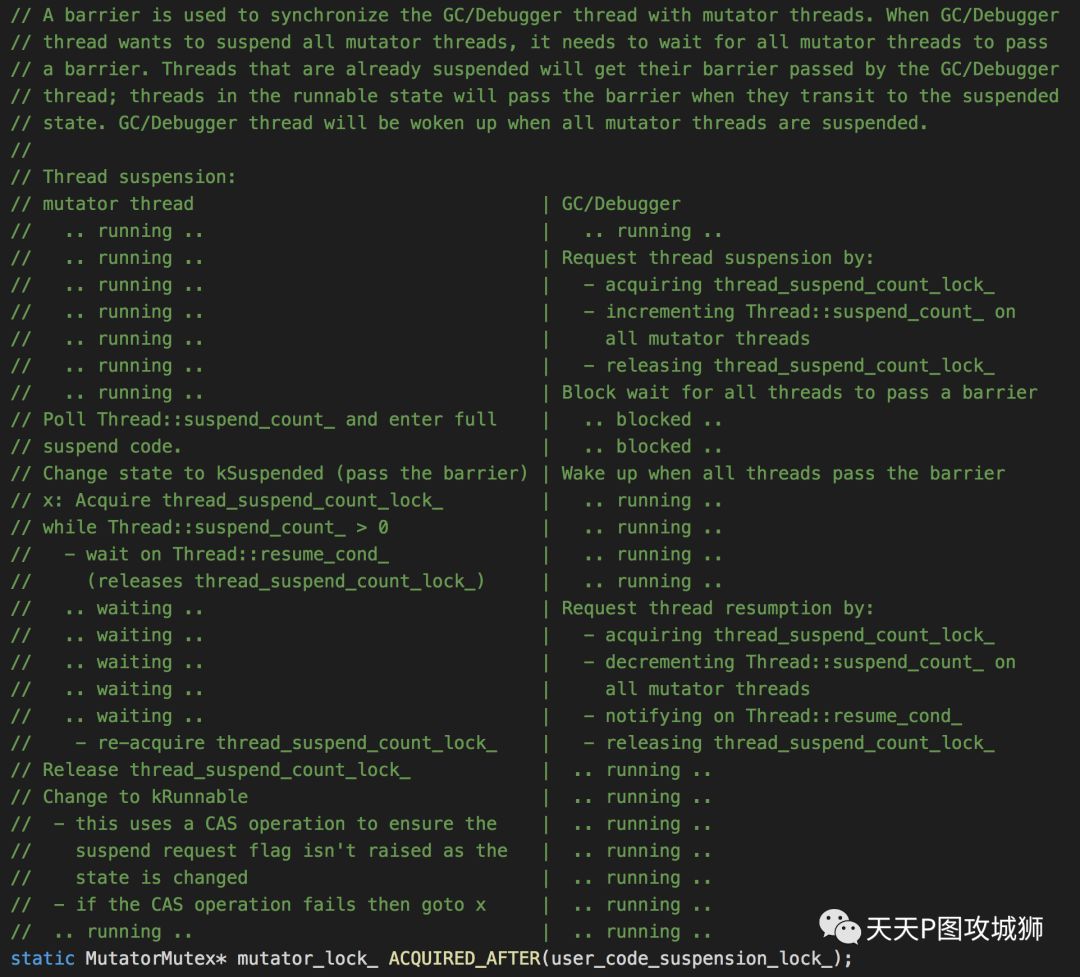
执行到MarkingPhase时,基本上所有的可达对象都已经被标记完了,此时标记栈都已经被处理完。实际中的MarkingPhase会存在多次标记的现象,因为前面提到,并不是所有的操作都需要stop the world,会导致mutator线程在GC过程中访问对象,甚至修改对象之间的引用关系,因此需要多次的标记来保证所有需要标记的对象都被标记了。每次标记完之后,都会通过CheckEmptyMarkStack进行校验。
复制对象的过程时候在标记阶段完成的,下图是复制的操作:
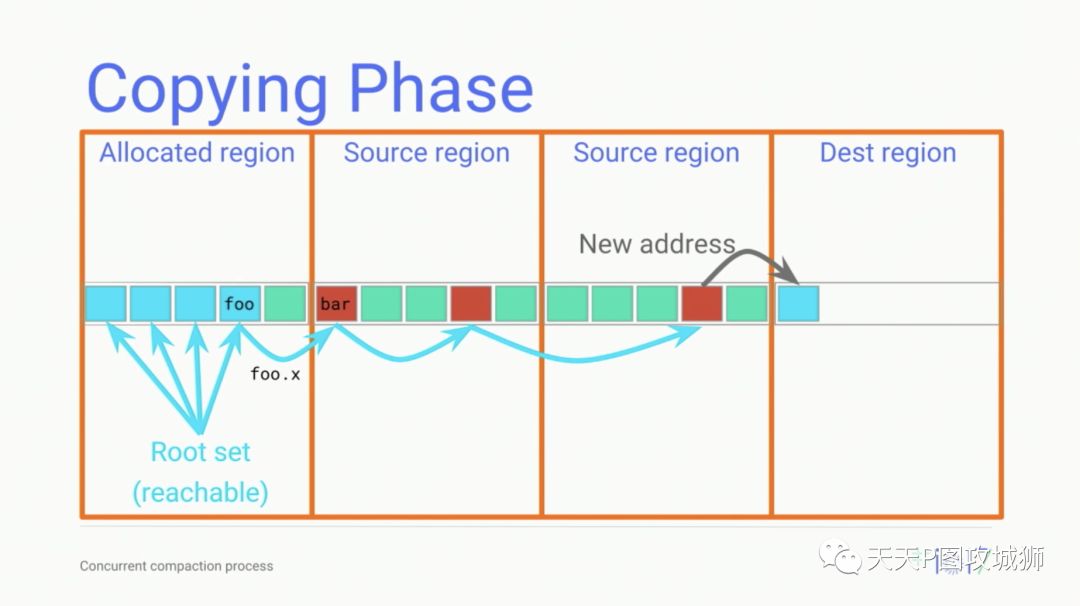
一旦from space中的某个对象被扫描到,就说明它是存活的,因此需要将这个对象拷贝到to space中。to space中的对象可以依次排布,从而有效地减少了内存碎片。拷贝之前,需要先获取一个转发地址,简单的说,就是在to space中分配一块同样大小的内存空间,并将这个对象在to space中的新地址,然后将这个对象memcpy过去。
template<bool kGrayImmuneObject, bool kFromGCThread>
inline mirror::Object* ConcurrentCopying::Mark(mirror::Object* from_ref,
mirror::Object* holder,
MemberOffset offset) {
if (from_ref == nullptr) {
return nullptr;
}
DCHECK(heap_->collector_type_ == kCollectorTypeCC);
if (kFromGCThread) {
DCHECK(is_active_);
DCHECK_EQ(Thread::Current(), thread_running_gc_);
} else if (UNLIKELY(kUseBakerReadBarrier && !is_active_)) {
// In the lock word forward address state, the read barrier bits
// in the lock word are part of the stored forwarding address and
// invalid. This is usually OK as the from-space copy of objects
// aren't accessed by mutators due to the to-space
// invariant. However, during the dex2oat image writing relocation
// and the zygote compaction, objects can be in the forward
// address state (to store the forward/relocation addresses) and
// they can still be accessed and the invalid read barrier bits
// are consulted. If they look like gray but aren't really, the
// read barriers slow path can trigger when it shouldn't. To guard
// against this, return here if the CC collector isn't running.
return from_ref;
}
DCHECK(region_space_ != nullptr) << "Read barrier slow path taken when CC isn't running?";
space::RegionSpace::RegionType rtype = region_space_->GetRegionType(from_ref);
switch (rtype) {
case space::RegionSpace::RegionType::kRegionTypeToSpace:
// It's already marked.
return from_ref;
case space::RegionSpace::RegionType::kRegionTypeFromSpace: {
mirror::Object* to_ref = GetFwdPtr(from_ref);
if (to_ref == nullptr) {
// It isn't marked yet. Mark it by copying it to the to-space.
