Nvidia_Mellanox_CX5和6DX系列网卡_RDMA_RoCE_无损和有损_DCQCN拥塞控制_动态连接等详解-一文入门RDMA和RoCE有损无损
原创
Nvidia_Mellanox_CX5和6DX系列网卡_RDMA_RoCE_无损和有损_DCQCN拥塞控制_动态连接等详解-一文入门RDMA和RoCE有损无损
原创
晓兵
修改于 2025-11-05 20:35:20
修改于 2025-11-05 20:35:20
简介
随着互联网, 人工智能等兴起, 跨机通信对带宽和时延都提出了更高的要求, RDMA技术也不断迭代演进, 如: RoCE(RDMA融合以太网)协议, 从RoCEv1 -> RoCEv2, 以及IB协议, Mellanox的RDMA网卡cx4, cx5, cx6/cx6DX, cx7等, 本文主要基于CX5和CX6DX对RoCE技术进行简介, 一文入门RDMA和RoCE有损及无损关键技术
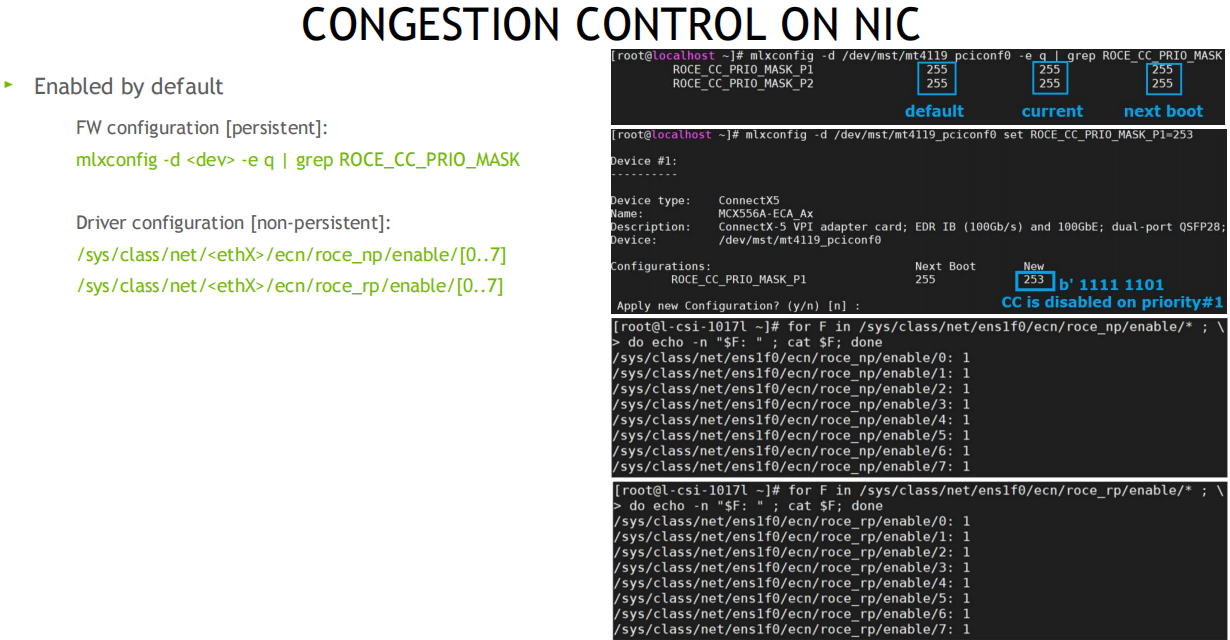
Nvidia Mellanox重于诸多网络细节问题的实现, 把更多的选择留给了用户(用户理解后选择启用或禁用)
术语
RoCE: RDMA融合以太网, 继承RDMA所有的优势
WQE: 工作队列元素, 可发音(wuki)
CQE: 完成队列元素, 可发音(cookie)
RDMA Atomic: 原子操作, 主要用于分布式锁, Redis缓存等场景
DCQCN: 数据中心量化拥塞通知
ZTR(Zero Touch RoCE)
PCP(Priority Code Point): 优先级代码点用于对网络流量进行分类和管理,并在第 2 层以太网中提供 QoS。 它使用 VLAN 标头中的 3 位 PCP 字段对数据包进行分类。 差分服务或 DiffServ 使用 IP 标头中 8 位 DS 字段中的 6 位 DSCP 进行数据包分类
ECN: 显式拥塞通知 (Explicit Congestion Notification) 是互联网协议和传输控制协议的扩展,在 RFC 3168 (2001) 中定义。 ECN 允许在不丢失数据包的情况下进行网络拥塞的端到端通知。 ECN 是一项可选功能,当底层网络基础设施也支持时,可以在两个启用 ECN 的端点之间使用
DSCP(differentiated services code point): 差分服务代码点, 差分服务或 DiffServ 是一种计算机网络体系结构,它指定了一种在现代 IP 网络上分类和管理网络流量并提供服务质量 (QoS) 的机制。 例如,DiffServ 可用于为语音或流媒体等关键网络流量提供低延迟,同时为 Web 流量或文件传输等非关键服务提供尽力而为的服务。DiffServ 在 IP 标头的 8 位差分服务字段(DS 字段)中使用 6 位差分服务代码点 (DSCP),用于数据包分类。 DS 字段取代了过时的 IPv4 TOS 字段
Cos: class of service 服务分类
CX-6 DX: Datacenter系列
OOS: out of sequence, 出现乱序
PSN: package sequence num, 包序号, 一个包按MTU拆分成多个包, 每个包有个序号PSN
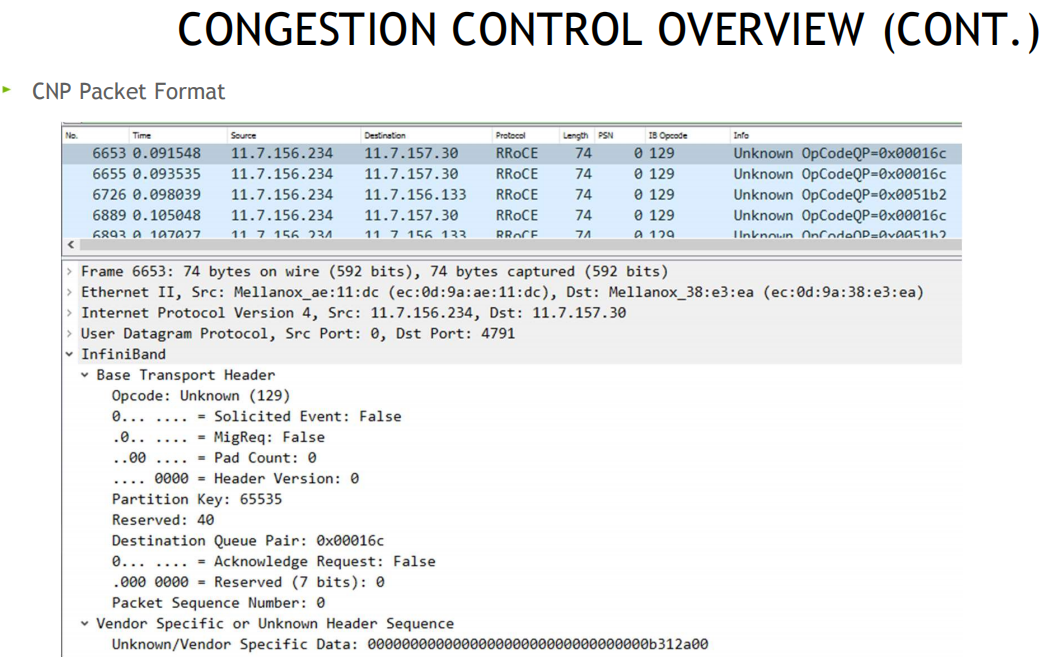
CNP: congestion notification packet 拥塞通知包
RP: reaction point 响应通知的一端(被动方)
NP: notification point 发起通知的一端(主动方)
TO: trade off, 权衡
BDP: bandwidth-delay product 在数据通信中,带宽延迟乘积是数据链路容量(以比特/秒为单位)与其往返延迟时间(以秒为单位)的乘积
前置知识
GoBackN机制
RDMA基本概念
RDMA如何工作
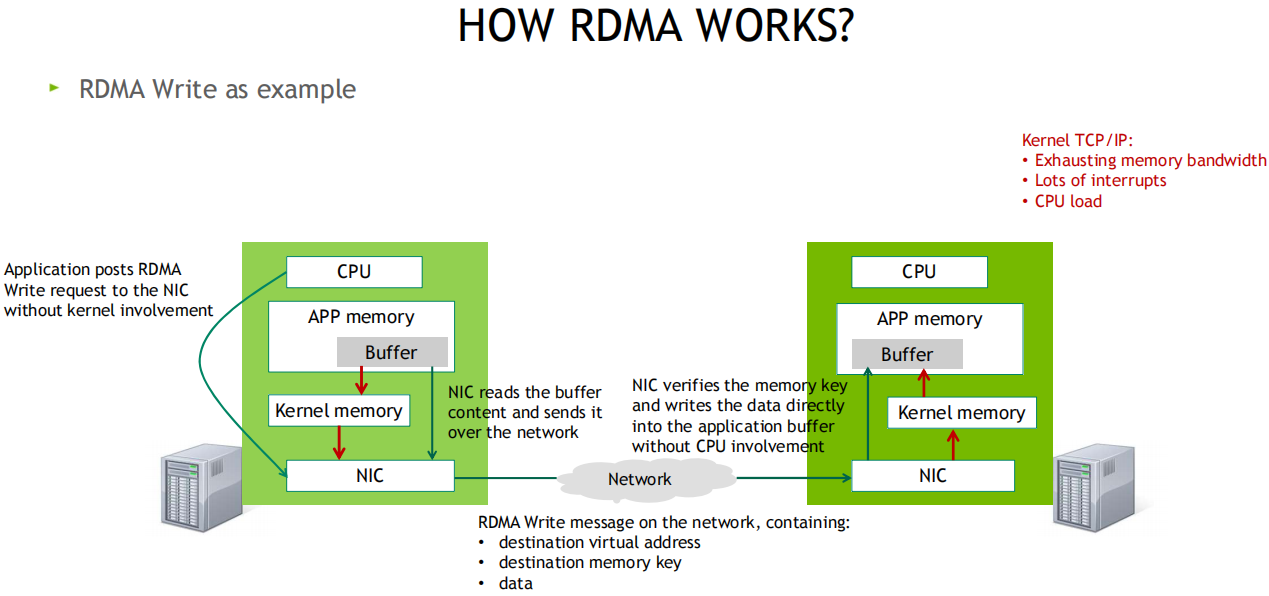
发送端CPU准备好发送数据后会敲一次门铃, 而接收方收到网卡数据后不会通知CPU(降低开销)
IBA通信技术栈

