开源RDS替代:开箱即用、自动驾驶的数据库发行版 Pigsty

开源RDS替代:开箱即用、自动驾驶的数据库发行版 Pigsty

用户6543014
发布于 2023-03-02 14:38:18
发布于 2023-03-02 14:38:18

本次分享将介绍Pigsty:PostgreSQL RDS的Me-Better开源替代。Pigsty是如何从可观测性,可靠性,可维护性,可用性,可扩展性与安全性六个维度上,让裸奔的PostgreSQL内核成为全盛状态的六边形战士,以云数据库5%~30%的成本,提供更好的生产级关系型数据库服务(RDS)。
以下为 DTCC 2022 磐吉云数CEO 冯若航的演讲实录:
最近有一个非常火热的领域 —— FinOps,它关注的是如何在公有云上节省开支。
公有云上什么最花钱?正常来说,如果不是把公有云单纯当作一个 IDC 2.0 或者 CDN供应商来用,最费钱的服务当属云数据库。
公有云上的存储、计算、网络资源贵吗?严格来说不算特别离谱。IDC托管物理机代维的核月成本大约为二三十块,而公有云上一核 CPU 算力用一个月的价格,大概在七八十块到一两百块,考虑到各种折扣与活动,以及弹性溢价,基本处于薄利多销的状态:国内公有云 IaaS 层的收入占营收接近一半,但毛利率只有 15% ~ 20%。
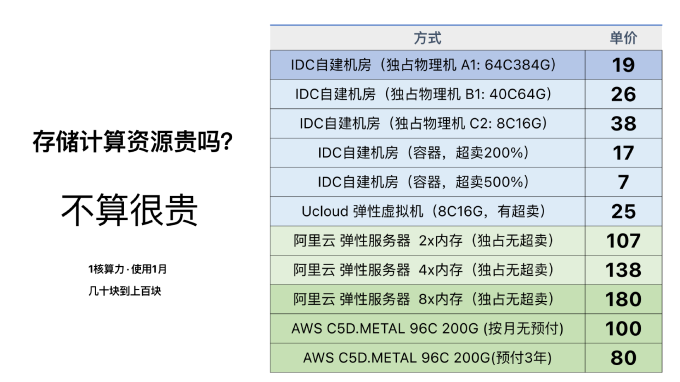
不过说起云数据库的价格,那就非常离谱了。同样是一核算力用一个月,云数据库价格,比起对应规格的硬件可以翻几倍乃至十几倍。 便宜一些阿里云,核月单价三四百,RDS大致有两到三倍的溢价;贵一些的 AWS,核月单价上千,RDS相比EC2溢价高达十几倍。以 AWS 顶配RDS (m5.24xlarge )为例,标准(单可用区版)每月价格13万,但如果你直接买对应的EC2资源,就只需要 1.2 万元每月,相差足足有十倍。

云数据库为什么这么贵?这是公有云的商业秘密:用廉价的存算资源获客,用云数据库杀猪。
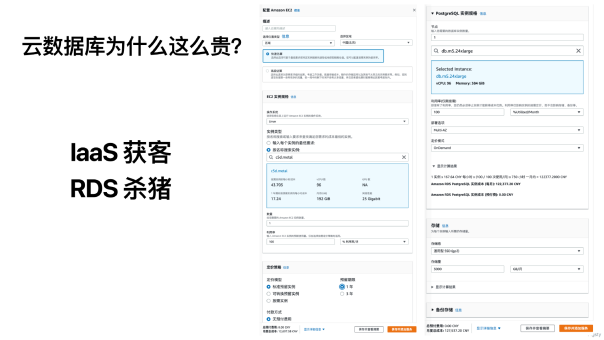
尽管公有云上PaaS 的营收仍不如 IaaS,但 PaaS 的毛利率可以达到 50%,完爆卖资源吃饭的 IaaS 。
为什么会是这样呢?用话术说差不多是,数据库是基础软件里的皇冠明珠,凝聚着无数无形知识产权BlahBlah,价格远超硬件,那是很自然的事呀。如果是 Oracle 这样的顶尖商业数据库,这也许勉强说得通。但公有云上的云数据库,本质上就是免费开源数据库内核换皮封装魔改,加上自己管控软件和共享DBA人头。一番操作,就敢把核月单价 20 块的机器卖出 1000 元的天价,这就非常离谱了。
千把块的单价,比起 Oracle 动辄上万的核月 License Fee 好像便宜不少。如果买个几核的小微实例,好像 RDS 还是挺合算的,几倍溢价也不算什么。但只要数据库的规模稍微大一点,这种线性增长的费用模型就是纯粹的杀猪:为了不需要的弹性支付几倍溢价,不是理智的行为。
前生今“势”
软件行业经历了几次范式转移,数据库也不例外。

