「卷积神经网络」深入浅出


提取特征 → 压缩特征 → 比较特征
六月份初开启了我神经网络相关内容的学习,眨眼间一个月过去了,是时候来总结下自己这个月的学习心得了。
卷积层——提取特征
卷积核的特点:
- 局部性;
- 平移不变性。
卷积的作用
在数学上,卷积核的标准定义是两个函数在反转和移位后的乘积的积分:
B站上面有一位数学老师把这个概念讲的特别清楚,大家可以参考:
- Bilibili @小元老师高数线代概率:【小动画】彻底理解卷积【超形象】卷的由来,小元老师
但是我自己看完觉得即使不去明白数学上的卷积是什么意思,也不影响我们理解深度学习中的卷积(所以说就不用看上面的视频辣!)。
最近又花了几天的时间专门去扣了下“卷积”这两个字,总结就是:数学上的卷积与卷积神经网络中的卷积确实在思想上有一定的相似性,但是不能等价于一个概念。不建议大家为了理解卷积神经网络中的“卷积”而去学习数学中的卷积!!!
在上面的函数表达式中,函数g被称为过滤器(filters),函数f指的是信号/图像。
而在卷积神经网络里,卷积核其实也被称为过滤器。与上面公式中不同的是,在卷积神经网络里,它不做反转,而是直接执行逐元素的乘法和加法。
之所以在图像处理领域引入了卷积的概念,是因为上个世纪有科学家研究发现,视觉皮层的很多神经元都有一个小的局部感受野,神经元只对有限区域的感受野上的刺激物做出反应。不同的感受野可以重叠,他们共同铺满整个视野。并且发现,一些神经元仅仅对横线有反应,有一些神经元对其他方向的线条有反应,有些神经元的感受野比较大。因此,高级别的神经元的刺激是源于相邻低级别神经元的反应。
