全国维吾尔语分词技术比赛斩获冠军系统窥密

全国维吾尔语分词技术比赛斩获冠军系统窥密

TEG云端专业号
发布于 2023-03-30 16:10:53
发布于 2023-03-30 16:10:53

题记:
2017年9月25日,第十六届少数民族语言文字信息处理学术研讨会维吾尔语分词技术评测结果公布,TEG以“腾讯基础研发部”名义参赛系统超越了新疆大学,北京大学青鸟,中科院自动化所等10余家队伍,获得了本次竞赛评测第一名,在召回率不变的前提下,准确率超越第二名系统22%,取得绝对领先。
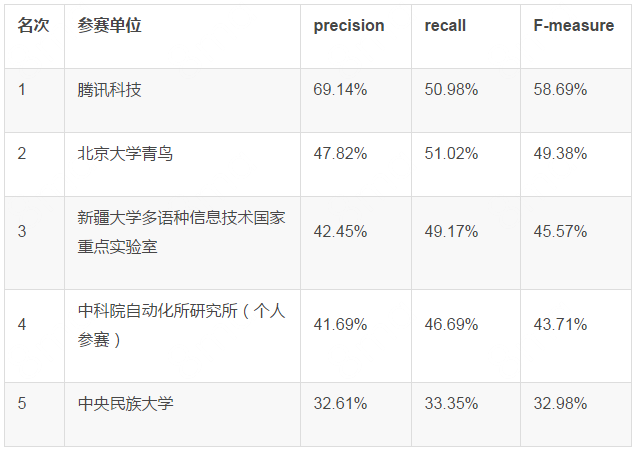
表1. 比赛结果前五名



巴别塔的渴望:
"这里是新疆是我的家乡,他广阔美丽天生他就是这样。喀纳斯的湖水映着晚霞泛着银光,塔里木河在沙漠中间流淌,我想我渴望我歌唱我绽放,在我出生的这片土地上歌唱。我登高眺望感受吐鲁番的阳光,看着天山山脉绵延万里伸向远方…."

每当唱起这首《这里是新疆》时,我总是心潮澎湃。虽然自己是个汉族人,但从中科院自动化所读硕博起,我就经常从事涉疆的语音项目,更多的是汉语语音识别,目的是使得民族地区的同胞能够更好地利用语音评测技术学习汉语。那时,在南疆和田和喀什地区一呆就是三个月,沙漠绿洲的淳朴民风和新疆的饕餮美食让我终身难忘。但是,平淡的生活中也有迷茫,其中无法交流是最大的屏障,在南疆这个90%以上维族同胞的地区,汉语的普及率只有36%。
多年来我的一个梦想,就是能够打造维吾尔语和汉语的巴别塔,使得这个中国第二大语言可以和汉语流利地通过语音交流。来到鹅厂后,这个愿望更加迫切,尤其是在鹅厂这个第一大社交平台,腾讯肩负的使命也更为巨大。如果能够实现维吾尔语语音的转写和翻译,是一件有助于民族和谐和交流的事情;其次,社交平台上存在着大量的不法信息,暴恐信息,如果我们能够通过语音识别技术和自然语言翻译技术将这些信息得到解码,推送到人工审核,势必可以高效地发现和举报高危事件,保障腾讯各个社交平台的信息安全,保障民生和社会的长治久安。
自汉语语音识别各项技术落地之后,腾讯基础研发部从2017年3月份开始启动维吾尔语语音识别项目,项目启动以后,冒着天寒地冻,和维语专家 loganzhang, jinronggu远赴新疆,白天采集语音语料素材,夜晚制订第二天的数据收集改进策略,每天都奋战到2点才睡。在广袤的边疆大地上,和各个高校的维族同胞进行自由对话交流和采音,搜集维吾尔语聊天的语音和文本素材。短短2周内,收集了上千小时的维吾尔语语音和几十万句的文本素材,为自研的维吾尔语识别技术研发奠定了基础。很多新疆同胞握着我们的手说:“真希望腾讯能够在维吾尔语上做一些研发,促进民族交流,使得民族同胞更好地像石榴籽一样团结在一起”。


维语其实是很难学的。无穷的词汇、小舌音、卷舌音和气声音,这都是汉语里所没有的,更困难的是那些大致与汉语的音素相近的音……语法就更麻烦了,什么名词的六个格,动词的时、态、人称附加成份……真是怎么复杂怎么来呀!而它们又是那样使我倾心,使我迷恋。它们和所有的能歌善舞的维吾尔人联结在一起。它们和吐鲁番的挂和葡萄、伊犁和焉耆的骏马、英吉沙的腰刀,喀什的大清真寺和香妃墓、和田的玉石与地毯连接在一起......
