语音诈骗技术案例剖析:VoIP 电话劫持+AI语音模拟

语音诈骗技术案例剖析:VoIP 电话劫持+AI语音模拟

博文视点Broadview
发布于 2023-04-04 10:50:53
发布于 2023-04-04 10:50:53
👆点击“博文视点Broadview”,获取更多书讯

AI语音技术是AI技术的一个分支,随着AI技术的发展,AI语音技术突飞猛进、换代升级。
通过基于AI的深度伪造变声技术,可以利用少量用户的语音生成他想要模仿的语音。这种技术在给用户带来新奇体验的同时,潜在安全风险。
深度伪造AI变声技术可能成为语音诈骗的利器。
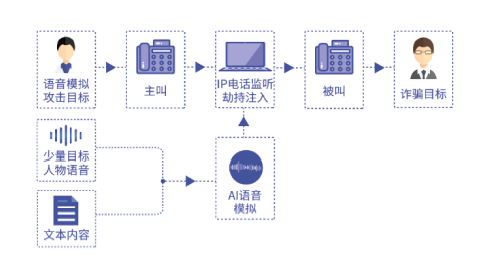
研究发现,利用漏洞可以解密窃听VoIP电话,并利用少量目标人物的语音素材,基于深度伪造AI变声技术,生成目标人物语音进行注入,拨打虚假诈骗电话。
下图展示了语音诈骗的整体流程。总的来说,这种新型攻击的实现方式分为两个部分:一是VoIP 电话劫持:二是语音模拟。
01
VoIP 电话劫持
要实现对VoIP 电话的劫持,首先需要对音频进行嗅探,然后需要对来电身份及语音内容进行篡改。下面着重介绍一下音频嗅探技术和如何实现来电身份及语音内容篡改。
1)音频嗅探技术
在某品牌CP-79XX 系列电话中,通信使用SCCP 协议,该协议没有使用TLS对流量进行加密, 因此可以在同VLAN 下对目标电话进行中间人攻击(Man-in-the-Middle Attack,MITM 攻击),这可以让攻击者对目标通话人的来电信息进行伪造,同时完成窃听操作。
ARP 协议是网络行为中应用广泛的基础数据链路层协议,用于在VLAN 内完成从IP 地址到MAC 地址的转换。利用APR 欺骗可以获取目标通话人的语音信息。例如,在VoIP 电话的案例中,我们在访问一个IP 地址时首先会在同VLAN内发送问询广播包:Who has 10.26.132.134?。
地址广播示意图见下图。
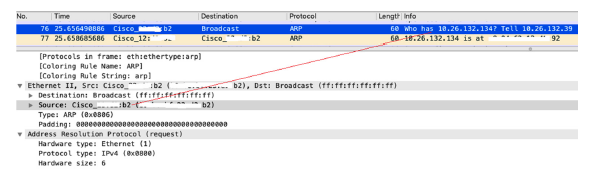
接收到该问询广播包的主机会比较问询IP 是否为自己的IP,如果是,则向询问主机发送应答包,应答包中包含自身的MAC 地址。随后询问主机会根据MAC地址构造自己的数据包完成数据交互。
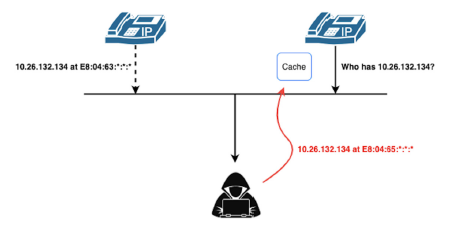
在操作系统中,存在ARP 缓存表来加速这种映射关系,黑客攻击ARP 协议时会抢先应答ARP 广播,从而造成被攻击者的ARP 缓存表被投毒的情况,在后续的网络通信中,数据包均会被发送到黑客的主机中,见下图。
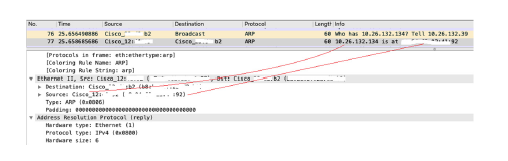
下图为真实的ARP 应答包。
通过这种ARP 欺骗的攻击方式,攻击者将被攻击者的语音流量劫持到自己的主机上,并进行RTP 语音流的还原来实现窃听操作,见下图。
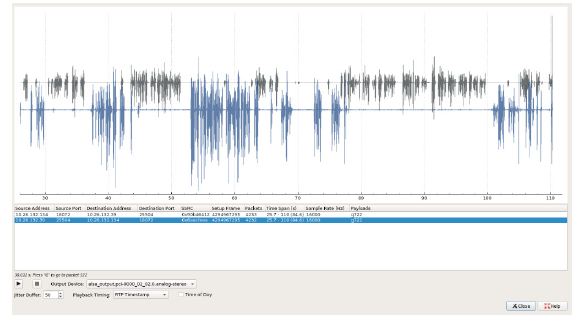
2)来电身份及语音内容篡改
在监控电话流量时,攻击者可以修改SCCP 协议中呼入者的用户名与电话号码信息,实现代码如下。
key1 = b"tomzhang"key2 = b"12264"try:buff = bytearray(p[Raw].load)for pos in find_sub_array(p[Raw].load, key1):buff[pos : pos+len(key1)] = b"tonyli "for pos in find_sub_array(p[Raw].load, key2):buff[pos: pos + len(key2)] = b"88888"SCCP 协议在无法对呼入数据进行真实性校验的情况下,将数据包中的呼入姓名与来电号码完整地显示在来电屏中,见下图。

