【玩转 GPU】GPU加速的AI开发实践
原创

一、GPU的数据匮乏
Google、Microsoft以及世界各地其他组织最近的研究表明,GPU花费了高达70%的AI训练时间来等待数据。看看他们的数据管道,这应该不足为奇。下图显示了典型的深度学习数据管道,NVIDIA称这是他们及其客户常用的。
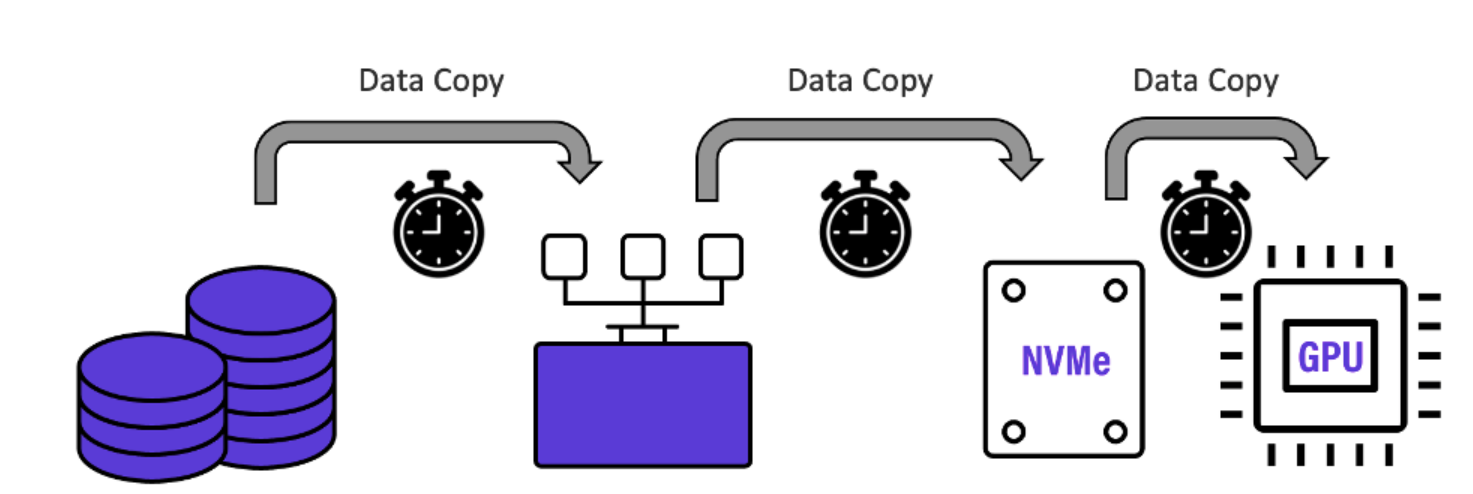
GPU数据匮乏
如上图所示,在每个训练Epoch开始时,保存在大容量对象存储上的训练数据通常被移动到Lustre存储系统层,然后再次移动到GPU本地存储,用作GPU计算的暂存空间。每个“跃点”都会引入数据复制时间延迟和管理干预,从而大大减慢每个训练时期。宝贵的GPU处理资源在等待数据时一直处于空闲状态,并且不必要地延长了重要的训练时间。
HK-WEKA将典型的GPU匮乏的“multi-hop”AI数据管道折叠成一个单一的、零拷贝的高性能AI数据平台—其中大容量对象存储与高速HK-WEKA存储“融合”在一起,共享同一命名空间,并由GPU通过NVIDIA GPUDirect Storage协议直接访问,消除了所有瓶颈,如下图所示。将用于人工智能的HK-WEKA数据平台纳入深度学习数据管道,可使数据传输率达到饱和,并消除存储仓之间浪费的数据复制和传输时间,使每天可分析的训练数据集数量呈几何级数增加。
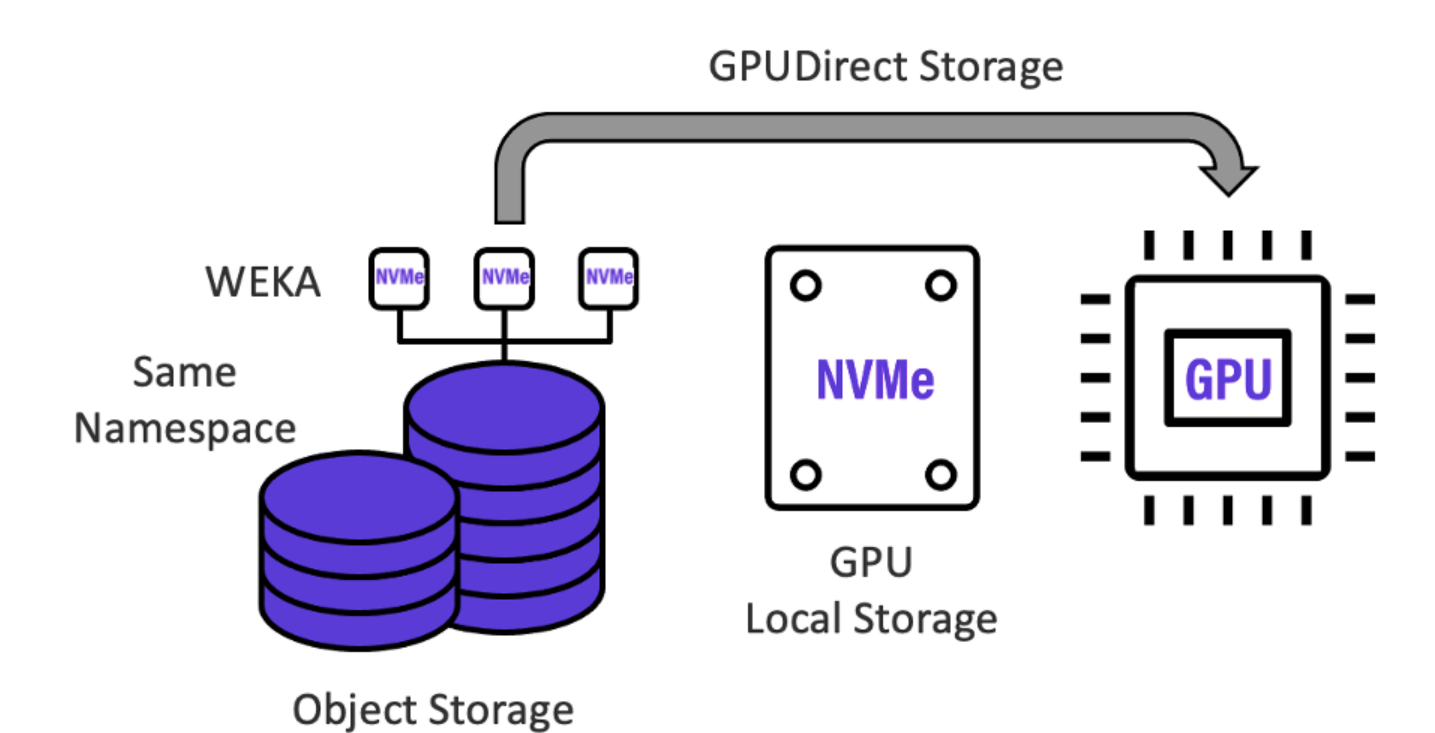
GPU实践
通过HK-WEKA零拷贝架构,数据只需写入一次,就可以被深度学习数据流中的所有资源透明地访问。如上图所示,HK-WEKA人工智能数据平台支持英伟达的GPUDirect存储协议,该协议绕过了GPU服务器的CPU和内存,使GPU能够直接与HK-WEKA存储进行通信,将吞吐量加速到尽可能快的性能。
1.专为最低延迟深度学习数据管道设计的架构
深度学习人工智能工作流程包括跨训练数据集的密集随机读取,低延迟可以加速训练和推理性能。
- HK-WEKA的设计是为了尽可能实现最低的延迟和最高的性能。
- HK-WEKA的小型4K块大小与NVMe SSD介质块大小相匹配,以实现最佳性能和效率。