to_ref = Copy(from_ref, holder, offset);
}
DCHECK(region_space_->IsInToSpace(to_ref) || heap_->non_moving_space_->HasAddress(to_ref))
<< "from_ref=" << from_ref << " to_ref=" << to_ref;
return to_ref;
}
case space::RegionSpace::RegionType::kRegionTypeUnevacFromSpace: {
return MarkUnevacFromSpaceRegion(from_ref, region_space_bitmap_);
}
case space::RegionSpace::RegionType::kRegionTypeNone:
if (immune_spaces_.ContainsObject(from_ref)) {
return MarkImmuneSpace<kGrayImmuneObject>(from_ref);
} else {
return MarkNonMoving(from_ref, holder, offset);
}
default:
UNREACHABLE();
}
}我们前面介绍了,对象的lock word可以处于转发地址的状态,也就是说这时候lock work可以用来存储要复制的to space的地址。
等到copy完这个对象之后,根据前面三色抽象的原理,这个对象就可以标记称灰色了,ART中的代码也是这么做的。这些都完成之后,需要将这个新的转发地址push到标记栈中,意味着它的子节点需要进行标记了。ART的实现与三色抽象的原理略有不同的是,它并未使用黑色这种状态,而是只有白色和灰色的状态:
static constexpr uint32_t white_state_ = 0x0; // Not marked.
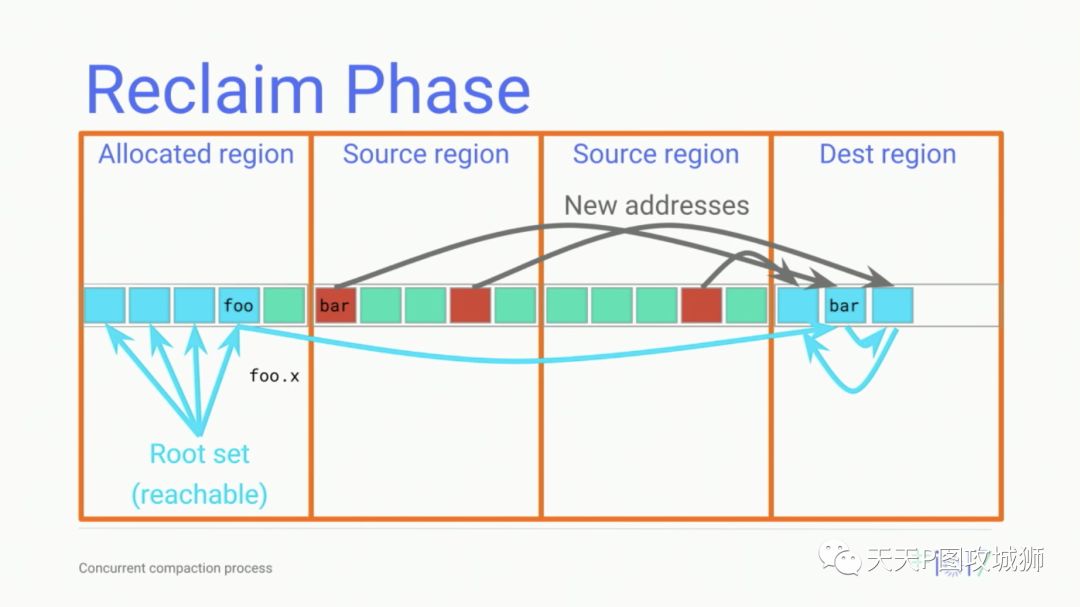