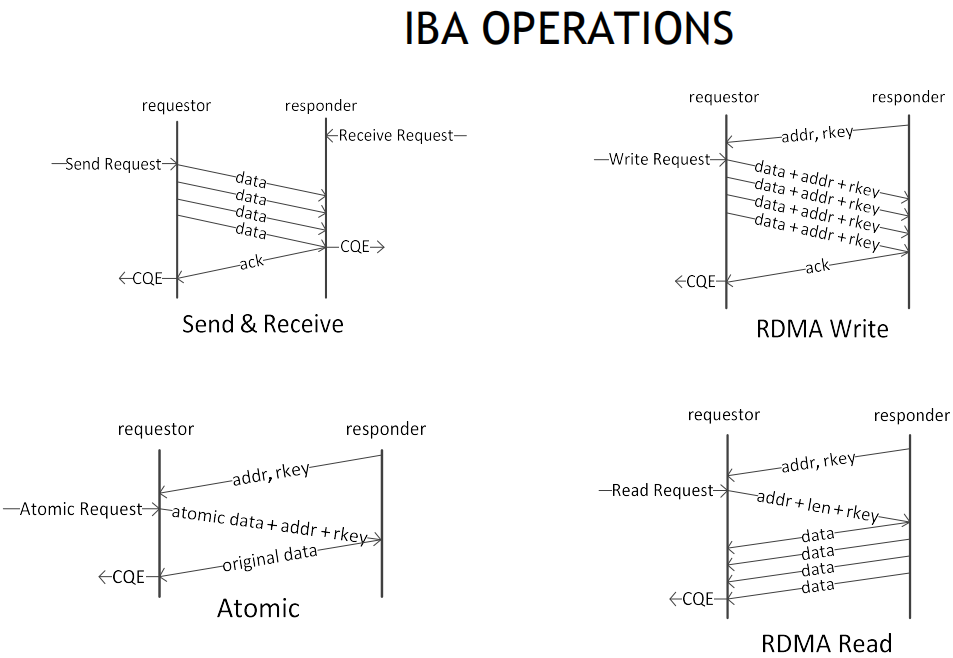
RDMA常见操作
RoCE与RoCEv2对比
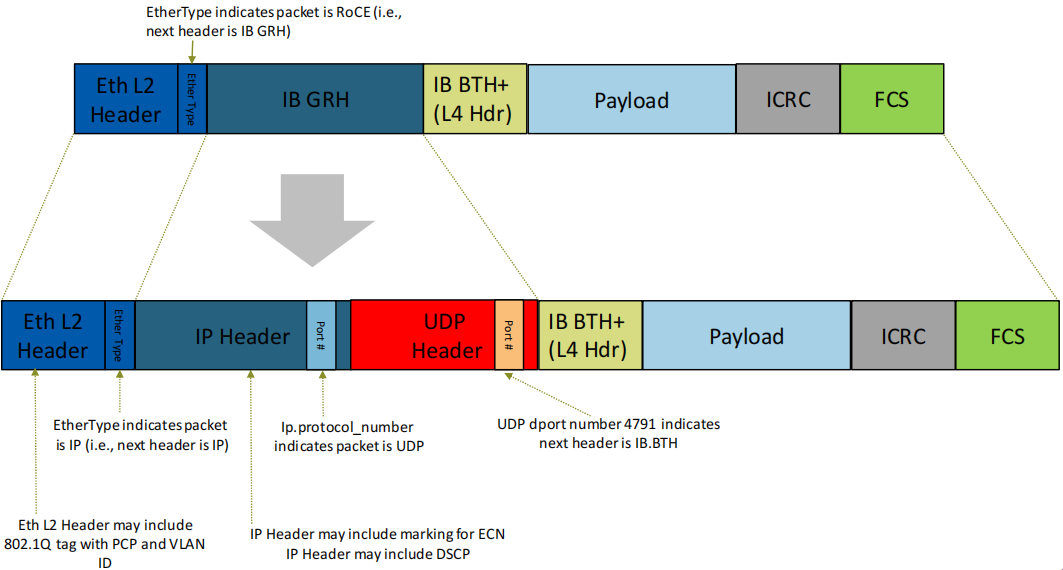
- RoCEv2没有RoCE的GRH(全局路由头)
- L2二层以太头中可能包含了802.1Q标签(PCP或VLAN_ID)
- RoCEv2的IP头可能包含ECN标记, 和DSCP
- IP协议端口号表明该包是UDP报文
- UDP目的端口4791(保留端口)表明, 下一个头是IB的BTH(BasicTranspotHeader 基本传输头占用12字节)
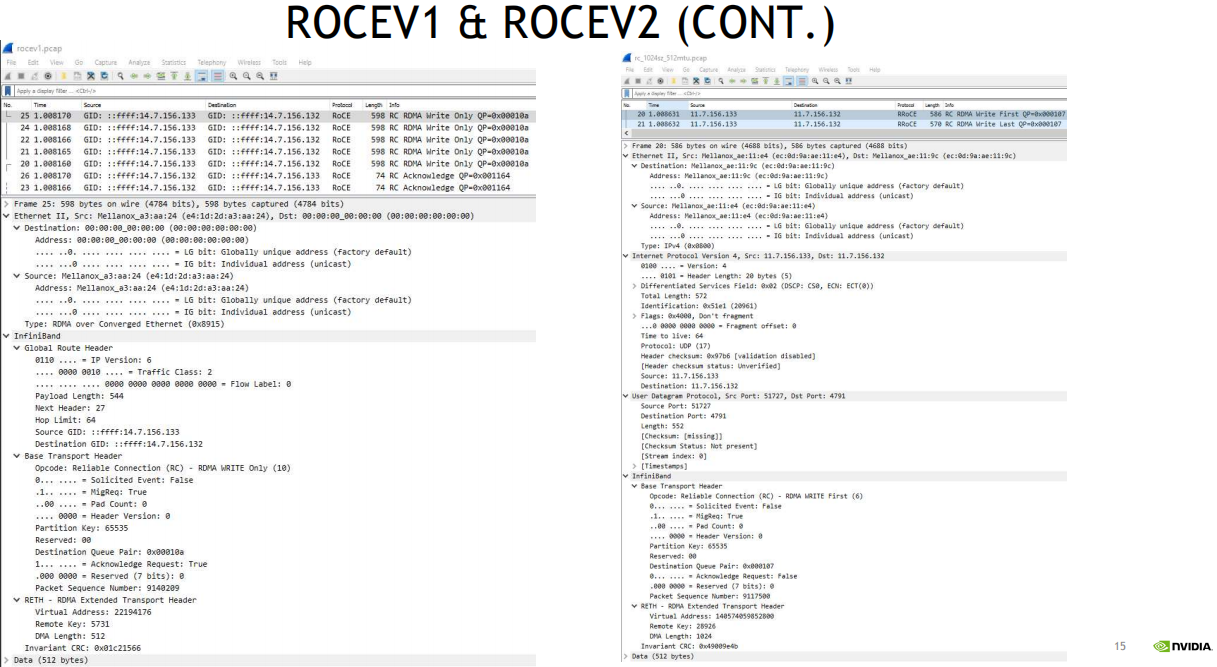
- 可通过抓包对比两者差异(注意IPv6与IPv4的差异), 如下图所示:

如何让RoCE工作的更好
配置流控(L2 PCP / L3 DSCP)
Sender发送方 -> Receiver接收方
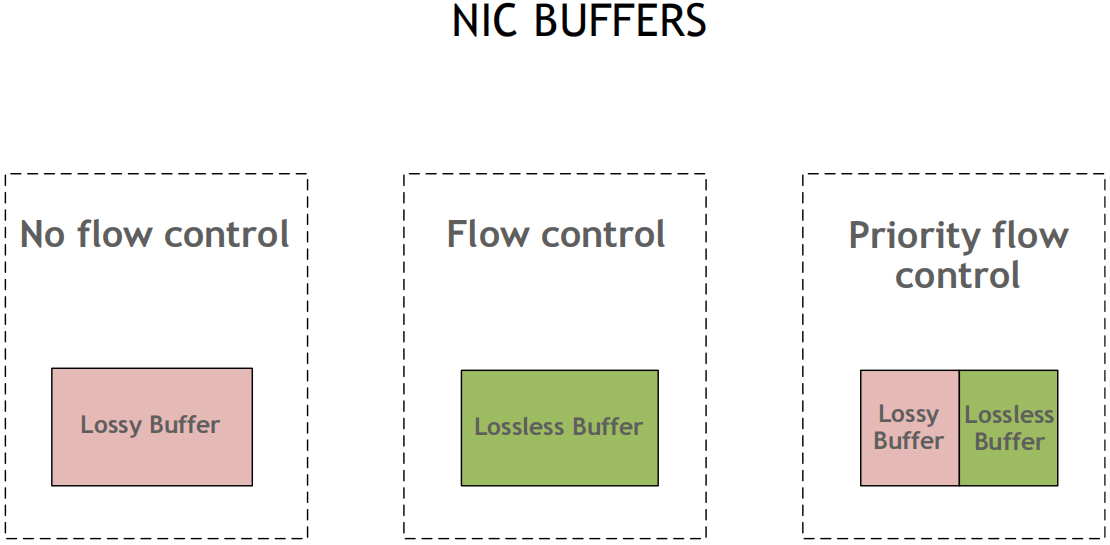
流控为链路层协议, 在接收方的RX Buffer接收缓存区设置高和低水位, 接收方Buffer填满时, 发送暂停帧Pause给发送方, 发送方XOFF, 并暂停发包, 等接收方释放出接收Buffer后, 给发送方发送一个UN-Pause帧, 发送方XON, 重新开始发送, 该方案不会跨越交换机