所以,训练一个好的维吾尔语识别系统,绝不是简单的把数据堆砌上去然后调用开源的训练库这样简单。为此,我们决定采用自研的维语语音识别算法,和汉语不同,维吾尔语的构形附加成分很丰富,名词有数、从属人称、格等语法范畴。动词有态 、肯定否定、语气、时、人称、数、形动词、动名词、副动词等语法范畴。表示各种情态的动词很发达。词汇中除有突厥语族诸语言的共同词外,还有一定数量的汉语、阿拉伯语、波斯语和俄语的借词。如果将所有的词汇都和盘托出,建立在语音识别的发音词典模型中,势必会造成词典模型的爆量。同时,训练语言模型时,由于词汇量过大,对应词汇的简单连接关系会变得充满变化,导致PPL(语言模型困惑度)的下降,这就使得语言模型的可靠性打了一分折扣。
研发出一套专门针对维吾尔语特点的音转文识别系统是有难度的。不同于汉语识别,维吾尔语识别可参考的资料非常少,目前只有科大讯飞和新疆大学等少数单位投入了一些试验性的研究和应用。我们在拿到问题后,针对维语的特殊性和与其他语言的共性。我们决定从词典模型,语言模型,声学模型,和前端四个语音识别中常见的模块下手。
1) 在词典模型上,进行了核心利器------维吾尔语分词技术的研发,以及从大数据里建立口语化维吾尔语词汇的发音词典,以及专门适应维语发音变异的G2P模型;
2) 在语言模型上,由于信安场景对识别精度和召回率的高要求,这里采用维语分词和stemming后的n-gram模型编译成WFST网络;一遍 HCLG 网络识别后,再用另一个海量数据里训练得到的超大 stemming LSTM WFST网络对识别出的 lattice 做二次 rescore;
3) 在声学模型这个语音识别最核心的模块上,我们采用了对海量纯净维语数据进行真实互联网场景下的多信道(采样率,远近场,低质量编解码,声学环境)声学模拟,之后基于Lattice free-MMI区分度准则在多层TDNN-BLSTM的网络上通过chain model HMM框架进行训练;
4) 在前端,由于新疆地区的语音场景更加开放和低质量,针对单通道的用户可能发送的任何信道下的音频,采用基于CNN-LSTM的端点切分和单通道降噪增强技术,使得只有增强后的语音部分进入到维吾尔语语音识别器;
在几个月的努力下,团队在维吾尔语一般信道下16K语音识别WER目前做到了10%以下。当然,针对互联网复杂的信道场景,和开放式的口语交谈场景,我们还有很长的路要走.... 下面,作为本次维语识别技术系列文章的第一弹,我们就系统中维语语言模型和词典模型中的重要模块——分词技术参加全国维吾尔语分词比赛的情况做以下小结:
一曲菱歌敌万金——参加全国比赛
系统做出,我们在词典建模方面也总结出了一套技术解决方案。 恰逢今年第十六届少数民族语言文字信息处理学术研讨会(MLWS2017)在广西桂林市召开。本大赛是中国中文信息学会举办,全国在民族语音语言领域最有权威价值的会议,今年的special session是民族语言自动分词评测,涉及到维吾尔语,藏语,蒙语三种主要民族语言。其中我们的系统参加了维吾尔语的部分,这部分的参赛队伍有10多个,其中不乏新疆大学,中科院自动化所,中央民族大学等实力队伍。