我做到了一分钟 文稿转短视频,并开源了
原创

背景
最近萌生了一个想法,就是短视频给人传递信息的速度要远远超过枯燥无味的文字,而众所周知,短视频也是媒体人花费很多经历所创造出来的。
我猜想大概的过程是这样的:
- 选取一个好的题材
- 更具题材写一篇稿子
- 通过稿子里面的一些关键字来搜索一些和主题相关的图片素材,或者电影的片段。
- 然后基于以上内容,通过一些视频剪辑工具,将素材和稿子合并起来,然后在增加配音。
大概是上面这几个步骤就完成了一个短视频的输出,可能我上面描述的过于清爽,实际上,上面每一步都很浪费时间,这也就是出一个精品不容易的原因。
那么,有没有想过,如果有现在有一封题材比较好的稿子,能否直接通过稿子生成短视频呢?
当你看到这篇文章的时候,那不好意思,这个想法已经实现了:这里是GitHub仓库地址:https://github.com/bravekingzhang/text2viedo
原理
其实现原理可以大致的描述一下:
- 将文本进行分段,现在没有想到好的办法,就是通过标点符号句号分段,分成一个个的句子
- 通过句子生成图片,生成声音,图片开源的有很多,本方案采用 stable-diffusion,语言转文字使用 edge-tts
- 在通过 opencv 将图片合并为视频,目前输出 mp4 格式的视频,句子作为字母贴到视频内容的底部区域。
- 音频是一个有时间概念的东西,恰好可以通过音频控制一张画面的播放时长
- 在通过 ffmpeg 将音频合并到原始视频中。
最终,一个有画面,有字幕,有声音的视频就出现了,咱们实现了一个 文本转视频。
成果
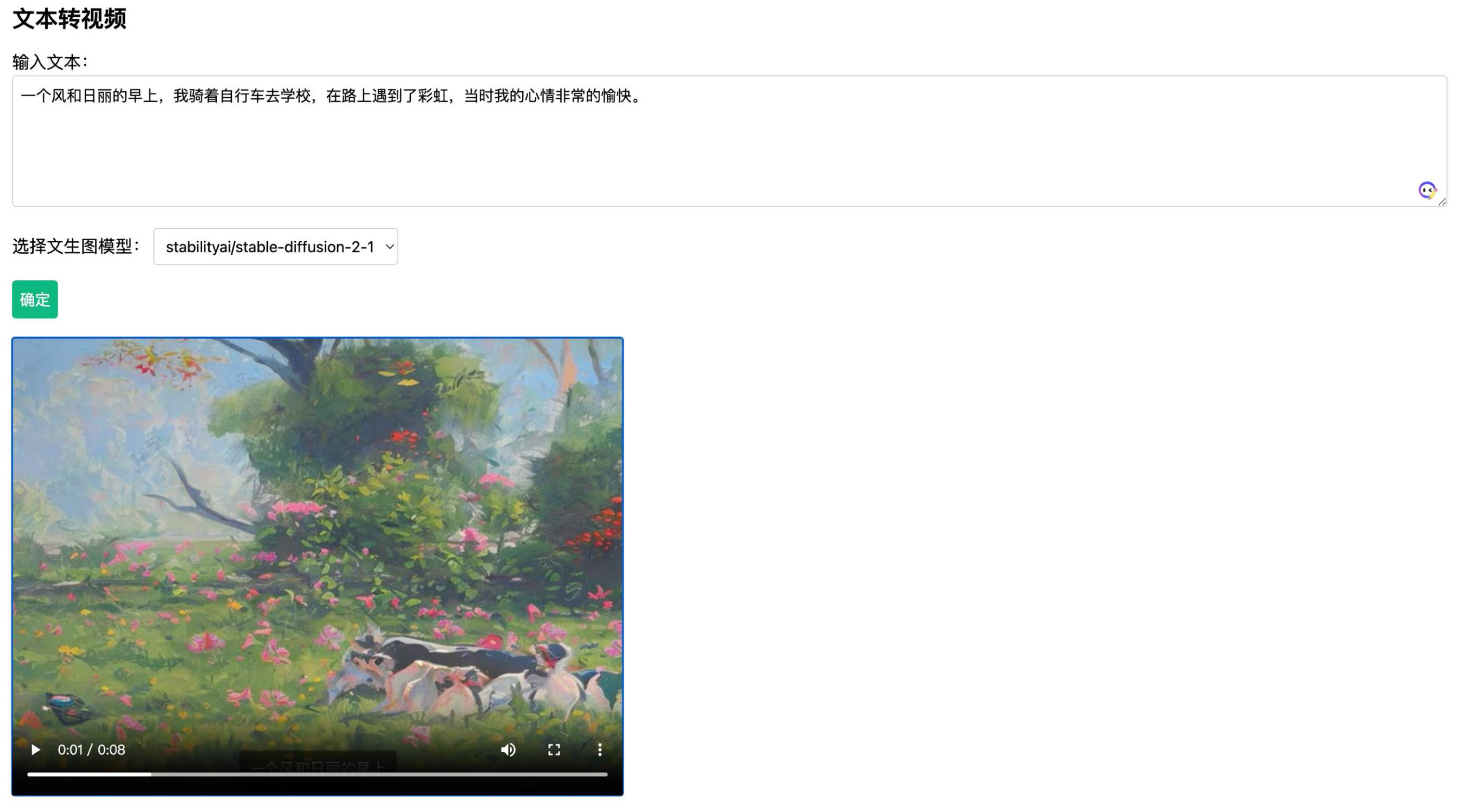
这个工具可以将一段文本转换为视频,并保存到指定的本地,初衷是想实现小说的可视化视频阅读。
if __name__ == '__main__':
text_test= '''
一个风和日丽的早上,我骑着自行车去学校,在路上遇到了彩虹,当时我的心情非常的愉快。
'''
convertTextToVideo(models[0], text_test)文本转视频后的效果可以查看 demos/demo.mp4
使用方式可以参考项目里面,安装好python依赖之后
python3.10 app.py
http://127.0.0.1:5000/就可以进行体验了。
细节
文字生成图片
文字生成图片,发现中文生成图片的效果不是很理想,因为是使用开源社区的stable-diffusion 这些模型,我想如果接入百度的文心一言文字生成图片,也许效果会稍微好点,毕竟某度还是更加懂中文的。
def generateImage(model, prompt):
body = {
"inputs": translate_to_english(prompt)
}
r = requests.post("https://api-inference.huggingface.co/models/" + model,
data=json.dumps(body), headers=headers)
# 将图片写入到 images 目录下,每个图片使用(时间戳+model).png 来命名
timeStamp = str(int(time.time()))
imagePath = "images/" + timeStamp + \
"-" + model.split("/")[-1] + ".png"
with open(imagePath, "wb") as f:
f.write(r.content)
f.close()
voicePath = "voices/" + timeStamp + \
"-" + model.split("/")[-1] + ".mp3"视频字幕
视频上字幕其实做了取巧,直接把文字贴在图片上,但是注意opencv 不太好处理中文字,对英文还算好,妥协之下还是选择了PIL库。注意字幕有长短,还有换行的处理,以及给字幕一些背景,因为,字幕颜色和图片相近,容易看不到字。以及怎么摆放。
