图解K8s源码 - kubelet 下的 QoS 控制机制及 k8s Cgroups v2 简介

图解K8s源码 - kubelet 下的 QoS 控制机制及 k8s Cgroups v2 简介

才浅Coding攻略
发布于 2023-03-01 14:51:13
发布于 2023-03-01 14:51:13
在日常使用 K8s 时,难免遇到 Node 上资源紧张导致节点中的 Pod 被 OOMKill 掉的情况,哪些 Pod 会被 kill 呢?又是根据什么评判标准来确定的优先级呢?
QoS
这个评判标准就是 QoS(Quality of Service)即服务质量,它是一种控制机制,会针对不同用户或者不同数据流采用不同的优先级。在 K8s中它会对运行中的 Pod 进行质量划分,划分出三种类型:Guaranteed,Burstable,BestEffort。

我们通过设置 Requests 和 Limits 来保障集群资源,其中 Requests 是 Pod 运行的最低资源要求,Limits 是 Pod 最多可以获取到的资源。根据设置的 Requests 和 Limit,K8s 又将其分为不同的 QoS。三种QoS级别是针对整个 Pod 而非某个容器,它决定了 Pod 的调度和驱逐策略。当节点主机资源紧张或不足时,kubelet 会把一些低优先级的,或者说服务质量要求不高的 Pod 优先删除掉(如 BestEffort Pod)。
QoS 会根据不同的分类进行 OOMScore 打分,首先每个种类设置基础分数,kubelet 会根据 OOM 的评分调整 oomScoreAdjust 。当宿主机上内存不足发生 OOM 时,oomScoreAdjust 数值越高就越优先被 Kill。打分机制流程见下图,图片来自旭东大佬文章:
图解 K8S 源码 - QoS 篇 https://mp.weixin.qq.com/s/YxKAd4u4_nYEspvkTJTPaw
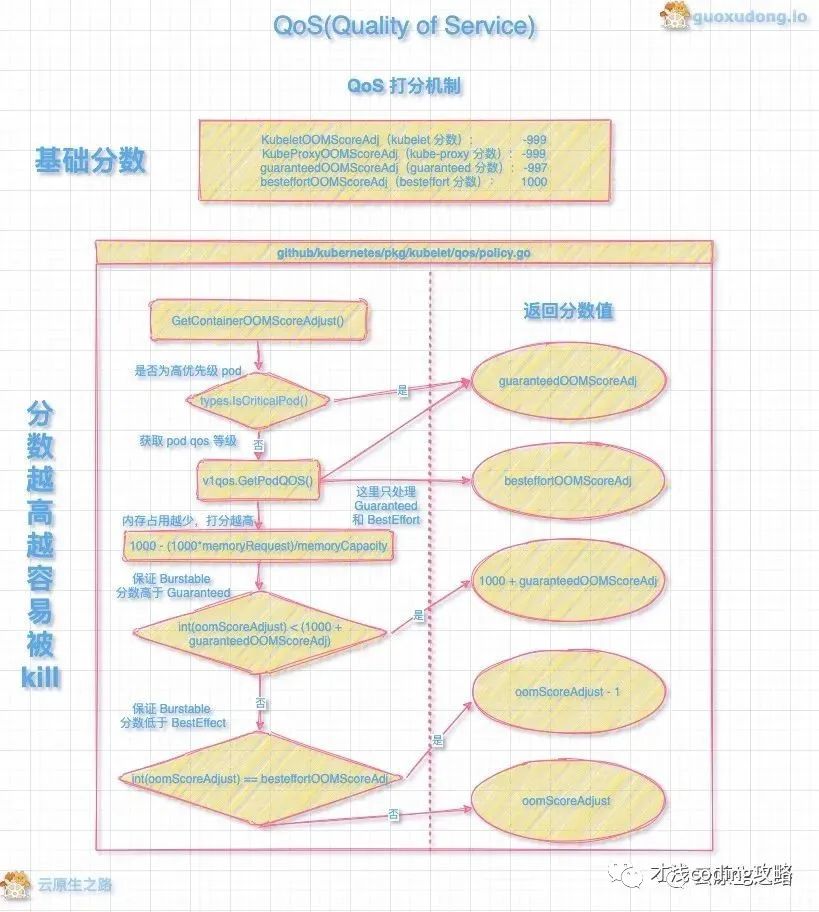
