系统性能调优必知必会(1)note

准备知识 Nginx支持QUIC/HTTP3的实现路径和实践思考 | InfoQ公开课 https://www.infoq.cn/video/VPK3Zu0xrv6U8727ZSXB?utm_source=in_album&utm_medium
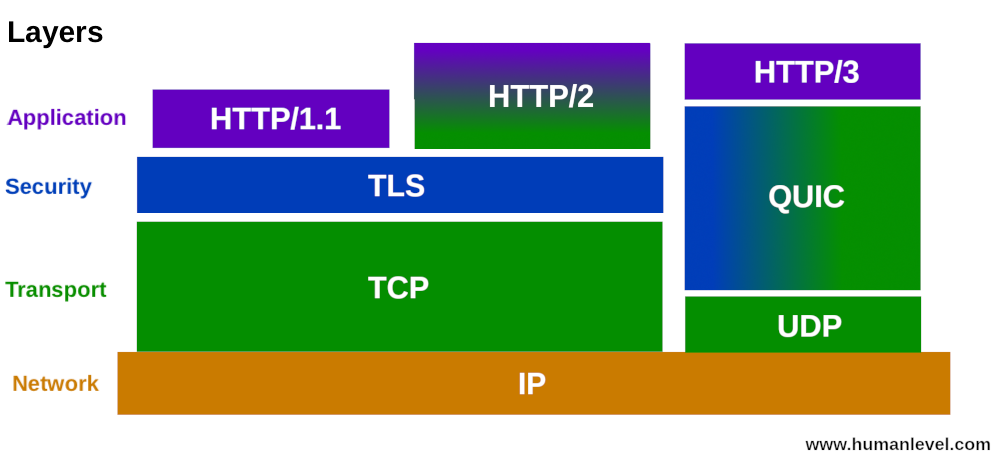
HTTP/2 协议虽然大幅提升了 HTTP/1.1 的性能,然而,基于 TCP 实现的 HTTP/2 遗留下 3 个问题:
- 有序字节流引出的队头阻塞(Head-of-line blocking),使得 HTTP/2 的多路复用能力大打折扣;
旁白:没看懂 搜索http2网上都说他好呀 https 特点 https://blog.csdn.net/zhuyiquan/article/details/52585941】
- TCP 与 TLS 叠加了握手时延,建链时长还有 1 倍的下降空间;
- 基于 TCP 四元组确定一个连接,这种诞生于有线网络的设计,并不适合移动状态下的无线网络,这意味着 IP 地址的频繁变动会导致 TCP 连接、TLS 会话反复握手,成本高昂。
而 HTTP/3 协议恰恰是解决了这些问题:
- HTTP/3 基于 UDP 协议重新定义了连接,在 QUIC 层实现了无序、并发字节流的传输,解决了队头阻塞问题(包括基于 QPACK 解决了动态表的队头阻塞);
- HTTP/3 重新定义了 TLS 协议加密 QUIC 头部的方式,既提高了网络攻击成本,又降低了建立连接的速度(仅需 1 个 RTT 就可以同时完成建链与密钥协商);
- HTTP/3 将 Packet、QUIC Frame、HTTP/3 Frame 分离,实现了连接迁移功能,降低了 5G 环境下高速移动设备的连接维护成本。
所以现在学习 HTTP/3 正当其时,这将是下一代互联网最重要的基础设施。
HTTP/3 协议到底是什么?就像 HTTP/2 协议一样,HTTP/3 并没有改变 HTTP/1 的语义。
那什么是 HTTP 语义呢?
