「科技·TEG」沉吟至今,生而为云 - 异构FPGA在云端一次算力的升华
「科技·TEG」沉吟至今,生而为云 - 异构FPGA在云端一次算力的升华


1
背景
随着以数据中心为核心的云计算的兴起,传统计算领域不断被蚕食。各大公司纷纷出手,构成形如战国七雄的乱战格局:Amazon、Google、Facebook、Microsoft、阿里、腾讯、百度。

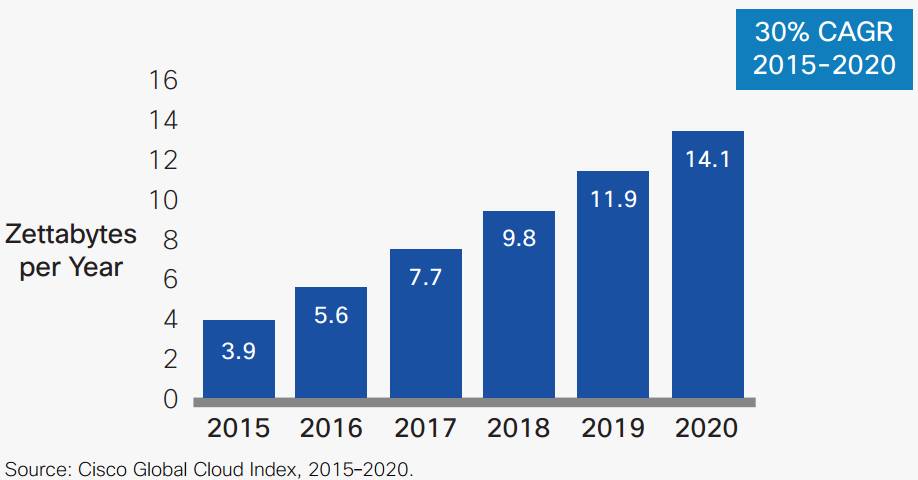
在吃瓜群众眼中,云计算体大量足,实力强劲,于是,以机器学习、物联网、视频、科学计算、金融分析等大数据制造者为首的大量任务在云端构成了长长的计算队列。思科云指数报告指出,预计到2020 年,全球 92% 的数据流量将来自云计算,将从2015 年的每年 3.9 ZB 增长 3.7 倍,到 2020 年达到 14.1 ZB(ZettaByte,1 ZB = 2^70 B),如下图所示。多样化、复杂化的大量应用使云端的负荷不断增加,在计算能力、带宽瓶颈、响应延迟等方面提出了更大的挑战。
2
大数据计算带来的问题
计算能力:随着以深度学习、金融分析、科学计算等为代表的大数据业务的兴起,数据中心的业务逐渐从IO密集型向计算密集型转变。按照传统的性能扩容方式,单纯的增加计算节点的数量已不再适用,大规模计算任务中,更大范围、更多计算节点、更长路径下的数据传递与交互,带来了一系列问题。首先,节点交互的增加导致数据转发和数据重发机制占用了通信链路的大量带宽,增加了通信成本和路由的负担;其次,更多计算节点的参与增加了延迟并降低稳定性,极大影响了服务质量;再次,更多的服务器和更大的集群规模使数据中心的建设成本和运营成本线性增加,尤其在电力需求的倍增成为现有方案的挑战。
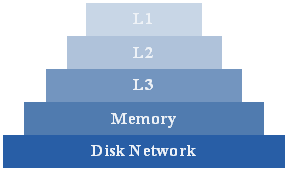
带宽瓶颈对计算效率的制约:计算能力不是狭义的CPU性能,而是云端每台服务器视为一个计算粒度的处理能力。除了CPU,计算能力还受到多级带宽的制约,如网络带宽、缓存带宽、内存带宽、硬盘带宽,也就是所谓的冯诺依曼体系下的Memory Wall,如图所示。从1980年开始,CPU和带宽的增长速度就开始出现不一致,出现了CPU每年以50%速度的增长,而Memory只有7%。不同的应用场景对带宽的需求不同,导致了CPU计算效率的极大差异。尤其当CPU的内核数量不断增加时,如至强处理器多至72核,在带宽的限制下平均计算效率可想而知。
响应延迟:响应延迟取决于任务数量。为了提高CPU的计算效率,经常让一台服务器跑多个应用,把服务器的利用率成倍提升,但也增大了延时。例如,若把CPU利用率从30%提升到70%,响应时间增加10倍[1]。而在大部分的场景中,更多的用户对延时更敏感,将响应速度的优先级设定在吞吐量之上[2]。在某些大量用户访问场景中,请求排队的长度太长,导致内存耗尽、带宽占满等空间问题,也会增加延迟。值得注意的是,当某个计算任务规模较大从而需要集群计算时,服务器之间的通信会进一步增加延时。尤其在计算模型的关键路径上,无法用并行换取更短的执行时间,每一个节点的延迟会造成整个进程的延时积累,响应速度将进一步恶化。
大数据的价值固然可爱,而在兼顾性能、带宽和延时的前提下,规模不断增大的任务也成为迫使云计算进步的新动力。
3
FPGA与CPU,小鲜肉与老司机
