TKE Serverless(eks)集群使用filebeat采集日志
原创
TKE Serverless(eks)集群使用filebeat采集日志
原创
williamji
修改于 2026-03-25 18:10:32
修改于 2026-03-25 18:10:32
概述
该文档参考filebeat on k8s,在Serverless集群部署filebeat采集容器日志到ckafka(es),filebeat采集tke容器日志到es参考使用filebeat采集tke容器日志
Serverless集群
腾讯云Serverless集群参考:https://cloud.tencent.com/document/product/457/39804
tke集群弹超级节点参考:https://cloud.tencent.com/document/product/457/74014
filebeat
filebeat文档参考:https://www.elastic.co/guide/en/beats/filebeat/current/index.html
filebeat开源项目参考:https://github.com/elastic/beats
ckafka(es)
腾讯云ckafka文档参考:https://cloud.tencent.com/document/product/597
腾讯云elasticsearch文档参考:https://cloud.tencent.com/document/product/845
实践
创建TKE serverless集群
创建集群
创建TKE Serverless集群参考:https://cloud.tencent.com/document/product/457/39813
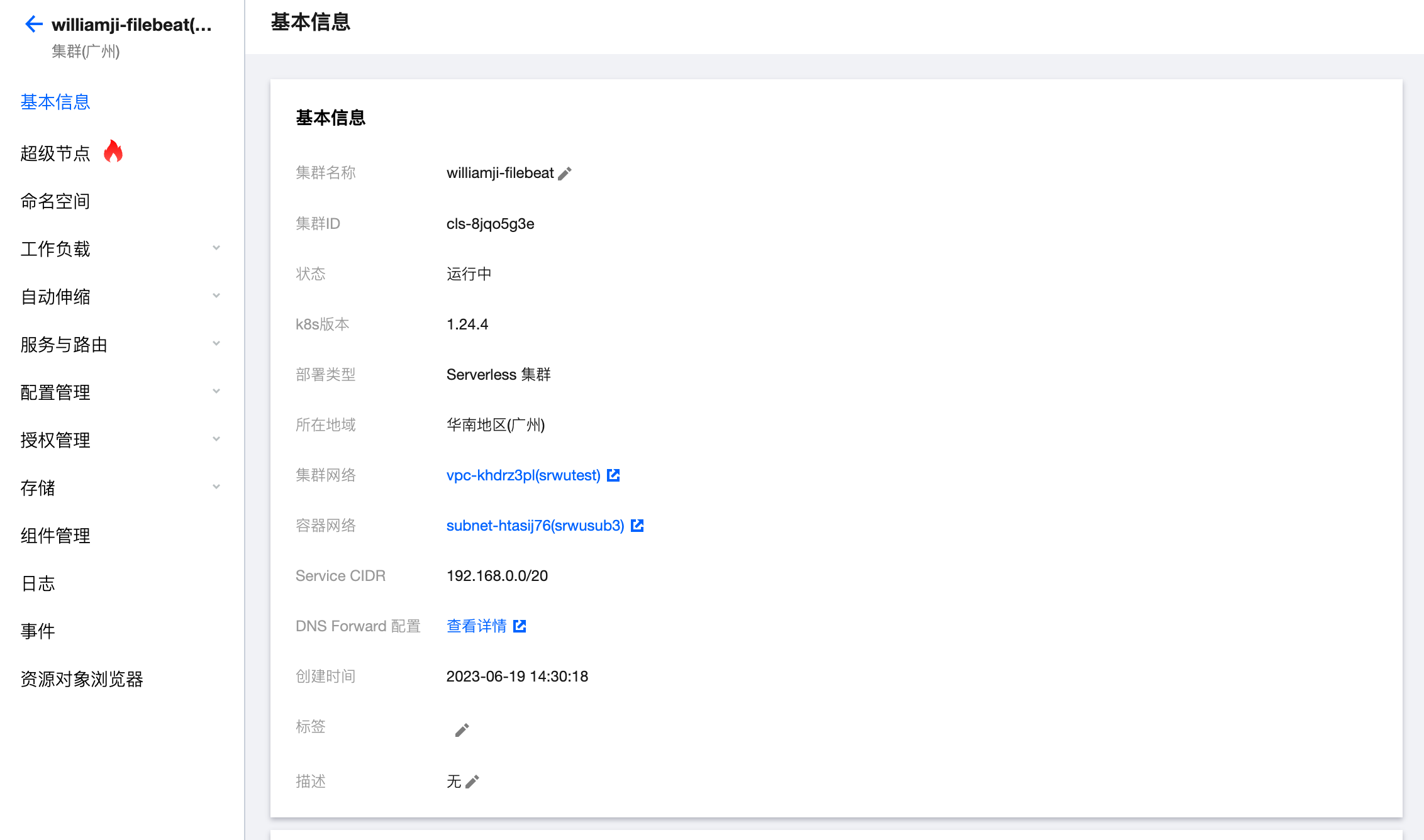
如果是TKE 弹超级节点,可以参考:https://cloud.tencent.com/document/product/457/78328
连接集群
可以在控制台管理集群,也可以通过开启内网/公网访问集群连接集群使用kubectl管理集群
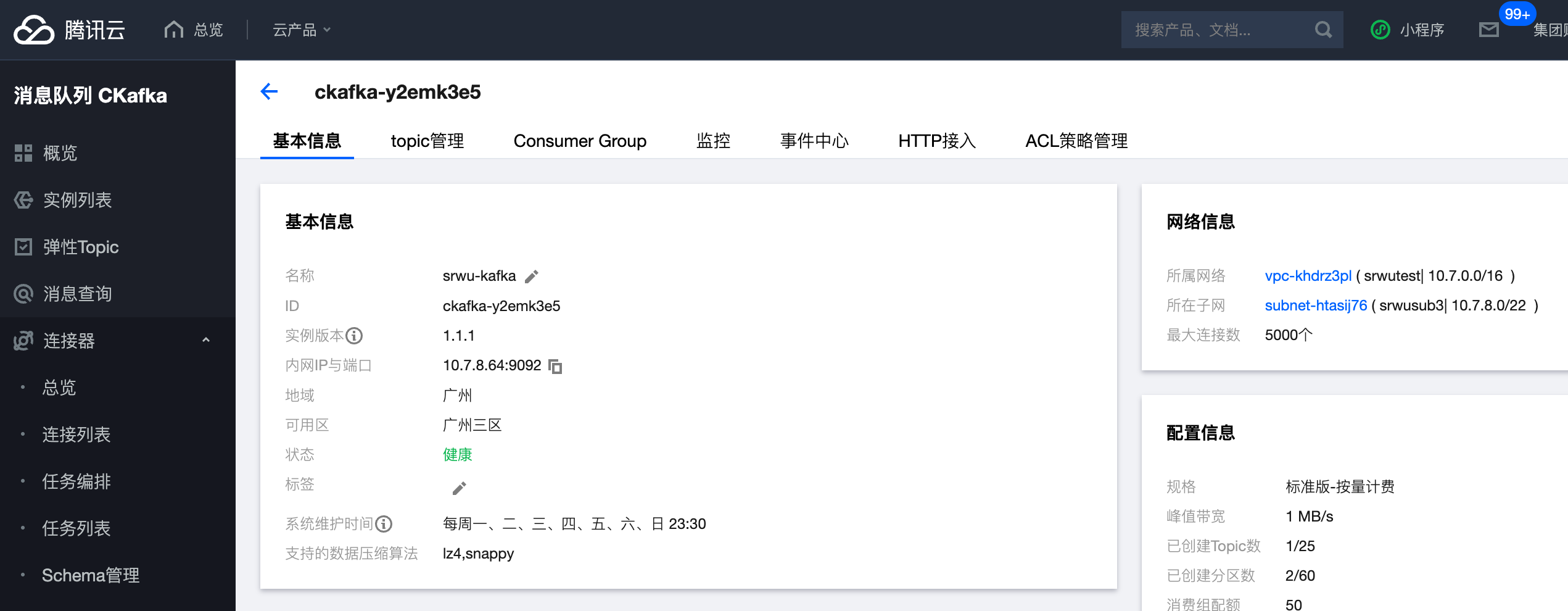
创建ckafka实例
- 需要注意的是如果是在腾讯云创建ckafka实例,vpc需要选择一致的,这样可以保证集群和ckafka内网访问
- 如果是自建ckafka实例,则需要开放公网,集群通过公网访问ckafka
- 如果是集群里的ckafka实例,则可以集群内访问即可
创建实例
参考:https://cloud.tencent.com/document/product/597/53207
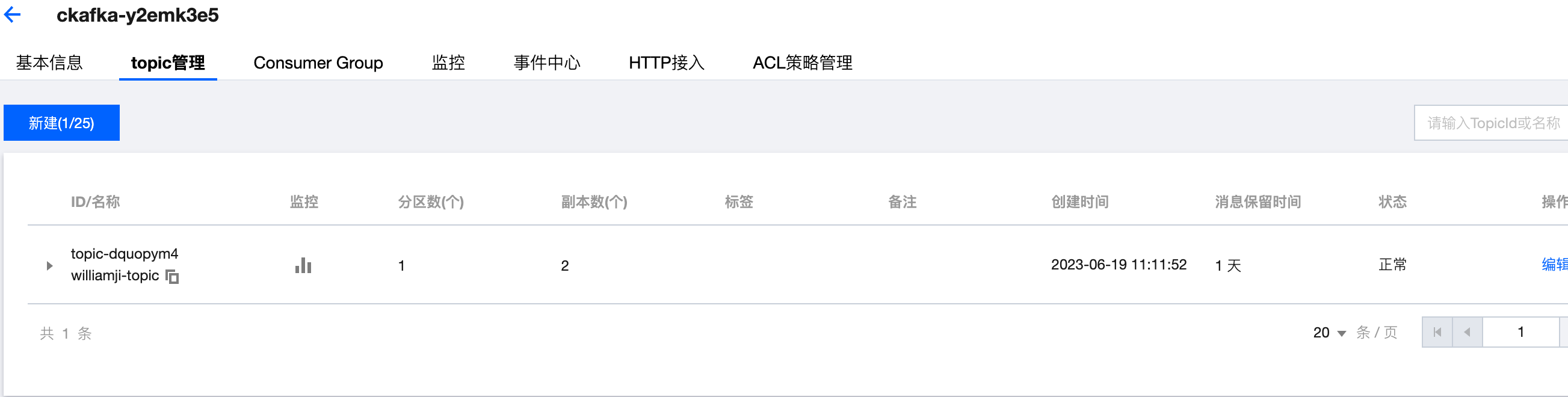
创建topic