for image_file in image_files:
if image_file.endswith(".png"):
text_color = (255, 255, 255) # 白色文字
background = (0, 0, 0,128) # 黑色背景半透明
image_path = "images/" + image_file
draw_text = sentences[image_files.index(image_file)]
add_text_to_image(draw_text, image_path,
text_color, background, padding=10)
image = cv2.imread(image_path)
resized_image = cv2.resize(image, (frame_width, frame_height))
output_video.write(resized_image)
# 添加停顿帧
duration = get_duration_from_vtt(
f"voices/{find_file_name_without_extension(image_file)}.mp3.vtt")
print(duration)
for _ in range(int(duration * 30)):
output_video.write(resized_image)
添加音频
音频直接是一句子转声音,这个有很多库可以用,但是免费的还是edge-tts好用一些,效果会好一些,因此本项目采用edge-tts。
def convert_text_to_speech(text, output_file):
# 指定输出目录
output_directory = os.path.join(current_directory,"voices")
# 创建输出目录(如果不存在)
os.makedirs(output_directory, exist_ok=True)
# 执行命令,并将工作目录设置为输出目录
try:
command = ['edge-tts', '--voice', 'zh-CN-XiaoyiNeural', '--text', text, '--write-media', output_file, '--write-subtitles', f'{output_file}.vtt']
result = subprocess.run(command, cwd=current_directory, timeout=10)
print(result)
duration = get_duration_from_vtt(output_file + ".vtt")
# 删除 无效音频 or 重新生成?
if duration == 0.1:
os.remove(output_file + ".vtt")
os.remove(output_file)
except subprocess.CalledProcessError as e:
print("Command execution failed with return code:", e.returncode)
print("Command output:", e.output)
图片音频同步
图片如何和播放的声音同步,这是一个有趣的问题,我们知道图片和声音都是通过句子生成的,而声音天然就有时长这个属性,因此,在融入视频的时候,基于这个时长来做停顿帧就可以了。
# 添加停顿帧
duration = get_duration_from_vtt(
f"voices/{find_file_name_without_extension(image_file)}.mp3.vtt")
print(duration)
for _ in range(int(duration * 30)):
output_video.write(resized_image)原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号