最开始,以 Oracle 为代表的商业数据库,替代了人工纸笔手算,用软件取代了人节省了很多花费。 不过,Oracle 这样的数据库还是很贵,所以像 PostgreSQL这样开源免费的数据库出现了。大多数场景下,如果能雇到一两个专家,用好开源数据库,那可比傻乎乎给 Oracle 送钱要实惠太多了。
但问题就在于,能用好开源数据库的专家是很稀缺的。而且往往有价无市。这就阻碍了开源数据库的普及。
所以云数据库出现了:用免费的开源数据库内核,加上共享的专家和管控软件,打包成服务出售。千把块的单价,比起商业数据库动辄上万的核月 License Fee好像便宜不少,但和开源数据库一比,还是差的太远太远。最后大家算起账来会发现,买一核的云数据库,掏个几倍溢价还没什么。但只要数据库的规模稍微大一点, 用云数据库就是冤大头了,杀起猪来杠杠的。
那么,后云时代,我们需要什么样的数据库管理软件?时代在呼唤一个开源的RDS替代品。
时代在呼唤什么?
2022年的现状是什么?数据库内核已经完全卷不动了,作为一项有四五十年历史的技术,能折腾的东西已经被折腾的差不多了。业界已经不缺足够完美的数据库内核了 —— PostgreSQL,功能完备且开源免费,无数”国产数据库“基于此换皮改造而成。真正稀缺的是什么,是把现有的 DBMS / Kernel 用好的能力。
业界稀缺的并非是各种数据库内核的新轮子,现有的数据库已经足够好了,稀缺的是能把现有数据库内核用好的能力。在以前,专业DBA来解决这个问题,而我们要用数据库的自动驾驶软件来解决这一问题,让所有人都有能力去用好最先进的开源数据库 ——PostgreSQL。
这就是我们正在做的事情,Pigsty。Pigsty 是 Postgres in Great STYle 的缩写,即“全盛状态下的 PostgreSQL”。 它完全开源,是一个基于开源软件的,可以跑在任何地方的,浓缩了 PostgreSQL使用最佳实践的,Me-Better 开源 RDS 替代。

在介绍 Pigsty 之前,有必要提一下 PostgreSQL。
PostgreSQL本身已是一个足够完美的数据库内核,但问题在于,能用好它的人还真不多。我亲身见到的大量用例里,就是两板斧:
yum install postgresql & systemctl start postgres
这相当于,新手玩家买了架无人穿梭机,说明书都没看就开始翻起筋斗:在足够空旷的高空也许没问题,但在城市的复杂环境中,用不了多久就该炸机了。
因此,介绍全盛状态的 PostgreSQL之前,先要说一说裸奔状态的PostgreSQL。