- HK-WEKA将元数据处理和直接数据访问均匀地分布在所有存储服务器上(没有后端网络),进一步降低了延迟,提高了性能。
- 更重要的是,HK-WEKA设计了低延迟的性能优化的网络。
- HK-WEKA不使用标准的TCP/IP服务,而是使用UDP上的数据平面开发工具包(DPDK)来加速数据包处理工作负载,没有任何上下文切换和零拷贝访问,这是一个特制的基础设施。
- HK-WEKA绕过了标准的网络内核栈,消除了网络操作对内核资源的消耗。
2.无缝低延迟命名空间扩展到对象存储
HK-WEKA数据平台的集成对象存储提供经济、大容量和快速访问,以便在深度学习训练过程中存储和保护大量训练集。
- 用于AI的HK-WEKA数据平台包括无缝扩展其命名空间到对象存储和从对象存储扩展的能力。
- 所有数据都位于一个HK-WEKA命名空间中,所有元数据都位于闪存层上,以便快速、轻松地访问和管理。
- 为了减少延迟,大文件被分割成小对象,小文件被打包成更大的对象,以最大限度地提高并行性能访问和空间效率。
二、NVIDIA Riva SDK
NVIDIA Riva 是一个 GPU 加速的 SDK,用于构建和部署完全可定制的实时语音 AI 应用程序,这些应用程序可以实时准确地交付。 这些应用程序可以部署在本地、云端、嵌入式和边缘。 NVIDIA Riva 旨在帮助您轻松快速地访问语音 AI 功能。 只需几条命令,即可通过API操作访问高性能服务并试用demo。
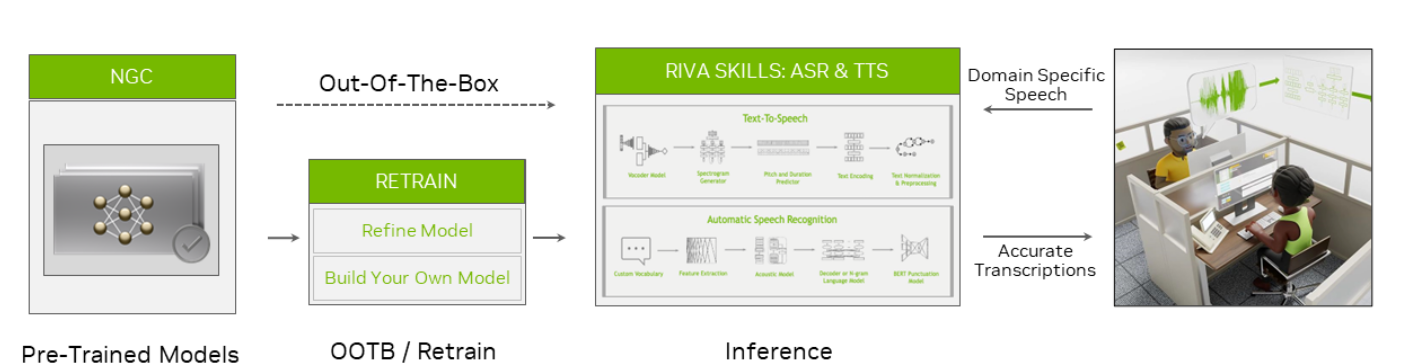
NVIDIA介绍
三、NVIDIA Riva功能概述
Riva 为实时转录和智能虚拟助手等用例提供高度优化的自动语音识别和语音合成服务。 自动语音识别技能支持英语、西班牙语、普通话、印地语、韩语、葡萄牙语、法语、德语和俄语。
它在各种真实世界的特定领域数据集上进行训练和评估。 凭借电信、播客和医疗保健词汇,它提供了世界一流的生产准确性。 要了解更多信息,请参阅探索自动语音识别技术的独特应用。