static constexpr uint32_t gray_state_ = 0x1; // Marked, but not marked through. On mark stack.回收阶段,GC就可以将所有from space都清空了,也就是把类型为from的region都清空,因为存活的对象类型都是在to space中了(region为to类型)。
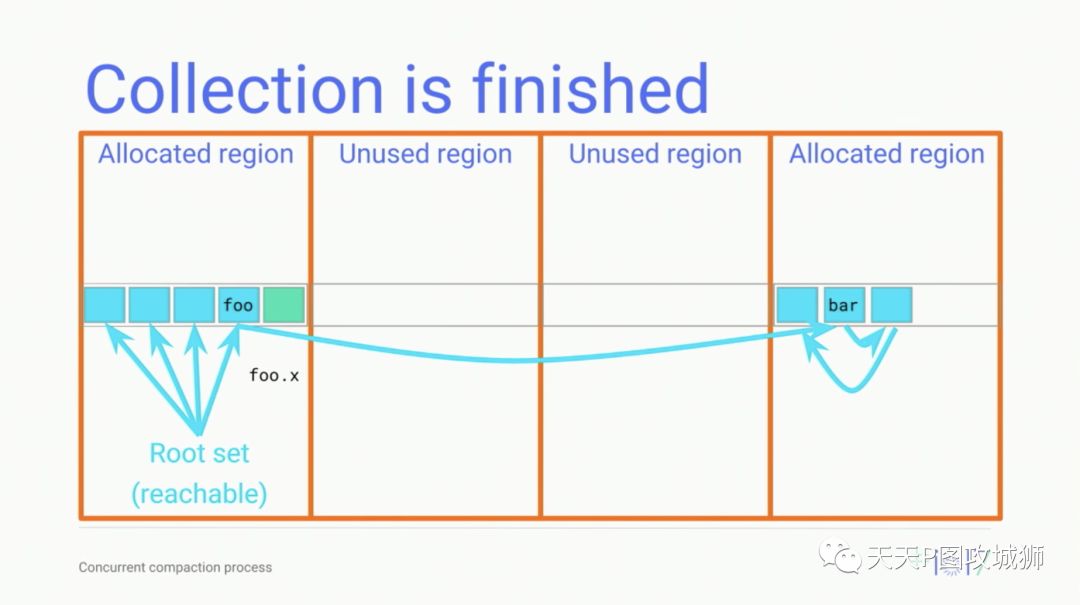
如何做到并发
既然是并发复制GC,那么肯定要关注一个是如何做到并发的。并发的好处很明显,可以大幅降低暂停时间pause time,比如一些交互性的应用,对时间比较敏感,如果pause time过长,会出现明显的卡顿现象。另外对于一些后台的应用,其实不是十分关心暂停时间的,因为就算暂停几百ms用户也不会感觉到(根据场景,ART中可以分为前台GC和后台GC,并可能根据不同的场景选择不同的算法)。
pause time是目前所有GC都无法回避的问题,我们通常称用户线程为mutator线程,也就是说,这些线程会修改堆中的对象,造成对象数值和引用关系的改变。GC线程(collector线程)需要在某个必要的时刻(GC safe point)暂停所有的mutator线程,然后进行对象标记操作。
为了实现并发,并发复制GC中引入了ReadBarrier(读拦截器)技术,具体是Baker ReadBarrier。通过在编译器指令生成的时候,插入部分拦截器指令,可以做到对象访问操作的拦截。这样,只要mutator线程访问堆上的某个对象,都会被GC线程监控。这样做的目的,是为了在GC在拷贝对象时,如果有对象被mutator线程访问了,就可以拦截到这个访问,将这个存活的对象要拷贝的to space地址返回给这个mutator线程,以免被错误的回收掉。
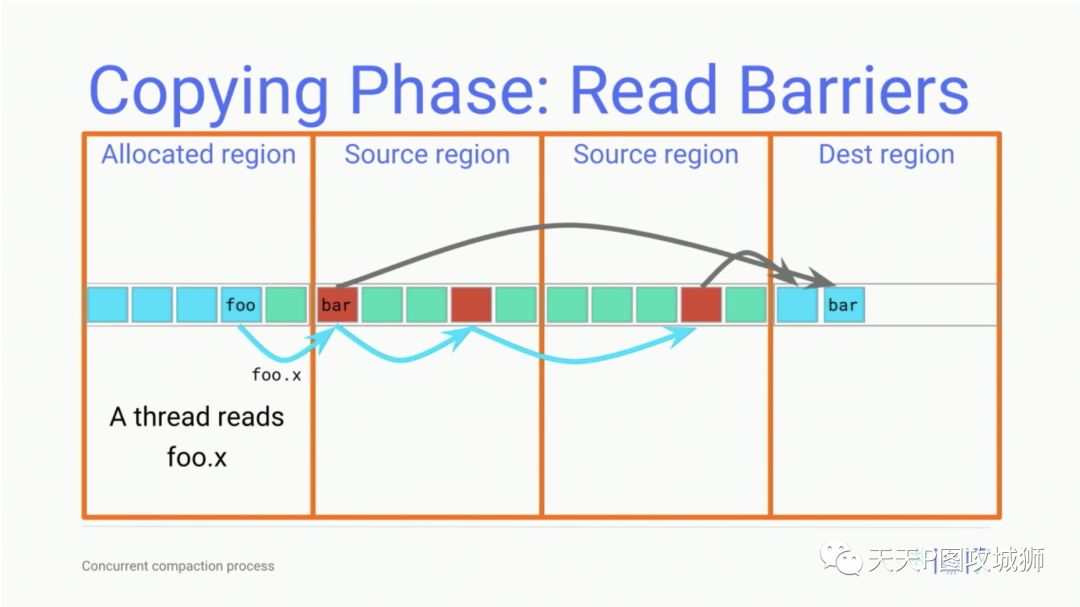