一个生产级、企业级的数据库服务,内核只是其中一部分,更重要的往往是配套的软件与服务。基础设施管理平台、监控日志、告警规则、服务发现、高可用,连接池、负载均衡、访问控制、审计、安全备份、PITR。只有把这些整合起来,才能变成一个企业级的数据库服务。
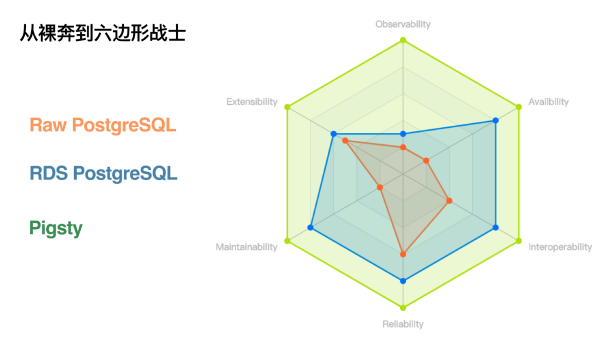
Pigsty 就是这样的一款产品,它在六个重要的维度上,做了很多的工作:可观测性、可靠性、可维护性、可用性、可扩展性以及互操作性。
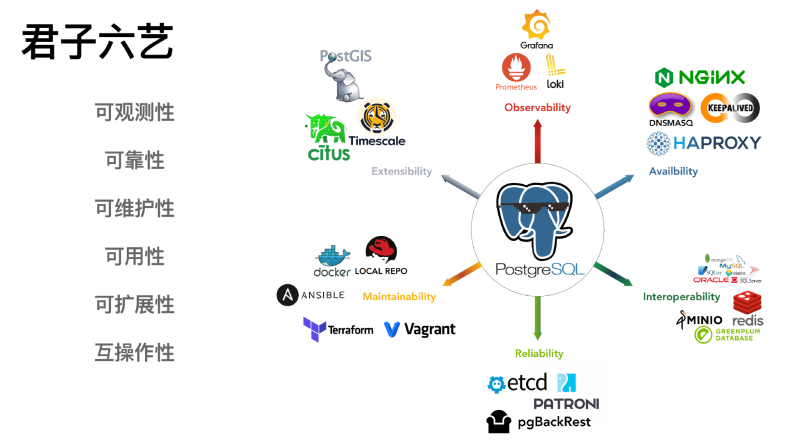
这里最重要的一对属性是 Observability 和 Reliability,这是对数据库系统的核心要求。
可观测性是天,这是任何有效管理的基础。所以我们用了现代的可观测性技术栈,为 PostgreSQL打造了一款无与伦比的监控系统,让用户对系统能够做到洞若观火。
可靠性是地。任何数据库系统,可靠性一定是最重要、最基本的能力指标。我们提供了自动驾驶的高可用,在硬件故障时可自动恢复、故障自愈。也提供了开箱即用的 PITR时间点恢复,为人为删库兜底。
第二对属性是可用性和可维护性。
可维护性是关于DBA与运维人员如何管理数据库的问题,Pigsty 提供了 Database-as-Code 的能力,通过声明式的接口,让数据库操作与管理的门槛从专家级降低到新手级。
可用性是关于开发者如何使用数据库,数据库如何持续不间断提供服务的能力。这里我们提供了开箱即用的 DNS / VIP / HAPROXY,对用户屏蔽了接入的复杂性,使故障切换、主动切换、都能对用户保持透明。
最后一对属性是 Extensibility 和 Interoperability。
可扩展性是如何为现有系统加装功能的能力。这里面我们深度集成了 PostgreSQL 的三大核心扩展PostGIS、TimescaleDB、Citus ,与无数PG生态的插件。
互操作性是它和一些外部的数据库组件交互的能力。比如通过 FDW 访问其他数据库的能力。和 Redis、Greenplum、MINIO 交互的能力,还有很多使用 PG 的软件应用模板。
这是我们最为关注的六个能力方向。通过这些改进,我们让 PostgreSQL从裸奔状态下的堪堪可用,升级为全盛状态下的六边形全能战士。
更重要的是,在实现这些权能的同时,Pigsty还能将系统的复杂度控制在一个极低的水平。这样一整套的生产及解决方案,下载、配置、安装仍然只需要一条命令即可。
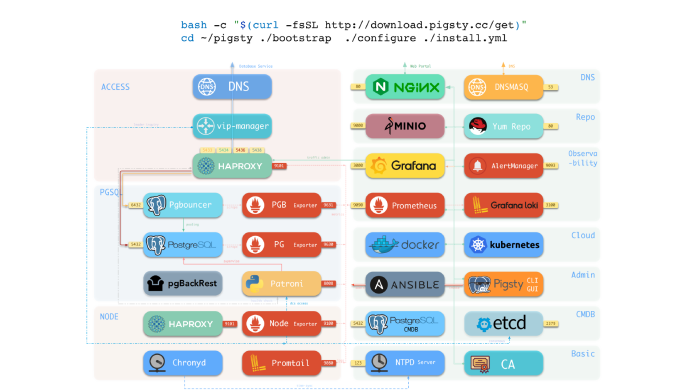
下面我们会详细介绍 Pigsty 在这六个领域上进行的一些工作。
可观测性
可观测性是天,它是任何有效管理的基础。我们使用现代可观测性技术栈,打造了一款无与伦比的监控系统。
各大云厂商,三方监控,在PostgreSQL可观测性上确实没有一个能打的,这也是我们自己做监控系统的原因:实在是找不到满足我们自己需求的软件产品。 Pigsty的监控系统将几千类监控指标精炼为几十个综合面板,从最顶层的全局概览到单个表/索引/函数/序列号的实时/历史详情一览无余, 让用户对系统的状态洞若观火。应该说,在PostgreSQL监控上, Pigsty有着无可替代的巨大价值。
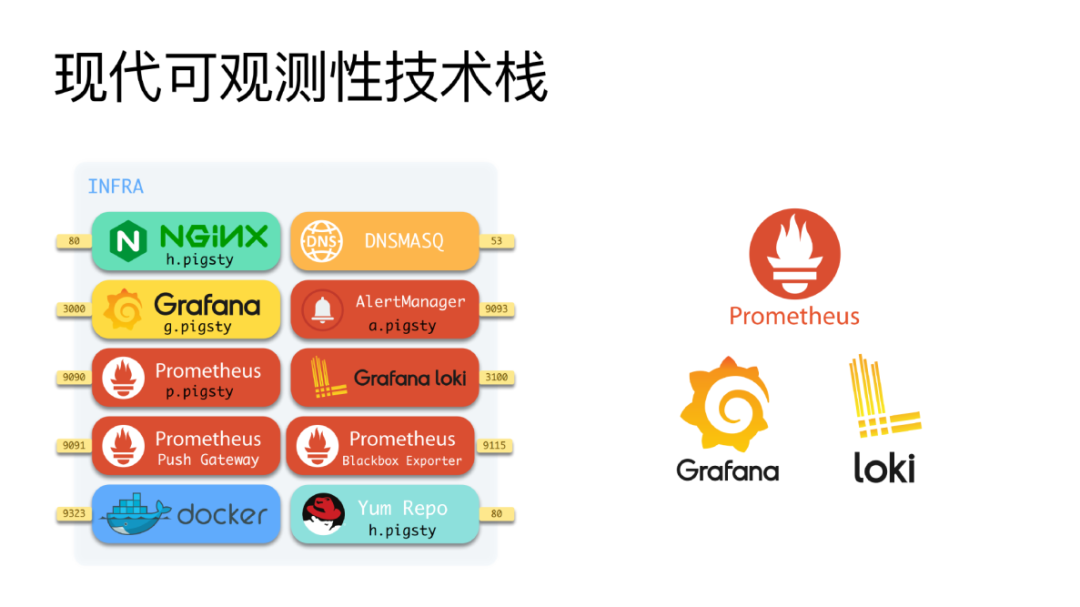
以前大家做监控,可能会用到 Nagios 或者其他的一些监控软件。 现在,以 Prometheus、Grafana、 Loki 为代表的新一代技术栈,已经成了为了可观测性领域的事实标准。在互联网公司上大行其道。
Pigsty 就带有这样一套可观测性的基础设施,包括 Prometheus 全家桶、时序数据库、 Prometheus 推送组件 PushGateway、AlertManager用于告警、黑箱监控 Blackbox Exporter,等等。
Grafana 也有一个全家桶,开源的可视化仪表平台 Grafana,开源的日志存储Loki,后面还有 trace 存储 temper 和指标存储media。这些组件全部已经配置好,开箱即用。