当CPU陷入瓶颈,以GPU、FPGA和专用ASIC为代表的异构计算平台异军突起。其中GPU成就了深度学习而成为学术界加速构架性能对比的标杆,黄教主和Google TPU(深度学习的专用ASIC)团队的口水仗,从互相伤害走向相互攀比,也成了业界喜闻乐见的谈资。期间,低调的FPGA也渐渐走向前台,以期三分天下。
FPGA可视为具备可编程能力的资源池,其中的逻辑(CLB)、存储(BRAM)、和计算单元(DSP)的组织方式可根据具体应用设计不同的架构,实现深度定制。随着技术的进步,FPGA突出的计算能力和能耗优势使其成为Datacenter的一个选择。例如Microsoft在Catapult项目中将FPGA部署于Bing搜索业务,以功耗增加10%,获得性能提升95%的收益[3];IBM的SuperVessel提供了FPGA加速的云服务,并将其集成在OpenStack中[4]。同时,新一代服务器CPU也纷纷增加对FPGA的支持,如Intel的Xeon+FPGA平台,将FPGA和Xeon处理器集成在同一个芯片封装上;IBM也在POWER8上提供了CAPI接口实现与FPGA/ASIC等协处理器的高速通讯。那么,FPGA到底有何魅力,而在云计算的大势下崭露头角呢?
深度定制与算力革命:相比于增加服务器数量和集群规模,另一种增加计算能力的方式是提升每台服务器的性能,于是,异构的计算方式成为提升算力的利器。当前处理器可根据通用性和定制性的差异总结为下图。

在相同的晶体管规模下,越是通用的处理器计算效率越低,能耗比也越差;定制性越高,应用的范围越窄,但越“精通”某一类型的计算。当某一类型的计算形成一定规模,高算力、低功耗为代表的专用 ASIC 便成为一种极致下的选择,如:Google的TPU。然而 FPGA 却是一种例外。一方面,FPGA针对每一种具体应用,都可以根据其算法结构进行深度定制,甚至为算法的每个步骤设计专门的执行逻辑,避免了通用处理器的取指和译码过程,从而达到较高的计算效率和能效;另一方面,FPGA的可编程特性可以加载不同的运算架构,实现器件本身的通用性,不但可以设计针对图像图像的计算结构,也可实现GPU并不擅长的搜索、加密解密等计算结构,因此成为CPU的黄金搭档,为每个计算节点实现算力的全面升级。
优化带宽:带宽问题始终是计算机体系结构中制约计算能力的瓶颈之一。当采用GPU提升算力时,GPU的计算数据需要分享服务器的网络带宽、PCIE带宽、内存带宽等,影响计算效率的同时反而加剧了服务器的带宽瓶颈。只有在具备极高数据复用率的场景中,如CNN等,才有望跑满计算资源。Google第一代TPU也遭遇了同样的尴尬,按业务场景比例加权平均后的性能仅为峰值性能的11%,如同买了一辆最高时速300Km/h的豪车,上路后发现平均限速30Km/h,一脸懵逼。对于FPGA,可以通过IO编程能力采用另一种加速方式——智能网卡,如图所示[5],其中右图Role×N为FPGA中的硬件加速逻辑。
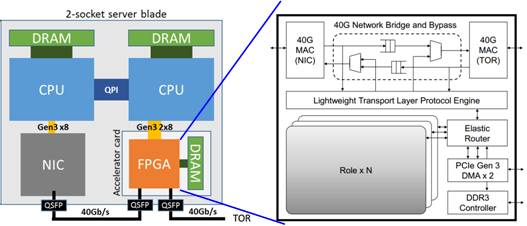
智能网卡的方式将FPGA置于服务器网口输入之外,使数据经FPGA预处理后再到达网卡(NIC),进入服务器。其带宽优势主要体现为:
1、FPGA计算所需的数据不需要进入服务器,将硬件加速过程与服务器的带宽瓶颈解耦,避免与CPU的带宽竞争。
2、可承担部分原属于CPU的计算任务,减少进入服务器的数据量和计算复杂度,从而缓解带宽压力。