作为母语的研究,其中新疆大学在这个领域的研发已经超过20年 [文献 1-6],拥有绝对实力;而科大多年来实力雄厚,在今年两会期间还给李克强总理展示了维吾尔语识别和翻译系统,和其依托的中国科技大学提供的强有力支持分不开;中科院自动化所作为近年来维语研究的一匹黑马,在这个方向上也有很多不俗的应用。面对强有力的对手,我们加班加点,一边训练系统,一边结合手上数据提供方“慧听科技”的数据,分析解决方案。在deadline当天,怀着忐忑的心情提交了系统。
结果如愿以偿,正如文章开头所述,我们取得了第一名。下面我们将冠军系统的技术做以下深度解析,以飨读者。
抽丝剥茧,深度剖析技术:
不同于以往计算复杂的诸如基于CRF等的维语分词系统,本系统的追求是速度和简单易用。系统主要针对维吾尔语词进行音节和词干、附加成分的切分问题。本系统设计了三个主要模块:bigram语言模型、词性特征筛选和上下文词干信息viterbi解码 [5]。通过这三个模块完成了维语的基本词干提取,最后通过规则方法解决部分词切分不准确和冗余切分的情况。
1. 为什么要做维语分词:
维吾尔语(以下简称维语)属于阿尔泰语系突厥语族,是拼音文字。词是维语中的最小的能独立运用的语言单位,词与词之间有空格分隔开,不存在像汉语中的分词问题。但存在对词进行音节和词干、附加成分的切分问题。因此,在维语文本的词自动切分时,切分单位的确定是一个关键而困难的问题。维语词的切分还处于研究阶段,维语词的自动切分是维语语音识别的一个十分重要的环节,不仅如此,也是涉维吾尔语机器翻译,自动结对,智能检索等的基础处理工作之一。
维语作为黏着语,它的语法形式都是通过在单词原形的后面或前面添加一定的附加成分来完成的。这就造成在真实维语文本中,一个维语词对应多个字符串的形式。由于词典的规模是有限的,所以这些不同的形式不可能都录用在词典中。因此又必须找出词干与相应的附加成分的关系。并且,维语词切分中,除了词干提取之外还要进行词缀的切分。这是因为构形附加成分与词干互相黏连,并且构形附加成分也相互黏连。构形附加成分往往可以表示一定词汇意义或语法意义,所以,如果不将这些黏连在一起的构形附加成分完整的切分开,就不能准确地领会整个单词的含义。并且,构形附加成分还能表示词与词的关系。所以,切分构形附加成分是很有必要的。同时,构形附加成分的切分对句法分析、语义分析、语用分析等更深层的自然语言处理的应用都有很重要的意义。
文献[1] 提出了基于有限状态自动机和词典查询相结合的维语名词词干提取算法,此方法中由于维语的语音和谐,词缀与词干词尾相似导致过度切分的情况。文献[2] 提出了最大熵模型和有限状态自动机相结合的维语词干提取方法,这个方法对名词词干提取是有效的,但是最其他词性效果不明显。文献[3] 提出了使用条件随机场的维语词干提取方法。文献[4]提出了通过构建词干、词缀库,规则和统计相结合的维语词干提取方法。
2. 系统架构:
本章主要介绍系统的总体架构,并详细介绍每个模块的特征设计和解决的问题。本系统架构如图所示:系统主要分为二元语言模型、词性特征、上下文词干信息三大模块。系统的总体流程大致为:
1) 从训练集中抽出已经标注且高频的词和词干集合,对测试集进行初步stemming;
2) 利用 1)步骤中已经检测出的词缀和词根对测试集进行再次词干提取,得到词的切分候选集合;
3) 利用bi-gram语言模型对已经切分的候选集合进行打分;
4) 加上词性特征,过滤掉词干、词缀链接不合法的情况,并对候选重新打分;
5) 加上上下文词干信息特征,并对候选切分重新打分;
6) 通过 Viterbi 算法选择出最佳切分路径;
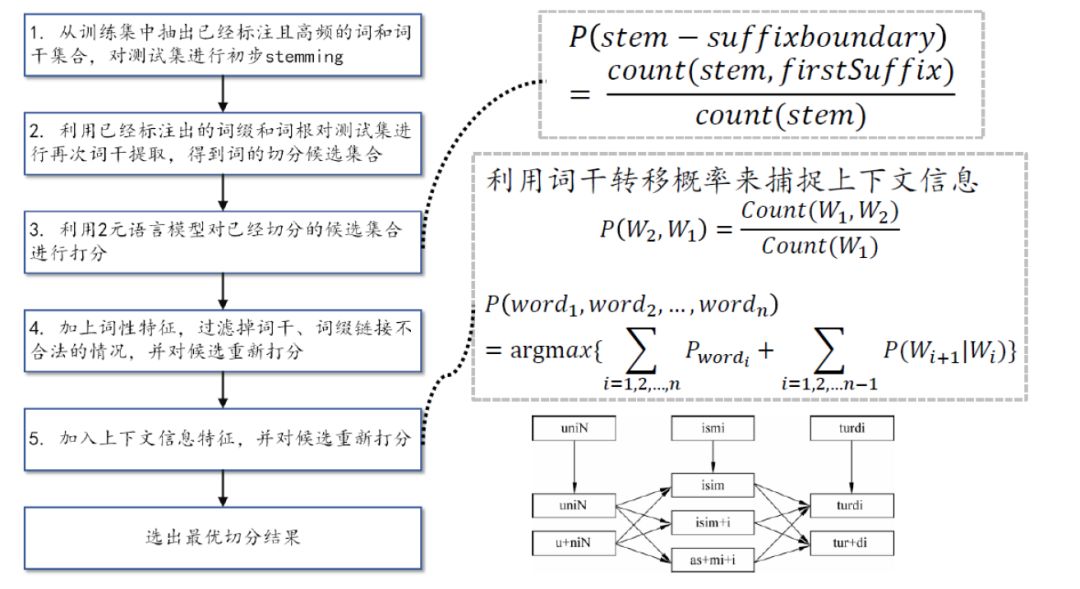
图1. 系统的总体架构
3. Bi-gram语言模型:
维语的语素可以分为三类,即词根、构词附加成分和构形附加成分。维吾尔语单词的组成形式是“prefix+stem+suffix1+suffix2+ ··· + suffixn”。其中,prefix是前缀,stem是词干,suffixn是单词缀,复合词缀是由多个单词缀链接构成的。一般,用二元语言模型来计算每个切分候选的概率,我们采用词干-词缀的边界来计算切分概率的重要部分,如(1)式:
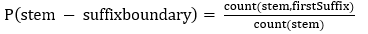
1)
其中,count(stem)指的是词干出现的次数,count(stem,firstSuffix)指的是该词干和该词缀共现的次数。
4. 词性特征进行剪枝:
维吾尔语词语分为12类,其中七类是实词(主要分类),五类是虚词(助词类)。实词分为动词和静词,静词包括名词、形容词、数词、量词、代词、副词和拟声词等词类。虚词包括后置词、连词、感叹词和语气词。
本文我们收集训练语料库中的词干,对它们进行人工词性标注,例如:名词、数词、动词和形容词等。维吾尔语中有大量的词缀成分,以上词类都可以附加各自的词缀和有自己特定的词缀,而且不同词性的词干能够连接的词缀也不同。基于此规则,本文通过检查一个单词缀是否能够合法的连接在某一词性类的词干后面,从而可以降低词干-词缀链接错误的问题。
例如:维吾尔语词

birlexme (联合)本身是一个名词词干,通过前向逆向匹配法可以得到该词的五个候选切分,我们可以对这五个候选切分进行词干词缀链接合法性的检查,如表2所示。
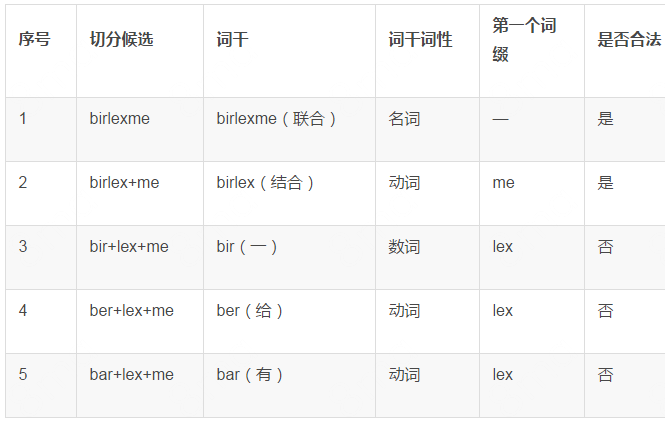
表2. 通过词性过滤不合法切分候选 (注:为了显示方便,阿拉伯维文全部使用拉丁维文显示)
当 birlexme 被切分成bir+lex+me时,bir是数词性词干,由于词缀 lex不能连接在数词性词干后面,所以这种切分是不合法的。因此,词性词干-词缀链接形式可以有效地减少非法候选导致的歧义性问题。
5. 基于上下文词干信息的重打分 (rescore):
维吾尔语词汇中同形异义词较多,出现频率较高,而且同一个词在不同上下文中切分结果是不同的。例如:
1.他的名字叫吐尔地
阿拉伯维文:
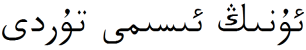
拉丁维文:uniN ismi turdi
2.他站起来了
阿拉伯维文:

拉丁维文:u ornidin turdi