多流问题: 暂停帧不区分流, 会影响其他流
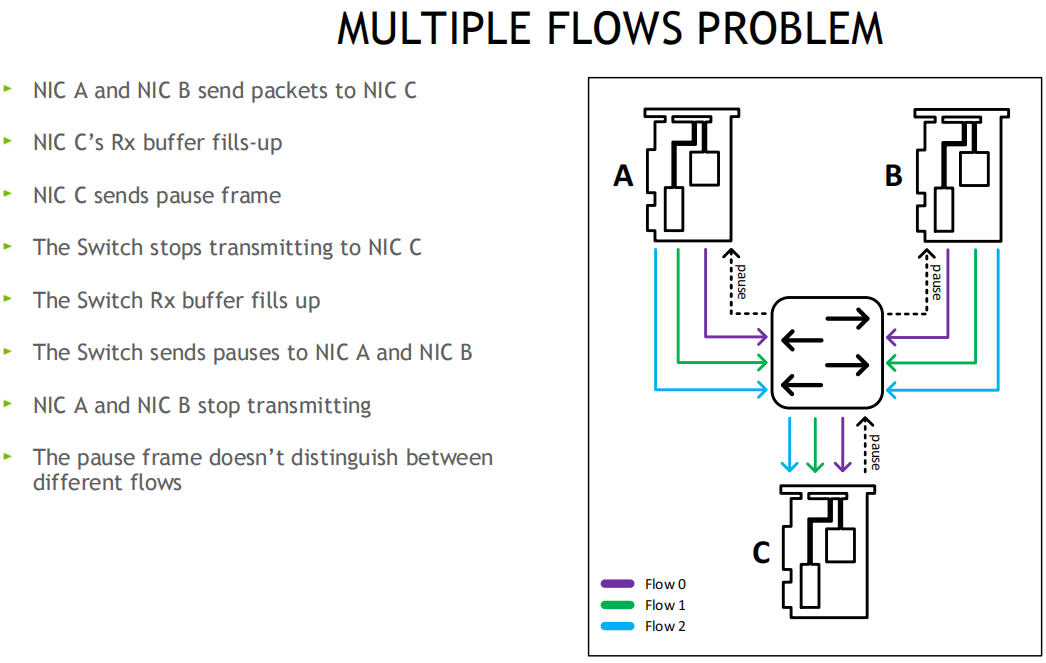
解决: 无损方案, PFC优先级流控, 用8个优先级(0-7), 独立控制每个流分类服务CoS, 网卡可将Buffer切分, 比如一半启动无损, 一半保持有损

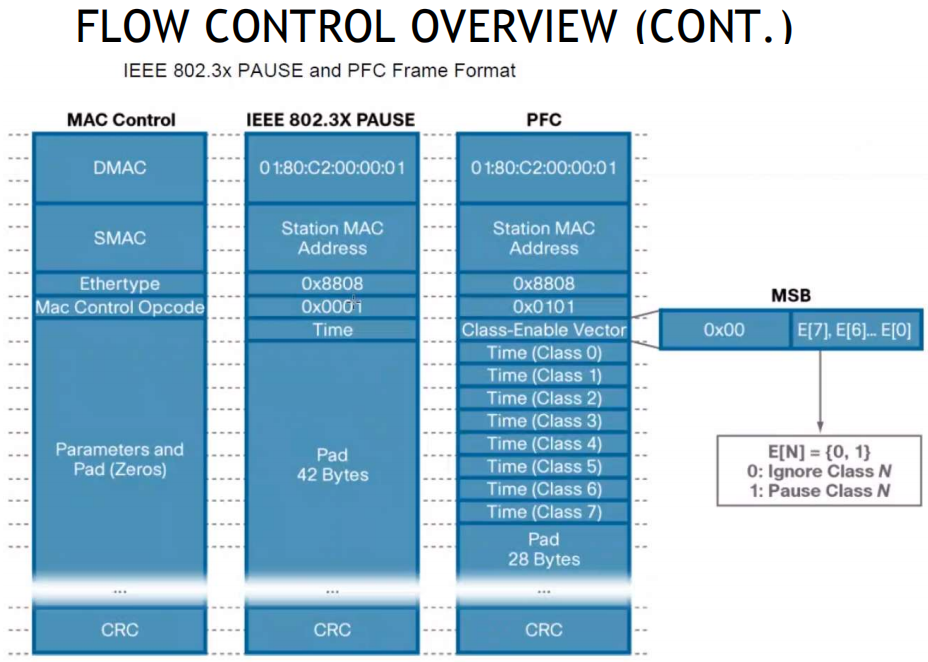
802.3x PAUSE帧和PFC帧格式参考
主机侧: 可通过ethtool, mlnx_qos工具查看和配置PFC流控, 交换机侧也需要做对应的配置, 如果是跨机房,也需要保持类似的配置(无损痛点之一, 有时候交换机不在咱们得控制范围, 所以这种规模的网络, 限制了无损的配置)

