改进 Elastic Stack 中的信息检索:对段落检索进行基准测试
原创
改进 Elastic Stack 中的信息检索:对段落检索进行基准测试
原创
点火三周
发布于 2023-07-20 10:37:37
发布于 2023-07-20 10:37:37

在之前的博客文章中,我们讨论了信息检索的常见方法,并介绍了模型和训练阶段的概念。在这里,我们将介绍基准测试,以公平的方式比较各种方法。请注意,基准测试的任务并不简单,不恰当的测试可能会导致人们对模型在现实场景中的表现产生误解。
从历史上看,BM25 和学习检索模型之间的比较一直基于有限的数据集,甚至仅基于这些密集模型的训练数据集:MSMARCO,这可能无法准确表示模型在数据上的性能。尽管这种方法对于展示密集模型在特定领域中对抗 BM25 的表现非常有用,但它并没有抓住 BM25 的关键优势之一:它能够在许多领域中表现良好,而无需监督微调。因此,使用这样一个特定的数据集来比较这两种方法可能被认为是不公平的。
BEIR 论文(“ BEIR:信息检索模型零样本评估的异构基准”,Takhur 等人,2021 年)提出了解决在通用环境中评估信息检索方法的问题。该论文提出了一个框架,使用来自不同主题的 18 个公开数据集来对最先进的检索系统进行基准测试。
在这篇文章中,我们使用这些数据集的子集来针对两个经过专门训练用于检索的密集模型以及 BM25 进行基准测试。然后我们将说明使用这些密集模型之一的微调策略可实现的潜在增益。我们计划在下一篇博客文章中重新讨论这个基准,因为它构成了我们在零样本设置中使用语言模型来增强 Elasticsearch 相关性所做的测试的基础。
BEIR 数据集
不同检索方法的性能可能存在很大差异,具体取决于查询类型、文档大小或主题。为了评估数据集的多样性并识别基准中潜在的盲点,使用经过训练来识别自然问题的分类算法来理解查询类型。结果总结于表 1 中。

表1.BEIR数据集的子集比较
在我们的基准测试中,我们选择不包含 MSMARCO,只是为了强调在不熟悉的环境中的性能。当用例数据的性质未知或资源限制阻止专门调整模型时,在不同于训练数据的设置中评估模型很有价值。
搜索相关性指标
选择适当的指标对于准确评估模型的排名能力至关重要。在各种可用的指标中,有三个指标通常用于搜索相关性:
- 平均倒数排名 (Mean Reciprocal Rank - MRR) 是最直接的指标。虽然它很容易计算,但它只考虑结果列表中的第一个相关项,而忽略单个查询可能具有多个相关文档的可能性。在某些情况下,MRR 可能足够了,但通常不够精确。
- 平均精度 (Mean Average Precision - MAP) 在排名列表中表现出色,并且适用于二元相关性评级(文档要么相关,要么不相关)。然而,在细粒度评级的数据集中,MAP 无法区分高度相关的文档和中等相关的文档。此外,仅当列表重新排序时才合适,因为它对顺序不敏感;搜索工程师会更希望相关文档首先出现。
- 标准化贴现累积收益 (Normalized Discounted Cumulative Gain - NDCG)是最完整的指标,因为它可以处理多个相关文档和细粒度的文档评级。这是我们将在本博客和未来博客中研究的指标。
所有这些指标都应用于固定大小的检索文档列表。列表大小可能会根据手头的任务而有所不同。例如,重新排序任务之前的初步检索可能会考虑前 1000 个检索到的文档,而单阶段检索可能会使用较小的列表大小来模仿用户的搜索引擎行为。我们选择将列表大小固定为前 10 个文档,这与我们的用例一致。
BM25 和域外密集模型
在我们之前的博客文章中,我们注意到密集模型由于其训练设计,需要针对特定数据集进行优化。虽然它们已被证明在此特定数据集上表现良好,但在本节中,我们将探讨它们在域外使用时是否保持其性能。为此,我们在Elasticsearch中使用默认设置和英语分析器将两种最先进的密集检索模型( msmarco-distilbert-base-tas-b 和 msmarco-roberta-base-ance-fristp )与 BM25 的的性能进行比较。