实际上我们有一些用户并不是奔着 PostgreSQL数据库发行版来的,而是奔着这一套开箱性的可观测性组件来的。这里我们把 PostgreSQL的可观测性点全部都列了出来, PG 本身提供了很多的可观测性点,而我们自己编写的 PG Exporter 把这些监控指标全部采集过来。
关于PostgreSQL数据库一项,就有六百种监控指标,还包括主机节点、基础设施自监控,共计约有三四千类的监控指标,而这些监控指标都会被转换为洞察。
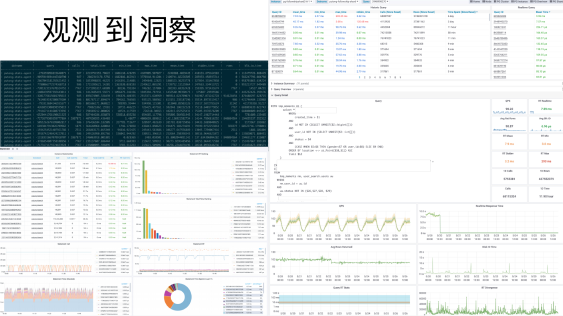
我们更重要的是将这些监控指标汇总成了一个监控面板,其中基本上 30 个 dashboard 分成了很多主题,覆盖了各个不同的topic,经过了很长时间的打磨。从 2019 年开始,在内部我们经过了 10 个大版本的迭代,基本上已经将其打磨到完善的程度了。

可以访问http://demo.pigsty.cc,直接在线交互式体验监控系统的部分。
可观测性部分的内容就是这些,而第二个重要的能力,即为可靠性。
可靠性
可靠性是什么?即使出现问题也可以继续工作。对于玩具系统,我们可以不在乎可靠性,但是生产系统就必须要考虑各种各样的问题,硬件故障、软件故障,人为故障。
硬件故障是很常见的一类故障。而冗余是应对硬件故件的主要手段。在 Pigsty 中,我们使用Patroni和 ETCD 实现了硬件故障自愈。
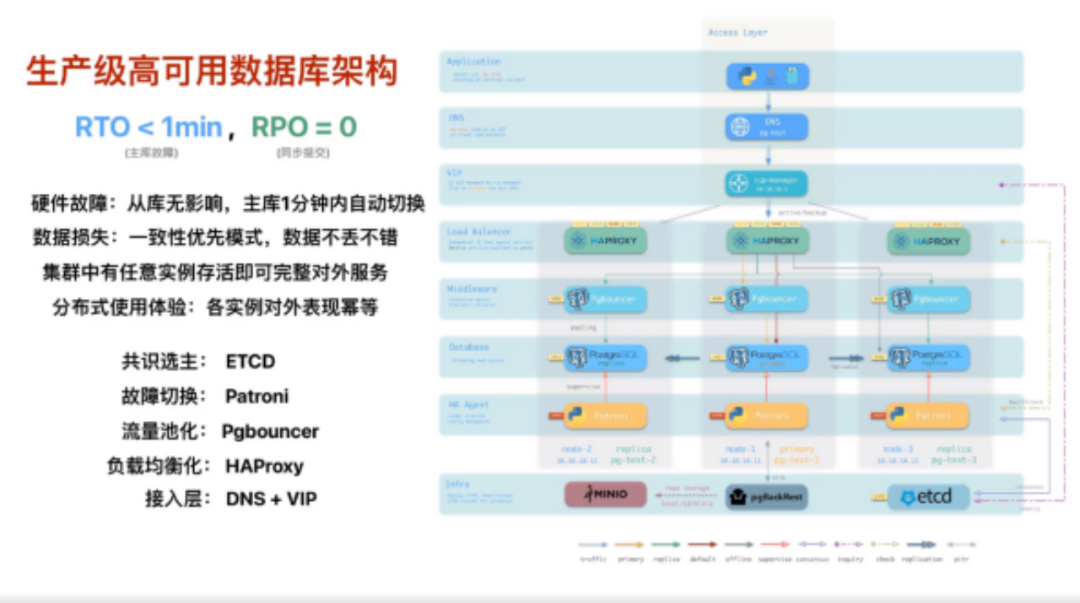
硬件故障自愈是指,如果你不是非常倒霉,一次性整个集群的所有节点全部都挂掉。那么节点故障这种对整个集群的服务不会有什么影响。从库挂了,仅是那一瞬间的的活跃查询会失败。主库挂了,最多会影响 30 秒的写入流量。
故障自愈是一个非常重要的特性。它直接关乎 DBA 的工作生活质量。硬件故障不挑时间,以前DBA可能大半夜接到告警电话,说数据库机器挂了,那么DBA立刻就要火急火燎上线去处理。有了故障自愈后,碰上这种事儿就可以睡个好觉,第二天再慢慢善后。
像这样的一套系统,在我们的生产环境管理了 13000 核的 PostgreSQL数据库,跑了接近三年。十几次的硬件故障全都是高可用系统自己处理,基本无需人工介入。

