在 PyTorch 中使用梯度检查点在GPU 上训练更大的模型

在 PyTorch 中使用梯度检查点在GPU 上训练更大的模型

数据派THU
发布于 2023-03-29 10:55:45
发布于 2023-03-29 10:55:45

来源:Deephub Imba
本文约3200字,建议阅读7分钟
本文将介绍解梯度检查点(Gradient Checkpointing),这是一种可以让你以增加训练时间为代价在 GPU 中训练大模型的技术。我们将在 PyTorch 中实现它并训练分类器模型。
作为机器学习从业者,我们经常会遇到这样的情况,想要训练一个比较大的模型,而 GPU 却因为内存不足而无法训练它。当我们在出于安全原因不允许在云计算的环境中工作时,这个问题经常会出现。在这样的环境中,我们无法足够快地扩展或切换到功能强大的硬件并训练模型。并且由于梯度下降算法的性质,通常较大的批次在大多数模型中会产生更好的结果,但在大多数情况下,由于内存限制,我们必须使用适应GPU显存的批次大小。

梯度检查点
在反向传播算法中,梯度计算从损失函数开始,计算后更新模型权重。图中每一步计算的所有导数或梯度都会被存储,直到计算出最终的更新梯度。这样做会消耗大量 GPU 内存。梯度检查点通过在需要时重新计算这些值和丢弃在进一步计算中不需要的先前值来节省内存。
让我们用下面的虚拟图来解释。
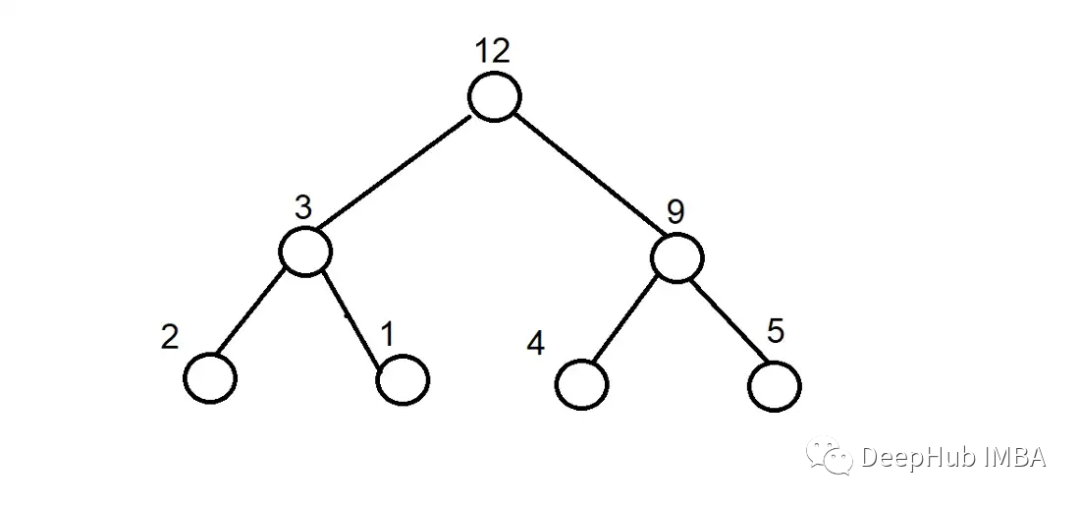
上面是一个计算图,每个叶节点上的数字相加得到最终输出。假设这个图表示反向传播期间发生的计算,那么每个节点的值都会被存储,这使得执行求和所需的总内存为7,因为有7个节点。但是我们可以用更少的内存。假设我们将1和2相加,并在下一个节点中将它们的值存储为3,然后删除这两个值。我们可以对4和5做同样的操作,将9作为加法的结果存储。3和9也可以用同样的方式操作,存储结果后删除它们。通过执行这些操作,在计算过程中所需的内存从7减少到3。
在没有梯度检查点的情况下,使用PyTorch训练分类模型
我们将使用PyTorch构建一个分类模型,并在不使用梯度检查点的情况下训练它。记录模型的不同指标,如训练所用的时间、内存消耗、准确性等。
由于我们主要关注GPU的内存消耗,所以在训练时需要检测每批的内存消耗。这里使用nvidia-ml-py3库,该库使用nvidia-smi命令来获取内存信息。
pip install nvidia-ml-py3为了简单起见,我们使用简单的狗和猫分类数据集的子集。
git clone https://github.com/laxmimerit/dog-cat-full-dataset.git执行上述命令后会在dog-cat-full-dataset的文件夹中得到完整的数据集。
导入所需的包并初始化nvdia-smi
import torch import torch.nn as nn import torch.optim as optim import numpy as np from torchvision import datasets, models, transforms import matplotlib.pyplot as plt import time import os import cv2 import nvidia_smi import copy from PIL import Image from torch.utils.data import Dataset,DataLoader import torch.utils.checkpoint as checkpoint from tqdm import tqdm import shutil from torch.utils.checkpoint import checkpoint_sequential device="cuda" if torch.cuda.is_available() else "cpu" %matplotlib inline import random nvidia_smi.nvmlInit()导入训练和测试模型所需的所有包。我们还初始化nvidia-smi。
定义数据集和数据加载器
#Define the dataset and the dataloader. train_dataset=datasets.ImageFolder(root="/content/dog-cat-full-dataset/data/train", transform=transforms.Compose([ transforms.RandomRotation(30), transforms.RandomHorizontalFlip(), transforms.RandomResizedCrop(224, scale=(0.96, 1.0), ratio=(0.95, 1.05)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]))
val_dataset=datasets.ImageFolder(root="/content/dog-cat-full-dataset/data/test", transform=transforms.Compose([ transforms.Resize([224, 224]), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), ]))
train_dataloader=DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=2)
val_dataloader=DataLoader(val_dataset, batch_size=64, shuffle=True, num_workers=2)这里我们用torchvision数据集的ImageFolder类定义数据集。还在数据集上定义了某些转换,如RandomRotation, RandomHorizontalFlip等。最后对图片进行归一化,并且设置batch_size=64。