在我看来,它包括以下 3 个点:
- 请求只能由客户端发起,而服务器针对每个请求返回一个响应;
- 请求与响应都由 Header、Body(可选)组成,其中请求必须含有 URL 和方法,而响应必须含有响应码;
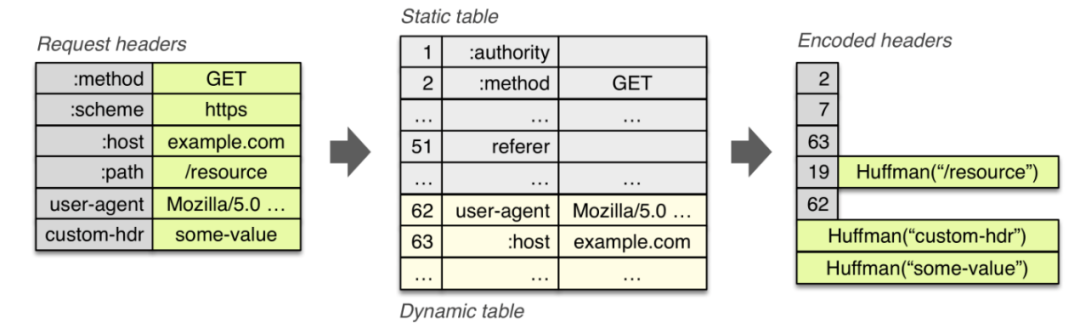
- Header 中各 Name 对应的含义保持不变。HTTP/3 在保持
HTTP/1 语义不变的情况下,更改了编码格式,
这由 2 个原因所致:首先,是为了减少编码长度。下图中 HTTP/1 协议的编码使用了 ASCII 码,用空格、冒号以及 \r\n 作为分隔符,编码效率很低。
- TCP有序,UDP无序;
task02 了解 http1 不支持,http2 和http3 支持多路复用。这个如何理解。
- HTTP/2 与 HTTP/3 都在应用层实现了多路复用功能:
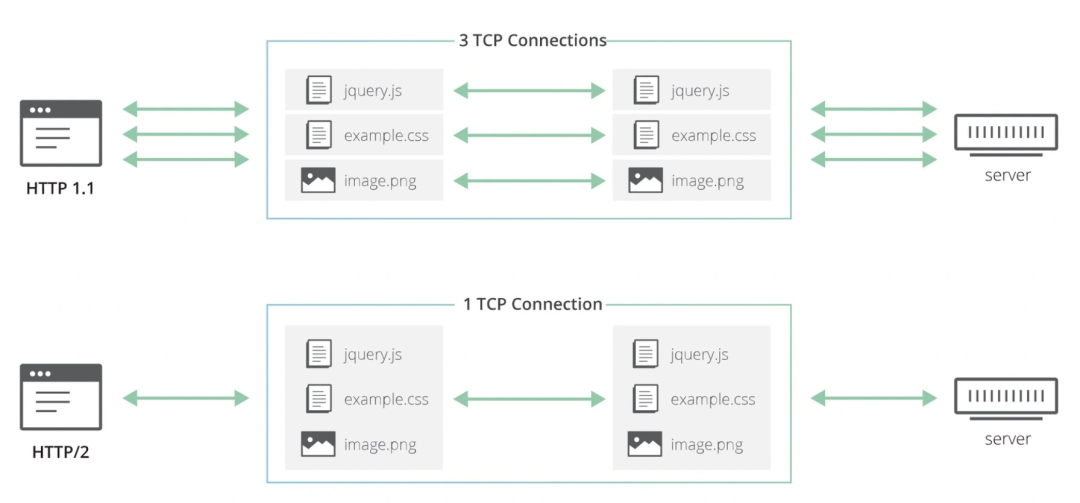
- 白话http2的多路复用:为每个请求,消息,分配一个streamid,然后最后合并-
- 第 15 题:简单讲解一下 http2 的多路复用 #14
- https://github.com/ChuChencheng/note/issues/38 :长连接能减少三次握手,多个请求服用一个连接,但是无法解决队头阻赛问题
task03 ,tcp不是保证安装传输吗?为什么在丢包场景下会出现队头阻塞问题

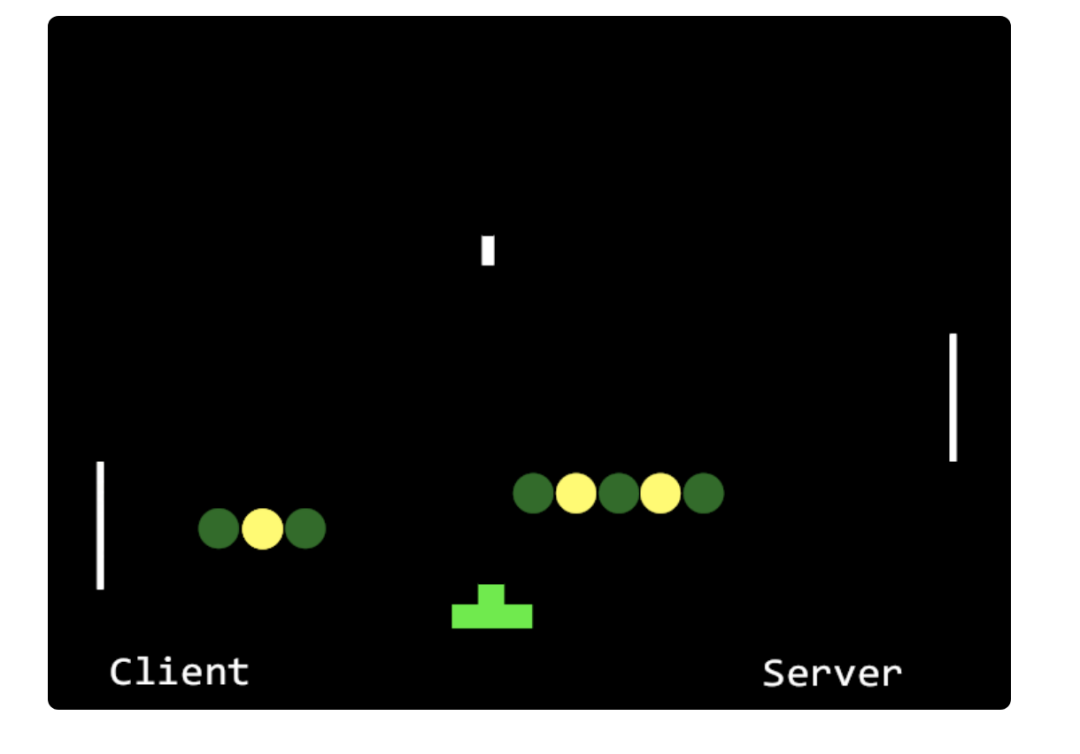
HTTP/2 协议基于 TCP 有序字节流实现,因此应用层的多路复用并不能做到无序地并发,在丢包场景下会出现队头阻塞问题。
如下面的动态图片所示, 服务器返回的绿色响应由 5 个 TCP 报文组成, 而黄色响应由 4 个 TCP 报文组成,
当第 2 个黄色报文丢失后, 即使客户端接收到完整的 5 个绿色报文,
但 TCP 层不允许应用进程的 read 函数读取到最后 5 个报文,并发也成了一纸空谈。
青铜:表示理解不了,为此进行查缺补漏
准备:了解粘包和丢包概念
- tcp粘包与udp丢包的原因 https://www.cnblogs.com/111testing/p/12810253.html
- 所以会造成所谓的粘包, 即前一份Send的数据跟后一份Send的数据可能会暂存到缓冲当中, 然后一起发送。