因为ReadBarrier会增加指令,也就导致了代码变长的现象,性能上似乎会有所损耗。但是这个相比以往GC很长的暂停时间,这个损耗是可以忽略不计的。
对于ReadBarrier更细节的介绍,有兴趣地可以参考《The Garbage Collection Handbook The Art of Automatic Memory Management》一书中的”Read and write barriers“一节。
另外,并发复制GC是精确GC(非保守式的GC),通过编译器生成的StackMap实现。
调试GC
调试GC的目的,一个是探寻GC内部的机制,另外一个是分析一些与GC相关的bug,比如堆损坏、GC的正确性以及GC的性能。
分析GC最常用的是GC log,当然除了log,还有很多其他方法,Google官方的指导也是不错的(里面有些内内容已经过时,不适用与并发复制GC):https://source.android.com/devices/tech/dalvik/gc-debug
里面比较有用的一个技巧是,可以通过kill -10 <pid>/kill -S QUIT(需要root权限)来触发一个显式的GC,通过这个GC,我们可以在/data/anr/traces.txt中抓取到当前app的GC性能数据,比如GC的吞吐率信息等。
另外我们可以通过dalvikvm启动一个java程序,配合gdb,我们可以探寻到GC的内部,以下是通过kill -10 <pid>进行显式GC调试的一个例子:
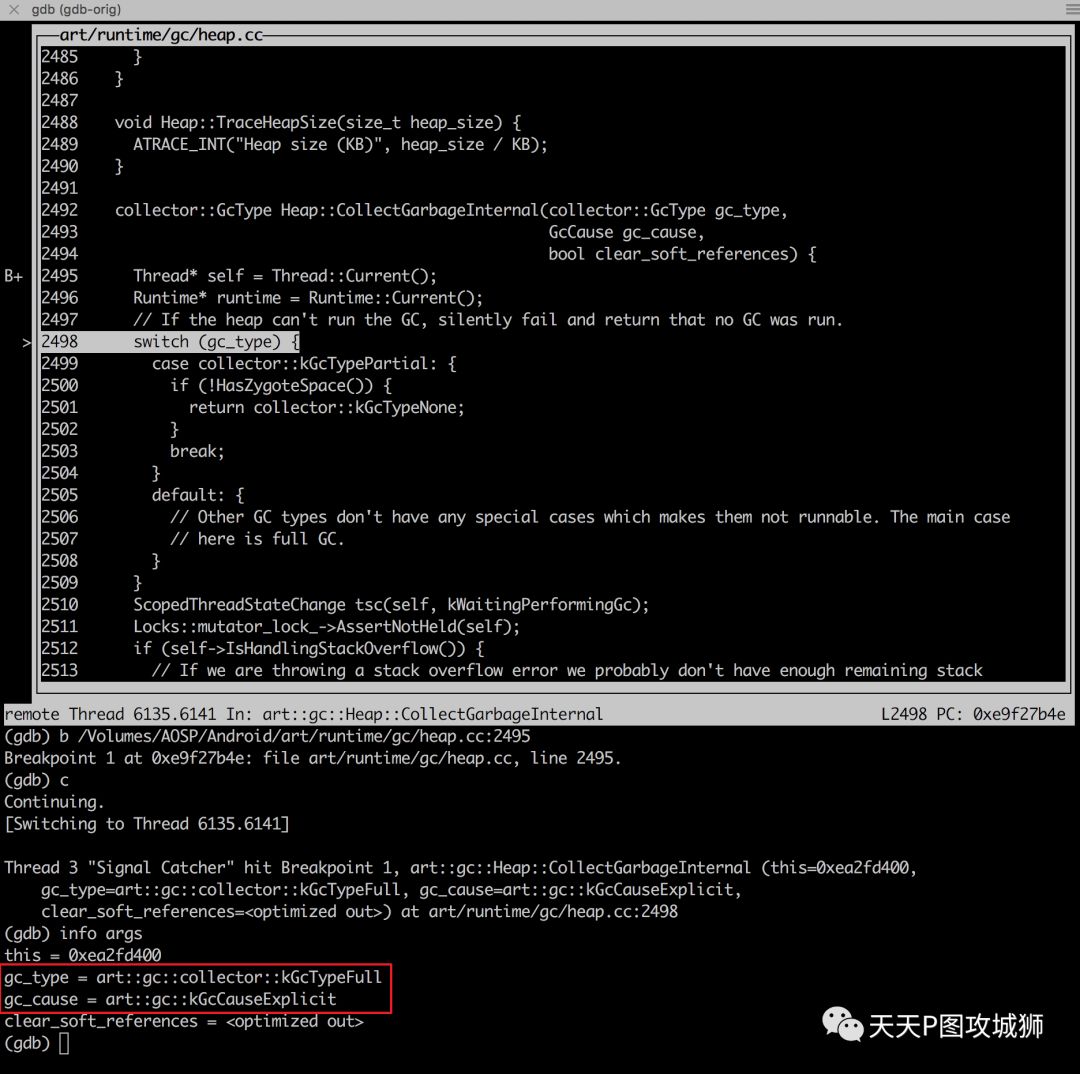
Android中并发复制GC的实现,还涉及到非常多的东西,由于篇幅原因和个人有限的知识,就先写到这里。后面有机会,再讲讲其他的内容。
参考文献
[1] Advanced Design and Implementation of Virtual Machines, Xiao-Feng Li, Jiu-Tao Nie, Ligang Wang