定义训练和测试函数
def train_model(model,loss_func,optimizer,train_dataloader,val_dataloader,epochs=10):
model.train() #Training loop. for epoch in range(epochs): model.train() for images, target in tqdm(train_dataloader): images, target = images.to(device), target.to(device) images.requires_grad=True optimizer.zero_grad() output = model(images) loss = loss_func(output, target) loss.backward() optimizer.step() if os.path.exists('grad_checkpoints/') is False: os.mkdir('grad_checkpoints') torch.save(model.state_dict(), 'grad_checkpoints/epoch_'+str(epoch)+'.pt')
#Test the model on validation data. train_acc,train_loss=test_model(model,train_dataloader) val_acc,val_loss=test_model(model,val_dataloader) #Check memory usage. handle = nvidia_smi.nvmlDeviceGetHandleByIndex(0) info = nvidia_smi.nvmlDeviceGetMemoryInfo(handle) memory_used=info.used memory_used=(memory_used/1024)/1024
print(f"Epoch={epoch} Train Accuracy={train_acc} Train loss={train_loss} Validation accuracy={val_acc} Validation loss={val_loss} Memory used={memory_used} MB")
def test_model(model,val_dataloader): model.eval() test_loss = 0
correct = 0 with torch.no_grad(): for images, target in val_dataloader: images, target = images.to(device), target.to(device) output = model(images) test_loss += loss_func(output, target).data.item() _, predicted = torch.max(output, 1) correct += (predicted == target).sum().item()
test_loss /= len(val_dataloader.dataset)
return int(correct / len(val_dataloader.dataset) * 100),test_loss上面创建了一个简单的训练和测试循环来训练模型。最后还通过调用nvidia-smi计算内存使用。
训练
torch.manual_seed(0)
#Learning rate. lr = 0.003
#Defining the VGG16 sequential model. vgg16=models.vgg16() vgg_layers_list=list(vgg16.children())[:-1] vgg_layers_list.append(nn.Flatten()) vgg_layers_list.append(nn.Linear(25088,4096)) vgg_layers_list.append(nn.ReLU()) vgg_layers_list.append(nn.Dropout(0.5,inplace=False)) vgg_layers_list.append(nn.Linear(4096,4096)) vgg_layers_list.append(nn.ReLU()) vgg_layers_list.append(nn.Dropout(0.5,inplace=False)) vgg_layers_list.append(nn.Linear(4096,2)) model = nn.Sequential(*vgg_layers_list) model=model.to(device)
#Num of epochs to train num_epochs=10
#Loss loss_func = nn.CrossEntropyLoss()
# Optimizer # optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=1e-5) optimizer = optim.SGD(params=model.parameters(), lr=0.001, momentum=0.9)
#Training the model. model = train_model(model, loss_func, optimizer, train_dataloader,val_dataloader,num_epochs)我们使用VGG16模型进行分类。下面是模型的训练日志。