当然除了硬件故障之外,还有一类故障也免不了会遇到,软件缺陷与人工误操作,俗称删库删表。删库删表这种操作会立刻重放应用到从库副本上,所以硬件冗余对于这类问题无效,需要使用的是冷备份,WAL归档做 PITR 时间点恢复。
但是大家也知道 PITR 配置起来非常复杂,而且需事先规划与准备。
Pigsty为创建的数据库都默认启用了WAL归档,每天一本地备份。使用集中存储仓库 (MinIO/S3)的时候,可以保留更多(默认两周)的全量备份,也就是,用户一键可以回溯到过去两周的任意时间点,而且这个操作还可以高效地、并行地,增量地重复地进行。一键傻瓜式的完成,用户再也不用担心程序员删库跑路了。
这是Pigsty在稳定性做的一些工作。
可用性
上面讲稳定性的时候,我们说到了一个生产环境故障切换的例子。其并不需要DBA或者应用研发人工介入处理,请求流量是自动恢复的。 这是因为我们还设计了一套服务接入机制来保障系统的可用性。
有一些数据库厂商的高可用,数据库自己故障切换完,是不管客户端的,还要求应用自己去修改DNS,修改VIP,然后重启生效。这是一个痛点,所以Pigsty送佛送到西,将客户端接入部分:负载均衡、连接池这些,一并做成开箱即用的架构解决方案。
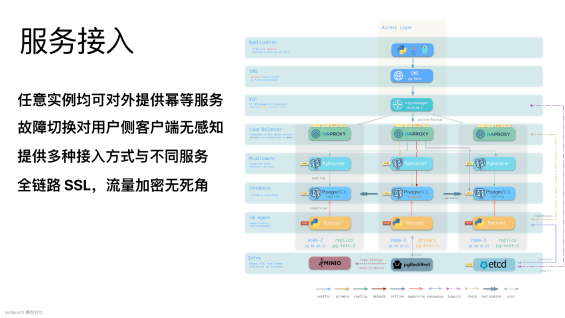
例如,读写分离是一个很常见的需求。Pigsty就通过服务的概念来满足这个需求。
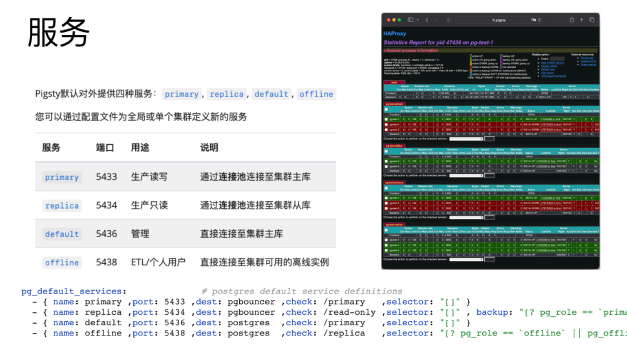
例如默认情况下,所有实例/节点的 5433 端口对外提供读写服务,访问 5433 端口的请求流量全部都会路由到主库, 而 5434 端口则提供只读服务,将流量路由到所有从库上,当所有从库都宕机时,才将主库作为 Backup Server 提供只读服务。
更重要的是,用户可以自己定义新的服务并对外暴露:没有读取延迟的Standby 服务,访问专用ETL实例的 Offline 服务,等等。
所有的这些服务都会通过节点上的 HAPROXY 暴露出去,用户可以通过声明式的配置,或直接使用 HAProxy 提供的管理界面来控制流量。比如,想要摘掉集群中的某一台机器去维护,只要在 HAPROXY ADMIN Page里点一下排干即可,非常直观易用。
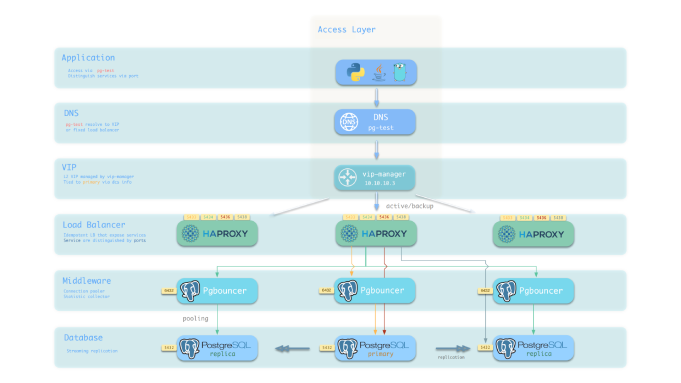
这样有什么好处?以前数据库升级、软件升级这些维护操作需要停机窗口,但是有了这些,我们完全可以在用户无感知的情况下滚动进行,对用户屏蔽这些内部维护的细节,将数据库维护对系统可用性的冲击程度降到最低水平。
整个维护过程中用户都感觉不到数据库有什么异常,所以绝大多数维护工作,甚至整个数据库集群的升级与迁移都可以在无需业务方配合的情况下进行,而不需要停机时间。
这意味着系统的可维护性将有质的飞跃。
可维护性
与“可用”相对应的能力是可管理,可维护。
用好数据库不算太难,管好数据库是很难的。我们的目标就是让普通的研发运维都有能力自助服务,都可以自己上手管好数据库。对于开发者来说,好用不是指 Web 界面上点点鼠标的 ClickOps,而是能用声明式的API精确快速地表达自己的意图和需求,即Infrastructure as Code。
在这一点上, Pigsty 中我们提供了一套类似于 Kubernetes 的声明式API,并且使用 ansible playbook 来实现了一个幂等的控制器逻辑。