其中,单词 turdi 在两个句子中形式是一样的,但是在第一句中turdi是一个人名,词干就是其本身。而在第二句中 turdi 是由词干tur加词缀di构成的,并且词干词缀的链接形式是合法的。如果不考虑上下文信息,仅仅简单地使用统计方法对turdi进行词干词缀切分会得到 tur+di 的切分结果,而这种切分结果在第一句的上下文环境中是不正确的。对于这类问题,我们可以利用上下文词干信息来找出正确的切分结果,从而解决维吾尔语词切分。如(2)式:
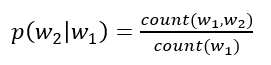
2)
其中,W1和W2是句子中相邻两个词的词干,count(W1,W2)是W1和W2的共现次数,count(W1)是W1出现的次数。通过转移概率,我们就能获知在词干W1出现的情况下W2出现的概率,从而帮助我们找到特定上下文红一个维吾尔语单词最有可能的切分。
6. Viterbi搜索最佳路径
我们定义word1,word2, ... ,wordn是一个维吾尔语句子,W1W2...Wn是该维吾尔句子中各单词的词干,Wi表示词干,那么,一个维吾尔语句子最优切分的概率由(3)计算。
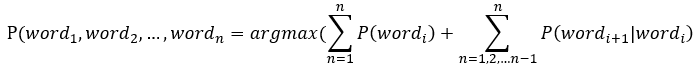
3)
其中P(wordi)是利用式(1)计算的多个切分候选概率,P(Wi+1|Wi) 是相邻两个单词词干的转移概率。
例如:对于维吾尔语句子uniN ismi turdi(他的名字叫吐尔地),其中turdi在不同上下文中有不同的意思。首先利用二元语言模型计算多个切分候选的概率,然后用词性特征检查每个翻译候选的合法性,过滤掉非法的切分候选,重新计算切分候选概率。我们得到了12种切分候选组合,如图2所示:
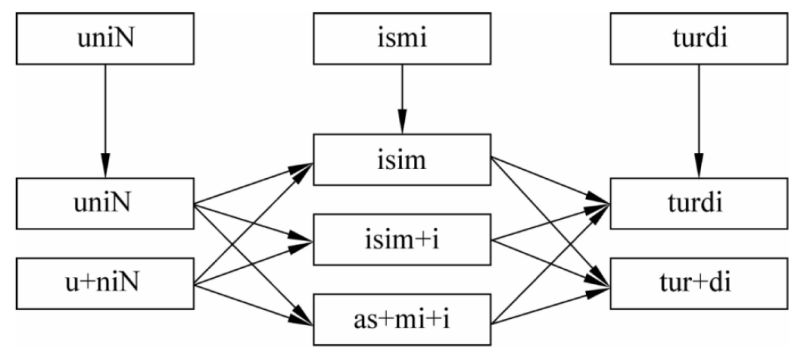
图2 . 切分候选组合图
本文通过引入词干的上下文信息,可以通过 Viertbi 算法搜索最佳路径,比较起穷举的方法,假设路径宽度为T,每一个词的状态平均宽度为D,则 Viterbi算法的时间复杂度可以控制在O(TD^2),远远低于穷举的O(D^T)。这样,我们就可以选出最佳的切分结果,继而可以有效地解决维语词切分的歧义问题。
实验结果
本章主要说明一下本系统的数据使用情况和数据处理情况。
1. 数据使用情况
本系统采用的数据主要是评测方提供的5万句训练数据。在实验时,我们从中抽出5000句作为测试集,另外45000句作为训练集。
我们从45000句训练集中抽出了5000句,做了人工标注,主要是提取词干和词缀,同时标注相应词干的词性。另外,我们提取出训练集中高频的已标注的词干和词组合前5万个,针对正确性做了校对,并修改错误的情况。
2. 实验设置
除了上面提到的三个模块外,我们针对高频出现的切分组合和不该切分却切分的情况,通过规则的方式来做切分。本文主要设置了三组实验:
第一组,前面提到的三种特征组合。
第二组,把高频出现的词和词干的切分组合加到规则库中,针对该词,强制这种切分。
第三组,构造停用词表,将一些不该切分却切分的词加入停用词表。其中,停用词表的构造主要是下面三个步骤得到:
1)获取不该切分却做了切分的词和切分正确的词分别输出到两个文件。