TCP为了提高传输效率, 发送数据的时候, 并不是直接发送数据到网路, 而是先暂存到系统缓冲, 超过时间或者缓冲满了, 才把缓冲区的内容发送出去, 这样, 就可以有效提高发送效率. 所以会造成所谓的粘包, 即前一份Send的数据跟后一份Send的数据可能会暂存到缓冲当中, 然后一起发送。
- UDP则是面向消息传输的,是有保护消息边界的,接收方一次只接受一条独立的信息,所以不存在粘包问题
应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文, 接收方UDP对下方交上来的UDP用户数据报 ,在去除首部之后就原封不动的交付给上层的应用程序,一次交付一个完整报
udp 没有拆分包文。
- 关于socket TCP丢包 https://bbs.csdn.net/topics/391990426
- tcp 不存在丢包。理解不了
- 神秘的溢出与丢包 [很重要,虽然和上面题目没太多关系] https://k8s.imroc.io/avoid/cases/kubernetes-overflow-and-drop/
- IO 延时较大,从而使 nginx 调用 accept() 变慢,accept queue 溢出,使得大量代理静态图片文件的请求被丢弃,也就导致很多图片加载不出来
- Send-Q 表示 accept queue 最大的大小 accept queue 的最大大小会受 net.core.somaxconn
$ ss -lnt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 129 128 *:80 *:*
If the backlog argument is greater than the value in /proc/sys/net/core/somaxconn, then it is silently
truncated to that value; the default value in this file is 128. In kernels before 2.4.25, this limit was
a hard coded value, SOMAXCONN, with the value 128.
