PyTorch 2.0 实操,模型训练提速!

PyTorch 2.0 实操,模型训练提速!

机器学习AI算法工程
发布于 2023-02-28 10:09:57
发布于 2023-02-28 10:09:57
PyTorch 2.0 官宣了一个重要特性 —— torch.compile,这一特性将 PyTorch 的性能推向了新的高度,并将 PyTorch 的部分内容从 C++ 移回 Python。torch.compile 是一个完全附加的(可选的)特性,因此 PyTorch 2.0 是 100% 向后兼容的。
支撑 torch.compile 的技术包括研发团队新推出的 TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor。
- TorchDynamo:使用 Python Frame Evaluation Hooks 安全地捕获 PyTorch 程序,这项重大创新是 PyTorch 过去 5 年来在安全图结构捕获方面的研发成果汇总;
- AOTAutograd:重载 PyTorch 的 autograd 引擎,作为一个跟踪 autodiff,用于生成 ahead-of-time 向后跟踪;
- PrimTorch:将约 2000 多个 PyTorch 算子归纳为一组约 250 个原始算子的闭集,开发人员可以将其作为构建完整 PyTorch 后端的目标。这大大降低了编写 PyTorch 功能或后端的流程;
- TorchInductor:是一种深度学习编译器,可为多个加速器和后端生成快速代码。对于 NVIDIA GPU,它使用 OpenAI Triton 作为关键构建块。
TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor 是用 Python 编写的,并支持 dynamic shapes(无需重新编译就能发送不同大小的向量),这使得它们具备灵活、易于破解的特性,降低了开发人员和供应商的使用门槛。
为了验证这些技术,研发团队在机器学习领域测试了 163 个开源模型,包括图像分类、目标检测、图像生成等、NLP 任务,如语言建模、问答、序列分类、推荐系统和强化学习任务,测试模型主要有 3 个来源:
- 46 个来自 HuggingFace Transformers 的模型;
- 来自 TIMM 的 61 个模型:由 Ross Wightman 收集的SOTA PyTorch 图像模型;
- 来自 TorchBench 的 56 个模型:包含来自 Github 上收集的一组流行代码库。
对于开源模型,PyTorch 官方没有进行修改,只是增加了一个 torch.compile 调用来进行封装
接下来 PyTorch 工程师在这些模型中测量速度并验证精度,由于加速可能取决于数据类型,因此研究团队选择测量 Float32 和自动混合精度 (AMP) 的加速。
在 163 个开源模型中,该团队发现使用 2.0 可以将训练速度提高 38-76%。torch.compile 在 93% 的情况下都有效,模型在 NVIDIA A100 GPU 上的训练速度提高了 43%。在 Float32 精度下,它的平均运行速度提高了 21%,而在 AMP 精度下,它的运行速度平均提高了 51%。
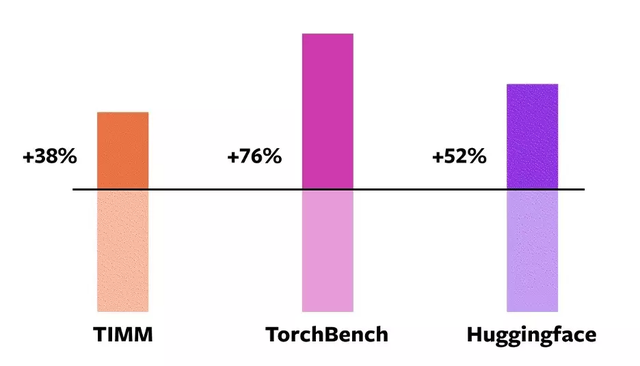
目前,torch.compile 还处于早期开发阶段,预计 2023 年 3 月上旬将发布第一个稳定的 2.0 版本。
PyTorch 的开发理念自始至终都是灵活性和 hackability 第一,性能则是第二,致力于:
1. 高性能的 eager execution
2. 不断 Python 化内部结构
3. 分布式、自动比较、数据加载、加速器等的良好抽
PyTorch 自 2017 年面世以来,硬件加速器(如 GPU)的计算速度提高了约 15倍,内存访问速度提高了约 2 倍。
为了保持高性能的 eager execution,PyTorch 内部的大部分内容不得不转移到 C++ 中,这使得 PyTorch hackability 下降,也增加了开发者参与代码贡献的门槛。
从第一天起,PyTorch 官方就意识到了 eager execution 的性能局限。2017 年 7 月,官方开始致力于为 PyTorch 开发一个编译器。该编译器需要在不牺牲 PyTorch 体验的前提下,加速 PyTorch 程序的运行,其关键标准是保持某种程度上的灵活性 (flexibility):支持开发者广泛使用的 dynamic shapes 以及 dynamic programs。
开发者 Sylvain Gugger 表示:“只需添加一行代码,PyTorch 2.0 就能在训练 Transformers 模型时实现 1.5 倍到 2.0 倍的速度提升。这是自混合精度训练问世以来最令人兴奋的事情!”
在研究支持 PyTorch 代码通用性的必要条件时,一个关键要求是支持动态形状,并允许模型接受不同大小的张量,而不会在每次形状变化时引起重新编译。
目前为止,对动态形状的支持有限,并且正在进行中。它将在稳定版本中具有完整的功能。
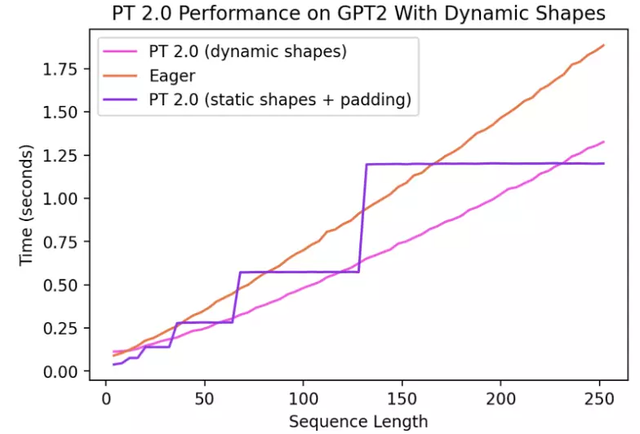
在不支持动态形状的情况下,常见的解决方法是将其填充到最接近的 2 次方。然而,正如我们从下面的图表中所看到的,它产生了大量的性能开销,同时也带来了明显更长的编译时间。
现在,有了对动态形状的支持,PyTorch 2.0 也就获得了比 Eager 高出了最多 40% 的性能。
简而言之,就是 PyTorch 2.0 stable 版本预计明年 3 月发布,PyTorch 2.0 在保留原有优势的同时,大力支持编译,torch.compile 为可选功能,只需一行代码即可运行编译,还有 4 项重要技术:TorchDynamo、AOTAutograd、PrimTorch 以及 TorchInductor,PyTorch 1.x 代码无需向 2.0 迁移,更多用户体验以及Q&A,大家可以查看下方链接中原文
参考链接
https://pytorch.org/get-started/pytorch-2.0/
PyTorch 2.0 通过简单一行 torch.compile() 就可以使模型训练速度提高 30%-200%,本教程将演示如何真实复现这种提速。
torch.compile() 可以轻松地尝试不同的编译器后端,进而加速 PyTorch 代码的运行。它作为 torch.jit.script() 的直接替代品,可以直接在 nn.Module 上运行,无需修改源代码。
torch.compile 支持任意的 PyTorch 代码、control flow、mutation,并一定程度上支持 dynamic shapes。
通过对 163 个开源模型进行测试,我们发现 torch.compile() 可以带来 30%-200% 的加速。
opt_module = torch.compile(module)
测试结果详见:
https://github.com/pytorch/torchdynamo/issues/681
本教程将演示如何利用 torch.compile() 为模型训练提速。
要求及设置
对于 GPU 而言(越新的 GPU 性能提升越突出):
pip3 install numpy --pre torch[dynamo] --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117
对于 CPU 而言:
pip3 install --pre torch --extra-index-url https://download.pytorch.org/whl/nightly/cpu
可选:验证安装
git clone https://github.com/pytorch/pytorch
cd tools/dynamo
python verify_dynamo.py
可选:Docker 安装
在 PyTorch 的 Nightly Binaries 文件中提供了所有必要的依赖项,可以通过以下方式下载:
docker pull ghcr.io/pytorch/pytorch-nightly
对于临时测试 (ad hoc experiment),只需确保容器能够访问所有 GPU 即可:
docker run --gpus all -it ghcr.io/pytorch/pytorch-nightly:latest /bin/bash
开始
简单示例
先来看一个简单示例,注意,GPU 越新速度提升越明显。