拥塞管理/算法(DCQCN, ZTR_RTTCC,自定义PCC算法)
拥塞问题:
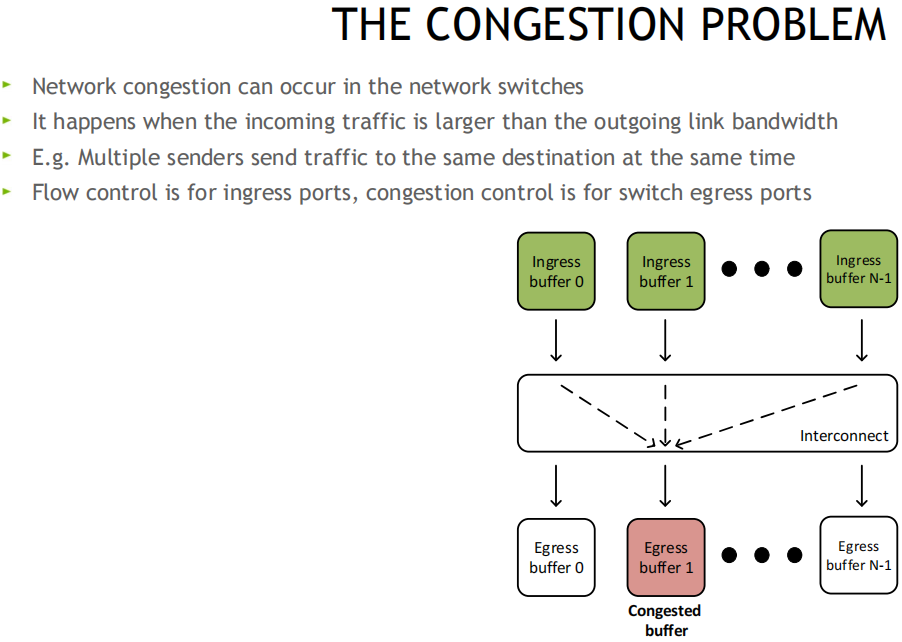
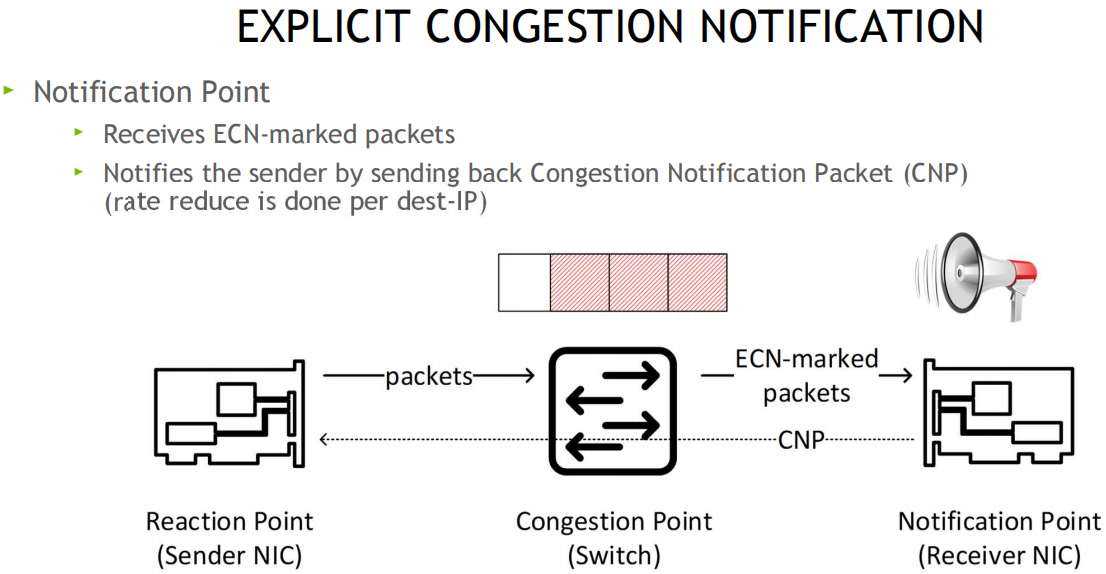
ReactionPoint 响应端(发送方网卡) --------------- Congestion Point 拥塞点交换机 -------------------- NotificationPoint 通知发起方(接收方网卡)
原理: 当交换机检测到拥塞时, 将出口包打上ECN标记, 接收端收到ECN包后, 因为有发送端的QP信息, 发送拥塞通知包CNP给发送端, 这时候假如发送端收到多个接收端发来的ECN包, 发送方需要有一个分布式拥塞控制算法(DCQCN, 由Mellanox和微软共同开发), 来降速和调度发送, 一段时间发端没有收到CNP时, 这个时候需要恢复流量, 目前是按照三个阶段来恢复, 快速恢复FR(fast recovery) -> 二分递增AI(additive increase) -> 更快增加HAI(hyper increase)
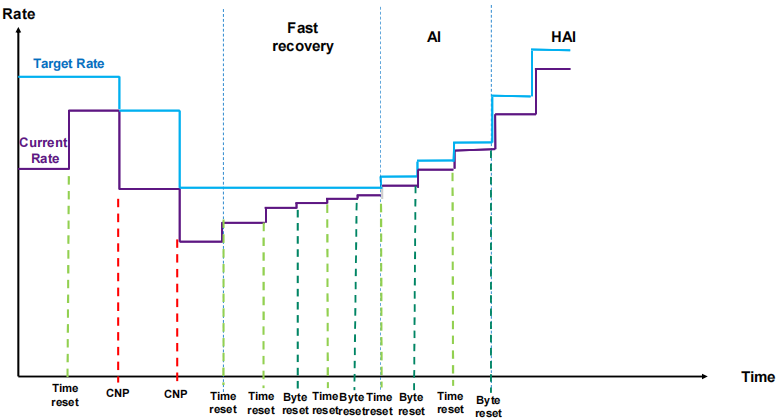
在cx6 DX网卡上可自定义拥塞控制算法, 比如阿里和google都有自己的拥塞管理算法, 算法参考:
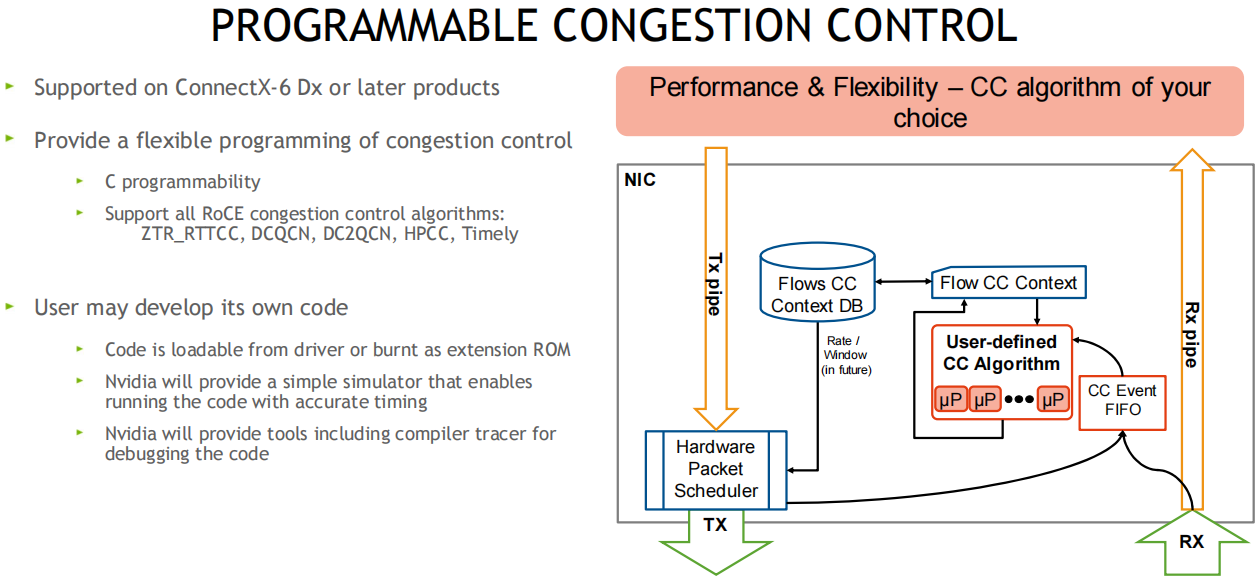
可编程的拥塞控制算法
1. 可用算法调整硬件,微核等, 可不用配置交换机就做到拥塞控制
2. 专门的团队也在做算法
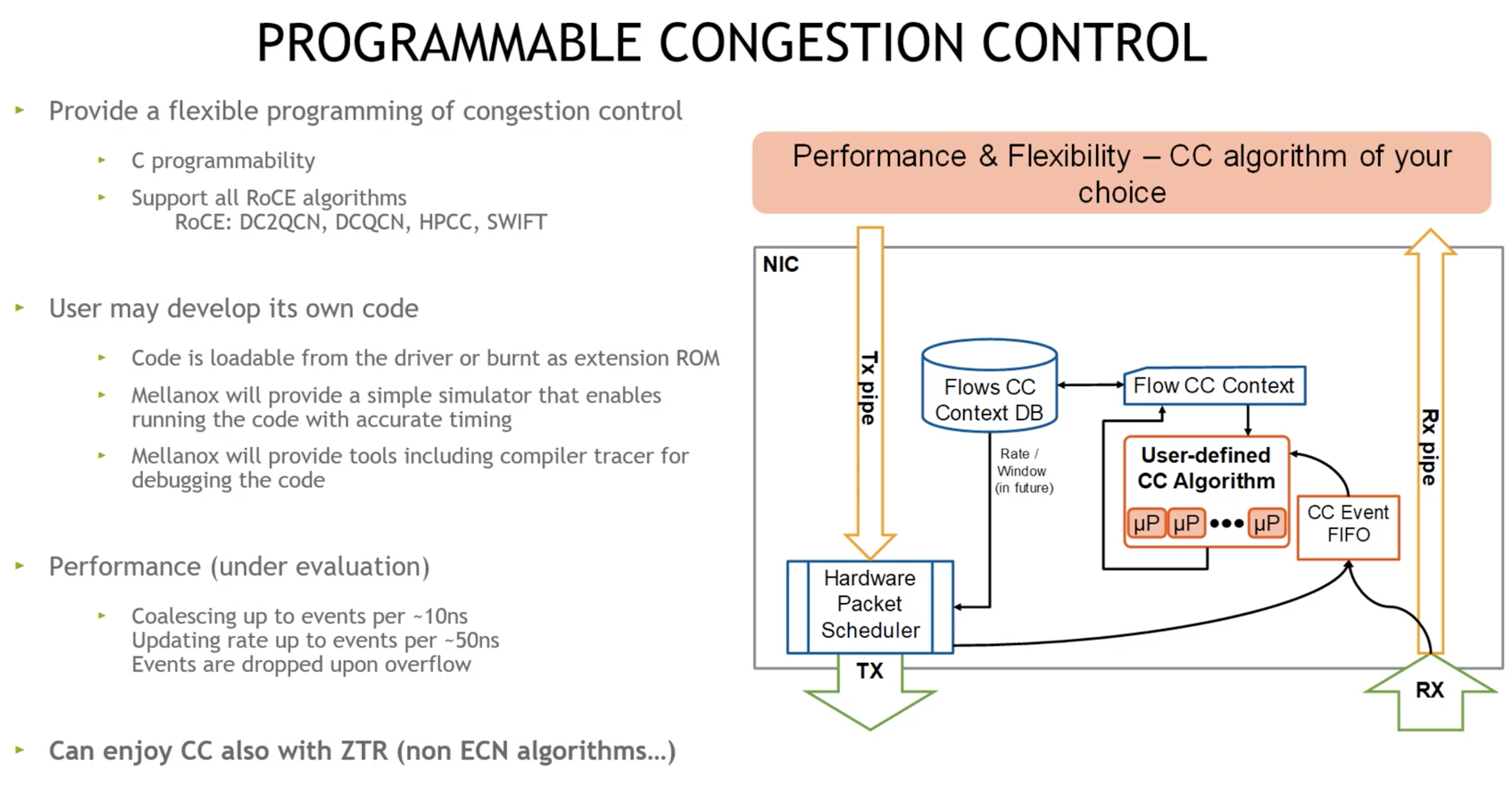
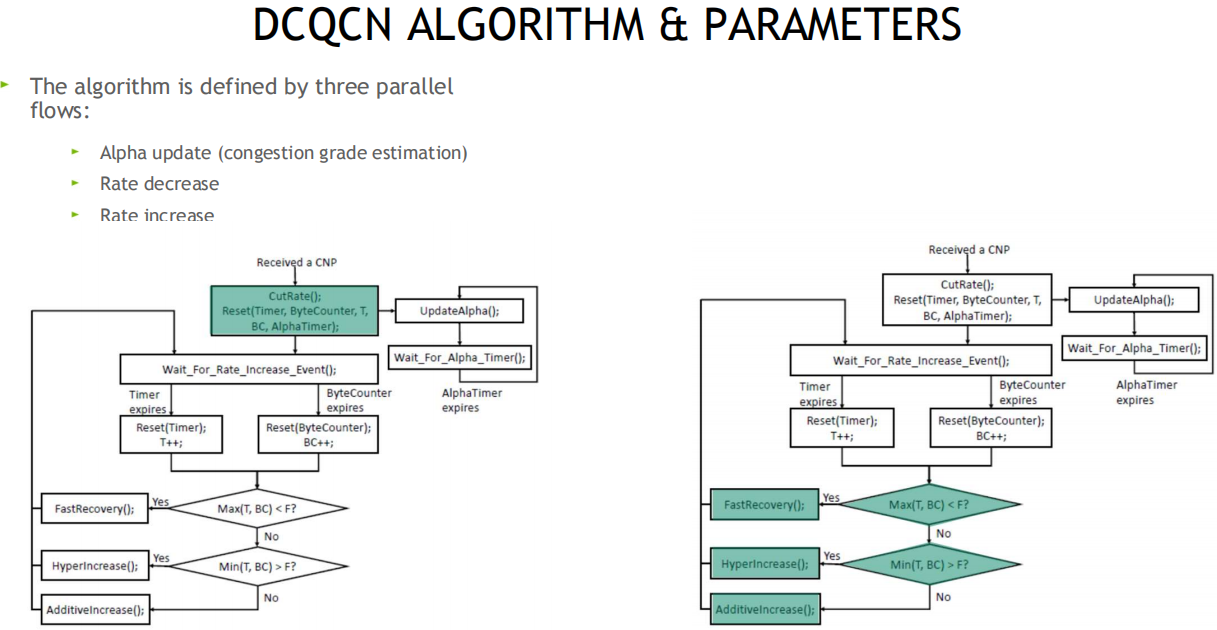
DCQCN算法及参数以及流程简图参考