不仅仅是数据库本身的创建、修改、扩缩容可以用这种声明式的方法来管理,甚至连数据库内的对象也可以。比如可以用声明式的方法管理 Database 与User。
若想给某一个数据库内装一个扩展,给用户改一个密码,设置一个白名单规则,直接在配置里面声明这些修改,然后也是一行命令,这个配置就生效了。原来要找一个 DBA 专家才能做的事情,现在简单到开发者可自助完成。这是我们在可维护性上,我们做的一个非常重要的事情。

最后,我们还提供了一个沙箱环境,以及 Vagrant和 Terraform模板。你可以用 Vagrant你自己的笔记本上拉起四个节点,一键拉起来,完全仿真一个生产环境的部署。
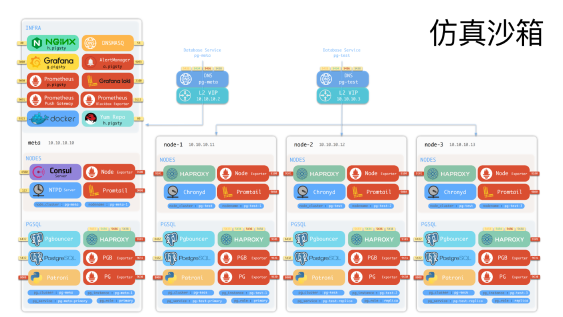
也可以使用 CloudFormation直接在比如 AWS 在各种云上申请这样对应的机器资源来完成 Pigsty的部署。所以 Pigsty 本身可以一键安装部署, 其所需的 IaaS 层资源也可以一键部署,这是在可维护性上Pigsty所做的一些工作。
可扩展性
PG最为人称道的一点即为可扩展性,它的生态里面有很多非常强力的扩展,比如:
- PostGIS 是地理信息数据处理的一个事实标准。
- TimescaleDB 则是一个非常强力的时序数据库扩展。
- Citus是一个被微软收购的插件,它可以将 PG 原地改造为分布式数据库。
除了上述三个核心扩展外,还有 100+ 各式各样的扩展插件。甚至是构建在 PostgreSQL之上的“高层数据库”:比如能够将 PG 提供改造为图数据库的 EdgeDB,让 PG 提供 MongoDB API的 FerretDB,将 PG 改造为 Firebase 的 Supabase,诸如此类,
您可以直接通过Docker模板来为PostgreSQL 加装这些能力,让 PG真正成为一个全能的超融合数据库,这是 PG 的可扩展性。
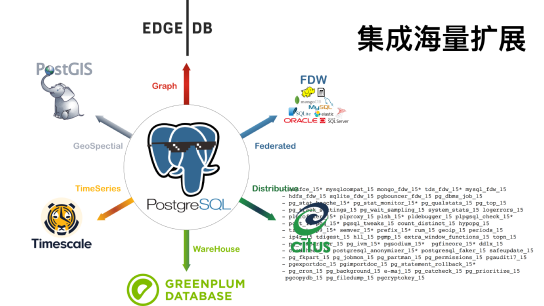
互操作性
最后一个能力就是互操作性,或称可集成性。
PG 虽然是一个足够好的数据库,但它也需要其他组件的配合。
在 Pigsty 中, ETCD 被用作高可用的DCS,所以我们将 ETCD 做成一个模块,高可用ETCD集群的部署与监控,Pigsty也可以完成。MinIO 是一个S3兼容的开源对象存储服务,Pigsty中的PostgreSQL 将其用作一个可选的集中备份仓库,所以我们也做了单节点/多节点 MinIO集群的部署与监控。
除此之外,用户在使用 PG之时,也常常会用到Redis,所以Pigsty也支持高可用 Redis 集群的部署与监控,此外还有 MatrixDB (Greenplum7) 的监控支持,后续我们还会把Kafka、 MySQL 这样几个给做进来。
最后,Pigsty不仅仅是一个 RDS for PostgreSQL,而是一整套完整的开源企业级数据栈:安装各种各样的模块,就可以拉起自己想要的各种各样的数据库。