表2.BM25与最先进的密集模型基准测试的NDCG@10
这两个密集模型在 MSMARCO 上的性能均优于 BM25(如BEIR 论文中所示),因为它们是专门针对该数据集进行训练的。然而,它们在域外通常更糟。换句话说,如果模型不能很好地适应您的特定数据,那么与 BM25 相比,使用 kNN 和密集模型很可能会降低您的检索性能。
微调密集模型
前面的描述中对密集模型的描述并不是全貌。通过使用代表该用例的一些标记数据针对特定用例进行微调,可以提高它们的性能。如果您有一个经过微调的嵌入模型,Elastic Stack 是一个很好的平台,可以为您运行推理并使用 ANN 搜索检索类似文档。
有多种方法可以微调密集模型,其中一些方法非常复杂。然而,这篇博文不会深入探讨这些方法,因为这不是重点。相反,我们测试了两种方法来衡量无需大量特定领域训练数据即可实现的潜在改进。第一种方法 (FineTuned A) 涉及使用标记的正面文档,并从语料库中随机选择文档作为负面文档。第二种方法 (FineTuned B) 涉及使用带标签的正面文档,并使用BM25来识别与BM25的角度相似但未标记为正面的查询文档。这些被称为“hard negatives”。
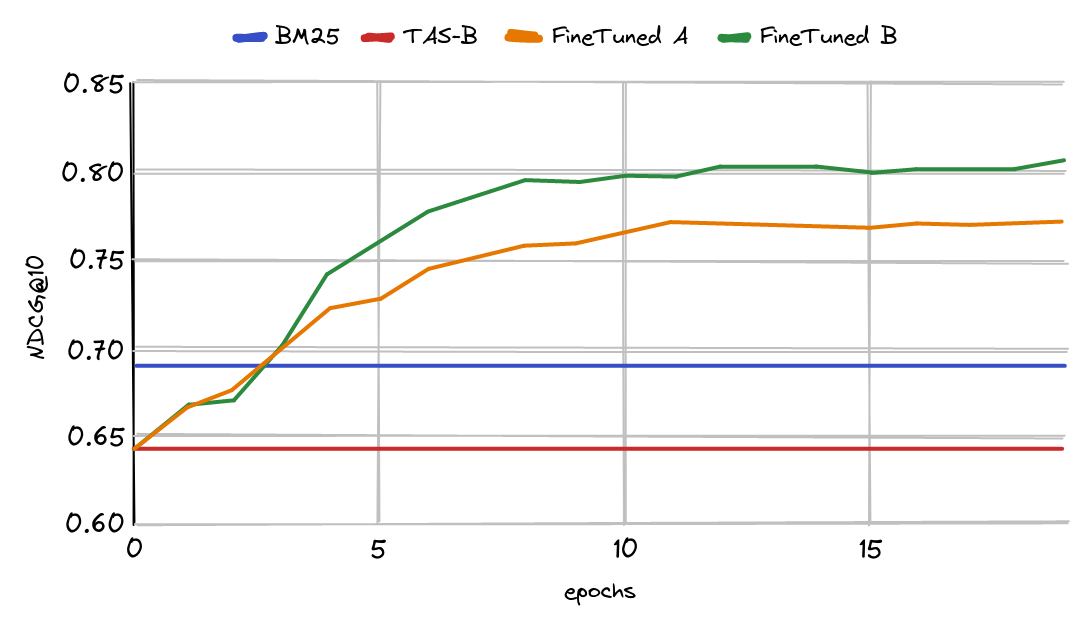
使用 SciFact BEIR 数据集中的 1000 个三元组微调 msmarco-distilbert-base-tas-b 的 NDCG@10 曲线
标记数据可能是微调中最具挑战性的方面。根据主题和领域的不同,手动标记正面文档可能既昂贵又复杂。不完整的标签也会给hard negatives 挖掘带来问题,对微调造成不利影响。最后,随着时间的推移,数据库中主题或语义结构的变化将降低微调模型的检索准确性。
结论
我们使用 13 个数据集建立了信息检索的基础。BM25 模型在零样本情况下中表现良好,即使是最先进的密集模型也很难在每个数据集上进行竞争。这些初始基准表明,如果没有适当的域内训练,当前的 SOTA 密集检索就无法有效使用。调整模型的过程需要标记工作,这对于资源有限的用户来说可能不可行。
在我们的下一篇博客中,我们将讨论不需要创建标记数据集的高效检索系统的替代方法。这些解决方案将基于混合检索方法。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号