参考:https://cloud.tencent.com/document/product/597/73566
部署filebeat组件
超级节点支持daemonset资源
Serverless集群里的超级节点实际上是子网虚拟池,并不是真正的节点,所以无法真正运行ds的pod,目前产品能力已经支持。参考如下配置
下载并配置filebeat清单
下载yaml文件参考:https://www.elastic.co/guide/en/beats/filebeat/current/running-on-kubernetes.html
最终参考配置如下(kube-system命名空间):
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat
labels:
k8s-app: filebeat
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
- nodes
verbs:
- get
- watch
- list
- apiGroups: ["apps"]
resources:
- replicasets
verbs: ["get", "list", "watch"]
- apiGroups: ["batch"]
resources:
- jobs
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: filebeat
# should be the namespace where filebeat is running
namespace: kube-system
labels:
k8s-app: filebeat
rules:
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs: ["get", "create", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: filebeat-kubeadm-config
namespace: kube-system
labels:
k8s-app: filebeat
rules:
- apiGroups: [""]
resources:
- configmaps
resourceNames:
- kubeadm-config
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: filebeat
namespace: kube-system
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: Role
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: filebeat-kubeadm-config
namespace: kube-system
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: Role
name: filebeat-kubeadm-config
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: kube-system
labels:
k8s-app: filebeat
data:
filebeat.yml: |-
filebeat.autodiscover:
providers:
- type: kubernetes
node: ${NODE_NAME}
hints.enabled: true
hints.default_config:
type: container
paths:
- /var/log/containers/*${data.kubernetes.container.id}.log
templates:
- condition:
equals:
kubernetes.namespace: default
config:
- type: container
paths:
- /var/log/containers/*${data.kubernetes.container.id}.log
processors:
- add_cloud_metadata:
- add_host_metadata:
output.kafka:
enabled: true
hosts: ["10.7.8.64:9092"]
topic: williamji-topic
keep_alive: 10s
version: 1.1.1
compression: none
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
spec:
selector:
matchLabels:
k8s-app: filebeat
template:
metadata:
annotations:
eks.tke.cloud.tencent.com/ds-injection: "true"
labels:
k8s-app: filebeat
spec:
tolerations:
- key: eks.tke.cloud.tencent.com/eklet
operator: Exists
effect: NoSchedule
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: filebeat
image: elastic/filebeat:8.8.1
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env:
- name: ELASTICSEARCH_HOST
value: elasticsearch
- name: ELASTICSEARCH_PORT
value: "9200"
- name: ELASTICSEARCH_USERNAME
value: elastic
- name: ELASTICSEARCH_PASSWORD
value: changeme
- name: ELASTIC_CLOUD_ID
value:
- name: ELASTIC_CLOUD_AUTH
value:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
runAsUser: 0
# If using Red Hat OpenShift uncomment this:
#privileged: true
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: data
mountPath: /usr/share/filebeat/data
- name: varlogcontainers
mountPath: /var/log/containers
readOnly: true
- name: varlog
mountPath: /var/log
readOnly: true
- mountPath: /data/eklet-pod-log/pods
name: ekletpodlog
readOnly: true
volumes:
- name: config
configMap:
defaultMode: 0640
name: filebeat-config
- name: varlogcontainers
hostPath:
path: /var/log/containers
- hostPath:
path: /data/eklet-pod-log/pods
type: ""
name: ekletpodlog
- name: varlog
hostPath:
path: /var/log
# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart
- name: data
hostPath:
# When filebeat runs as non-root user, this directory needs to be writable by group (g+w).
path: /var/lib/filebeat-data
type: DirectoryOrCreate
---- serviceaccount, role, clusterrole, rolebinding, clusterrolebinding是定义ds的pod资源incluster访问k8s资源的rbac权限