nstat -az | grep -E 'TcpExtListenOverflows|TcpExtListenDrops'
如果 syn queue 满了并且没有开启 syncookies 就丢包,并将 ListenDrops 计数器 +1。
如果 accept queue 满了也会丢包,并将 ListenOverflows 和 ListenDrops 计数器 +1。
- TCP传输协议中如何解决丢包问题【网络传输存在丢包,但是tcp保障了不丢包处理】
为了满足TCP协议不丢包。TCP协议有如下规定:
1. 数据分片:发送端对数据进行分片,接受端要对数据进行重组,由TCP确定分片的大小并控制分片和重组
2. 到达确认:接收端接收到分片数据时,根据分片数据序号向发送端发送一个确认
3. 超时重发:发送方在发送分片时设置超时定时器,如果在定时器超时之后没有收到相应的确认,重发分片数据
4. 滑动窗口:TCP连接的每一方的接受缓冲空间大小固定,接收端只允许另一端发送接收端缓冲区所能接纳的数据,TCP在滑动窗口的基础上提供流量控制,防止较快主机致使较慢主机的缓冲区溢出
5. 失序处理:作为IP数据报来传输的TCP分片到达时可能会失序,TCP将对收到的数据进行重新排序,将收到的数据以正确的顺序交给应用层;
6. 重复处理:作为IP数据报来传输的TCP分片会发生重复,TCP的接收端必须丢弃重复的数据;
7. 数据校验:TCP将保持它首部和数据的检验和,这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收
tak04 还是不理解HTTP队头阻塞时 是什么意思?
总结
- head-of-line blocking
如何解决HTTP队头阻塞
对于HTTP1.1中管道化导致的请求/响应级别的队头阻塞,可以使用HTTP2解决。HTTP2不使用管道化的方式,而是引入了帧、消息和数据流等概念,
每个请求/响应被称为消息,每个消息都被拆分成若干个帧进行传输,每个帧都分配一个序号。每个帧在传输是属于一个数据流, 而一个连接上可以存在多个流,各个帧在流和连接上独立传输,到达之后在组装成消息, 这样就避免了请求/响应阻塞。
当然,即使使用HTTP2,如果HTTP2底层使用的是TCP协议,仍可能出现TCP队头阻塞。
- 如何解决TCP队头阻塞 TCP中的队头阻塞的产生是由TCP自身的实现机制决定的,无法避免。
想要在应用程序当中避免TCP队头阻塞带来的影响,只有舍弃TCP协议。比如google推出的quic协议,在某种程度上可以说避免了TCP中的队头阻塞,因为它根本不使用TCP协议,而是在UDP协议的基础上实现了可靠传输。而UDP是面向数据报的协议,数据报之间不会有阻塞约束。
- 理解TCP序列号(Sequence Number)和确认号(Acknowledgment Number) 表示发送包的数量/接受多少数据包数量
- 应用层无法解决传输层的问题。因此要完全解决队头阻塞问题,需要重新设计和实现传输层。目前而言,真正落地在应用的只看到Google的QUIC(https://www.chromium.org/quic). 它的原理简单讲,就是使用UDP实现了一个可靠的多路复用传输层。
思路:
通过这个文字了解一点 我们在谈论HTTP队头阻塞时,我们在谈论什么?