另外当节点内存或 CPU 资源不足时,kubelet 在驱逐节点上的 Node 时也会依据 Qos 的优先级确定驱逐顺序,次序和 OOM kill 的次序一样。
下面我们来看看 QoS 的具体实现。QoS 的具体实现在 kubelet 中的 QOSContainerManager 中。QOSContainerManager 是包含在 containerManager 下的,所以在初始化和启动 containerManager 时也会对 QOSContainerManager 做初始化和启动。启动后的流程如下:
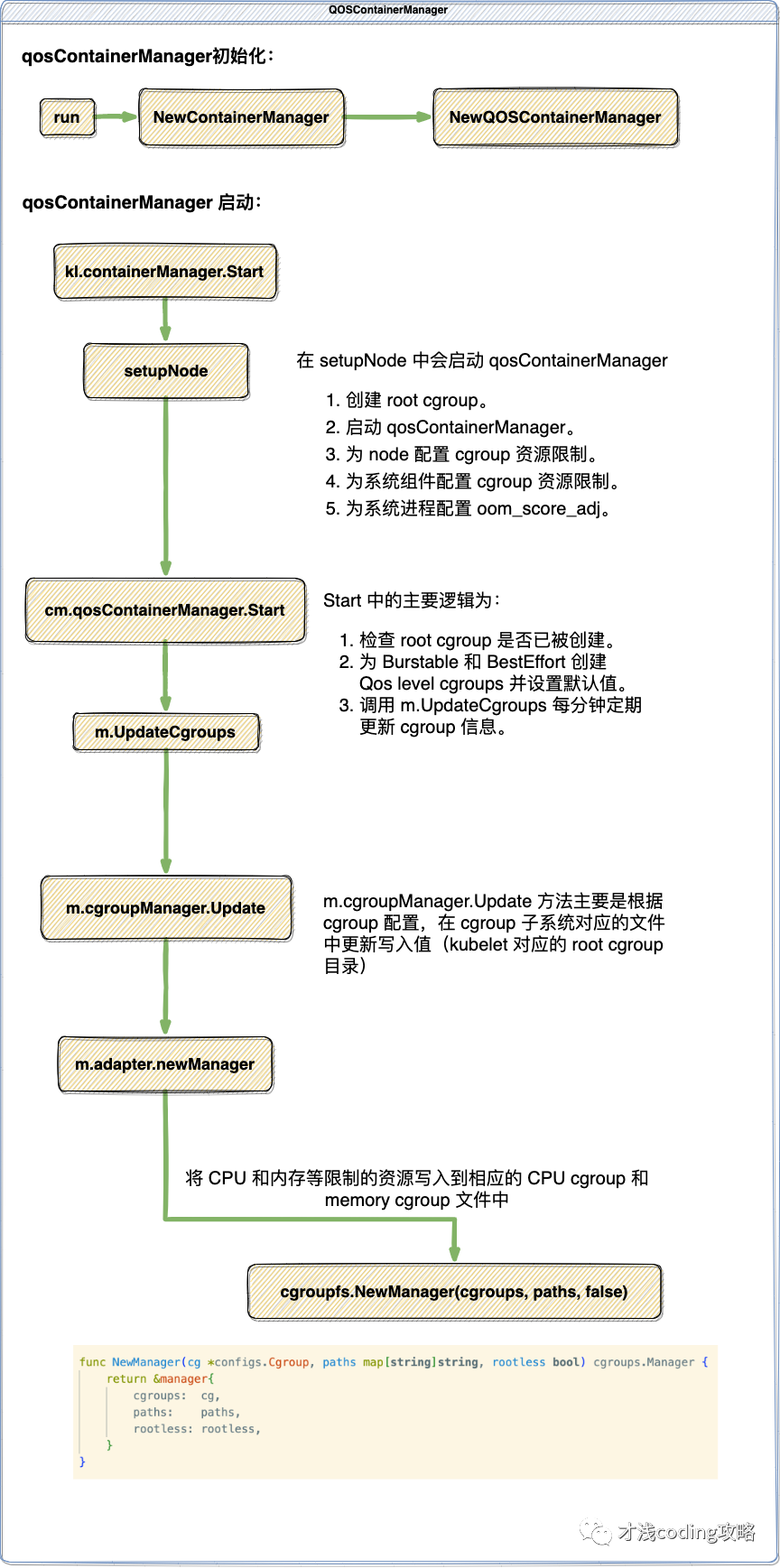
为了使 cgroup_manager 适配 cgroupv2,cgroup_manager 的部分代码做了更新。k8s 在1.19+版本中开始支持 cgroups v2,目前社区推荐使用 k8s 版本 v1.22+。
源码路径 k8s.io/kubernetes/pkg/kubelet/cm/cgroup_manager_linux.go 大家有兴趣可以去对比 cgroup v1 看下 。
cgroup
对于容器技术而言,它实现资源层面上的限制和隔离,依赖于 Linux 内核所提供的 cgroup 和 namespace 技术。简单来说 Namespace 可以让每个进程有独立的 PID, IPC 和网络空间。cgroup 可以控制进程的资源占用,比如 CPU ,内存和允许的最大进程数等等。cgroup 是在 2008 年进入的Linux内核,到目前为止有两个大版本:cgroup v1 和 cgroup v2 。
cgroups子系统
cgroups 的全称是control groups,cgroups为每种可以控制的资源定义了一个子系统。典型的子系统介绍如下:
- cpu 子系统,主要限制进程的 cpu 使用率。
- cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告。