CNP帧格式:
配置流控:
QoS保证质量
主要是二层的PCP和三层的DSCP, 进行流分类, 保证服务质量

网卡接收缓冲区的细粒度控制
将RX Buffer切片, 比如8片, 进行更细粒度的优先级队列控制

其他
一键配置: 可通过脚本检测和配置, 用于管理 RoCE 部署的系统高性能网络接口配置的命令行实用程序, 参考: https://github.com/NVIDIA/doroce-linux
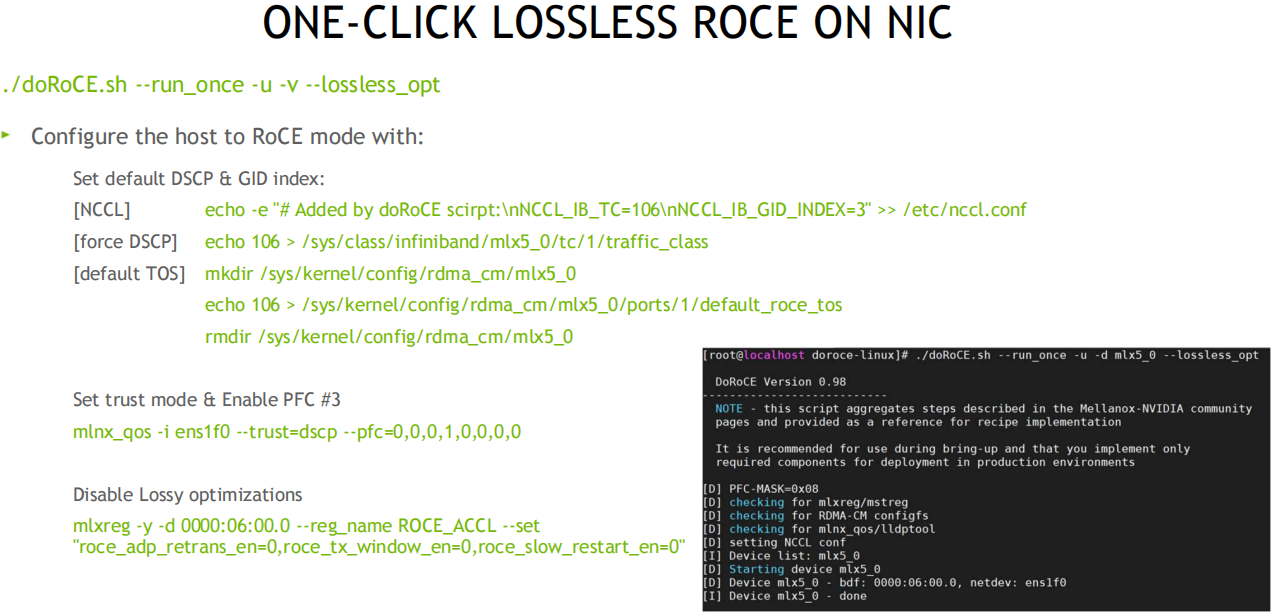
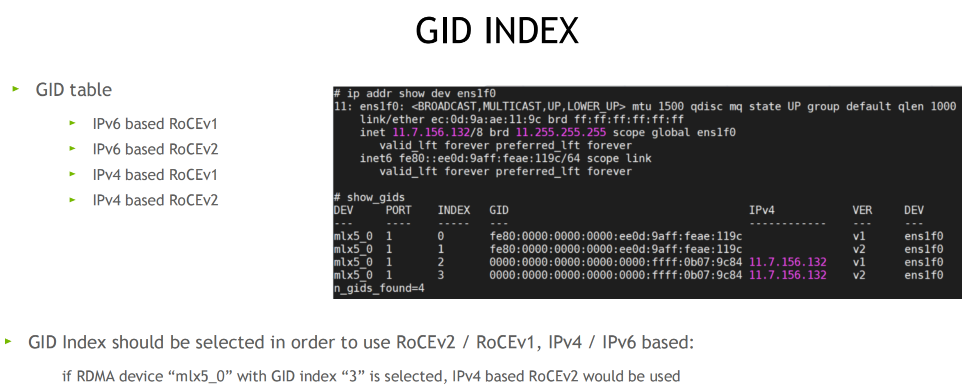
GID index
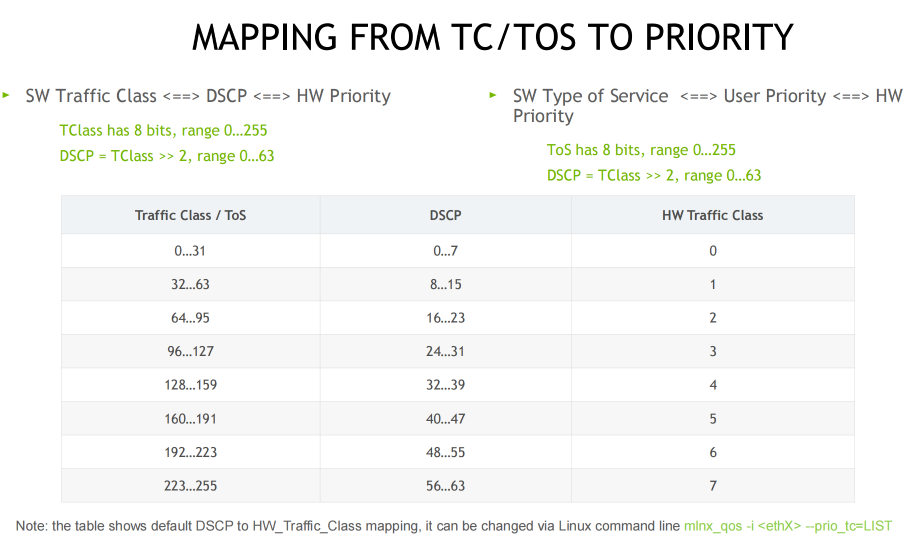
RoCEv2 流分类(TC/TOS/优先级)

无损带来的挑战

无损缺点
配置复杂
拥塞严重时会带来暂停发送的问题
- 延迟增加
- 暂停帧风暴PauseStorm
- 配置复杂, 每个Fabric节点需要保持一致的无损配置
- 受限制, 比如大型网络, 或客户的网络中, 没有权限去配置无损
为了更好的推广和使用RoCE, 有损配置解决了部分无损的配置难题
有损RoCE(CONNECTX-5/6 DX系列网卡)功能支持表(6大功能)
注意: 以下功能列表中, cx4只支持AR(自适应重传),该功能在cx4上只是一个过渡版本,在cx5上得到了更好的支持

CX-5
慢重启(SlowRestart, 丢包后的快速处理(响应) 默认打开)
1. 接收方收到乱序包(PSN2丢失)后, OOS计数器加1, 并在回复给发送端的oos_nack中带psn编号(psn2), 并发送CNP
2. 发送端收到消息后, 增加错误计数, 后面的包以较低的速率发送(防止继续丢包)
3. 硬件计数器中可查看相关错误计数
4. 其他: ecn_mark, mst status -v, ls /sys/class/net/ens3f0/roce_rp/enable/, 8个优先级(0~7), rp: reaction_point 这里只发送端

