小王职场记 谈谈你的STL理解(1)

第二天 stl的map和hash使用场景
1 随着数据量的增多
- 更快的查找速度 :std::hash_map>std::map
- 更快的插入和删除速度:std::map>std::hash_map
- 更少的存储空间:std::map >std::hash_map
这里就是区别
2 测试查找操作
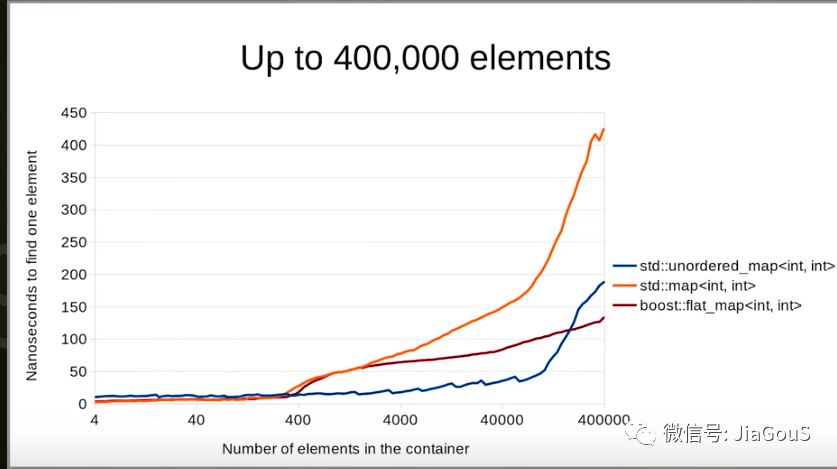
一般 在少量数据情况下 map查找耗时最小,
随着数据的增加,map的查找耗时急剧上升(这里说的一般情况 还有其他因素)
3 测试 插入和删除操作
hash_map(30万) map(30万)
insert: 203 172
delete: 76016 78
hash_map(20万) map(20万)
insert: 156 94
delete:33765 63
hash_map(10万) map(10万)
insert: 93 47
delete: 8422 32
对比数据:
map在instert方面 耗时更少,delte甚至差距更大
STL map , nginx,linux 虚拟内存管理,他们都有红黑树的应用. 当你对搜索的效率要求较高,并且数据经常改动的情景,你可以用红黑树, 也就是 map.
why
整个红黑树的查找,插入和删除都是O(logN)的,原因就是整个红黑树的高度是logN,查找从根到叶,走过的路径是树的高度,删除和插入操作是从叶到根的,所以经过的路径都是logN(这从不命中角度说的 最长路径和最短路径不能超过2倍)
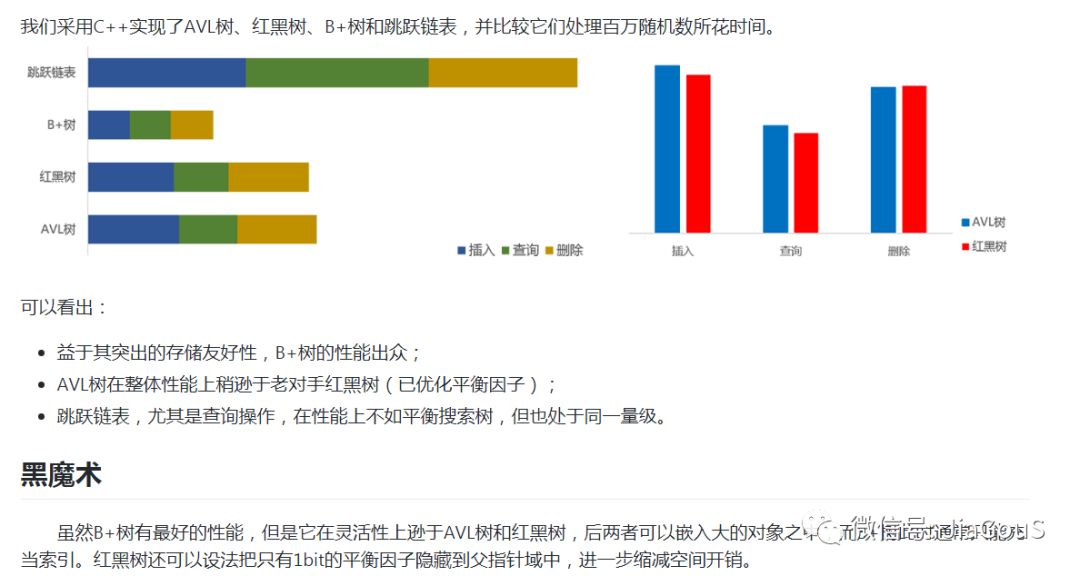
3. hash和map优化空间
- map 占用少内存分析 Void clear(){t.clear();}; //P241页《STL源码剖析》
1,当map中的元素占用内存大小总和小于128字节时,则erase或者clear操作确实不会释放内存(包括虚拟和物理内存)。
2,当元素对象大于或等于128字节,则直接系统调用malloc或者free进行内存的分配(malloc只是分配虚拟内存)
3,只有当对分配的内存区域初始化时,操作系统才会分配物理内存,产生minflt小缺页
glibc内存分配原理
1,当分配块小于128K时,通过brk系统调用控制堆顶往高方向变化。
2,当分配块大于128K时,则通过mmap2和munmap来进行内存的分配和释放的。
具体是否释放进程虚拟地址空间和物理内存,与内存gblic分配策略方式有关,而不是map本身的特性。
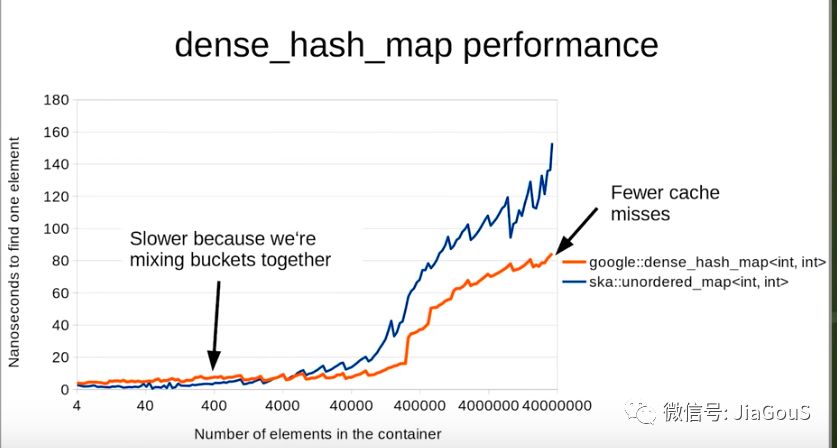
- hash的读取性能的优化
谷歌的google:dense_hash_map耗时更少
4. 什么时候用map,什么时候用hash_map?