https://cloud.tencent.com/developer/news/123577
https://juejin.cn/post/6844903853985366023
- https://xzchsia.github.io/2020/08/31/tcp-seq-ack/
https://xzchsia.github.io/2020/08/31/tcp-seq-ack/
https://packetlife.net/blog/2010/jun/7/understanding-tcp-sequence-acknowledgment-numbers/
- To better understand how sequence and acknowledgement numbers are used throughout the duration of a TCP session, we can utilize Wireshark's built-in flow graphing ability. Navigate to Statistics > Flow Graph..., select TCP flow and click OK. Wireshark automatically builds a graphical summary of the TCP flow.【这个看懂了就知道序列号什么意思了】
- TCP协议中的seq/ack序号是如何变化的?
https://segmentfault.com/a/1190000016375111 【翻译版本】
- 一篇带你读懂TCP之“滑动窗口”协议 【还是不懂 有序是啥意思看这个文字】
https://juejin.cn/post/6844903809995505671
- 问题:,一定要等确认包1.我们才能发送第二个包。
- 超时重传 这里有一点要说明:这个Ack是要按顺序的。必须要等到5的Ack收到,才会把6-11的Ack发送过去。这样就保证了滑动窗口的一个顺序
task05: ip发生变化,连接却没有改变,这个怎么做到 【webrtc神奇】
序言
在IoT时代,移动设备接入的网络会频繁变动,从而导致设备IP地址改变。