Riva 文本转语音或语音合成技能可生成类人语音。 与 NVIDIA V100 GPU 上的 Tacotron 2 和 WaveGlow 模型相比,它使用非自回归模型在 NVIDIA A100 GPU 上提供 12 倍的性能提升。 此外,借助 TTS,您只需 30 分钟的语音数据,即可为每个品牌和虚拟助手创建自然的自定义语音。

功能描述
相信熟悉模型架构的人都很清楚,GoogLeNet 的概念是为了解决传统深度网络在网络加深时容易遇到的两大问题:过度拟合 (over fitting) 及计算量增加。在透过网中网 (network in network) 的概念增加了网络的深度,但却减少了参数量。网络中采用了1x1、3x3和5x5的卷积核 (convolution kernel) 和3x3的最大池化(max pooling)。本篇会详细阐述 TensorRT 转换 GoogLeNet 的过程。
接着 TensorRT 完全可以直接接到需要的地方,不用专门做 concat 的操作,所以这一层也可以取消掉。此过程可以看到两个框框彼此之间是不相关的,因此我们可以单独启用两个计算流 (stream),分别运算。而上图也是TensorRT 针对Inception 层网络优化的结果,此过程称为网络隐藏层融合 (fusion layers of network)。网络在经过此过程后,都可有效降低隐藏层的数量,也表示减少计算量。
而经过TensorRT优化后模型的效能,由下图可知。实际来看 NVIDIA 在 GitHub 所提供的实际数据,表示 TensorRT 大约快1.5-4倍。此为透过 TensorRT 转换TensorFlow 上的常用于 NLP(Natural Language Processing) 领域的 BERT(Bidirectional Encoder Representations from Transformers) 语言模型。
四、NVIDIA GPU 加速“ AI +分子模拟”,助力深势科技打造微尺度工业设计平台
- 本案例中通过 NVIDIA A100 Tensor Core GPU,深势科技开创的“多尺度建模+机器学习+高性能计算”新范式得以进行高效、广泛的应用实践,运用AI表示高维复杂函数和处理大数据的能力,在相邻尺度间两两连接,通过多尺度建模攻克传统分子模拟瓶..