可以从上面的日志中看到,在没有检查点的情况下,训练64个批大小的模型大约需要5分钟,占用内存为14222.125 mb。
使用带有梯度检查点的PyTorch训练分类模型
为了用梯度检查点训练模型,只需要编辑train_model函数。
deftrain_with_grad_checkpointing(model,loss_func,optimizer,train_dataloader,val_dataloader,epochs=10):
#Training loop. for epoch in range(epochs): model.train() for images, target in tqdm(train_dataloader): images, target = images.to(device), target.to(device) images.requires_grad=True optimizer.zero_grad() #Applying gradient checkpointing segments = 2 # get the modules in the model. These modules should be in the order # the model should be executed modules = [module for k, module in model._modules.items()]
# now call the checkpoint API and get the output output = checkpoint_sequential(modules, segments, images) loss = loss_func(output, target) loss.backward() optimizer.step() if os.path.exists('checkpoints/') is False: os.mkdir('checkpoints') torch.save(model.state_dict(), 'checkpoints/epoch_'+str(epoch)+'.pt')
#Test the model on validation data. train_acc,train_loss=test_model(model,train_dataloader) val_acc,val_loss=test_model(model,val_dataloader)
#Check memory. handle = nvidia_smi.nvmlDeviceGetHandleByIndex(0) info = nvidia_smi.nvmlDeviceGetMemoryInfo(handle) memory_used=info.used memory_used=(memory_used/1024)/1024
print(f"Epoch={epoch} Train Accuracy={train_acc} Train loss={train_loss} Validation accuracy={val_acc} Validation loss={val_loss} Memory used={memory_used} MB")
def test_model(model,val_dataloader): model.eval() test_loss = 0 correct = 0 with torch.no_grad(): for images, target in val_dataloader: images, target = images.to(device), target.to(device) output = model(images) test_loss += loss_func(output, target).data.item() _, predicted = torch.max(output, 1) correct += (predicted == target).sum().item()
test_loss /= len(val_dataloader.dataset)
return int(correct / len(val_dataloader.dataset) * 100),test_lossdeftest_model(model,val_dataloader)我们将函数名修改为train_with_grad_checkpointing。也就是不通过模型(图)运行训练,而是使用checkpoint_sequential函数进行训练,该函数有三个输入:modules, segments, input。modules是神经网络层的列表,按它们执行的顺序排列。
segments是在序列中创建的段的个数,使用梯度检查点进行训练以段为单位将输出用于重新计算反向传播期间的梯度。本文设置segments=2。input是模型的输入,在我们的例子中是图像。这里的checkpoint_sequential仅用于顺序模型,对于其他一些模型将产生错误。
使用梯度检查点进行训练,如果你在notebook上执行所有的代码。建议重新启动,因为nvidia-smi可能会获得以前代码中的内存消耗。
torch.manual_seed(0)
lr = 0.003
# model = models.resnet50() # model=model.to(device)
vgg16=models.vgg16() vgg_layers_list=list(vgg16.children())[:-1] vgg_layers_list.append(nn.Flatten()) vgg_layers_list.append(nn.Linear(25088,4096)) vgg_layers_list.append(nn.ReLU()) vgg_layers_list.append(nn.Dropout(0.5,inplace=False)) vgg_layers_list.append(nn.Linear(4096,4096)) vgg_layers_list.append(nn.ReLU()) vgg_layers_list.append(nn.Dropout(0.5,inplace=False)) vgg_layers_list.append(nn.Linear(4096,2)) model = nn.Sequential(*vgg_layers_list) model=model.to(device)
num_epochs=10
#Loss loss_func = nn.CrossEntropyLoss()
# Optimizer # optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=1e-5) optimizer = optim.SGD(params=model.parameters(), lr=0.001, momentum=0.9)
#Fitting the model.
model = train_with_grad_checkpointing(model, loss_func, optimizer, train_dataloader,val_dataloader,num_epochs)输出如下:

从上面的输出可以看到,每个epoch的训练大约需要6分45秒。但只需要10550.125 mb的内存,也就是说我们用时间换取了空间,并且这两种情况下的精度都是79,因为在梯度检查点的情况下模型的精度没有损失。
总结
梯度检查点是一个非常好的技术,它可以帮助在小显存的情况下完整模型的训练。经过我们的测试,一般情况下梯度检查点会将训练时间延长20%左右,但是时间长点总比不能用要好,对吧。
本文的源代码:
https://medium.com/geekculture/training-larger-models-over-your-average-gpu-with-gradient-checkpointing-in-pytorch-571b4b5c2068
编辑:王菁
校对:林亦霖

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-02-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号