延迟控制与稳定性:FPGA在低延迟和稳定性上具备天然的优势。一方面,其片上集成了大量缓存和外部DRAM接口,降低计算过程中与CPU的交互,使硬件加速过程避免了操作系统层面的资源调度和进程间干扰,从而保证了确定性的延迟。另一方面,FPGA可实现基于定制流水线MIMD(并行指令和并行数据)设计,实现流式处理。中间数据在流水线之间传递和交互,降低对缓存的依赖,进一步降低延迟。例如:在针对QQ相册、微信等应用的图片转码业务中,我们实现10倍CPU性能的同时,延迟降为1/7;在基于DNN的搜索和推荐业务中,实现5倍CPU性能,延迟降为1/100。同样,在微软部署FPGA的数据中心中,应答排名服务中的延迟和稳定性对比如下图所示。
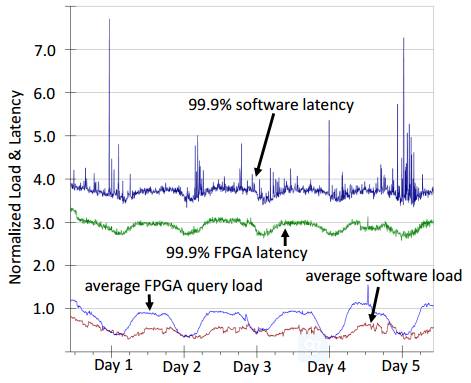
计算资源虚拟化后,云的性能依赖于数据中心的实体计算能力,而后者又受到计算节点性能、多节点规模、调度方式等因素的影响。FPGA的加入提升每个计算节点的处理能力,有利于缩小规模和简化调度,成为云计算的新助力。同时,更低的延迟和更高的稳定性,让提供的定制化服务在延迟、吞吐量等参数上具备更大的调整范围,兼容一些原本云计算无法满足或需要极大代价的苛刻应用场景,进一步促进了云的拓展和服务质量的提升。
4
结语
工欲善其事必先利其器。特定领域需求的多样性和对算力需求的增加,使异构化的云服务成为一种趋势,FPGA因其灵活性和对众多非标准计算构架的支持,受到了越来越多的公司的关注,学术界关于对虚拟化FPGA资源的高效利用也走进人们的视野。同时,亚马逊、腾讯、阿里纷纷推出的FPGA云服务,无不彰显着业界大佬对FPGA小鲜肉的认可和期待。与此同时,FPGA的开发门槛正在降低,高层次综合工具不断涌现。一方面在某些垂直领域,如深度学习等,更高层次的算法到逻辑的端到端综合工具正在形成;另一方面,计算终端的异构化带来计算粒度、构架、带宽、延迟、存储上的变革,也将继续推进云、分布式、集群计算部署框架的更新,异构云的生态正在形成。老骥伏枥,大器晚成。经历的30余年的沉淀,FPGA是否能在云端实现FaaS(FPGA as a Service)的升华,这一切尽在2017。
[1] 包云岗, 《云计算与标签化冯诺依曼体系结构》, CNCC 2016。
[2] Norman P. Jouppi etc. In-Datacenter Performance Analysis of a Tensor Processing Unit. ISCA 2017 (2017年6月正式发表).
[3] Andrew Putnum et al. A Reconfigurable Fabric for Accelerating Large-scale Datacenter Services. In Computer Architecture (ISCA), 2014 ACM/IEEE 41st International Symposium on, pages 13–24. IEEE, 2014.
[4] IBM Research. OpenPOWER Cloud: Accelerating Cloud Computing. https://www.research.ibm.com/ labs/china/supervessel.html, 2016.
[5] Caulfield A M, Chung E S, Putnam A, et al. A cloud-scale acceleration architecture[C]//Microarchitecture (MICRO), 2016 49th Annual IEEE/ACM International Symposium on. IEEE, 2016: 1-13.