对于通过四元组(源IP、源端口、目的IP、目的端口)定位连接的TCP协议来说, 这意味着连接需要断开重连,
所以上述2个RTT的建链时延、TCP慢启动都需要重新来过。
而HTTP3的QUIC层实现了连接迁移功能,允许移动设备更换IP地址后, 只要仍保有上下文信息(比如连接ID、TLS密钥等),就可以复用原连接。
思路
- Nginx支持QUIC/HTTP3的实现路径和实践思考 | InfoQ公开课
任务06:http的 head 也可能压缩。
理解
- 字符串怎么压缩 ?--数据结构哈夫曼tree/前缀tree。这里不涉及其他知识
加餐6|分布式系统的本质是什么?
https://time.geekbang.org/column/article/266962
- 如果你的系统需承载的计算量的增长速度大于摩尔定律的预测, 那么在未来的某一个时间点,集中式系统将无法承载你所需的计算量。
2个步骤
- 拆分
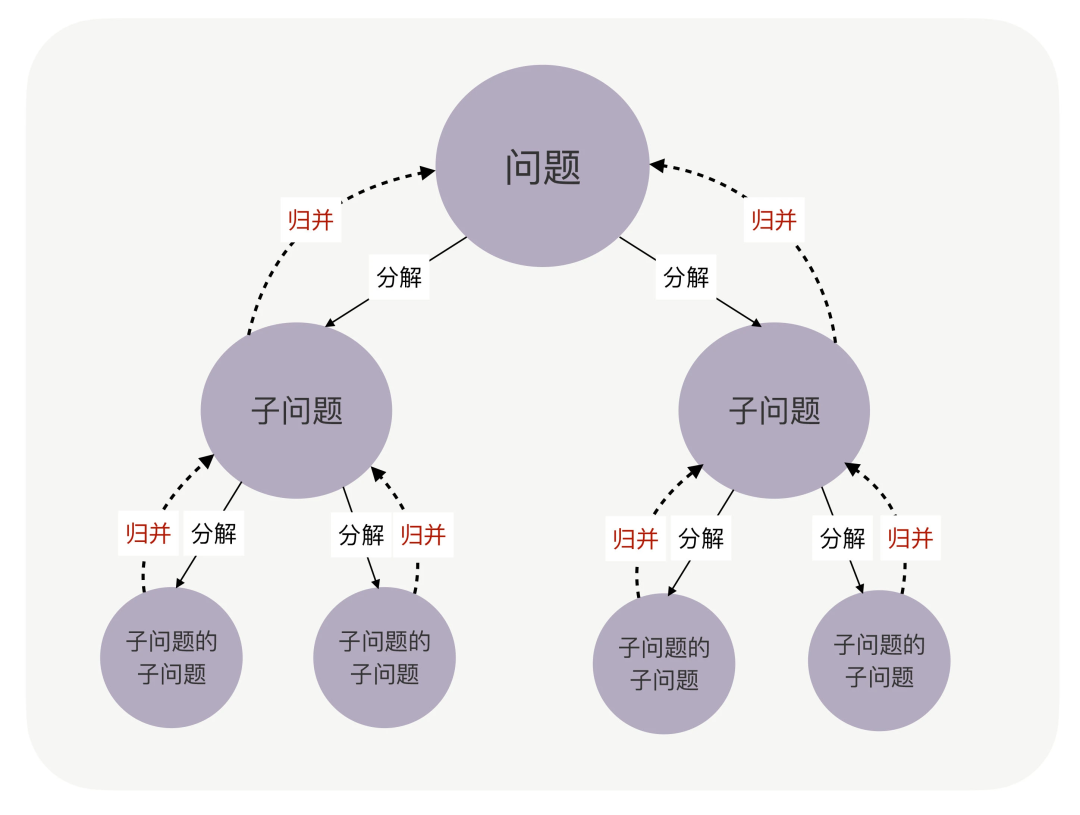
不同分支上的子问题,不能相互依赖,需要各自独立。因为一旦包含了依赖关系,子问题和父问题之间就失去了可以被“归并”的意义。在软件开发领域,我们把这个概念称为“耦合度”和“内聚度”,这两个度量概念非常重要。
- 拆分后在连接起来
如何将拆分后的各个节点再次连接起来,从模式上来说,主要是去中心化与中心化之分
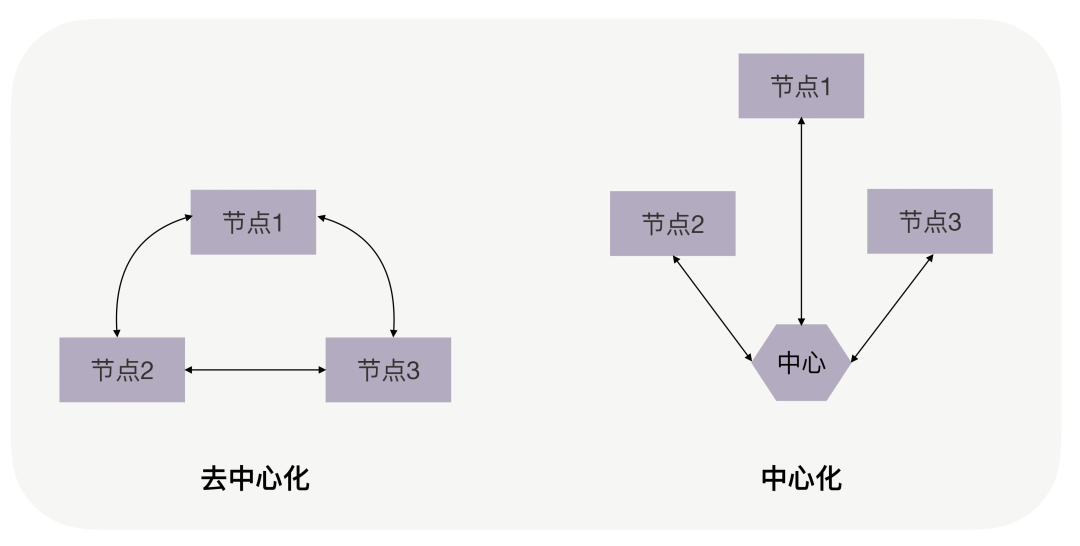
不管系统的规模发展到多大,合理的拆分,加上合适的连接方式, 那么至少会是一个运转顺畅、协作舒服的系统, 至少能够正常发挥分布式系统应有的价值。
加餐5 | 如何理解分布式系统?
- “分布式系统”等于 SOA、ESB、微服务这些东西吗?
- “分布式系统”等于 SOA、ESB、微服务这些东西吗?
维基百科对“分布式系统”的宏观定义是这样的:
分布式系统是一种其组件位于不同的联网计算机上的系统, 然后通过互相传递消息来进行通信和协调。
为了达到共同的目标,这些组件会相互作用。
小结
现在, 我们搞清楚了,看待一个“分布式系统”的时候,内在胜于表象。
以及,只要涉及多个进程协作才能提供一个完整功能的系统, 就是“分布式系统”。