利用这个观点,经过不断的努力,逐渐发展成了现在的卷积神经网络。通过卷积核提取图像的局部特征,生成一个个神经元,再经过深层的连接,就构建出了卷积神经网络。
读到这里,你已经得到了一个反复强调的概念,那就是:卷积核是用来提取特征的。
如何卷积
卷积的工作流程如下:
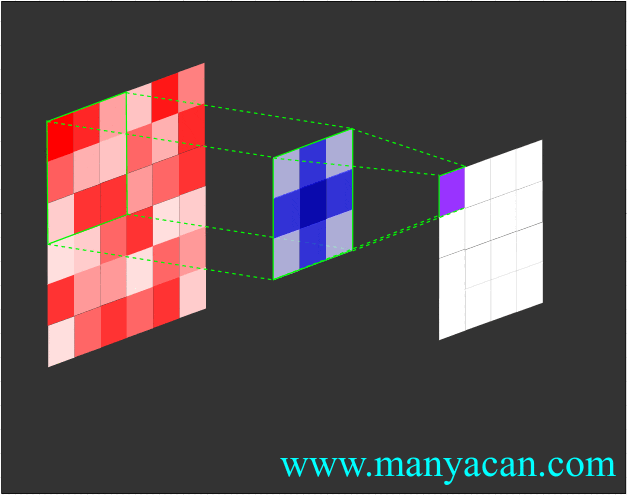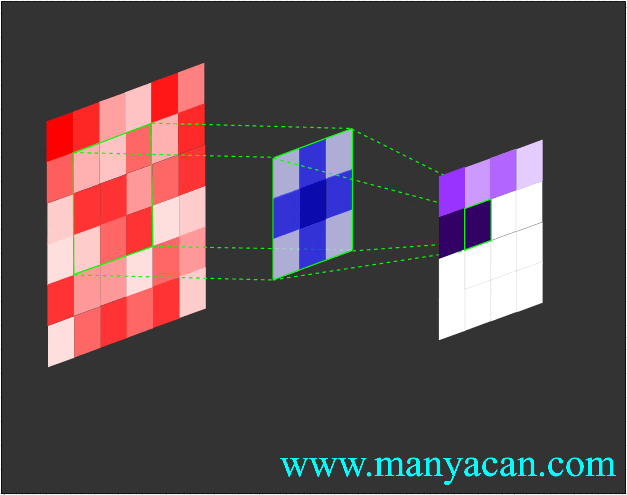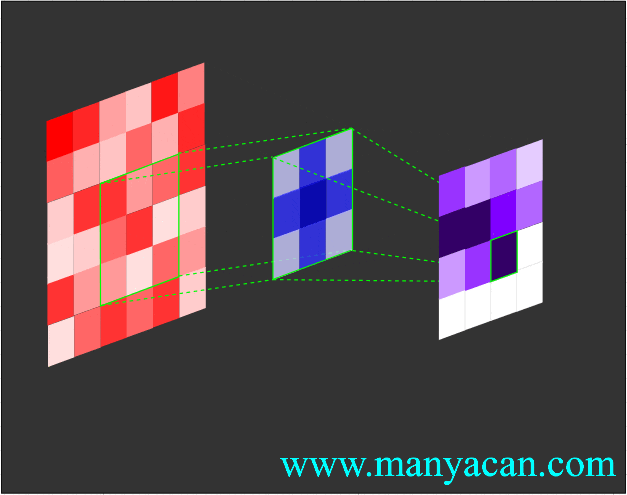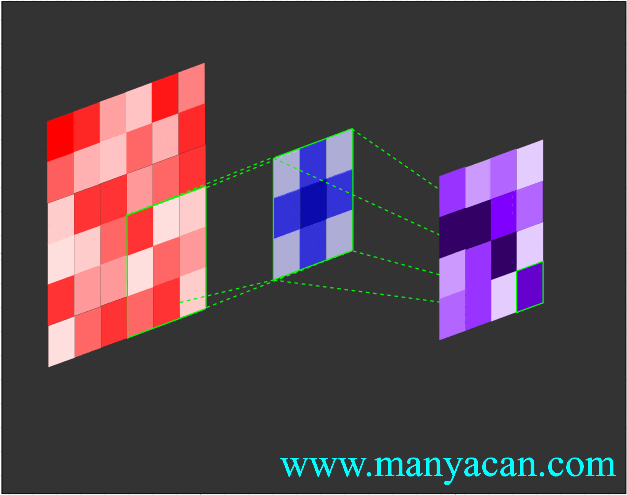
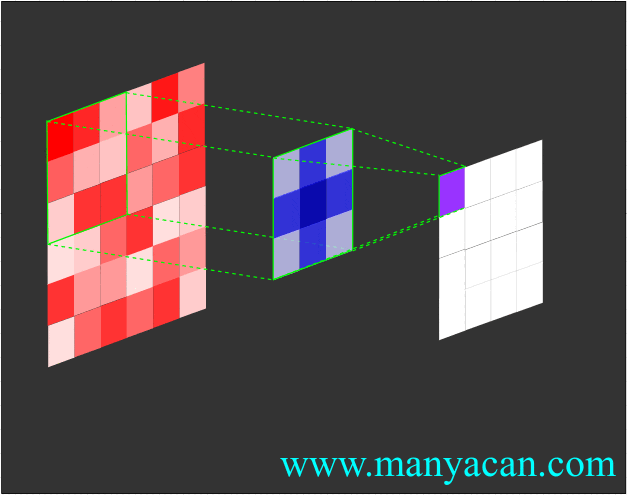