- cpuset 子系统,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
- memory 子系统,可以限制进程的 memory 使用量。
- blkio 子系统,可以限制进程的块设备 io。
- devices 子系统,可以控制进程能够访问某些设备。
- net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
- freezer 子系统,可以挂起或者恢复 cgroups 中的进程。
- ns 子系统,可以使不同 cgroups 下面的进程使用不同的 namespace。
cgroup 在 K8s中使用的几个点
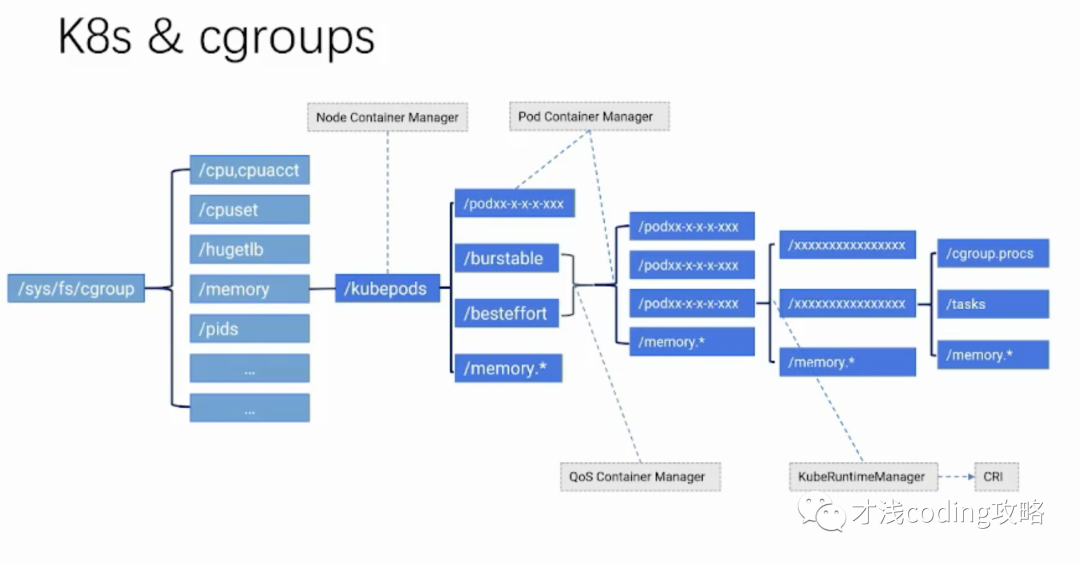
我们对照下图来看,首先在每一个子系统的目录下面都会有 kubepods 这个目录,所有的 cgroup 都是它的子 cgroup。接下来是 burstable 和baseeffort,Guaranteed 是直接在 kubepods 同级的 cgroup 目录,Guaranteed 类型的 pod 会直接放到 kubepods 下面。
在 kubepods 这一层级有 Node Container Manager 来负责为这个 cgroup 设置可分配的资源,比如可用的 cpu 和 memory。在 QoS 这个层级有 QoS Controller Manager 去创建 QoS 的 cgroup 并进行相应的设置。
在 Pod 这一层有 Pod Container Manager 来创建 Pod 对应的 cgroup,并且进行相应 cgroup 的设置。
最后到了容器这一层,会有 kubeRuntimeManager 通过 CRI 接口调用底层的运行时,比如 docker,将 cgroup 这些参数传递给 docker 来执行真正的容器的创建。
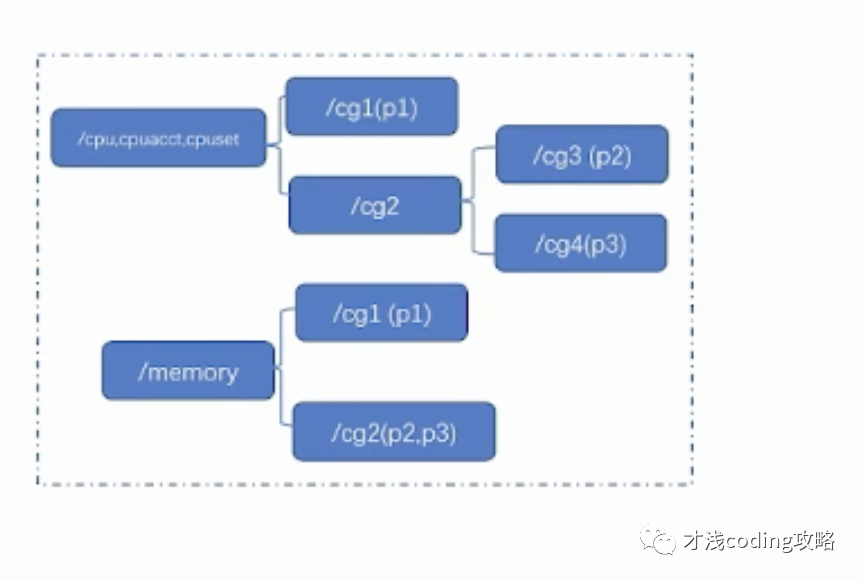
Cgroups v1已经在整个生态中使用很久了,为什么社区还要开发新版本呢?