- daemonset: kube-system/filebeat定义了filebeat运行组件,注意spec.template.metadata.annotations添加eks.tke.cloud.tencent.com/ds-injection: "true"以及spec.template.spec.tolerations是针对超级节点注入daemonset做的配置。另外默认下载的yaml里镜像docker.elastic.co/beats/filebeat:8.8.1 是elastic私仓,可以改成dockerhub里对应的镜像elastic/filebeat:8.8.1
- configmap: kube-system/filebeat-config定义了filebeat组件启动参数,挂载到pod里 此示例使用filebeat.autodiscover配置实现kubernetes日志采集并配置了只采集default命名空间的容器日志,filebeat.autodiscover参考文档: filebeat.autodiscover配置。该功能也可以通过processors来实现,processors实现参考文档:processors配置样例如下
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: kube-system
labels:
k8s-app: filebeat
data:
filebeat.yml: |-
filebeat.inputs:
- type: log
symlinks: true
paths:
- /var/log/containers/*.log
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
in_cluster: true
default_matchers.enabled: false
matchers:
- logs_path:
logs_path: /var/log/containers/
processors:
- add_cloud_metadata:
- drop_event:
when:
equals:
kubernetes.namespace: "default"
output.kafka:
enabled: true
hosts: ["10.7.8.64:9092"]
topic: williamji-topic
keep_alive: 10s
version: 1.1.1
compression: none
---创建filebeat组件资源
可以在控制台点击"YAML创建资源",粘贴yaml清单,创建资源
可以使用kubectl工具创建yaml清单