2)对这两个文件分别统计每个词出现的频次,并按频次排序,抽出频次大于5的词。
3)如果不该切分却做了切分的词出现的频次大于正确的词出现的频次,且正确的词出现的频次小于5,则把该词加入到停用词表中。
3. 开发集结果及分析
在实验是在参赛测试集结果未曾获取下在开发集上的结果。本系统主要是通过召回率 Recall,精准度 Precision,准确度 Accuracy三个评价指标来衡量系统性能。表3是本文设置的三组实验的实验结果,其中,Recall、Precision和Accuracy的计算方式如下:
Recall = correctNo / totalNo 4)
Precision = correctNo / (correctNo + wrongLabelNo + didButNotNo) 5)
Accuracy = (lengthNo - wrongLabelNo - shouldButNotNo - didButNotNo) / lengthNo 6)
其中,lengthNo指的是测试集的总词数,totalNo指的是应该被切分词的总数,correctNo指的是被正确切分词的总数,wrongLabelNo指的是应该切分但是切分错误的词总数,didButNotNo指的是冗余切分词的总数,shouldButNotNo指的漏切分的词的总数。
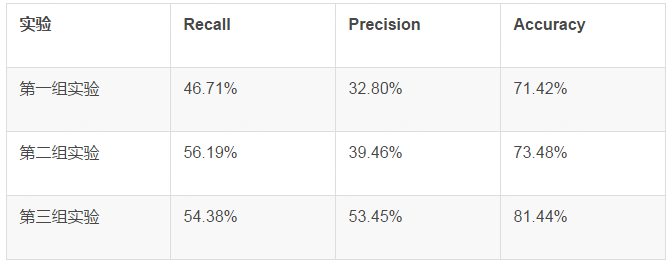
表3. 开发集上初步实验结果
从实验结果可以看出,在训练数据质量不太高的情况下,我们设置的三个特征(Bi-gram语言模型,词性,上下文词干)还是很有效果的,语言模型解决了多个切分候选的选择问题,词干上下信息特征有效解决切分歧义问题。第二组实验结果证明了,把频次比较高的切分加入到规则库,强制对该词做这种切分对词干提取问题是简单有效的。第三组实验,主要是针对不该切分却做了切分的情况,这种情况在词干提取问题中比较突出,我们的解决方案是构造一个停用词表,使得不该做切分的词强制对其不做切分。第三组实验结果也表明这种方法是比较有效的。于是在实际的参赛中,我们采用了第三套方案。
民族交流亚克西
随着项目的不断深入,我们还有很长的路要走。王蒙在《我的塞外16年》里讲:“我欣赏维吾尔语的铿锵有力的发音,欣赏它的令人眉飞色舞的语调,欣赏它的独特的表达程序……一有空闲,我就打开收音机,收听维吾尔语广播,开始,我差不多一个字也听不懂,那也听,像欣赏音乐一样地如醉如痴的欣赏它,一听就喜笑颜开,心花怒放。两个农民小孩子说话,我也在旁边‘灌耳音’……我学维吾尔语已经要走火入魔了。”
现在我对这句话也理解特别深。每天在腾讯的班车上,打开《维语吧》公众号学习基础语法,看一部维语版《屌丝男士》——《石榴熟了》,然后再听一首抒情的维语诗歌朗诵,成了我每日的必修课。

我爱听维吾尔语,爱看维吾尔语。我常常陶醉于各民族的同胞分别用着自己的语言,淋漓酣畅的抒情达意,而同时又能很好地交流的吉祥情景。还有,没有办法隐瞒的事,我不愿意放过任何可以使用维吾尔语的机会。一听维吾尔语,我就神采飞扬,春风得意,生动活泼,诙谐机敏。希望鹅厂能够将社交技术和AI技术遍及民族地区和边疆地区。