1、v1 层级结构过于灵活复杂。
在 v1 中,不同的子系统比如 cpu、memory 其实可以挂载到一起。比如以下例子中将 cpu 相关的三个子系统挂到了一起,memory 是另外一个挂载点。而且在不同的子进程中,同样的进程可以属于不同的层级。比如说p2、p3 在 cpu 和 memory 下是在不同的cgroup 层级中的。然而这种灵活性是没有必要的,还导致了不必要的复杂性。比如我们要对同一个容器设置 cpu 和 memory,包括所有其它的子系统,需要在所有子系统下重复同样的操作。这样的操作繁琐耗时长,还不是原子操作,会带来许多问题。
2、v1不支持buffer io写限速。
因为在 Linux 上的 page cache 回写机制,中间会有缓存以及脏页的机制,只有达到一定比例,系统才会回写磁盘。这种情况下做限速的话就需要 memory 和 blkio 这两个子系统能够协同。但是在 v1 中这两个子系统是独立设计和实现的,无法达到协同,也就无法限制 buffer io 的写。
3、v1 不同的资源控制器的设计和实现不统一。
- 有的继承父cgroup的属性,有的不继承。
- 接口文件命名和取值不一致,比如都表示最大:memory.limit_in_bytes,cpu.cfs_quota_us,pids.max,我们可以看到内存、cpu和进程数的表示方法并不统一。另外表示无限制的最大值也不同,对应分别是:0x7FFFFFFFFFFFF000,-1,max。
4、v1 的 cgroup 可同时包含 tasks 和子 cgroup,资源竞争行为不明确。
比如我本身有任务,我的子cgroup也包含了任务,这导致不同的任务在不同层级之间的资源竞争,很多情况下这种竞争行为不明确,系统无法保证。
5、v1 线程粒度的控制有很多问题。
比如我们把一个任务中不同的线程写到不同的 cgroup 中,这样操作对大多数子系统是无意义的,也会带来一些问题。
针对上述问题和不足 cgroup v2做了哪些改进?
1、首先在层级上不再会有单一独立的子系统,所有的子系统即资源控制器都使用同一层级。只需要挂载文件类型是 cgroups v2 的资源控制器,而不需要对如cpu、memory进行单独挂载了。
2、内存和io控制器是协同开发的,支持buffer io写限速。
3、统一了接口文件的命名和赋值规则:
- 接口文件:.min,.low,.high,.max,.weight,.stat,.current
- 无限制的最大值:max;最小值:0
- 权重范围:[1, 10000],默认100
4、只有叶子cgroup可以包含任务。
5、默认不支持线程模式,可通过写接口文件配置。
v1 和 v2 支持的资源控制器对比

另外新增一个新的特性 PSI——Pressure Stall Information,能够去统计由于资源短缺引起的系统停滞的这些信息,准确反映资源(cpu,memory,io)压力,并根据压力情况采取措施,比如不再调度,kill低优先级任务等等,减轻整个系统的压力。
参考:
https://cloud.tencent.com/developer/salon/live-1520
https://mp.weixin.qq.com/s/YxKAd4u4_nYEspvkTJTPaw
https://blog.tianfeiyu.com/source-code-reading-notes/kubernetes/kubelet_qos.html
https://tech.meituan.com/2015/03/31/cgroups.html
END
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-01-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号