这个例子实际上不会提升速度,但是可以抛砖引玉。
该示例中,torch.cos() 和 torch.sin() 是逐点运算 (pointwise ops) 的例子,他们可以在向量上逐一操作 element,一个更著名的逐点运算是 torch.relu()。
eager mode 下的逐点运算并不是最优解,因为每个算子都需要从内存中读取一个张量、做一些更改,然后再写回这些更改。
PyTorch 2.0 最重要的一项优化是融合 (fusion)。
因此,该例中就可以把 2 次读和 2 次写变成 1 次读和 1 次写,这对较新的 GPU 来说是至关重要的,因为这些 GPU 的瓶颈是内存带宽(能多快地把数据发送到 GPU)而不是计算(GPU 能多快地进行浮点运算)。
PyTorch 2.0 第二个重要优化是 CUDA graphs。
CUDA graphs 有助于消除从 Python 程序中启动单个内核的开销。
torch.compile() 支持许多不同的后端,其中最值得关注的是 Inductor,它可以生成 Triton 内核。
https://github.com/openai/triton
这些内核是用 Python 写的,但却优于绝大多数手写的 CUDA 内核。假设上面的例子叫做 trig.py,实际上可以通过运行来检查生成 triton 内核的代码。
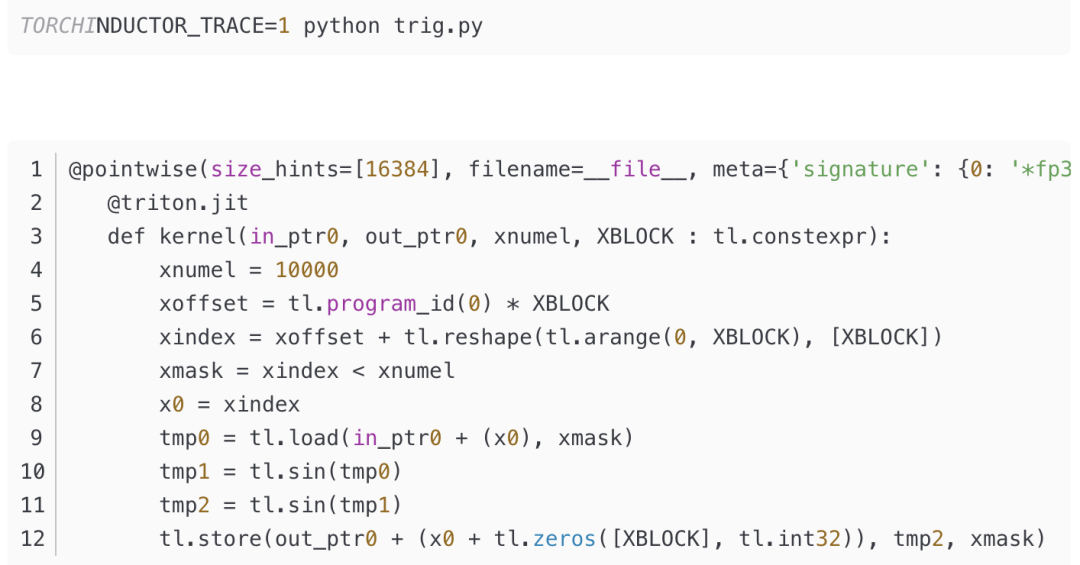
以上代码可知:两个 sins 确实发生了融合,因为两个 sin 算子发生在一个 Triton 内核中,而且临时变量被保存在 register 中,访问速度非常快。
真实模型示例
以 PyTorch Hub 中的 resnet50 为例:

实际运行中会发现,第一次运行速度很慢,这是因为模型正在被编译。随后的运行速度会加快,所以在开始基准测试之前,通常的做法是对模型进行 warm up。
可以看到,这里我们用「inductor」表示编译器名称,但它不是唯一可用的后端,可以在 REPL 中运行 torch._dynamo.list_backends() 来查看可用后端的完整列表。
也可以试试 aot_cudagraphs 或 nvfuser
Hugging Face 模型示例
PyTorch 社区经常使用 transformers 或 TIMM 的预训练模型:
https://github.com/huggingface/transformers
https://github.com/rwightman/pytorch-image-models
PyTorch 2.0 的设计目标之一,就是任意编译栈,都需要在实际运行的绝大多数模型中,开箱即用。
这里我们直接从 HuggingFace hub 下载一个预训练的模型,并进行优化:

如果从模型中删除 to(device="cuda:0") 和 encoded_input ,PyTorch 2.0 将生成为在 CPU 上运行优化的 C++ 内核。
可以检查 BERT 的 Triton 或 C++ 内核,它们显然比上面的三角函数的例子更复杂。但如果你了解 PyTorch 可以略过。
同样的代码与以下一起使用,仍旧可以得到更好的效果:
* https://github.com/huggingface/accelerate
* DDP
同样的,试试 TIMM 的例子:

PyTorch 的目标是建立一个能适配更多模型的编译器,为绝大多数开源模型的运行提速,现在就访问 HuggingFace Hub,用 PyTorch 2.0 为 TIMM 模型加速吧!
https://huggingface.co/timm
原文地址
https://blog.csdn.net/HyperAI/article/details/128257201
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-02-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号