在篡改呼入姓名与来电号码后,攻击者替换RTP 协议中的语音流,实现完整的电话欺骗链路,见下图。
02
语音模拟
语音模拟可以根据源人物的说话内容合成具有目标人物音色特征的音频输出。这项技术其实并不新鲜,早已在许多现实场景中应用落地,如地图应用中的定制播报语音,利用少量自己的语音,就可以定制自己语音的播报语音。
同样,在VoIP 电话劫持中,利用少量被攻击者的语音,就可以合成与被攻击者音色相似的任意内容的语音片段,一旦被恶意利用,攻击者可以轻松拨打虚假电话,与目标人员对话。
这里语音模拟用的是语音克隆技术,该技术只需要数秒目标人物的音频数据和一段任意的文本序列,就可以得到逼真的合成音频。下图展示了语音模拟过程。基于深度学习的语音克隆技术主要包含音色编码器、文本编码器、解码器、语音生成器4 个模块。

(1)音色编码器:音色编码器从音频中提取不同说话人的音色特征。
(2)文本编码器:文本编码器将输入文本转换为特征。
(3)解码器:解码器将说话人特征和文本特征拼接后的结果转化为梅尔声谱图。
(4)语音生成器:语音生成器根据梅尔声谱图合成语音。
拿到目标人物的数秒音频文件后,首先音色编码器对目标人物的音色进行编码,提取说话人的音色特征,然后梅尔声谱图合成器接收编码后的音色特征和文本信息,基于音色特征,合成带有既定文本内容的梅尔声谱图,最后语音生成器将梅尔声谱图转换为音频。语音克隆逻辑代码参考如下,其中encoder 为音色编码器,synthesizer 为梅尔声谱图合成器,vocoder 为语音生成器。完整代码内容详见代码库。
def synthesis(src_voice_path, text, dst_voice_path):"""语音克隆,提取目标人物音色特征,生成带目标人物音色的既定内容的合成音频参数:src_voice_path: 目标人物音频文件路径text:需要合成的文本内容dst_voice_path: 生成的音频文件保存路径"""base_name = src_voice.split('/')[-1].split('.')[0]save_wav = src_voice
in_fpath = Path(src_voice_path)original_wav, sampling_rate = librosa.load(in_fpath)
# 对音频内容进行预处理
preprocessed_wav=encoder.preprocess_wav(original_wav,sampling_rate)
# 提取目标人物音色特征,对目标人物音频进行编码embed = encoder.embed_utterance(preprocessed_wav)
# 根据目标人物音色特征和文本内容合成梅尔声谱图specs = synthesizer.synthesize_spectrograms([text], [embed])
# 生成音频generated_wav = vocoder.infer_waveform(specs[0])generated_wav = np.pad(generated_wav, (0, synthesizer.sample_rate),mode="constant")scipy.io.wavfile.write(dst_voice_path, synthesizer.sample_rate,generated_wav)使用上述方法可以将生成的虚假音频内容注入VoIP 电话中,实现声音的伪造,重现语音克隆攻击。随着技术开源及语音合成技术的发展,语音克隆的成本将越来越低,一旦被恶意利用,将带来无法预知的安全风险。
以上内容节选自《AI安全:技术与实战》一书。


京东限时优惠,快快扫码抢购吧!

发布:刘恩惠
审核:陈歆懿

如果喜欢本文欢迎 在看丨留言丨分享至朋友圈 三连
热文推荐
转行数据分析?你可能需要这块敲门砖!
黑客“劫持”了一颗卫星,用它直播黑客大会和放电影
一本书,带你走出Spring新手村
BUG退退退:搞懂MySQL隔离级别▼点击阅读原文,了解本书详情~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-11-10,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 博文视点Broadview 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号