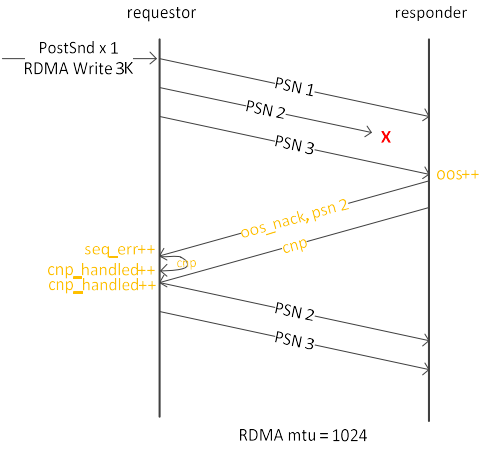
硬件丢包时, 发送方给自己发送一个CNP, CNP计数加1
接收方发送一个OOS_NACK(乱序包, 消极应答)和CNP, 发送方收到CNP后, 计数器再加1, 并降低速率
cx5默认启用该功能
新建QP连接时的慢重启(默认关闭)及计数器详解
1. 丢包时, 新建QP也需要被控制在较低的速率去发包
2. 新启动的流量的计数器都在发送端(如下), 收到几次慢重启控制, 自己给自己的拥塞通知包, QP从挂起到发送状态(suspend resume 暂停恢复),
3. QP超时由IB协议规定(闲置QP需要应用程序控制, 以提高QP利用率)
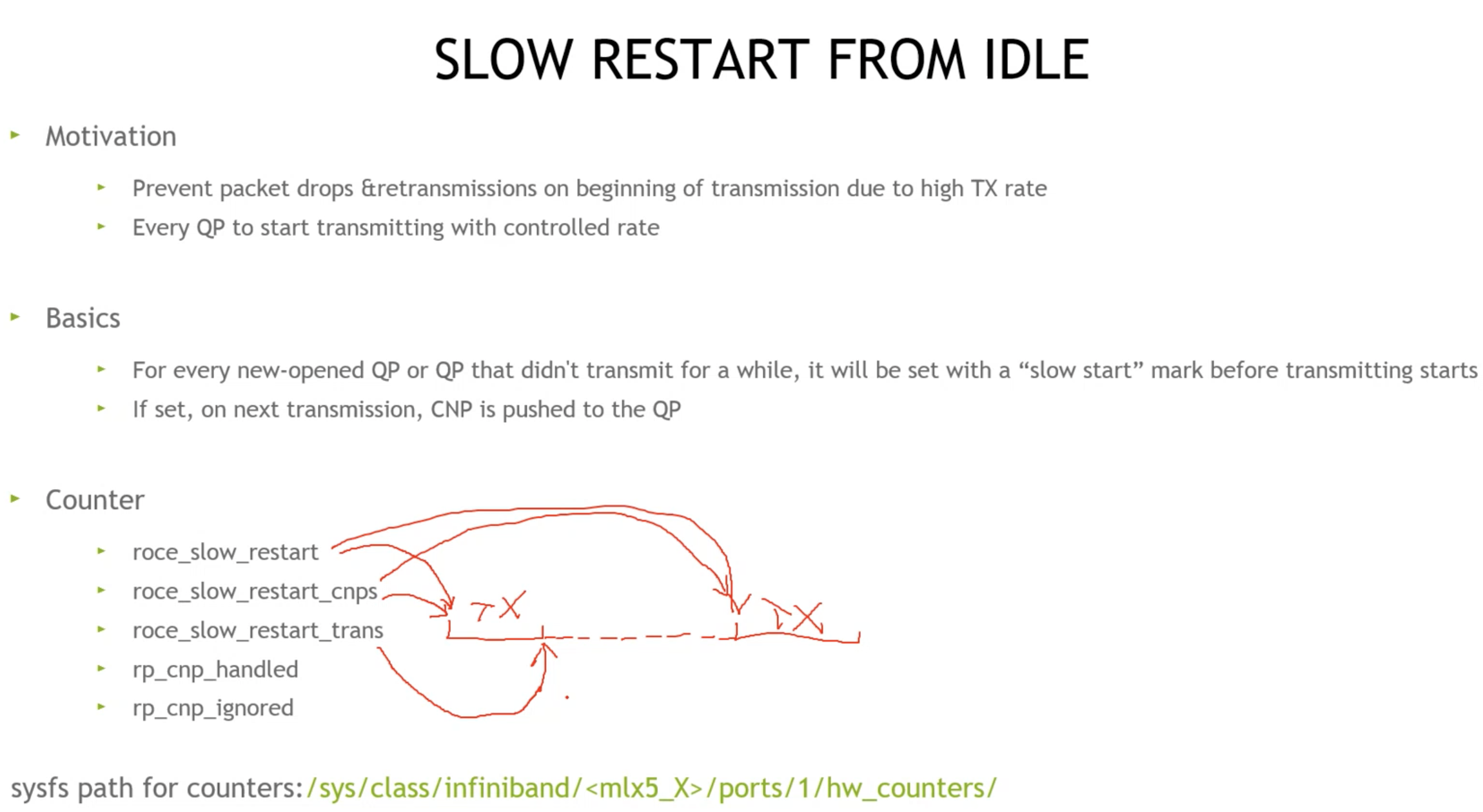
丢包重传, 还是新建QP或暂停重启QP, 查看固件信息(FW)

慢重启, 适用于长流量, 不适合发送紧急控制命令类的短流量QP, 相比tcp的控制, 要做的简单一些, 为了权衡, 受到慢重启控制的QP, 会在后续的DCQCN(动态拥塞控制算法中)得到限速上均衡
慢启动(默认关闭)
发生慢重启后, 其他QP启动后, 以受限速率发包, 直到拥塞解除
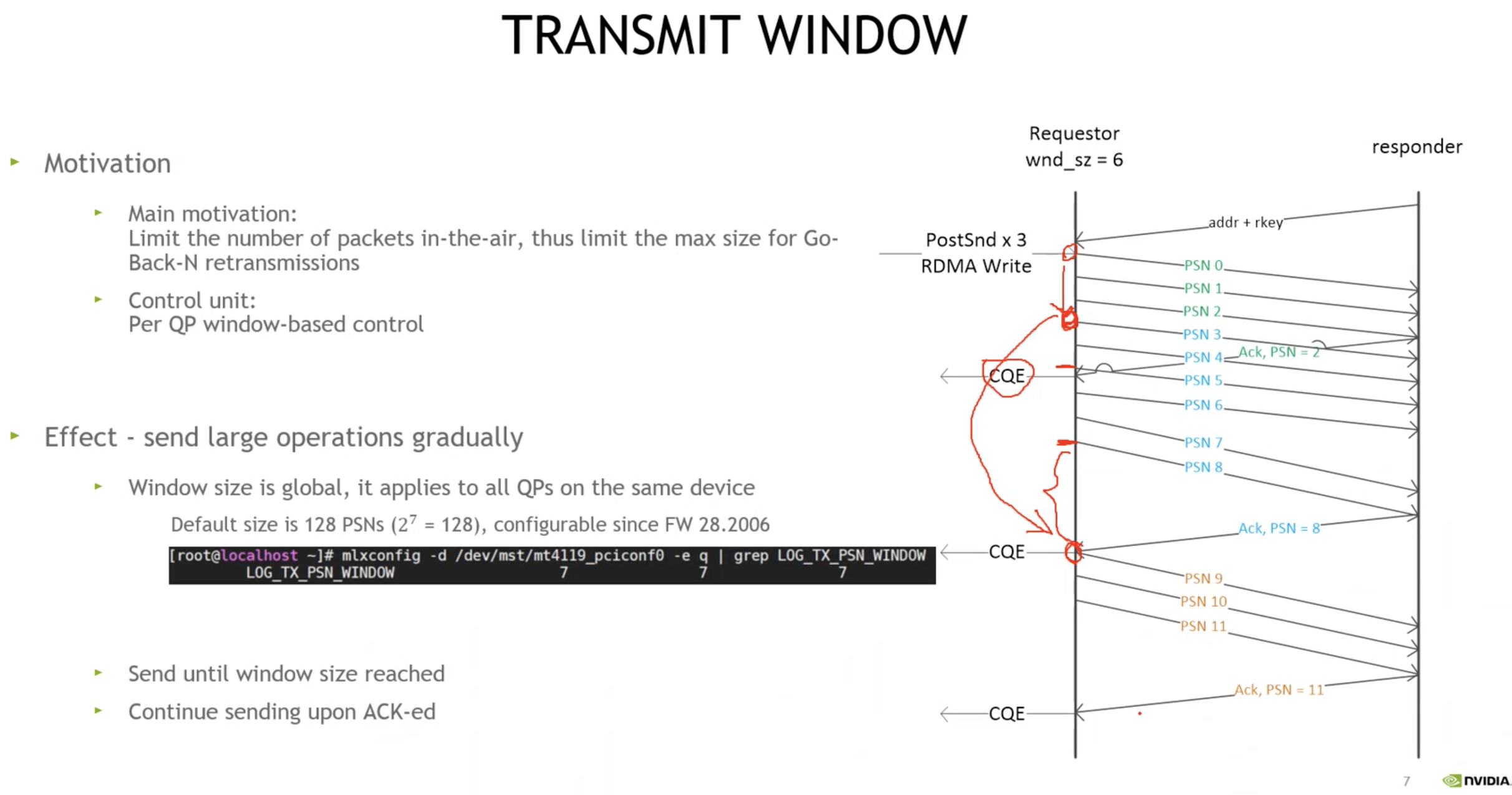
传输窗口(默认2的7次方=128PSN)
网络拥塞时, 原来的Go-BackN可能需要重传大量已经到达接收端但是被忽略的包
现在以一个窗口大小, 降低重传代价
1. TCP是可动态控制, 这里以QP为单位, 固定窗口大小
2. outstanding打满窗口大小: 没有到ACK或NACK的包
3. 收到ACK后,PSN窗口往下滑
4. 请求方下发3个1K的RDMA write, 收到ACK后, 下滑窗口(假如窗口为6个PSN), 产生CQE
5. 图中间距越大表示等待时间越长
6. IB规定ACK回复规范, 收到1个就需要回复1个(最后1个PSN), 为了防止死锁, 每8个PSN会回复1个ACK, 可参考BDP流控(Bandwidth Delay Product 带宽延迟积的影响)
自适应重传超时(建议打开, Nvidia Mellanox私有实现,可对比博通或其他实现)

发送方动态调整ACK_TIMEOUT(比如发送了3个PSN, 等接收方回复PSN3的ACK时间超时了)
1. 超时是如何发送的? (分别对应右边三个小图)
(1) 最后1个PSN丢失,响应端无操作,发送端最终触发确认超时(ack-timeout), 整个MSG需要重传, 该流程无任何异常, OOS, ACK和NACK也没有, 用户程序可以给QP设置用户级别的超时配置(参考编程手册), 如下QP的属性配置: attr->timeout, 连接属性
区分用户超时(较大)与硬件超时(ADAPTIVE_TIMER 小于用户超时)
(2) 2k数据分2个PSN, ACK丢失, 请求方没有等到ACK, 超时后重传整个消息, ACK没有重传机制
(3) 3个PSN, 丢失了PSN2, 触发OOS_NACK, 结果丢失该NACK, 类似2中, 超时后重传整个消息
2. 用户超时一般设置的比较大, 硬件超时以较小的值, 上限是用户超时时间, 动态调整, 更快速的响应消息重传
3. 计数器, roce_adp_retrans(hw), local_ack_timeot_err(sw,hw)
4. IB规范中的超时计算公式, 由指数函数来保证至少为4.096us(微秒), 该算法也用于CM建连超时

自适应超时设置的依据(硬件实现, 以小值开始, 结合RTT时间, 动态调整, 理想timeout为RTT时间)
1. 每个QP加一个上下文信息, 硬件事件处理, NACK事件处理, 每个QP不一样(非全局配置)
2. 软件看不到ACK和NACK, 只能看到CQE
3. 每个QP有不同的RTT, 让timeout接近RTT(网络理想效果), 每个QP的RTT也是动态变化, 依据是判断是否进入队列,
4. 特别的, 该功能对 RDMA READ 比较好