部署成功后,查看ds对应的pod是否状态为Injection,如果是Injection表示成功,调度到该超级节点上的pod都会自动注入该ds的pod容器

测试日志采集
创建测试pod
在default命名空间下创建deployment: default/nginx,创建之后查看pod信息
[williamji@centos ~]$ kubectl get po
NAME READY STATUS RESTARTS AGE
nginx-76fc77dd5c-5gzss 2/1 Running 0 124m其中2/1 Running表示nginx pod运行正常,并且注入的daemonset pod容器也运行正常
测试ckafka采集
查看nginx pod运行日志
[williamji@centos ~]$ kubectl logs nginx-76fc77dd5c-5gzss
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
/docker-entrypoint.sh: Sourcing /docker-entrypoint.d/15-local-resolvers.envsh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
2023/06/19 07:29:52 [notice] 1#1: using the "epoll" event method
2023/06/19 07:29:52 [notice] 1#1: nginx/1.25.1
2023/06/19 07:29:52 [notice] 1#1: built by gcc 12.2.0 (Debian 12.2.0-14)
2023/06/19 07:29:52 [notice] 1#1: OS: Linux 5.4.119-1-tlinux4-0009-public-eks
2023/06/19 07:29:52 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 1048576:1048576
2023/06/19 07:29:52 [notice] 1#1: start worker processes
2023/06/19 07:29:52 [notice] 1#1: start worker process 29查看ckafka top信息确实有16条消息数
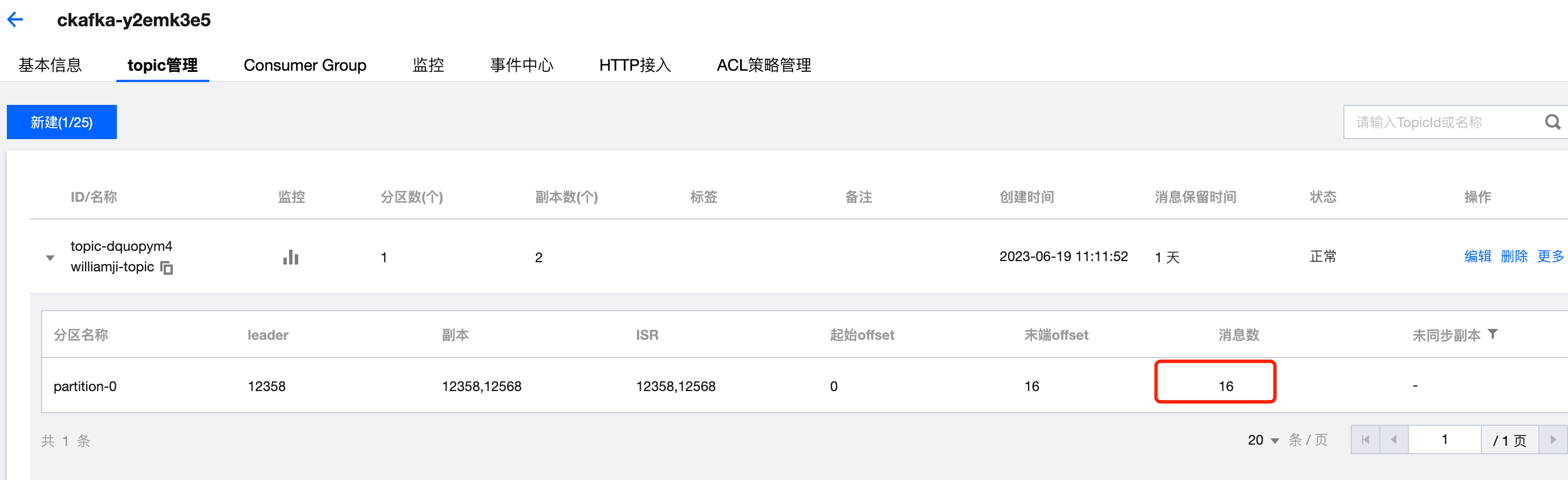
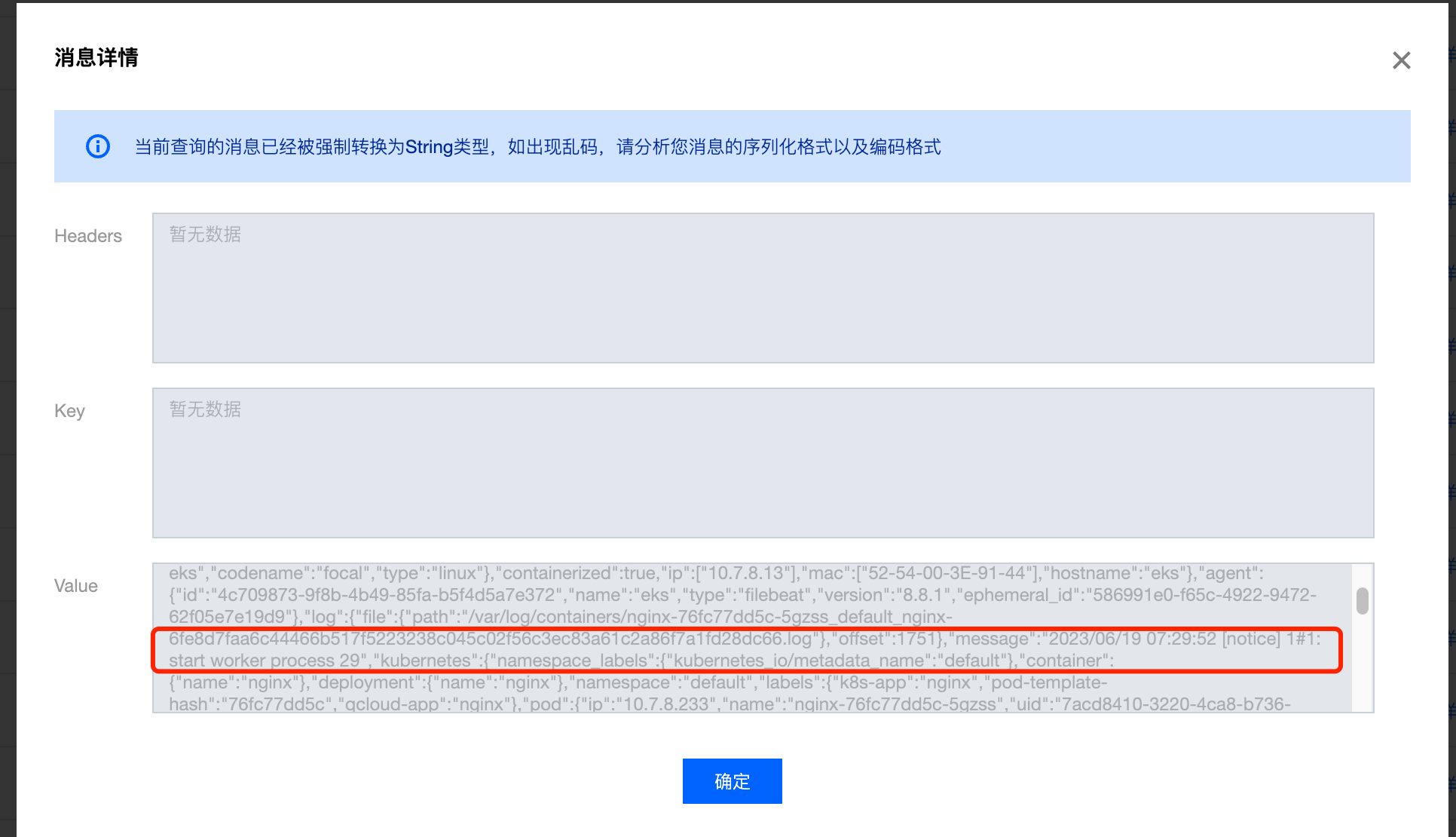
查看最后一条消息内容,与nginx pod日志内容一致,说明采集日志到ckafka成功
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号