• 本案例使用了NVIDIA A100 Tensor Core GPU、CUDA 加速药物研发与材料设计等微尺度工业设计中分子模拟的典型应用。

AI +分子模拟
以新一代分子模拟技术,打造微尺度工业设计平台 借助NVIDIA A100 Tensor Core GPUs、CUDA 和 cuDNN,深势科技开创的“多尺度建模+机器学习+高性能计算”的新范式得以进行广泛、高效的应用实践。深势科技自研的新一代分子模拟技术,运用AI表示高维复杂函数和处理大数据的能力,在相邻尺度间两两连接,通过多尺度建模攻克传统分子模拟瓶颈。运用NVIDIA CUDA 硬件支撑模型训练、推演的全流程,克服了以往研究中的“维数灾难”,在保持量子力学精度的基础上,实现了对数十亿原子规模的体系进行量子力学精度的计算模拟。
NVIDIA GPU 加速科学计算,释放“AI + Science”巨大潜力 “AI + Science” 的科学研究范式是当下的前沿热点。算力、算法与硬件设施的突破进展应用于基础科学领域,将会切实赋能科学研究与产业升级。深势科技作为AI+Science范式的典型企业,致力于以算力算法的进展切实赋能科研突破与产业升级,NVIDIA GPU 助力深势科技加速实现技术迭代与产品部署。
在NVIDIA A100 Tensor Core GPU 提供的 Tensor Core 计算单元之上,深势科技跨尺度建模的计算效率得到稳定保障,能够高效准确地对微观尺度下物质结构与性能进行计算模拟,打造性能优越的微尺度工业设计平台,加速新药研发与新材料发现。
NVIDIA A100 Tensor Core GPUs 作为高性能计算的硬件基础设施,加速深势科技云原生科学计算平台 Lebesgue 的落地,实现从算法到场景的端到端闭环,智能采集、整合优化算力资源,为 AI + Science 的深化发展提供稳定的算力保障。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号