TensorFlow Lite for Microcontroller

TensorFlow Lite for Microcontroller

用户6026865
发布于 2023-03-03 09:18:57
发布于 2023-03-03 09:18:57
The MCU universe
Microcontrollers (MCUs) are the tiny computers that power our technological environment. There are over 30 billion of them manufactured every year, embedded in everything from household appliances to fitness trackers.
If you’re in a house right now, there are dozens of microcontrollers all around you. If you drive a car, there are dozens riding with you on every drive.
Using TensorFlow Lite for Microcontrollers (TFLM), developers can deploy TensorFlow models to many of these devices, enabling entirely new forms of on-device intelligence.

While ubiquitous, microcontrollers are designed to be inexpensive and energy efficient, which means they have small amounts of memory and limited processing power.
A typical microcontroller might have a few hundred kilobytes of RAM, and a 32-bit processor running at less than 100 MHz.
With advances in machine learning enabled by TFLM, it has become possible to run neural networks on these devices.
With minimal computational resources, it is important that microcontroller programs are optimized to run as efficiently as possible. This means making the most of the features of their microprocessor hardware, which requires carefully tuned application code.
Many of the microcontrollers used in popular products are built around Arm’s Cortex-M based processors, which are the industry leader in 32-bit microcontrollers, with more than 47 billion shipped.
Arm’s open source CMSIS-NN library provides optimized implementations of common neural network functions that maximize performance on Cortex-M processors.
This includes making use of DSP and M-Profile Vector Extension (MVE) instructions for hardware acceleration of operations such as matrix multiplication.
Benchmarks for key use cases
Arm’s engineers have worked closely with the TensorFlow team to develop optimized versions of the TensorFlow Lite kernels that use CMSIS-NN to deliver blazing fast performance on Arm Cortex-M cores.
Developers using TensorFlow Lite can use these optimized kernels with no additional work, just by using the latest version of the library. Arm has made these optimizations in open source, and they are free and easy for developers to use today!
The following benchmarks show the performance uplift when using CMSIS-NN optimized kernels versus reference kernels for several key use cases featured in the TFLM example applications.
The tests have been performed on an Arm Cortex-M4 based FPGA platform:
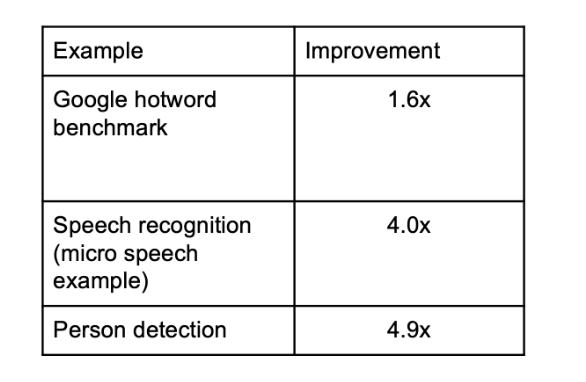
The Arm Cortex-M4 processor supports DSP extensions, that enables the processor to execute DSP-like instructions for faster inference. To improve the inference performance even further, the new Arm Cortex-M55 processor supports MVE, also known as Helium technology.
Improving performance with CMSIS-NN
So far, the following optimized CMSIS-NN kernels have been integrated with TFLM:
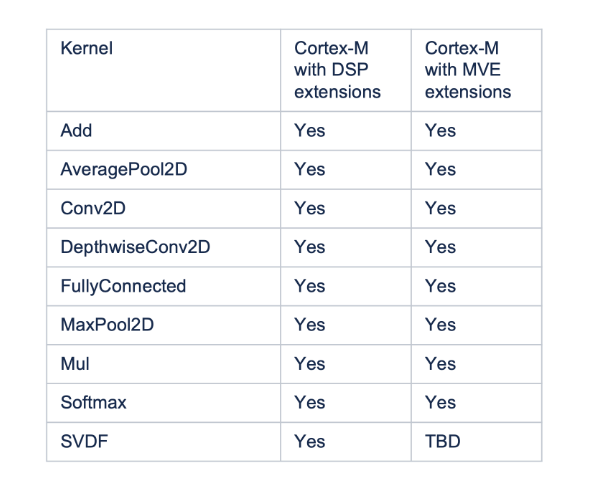
There will be regular updates to the CMSIS-NN library to expand the support of optimized kernels, where the key driver for improving support is that it should give a significant performance increase for a given use case.
For discussion regarding kernel optimizations, a good starting point is to raise a ticket on the TensorFlow or CMSIS Github repository describing your use case.
Most of the optimizations are implemented specifically for 8-bit quantized (int8) operations, and this will be the focus of future improvements.
Next leap in neural processing
Looking ahead into 2021 we can expect a dramatic increase in neural processing from the introduction of devices including a microNPU (Neural Processing Unit) working alongside a microcontroller.
These microNPUs are designed to accelerate ML inference within the constraints of embedded and IoT devices, with devices using the Arm Cortex-M55 MCU coupled with the new Ethos-U55 microNPU delivering up to a 480x performance increase compared to previous microcontrollers.
This unprecedented level of ML processing capability within smaller, power constrained devices will unlock a huge amount of innovation across a range of applications, from smart homes and cities to industrial, retail, and healthcare.
The potential for innovation within each of these different areas is huge, with hundreds of sub segments and thousands of potential applications that will make a real difference to people’s lives.

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-12-12,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 SmellLikeAISpirit 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号