我把微信名字改为了“琼库勒. 月戈尼西. 黄”,“琼库勒. 月戈尼西” 正是深度学习的意思。
致谢
• 感谢TEG基础研发部成都维语团队的aminali,zackma,lomoxu 和verasun 在训练集的标注支持和语言方面的指点;
• 感谢loganzhang,jinronggu,dinoewang 三位维语专家在维吾尔语翻译和维吾尔语深层次语法解析上一直给予的帮助;
• 感谢部门领导damonju,tracytan,davidyu 对维吾尔语技术的大力支持和推动;
• 感谢 julietwang , francesliu , yufeizheng 在资金和高校科研合作上对维吾尔语识别技术的大力支持;
参考文献
[1]早可热·卡德尔,艾山等. 维吾尔语名词构形词缀有限状态自动机的构造. 中文信息学报,2009,23(6): 116-121.
[2]古丽拉·阿东别克,米吉提·阿不力米提. 维吾尔语词切分方法初探[J]. 中文信息学报,2004,18(6): 61-65.
[3] Aisha B. A Letter Tagging Approach to Uyghur Tokenization[C]// Proceedings of the 2010 International Conference on Asian Language Processing: IEEE Computer Society, 2010: 11-14.
[4] Ablimit M, Eli M, Kawahara T. Partly supervised Uyghur morpheme segmentation[C] // Proceedings: IEEE Computer Society, 2010: 11-14.
[5]赛迪亚古丽·艾尼瓦尔,向露等. 融合多策略的维吾尔语词干提取方法. 中文信息学报,2015,29(5).
[6] Uyghur Stemming Using Conditional Random Fields. International Journal of Signal Processing, Image Processing and Pattern Recognition Vol.8, No.8 (2015), pp.43-50
[7] Aishan Wumaier, Tuergen Yibulayin, Zaokere Kadeer, Shengwei Tian. Conditional Random Fields combined FSM stemming method for Uyghur. Computer Science and Information Technology, 2009
关注腾讯TEG科技云端公众号
技术牛人牛事抢鲜看

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2018-07-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号