以下功能在CX-6 DX上支持
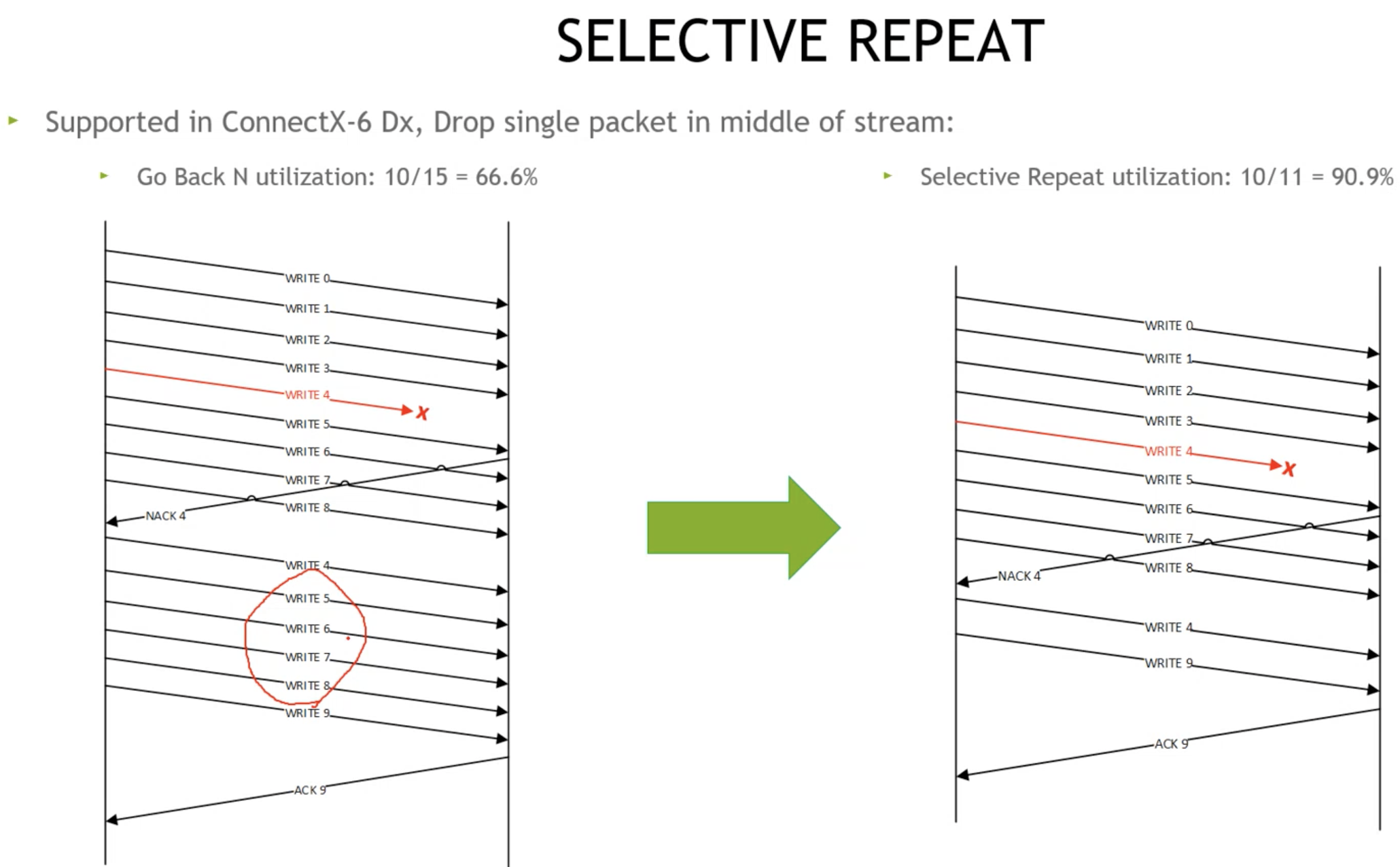
选择性重传(提高带宽利用率, QP越少效果越明显, 取决于一个QP上outstanding psn个数, 越多效果越好)
发送方只需要重传丢失的包即可, 接收方相当于支持乱序重组
1. 左边丢包, GO-BACK-N是如何处理的, 重发5,6,7,8
2. 如右图, 指哪打哪, 比如至重传4
3. 减少重传代价, 也就是减少由于go-back-n重传的部分, outstanding psn越多, 效果越好, 如: 针对单QP更佳
4. 多QP, 如100个QP, 被均分了的越细, gobackn相比selective_repeat带宽利用率相差不大
5. QP过多, 容易出现cache_miss缓存丢失, 且总速率没法在dcqcn的调整下起到很好的效果, 100~2K个QP, 比较合适, 一般业务是1W以内
6. DCQCN对QP数量有一定的要求
7. 根据固件版本和硬件版本, cx4/5可支持每个节点6K个QP(T+R)
8. 主要由NACK触发
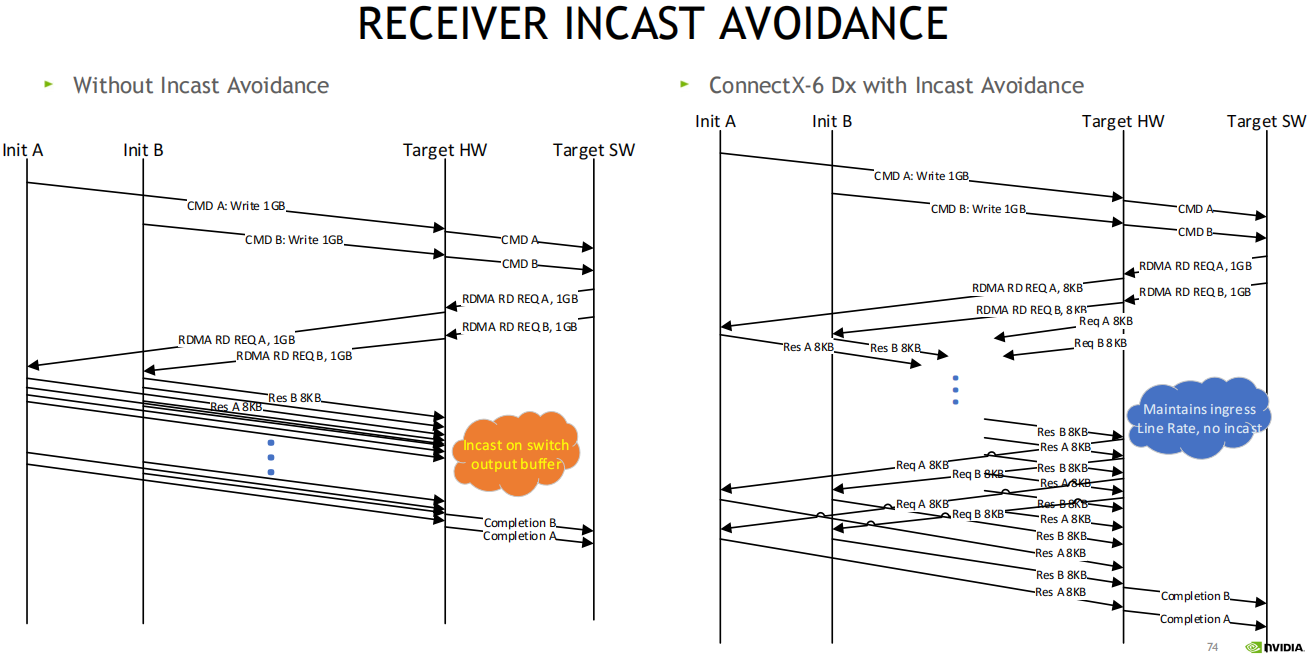
避免接收方突发广播(主要用于存储场景)可能在cx7上实现, 软件中间件上也可以实现该功能,比如UCX
将读请求切细, 避免交换机上内存并发冲突
1. 针对存储, 2个initiator, 1个tgt(硬件层面和软件层面)
2. 分别写1GB数据, 变为RDMA读(tgt读initiator)
3. A,B同时发数据给TGT, 在交换机上拥塞(INCAST on switch output buffer), 因为AB不知道对方, 这时候可通过TGT来协调控制
4. 开启该功能后, 如: TGT将1GB切分为多个8K读, 类似窗口机制, TGT按8K为窗口单位来滑动控制, 在硬件中来实现该功能
有损配置建议
1. cx5开始支持的, 打开4种有损配置
2. 最新的版本拥有更好的支持
3. 打开DCQCN
4. 其他功能根据业务自己权衡是否开启
5. 右侧是一个配置示例(查看和配置网卡)