[2] The Garbage Collection Handbook: The Art of Automatic Memory Management, Jones, Hosking, Moss
[3] Garbage Collection, Richard.Jones & Rafael.Lins
[4] Google IO 2017
[5] https://source.android.com/devices/tech/dalvik/gc-debug
[6] The Java™ Language Specification
作者简介:dc, 天天P图AND工程师
文章后记: 天天P图是由腾讯公司开发的业内领先的图像处理,相机美拍的APP。欢迎扫码或搜索关注我们的微信公众号:“天天P图攻城狮”,那上面将陆续公开分享我们的技术实践,期待一起交流学习!

加入我们 天天P图技术团队长期招聘: (1) 深度学习(图像处理)研发工程师(上海) 工作职责
- 开展图像/视频的深度学习相关领域研究和开发工作;
- 负责图像/视频深度学习算法方案的设计与实现;
- 支持社交平台部产品前沿深度学习相关研究。
工作要求
- 计算机等相关专业硕士及以上学历,计算机视觉等方向优先;
- 掌握主流计算机视觉和机器学习/深度学习等相关知识,有相关的研究经历或开发经验;
- 具有较强的编程能力,熟悉C/C++、python;
- 在人脸识别,背景分割,体态跟踪等技术方向上有研究经历者优先,熟悉主流和前沿的技术方案优先;
- 宽泛的技术视野,创造性思维,富有想象力;
- 思维活跃,能快速学习新知识,对技术研发富有激情。
(2) AND / iOS 开发工程师 (3) 图像处理算法工程师 期待对我们感兴趣或者有推荐的技术牛人加入我们(base 上海)!联系方式:ttpic_dev@qq.com
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2019-01-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号