除了支持多种数据库外,Pigsty还做了很多的应用模板,很多软件都会用到 PostgreSQL数据库,比如像GitLab、Habour、Confluence、Odoo、Jira等。
数据库配置通常是这些软件里最复杂的部分,现在有了 Pigsty 托管的 RDS PG,你只要用 docker-compose 就能一键拉起这些软来。比如,Gitlab企业版和开源版的核心区别就是里面 PostgreSQL 的高可用和监控。

我们还集成了很多工具,比如用来做模式变更的ByteBase,用来做日常管理的PGADMIN4,网页客户端工具PGWeb, 诸如此类,全部都集成了进去。
Pigsty除了用来做监控系统和数据库管控软件,也被用户挖掘出了一些其他用途,比如开发低代码应用和数据可视化。Pigsty里面带了一个Grafana,ECharts面板可以直接用来制作交互式的可视化应用。又可以直接访问 PG 查数据,可以用简单拖拽组件的方式去开发一个原型数据应用。

性能
上述介绍了 6 个方面,不过还少了两个重要的主题,性能和成本。其实, PostgreSQL本身的性能在现代硬件下已非常强悍, Pigsty 做的事情也无非是将其性能潜力全部释放出来。鉴于很多人对现代硬件上的 PG 的性能水平并没有一个直观的概念,这里简单提一下。
响应时间是衡量性能的黄金指标,这是 2020 年代一些操作的典型响应时间:

对于 PostgreSQL而言,一条单行 SELECT 语句在命中内存缓冲区的情况下,耗时大概在 30 微秒,换个角度从吞吐量来看,每个CPU核每秒可以跑 33000 个请求。如果有 100 个核,理论上你的 QPS 最大吞吐量可达 300 万。当然实际上还有一些损耗,所以还要打个 7 折左右。
我自己在 96 核的机器上用 PGBENCH 压测,点查的 QPS 吞吐上限在 200 万请求/秒 附近。而单条写入的吞吐量差不多在 70 万左右的。
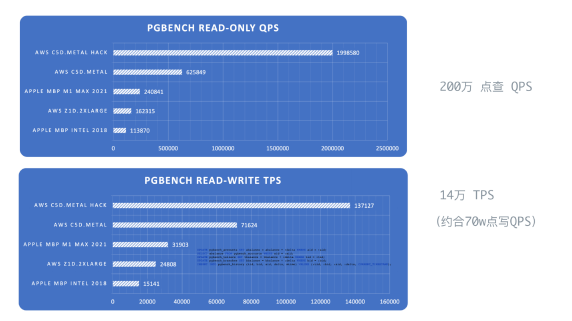
要知道一个头部的互联网应用也就是几百万QPS,12306 抢票TPS峰值也就是 20 来万。所以在现代硬件下,这一台机器它就可以有这么高的 QPS 和TPS 吞吐量,对于绝大多数应用来说,都已绰绰有余。
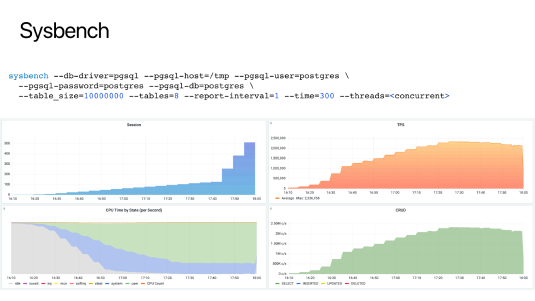
除了PGBENCH 还有一些更通用的测试工具,例如 SYSBENCH。这里我们用它的 point select 场景可以测到 230 万 point select 每秒的量级。下面就是在 AWS 的 C5D Metal 机型上测出来的吞吐-并发曲线。
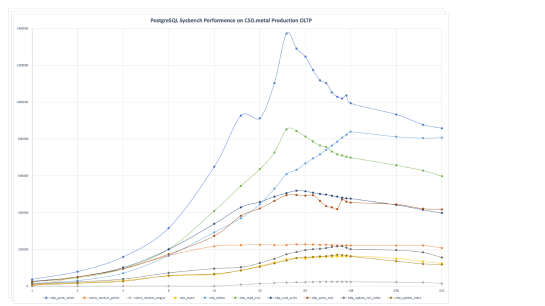
各种查询的吞吐量都可以跑到几十万、一两百万的数量级。所以通常来说,只要表与查询设计得当,PostgreSQL的性能并不是一个问题。
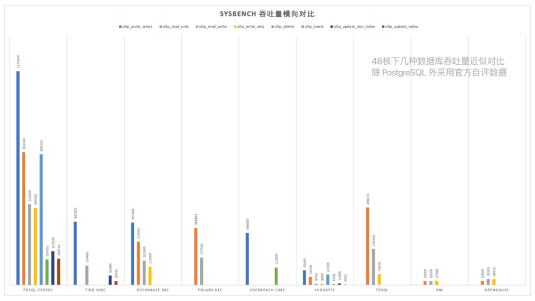
如果我们把其他的一些数据库官网的SYSBENCH结果拉过来放在一起对比,可以发现更有趣的结果,这张图基本里,大家基本都是四十八核左右的测试结果,PostgreSQL 的性能是相当爆炸,冠绝群雄。
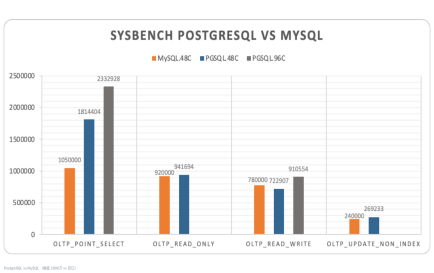
这里特别提一下 PostgreSQL 的老对头 MySQL,除了点查落后一些,MySQL 的性能基本与 PostgreSQL 持平。
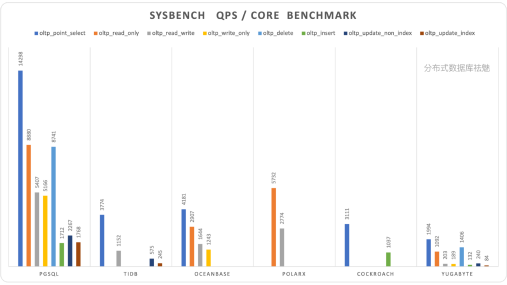
比较让人意外的一些 NewSQL,分布式数据库的性能,基本不论是延迟还是吞吐量,都要普遍打个三折。有很多厂家说分布式数据库是未来,大势所趋,汽车替代马车什么的,不过它们不会说的是,分布式的代价到底是什么。
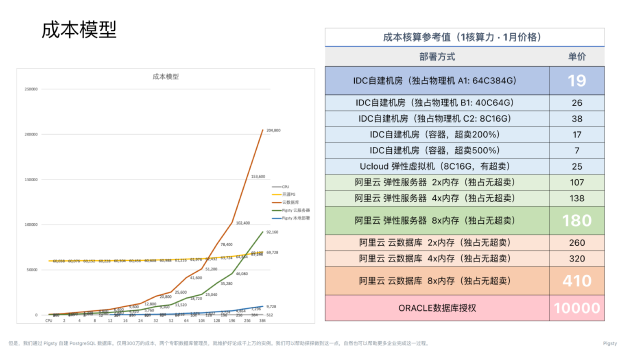
成本
前文简单阐述了性能,最后说一下成本。关于成本,一个最显著的例子就是 Pigsty 最大的用例 —— “TT”。
可以说互联网这个行业,就是建立在免费的开源软件的基础上的。
TT有 13000 核的 PostgreSQL数据库集群与12000 核规模的Redis。单纯就 PostgreSQL而言,这样的规模如果用 Oracle 这样的商业数据库,一年 15 亿的软件授权费就出去了。
如果用 AWS 或是阿里云肯定比 Oracle 便宜,但也要几千万、两三亿。而在 IDC托管代维物理机的基础上,用 Pigsty自建数据库,整个 PostgreSQL 的成本开销含人也就只要500 万, 对一个 13000 核规模的数据库集群来说,可谓是相当便宜了。

Pigsty改写了整个成本模型的函数:比云数据库省钱,而比开源自己折腾省人,用硬件的价格跑起生产级的本地RDS服务。让用户在任何情况下都能更好、更便宜地用好世界上最先进的开源数据库 PostgreSQL。
更重要的是,Pigsty是完全开源免费的自由软件,采用 AGPL v3.0 协议,也提供免费的社区支持和答疑,这一部分主要是靠的是社区专家与用户的情怀用爱发电。
尽管Pigsty 本身旨在用数据库自动驾驶软件替代人肉数据库运维,但再好的软件也没法解决 100% 的问题。优秀的软件可以解决80% 的高频常见问题,但是总会有 20% 的冷门低频疑难杂症,需要专家来介入处理。 这也是为什么我们也提供专业的商业支持与订阅服务,来为有需要的企业级用户使用 PostgreSQL 与 Pigsty 兜底。Pigsty帮助用户用好 PostgreSQL,而我们帮助用户用好 Pigsty。
以上就是 关于 Pigsty 的介绍,我们希望这些工作能够帮助 PostgreSQL 在中国进一步推广普及,让大家都能用好 —— 世界上最先进的开源关系型数据库 PostgreSQL。
|嘉宾介绍|

冯若航
磐吉云数(北京)科技有限责任公司 CEO
冯若航,Pigsty作者,PostgreSQL专家与全栈开发者,PostgreSQL中⽂社区技术委员会委员,磐吉云数科技公司CEO,曾任职于阿⾥巴巴、苹果、探探。译著出版有《PostgreSQL指南:内幕探索》与《设计数据密集型应⽤》中⽂版。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-02-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号