cx6DX配置命令

有损,RDMA等应用场景(云存储)
1. 跨DC 共享盘 距离拉远 集群切分 子集群 最多100个节点 分开管理 存储间用RDMA, 虚机间RDMA用的少
2. HPC场景交换机用ACL隔离, RoCE overlay 容器适用RDMA PF封装, RDMA适用于裸金属
3. OVS, TC, offload, fw
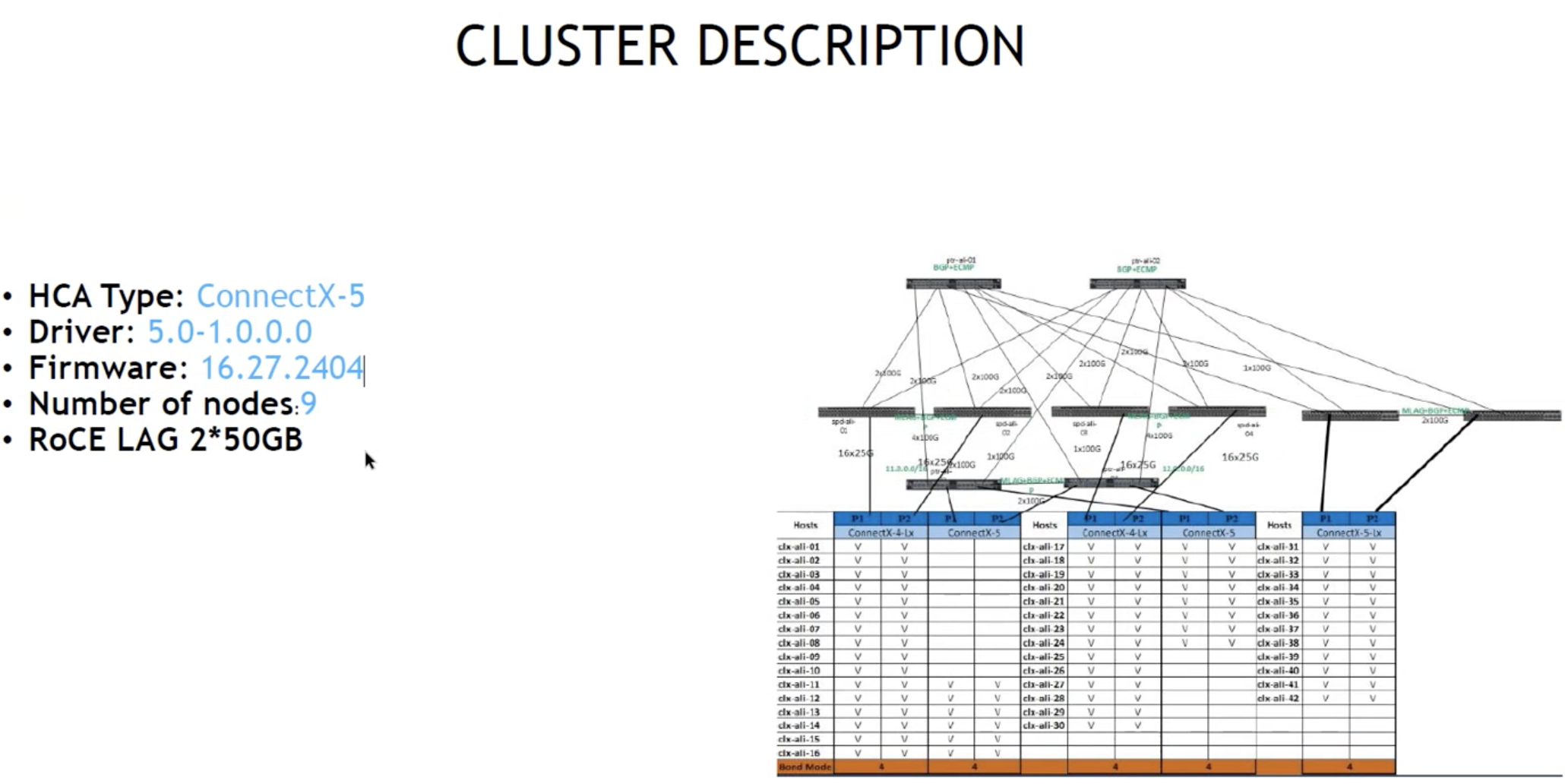
4. 性能测试, 三层交换机, 9个节点, 可跑到100GB, ib_read_bw, A2A, 多大多, M2O多打一

配置选项(提供以下4种配置方案)
1. ZTR: 取消所有交换机和节点上的PFC和ECN配置, 在网卡上启用所有的有损算法

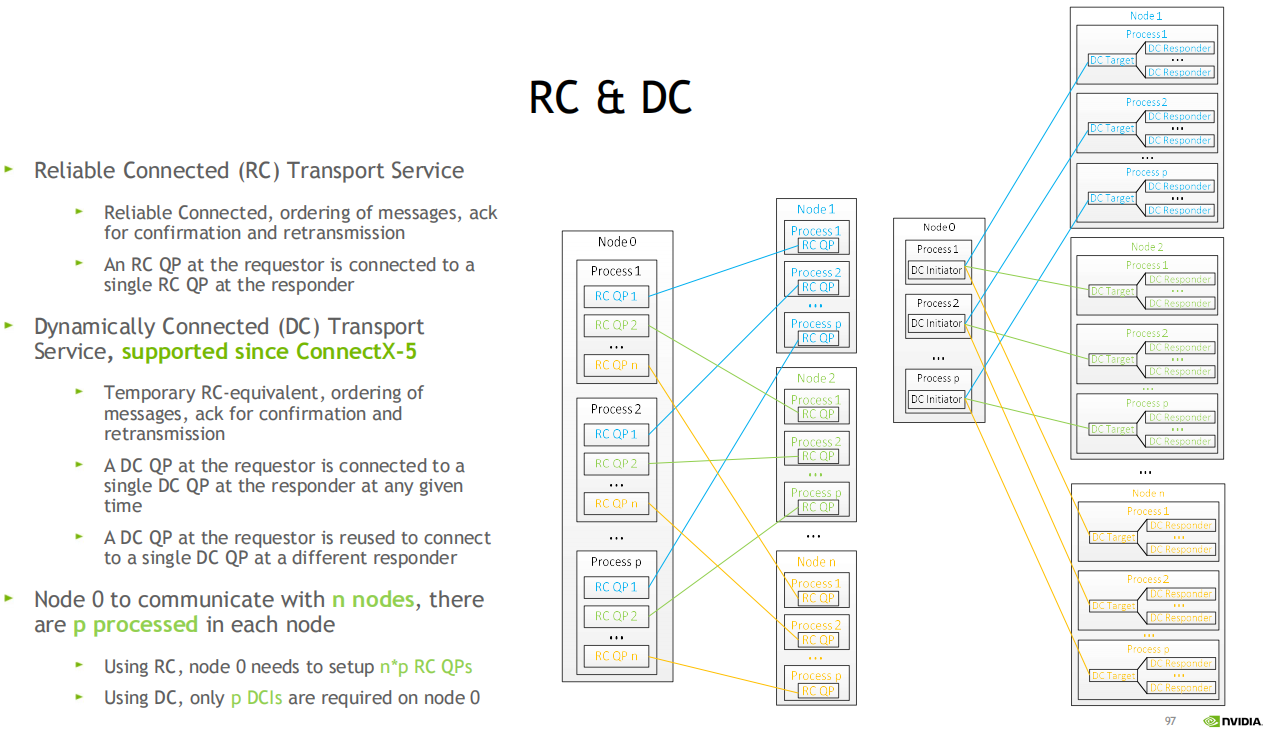
RC和DC服务类型
1. 可靠连接传输类型RC: 可靠, 消息保序, 通过ACK确认和重传
2. 动态连接DC: 从cx5开始支持, 临时的可靠连接, 保序, ACK机制
DC QP可复用
3. 比如: 服务器0连接到N个其他服务器, 每个服务器节点有P个处理器
使用RC, 服务器0将建立N*P个QPs
使用DC, 服务器0上只需要P个DCIs, 复用了多个QP
排查和调试

参考
Nvidia RoCE: https://docs.nvidia.com/networking/pages/viewpage.action?pageId=12013422
What is RDMA 什么是RDMA
https://enterprise-support.nvidia.com/s/article/What-is-RDMA
IB规范卷1: Supplement to InfiniBandTM Architecture Specification Volume 1 Release 1.2.1 - Annex 17: RoCEv2
https://cw.infinibandta.org/document/dl/7781
RDMA/RoCE Solutions 解决方案
https://enterprise-support.nvidia.com/s/article/rdma-roce-solutions
Understanding QoS Configuration for RoCE 理解QoS
https://enterprise-support.nvidia.com/s/article/understanding-qos-configuration-for-roce
mlnx_qos Manual
https://enterprise-support.nvidia.com/s/article/mlnx-qos
Understanding RoCEv2 Congestion Management 拥塞管理
https://enterprise-support.nvidia.com/s/article/understanding-rocev2-congestion-management
DCQCN Congestion Control Algorithm 流控算法
https://enterprise-support.nvidia.com/s/article/DCQCN-CC-algorithm
ECN/DCQCN parameters introduction
https://enterprise-support.nvidia.com/s/article/dcqcn-parameters
Enable/Disable Lossy RoCE Accelerations
https://enterprise-support.nvidia.com/s/article/How-to-Enable-Disable-Lossy-RoCE-Accelerations
Understanding MLX5 Ethtool Counters 理解计数器
https://enterprise-support.nvidia.com/s/article/understanding-mlx5-ethtool-counters
Understanding MLX5 Linux Counters and Status Parameters
Dump RDMA traffic with tcpdump 抓包
connectx-4-x
RoCE Debug Flow
https://enterprise-support.nvidia.com/s/article/RoCE-Debug-Flow-for-Linux
RDMA Sample Code 编程示例
[basic rdma pingpong] https://github.com/linux-rdma/rdma-core/tree/master/libibverbs/examples
[performance benchmarks] https://github.com/linux-rdma/perftest
[latency test] https://github.com/michaelbe2/rdma_samples/tree/master/rc_write_latency
[incast flow control] https://github.com/michaelbe2/rdma_fc
星云智联-深入浅出,带您了解RDMA的背景、原理和实现(下): https://zhuanlan.zhihu.com/p/596726493
RDMA(6)流控:让数据流动如沐春风,为数据传输保驾护航(RDMA系列): https://mp.weixin.qq.com/s/BjV5U7URuRQbQP_q0-j_Ng
什么是智能无损网络: https://mp.weixin.qq.com/s/bQZSepgoDRUFlTgLRqiOEQ
容损网络vs无损网络,讨论RDMA网络的两种思路: https://www.cnblogs.com/longbowchi/p/14802046.html
一文读懂RoCE: https://cloud.tencent.com/developer/article/2084218
晓兵
博客: https://logread.cn | https://blog.csdn.net/ssbandjl | https://cloud.tencent.com/developer/user/5060293/articles
DAOS技术汇总: https://cloud.tencent.com/developer/article/2344030
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号