分析角度 查找(命中 还是不命中) 插入 和存储空间 这三个方面

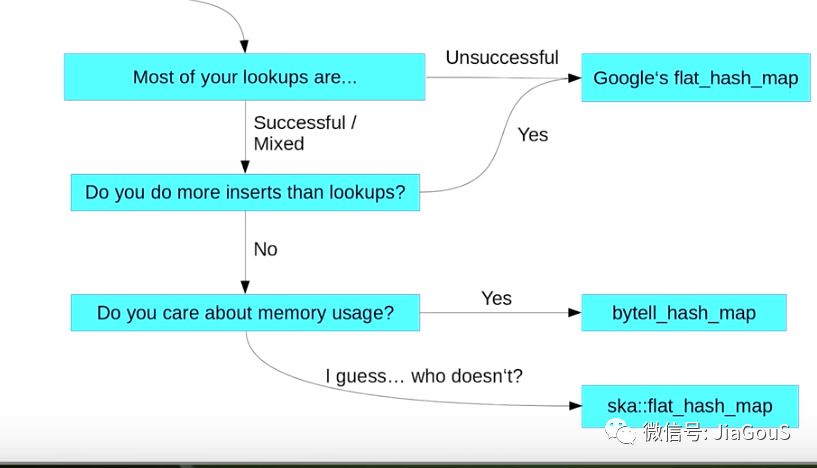
When to choose unordered_map instead of map
- When you have good hasher and no memory limitation
When to choose map instead of unordered_map
- When you need Low Memory:
When you need guaranted Performance
std::map because it will give you guaranteed O(log N).
稳定的。
hash——table o(1)-0(n) 存在扩容现象。5 塔山
- https://discuss.fogcreek.com/joelonsoftware/default.asp?cmd=show&ixPost=22948
- 测试数据 http://stlavlmap.sourceforge.net/
- 测试数据 https://github.com/rcarbone/kudb
- map容器clear操作不会释放内存?
- STL源码剖析
重要的学会用benchmark工具测试 各种容器,不需要记住最后结论
测试方法:https://github.com/rcarbone/kudb
回顾:
扩展
压力测试:观察缺页中断情况
执行一次只有一个结果
ps -o majflt,minflt -p 1731
一直监控 知道手工终结
strace -T -ttt -c -p 1731
pidstat - Report statistics for Linux tasks.
pidstat -r -p 1731 5
熟练度:
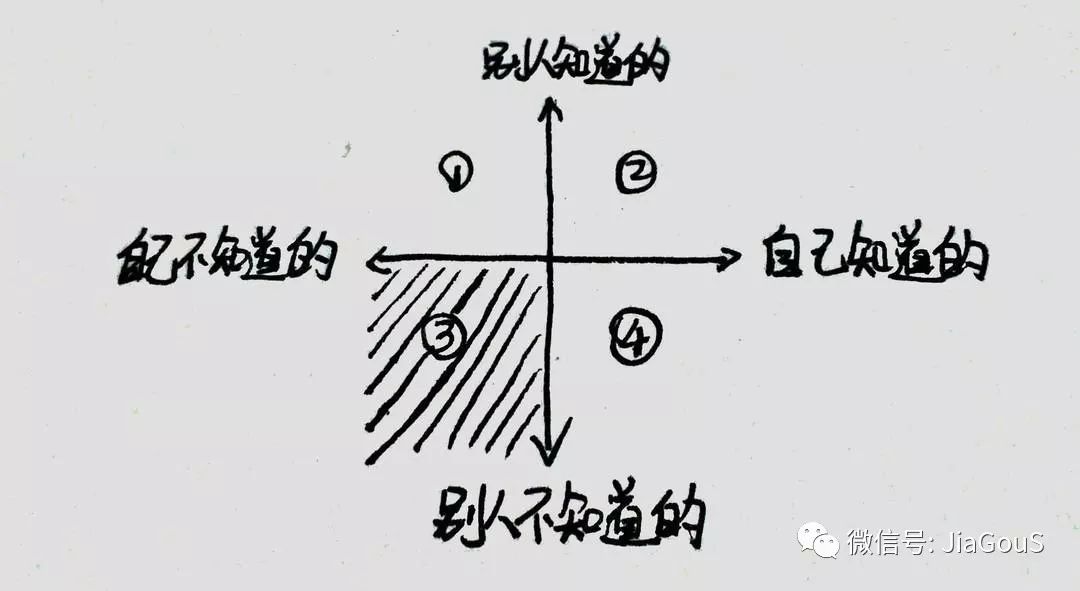
目前处于第一想象 自己不知道,别人知道,该如何办呢? 求讨论