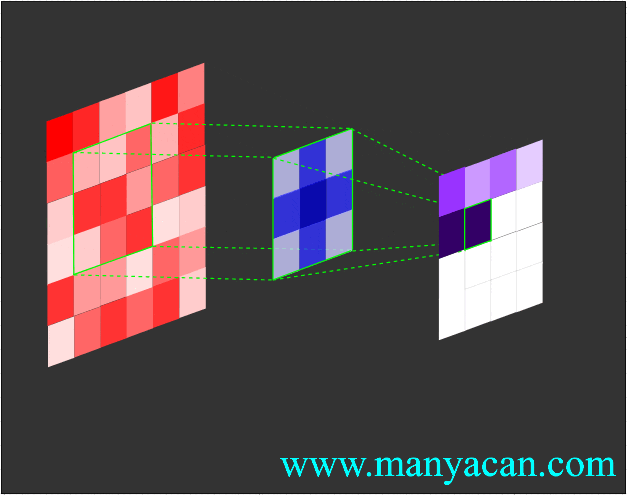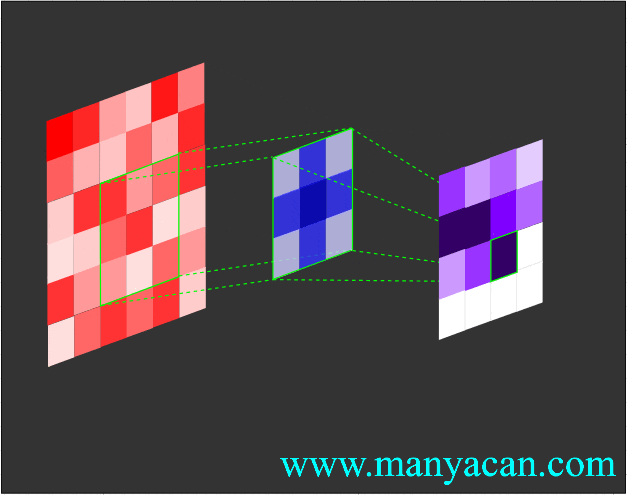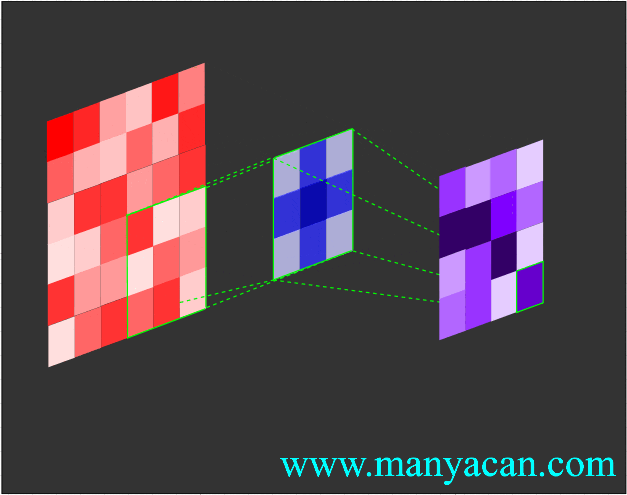
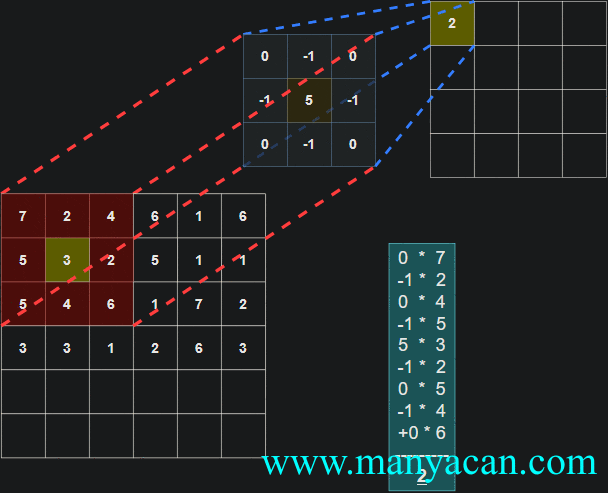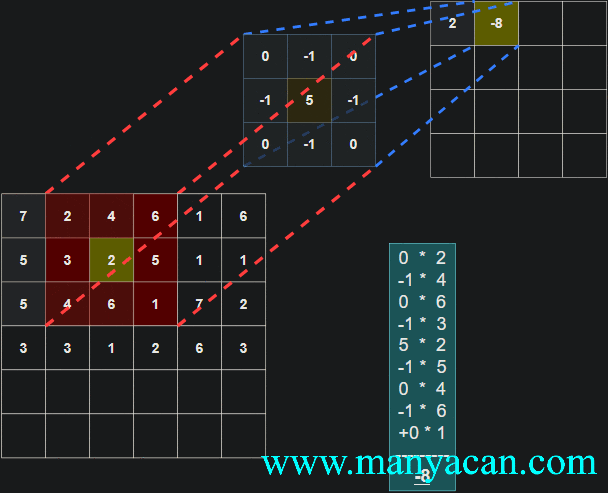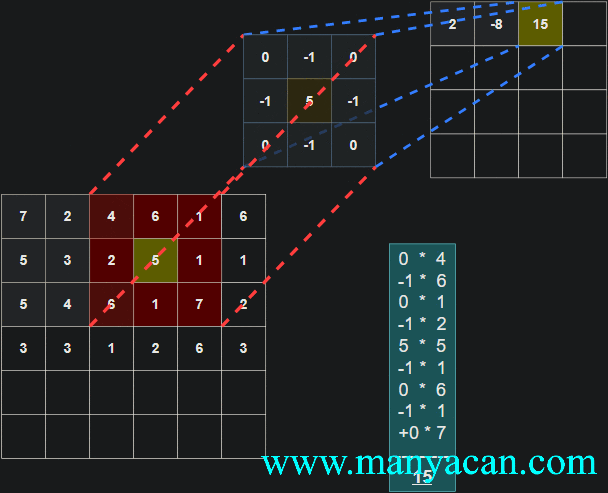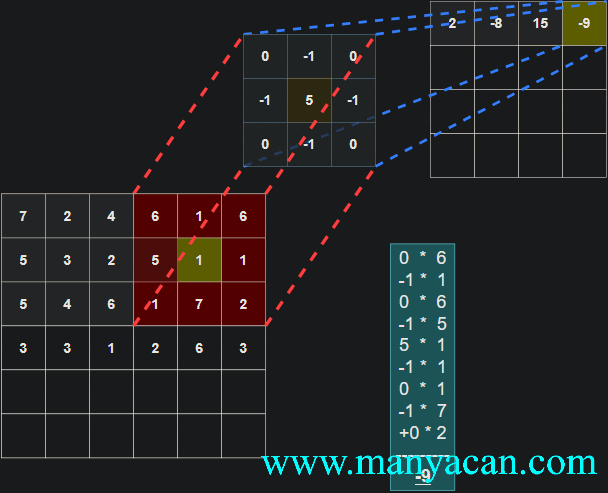
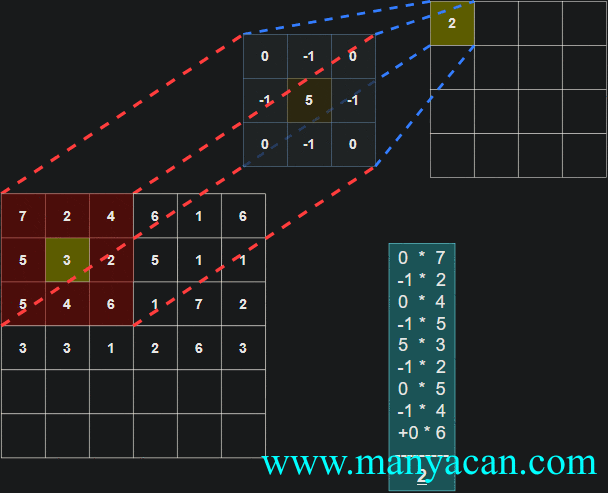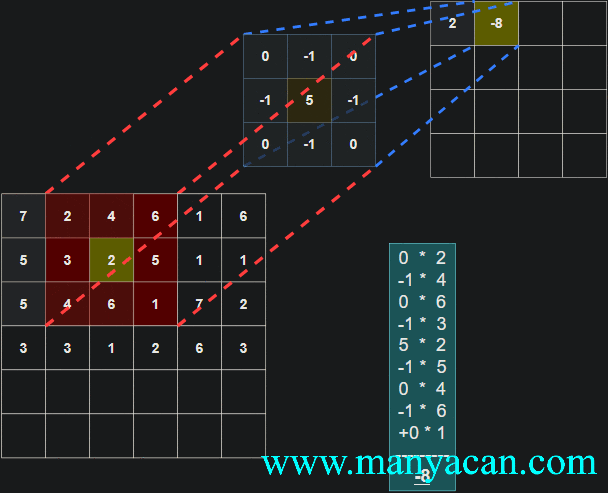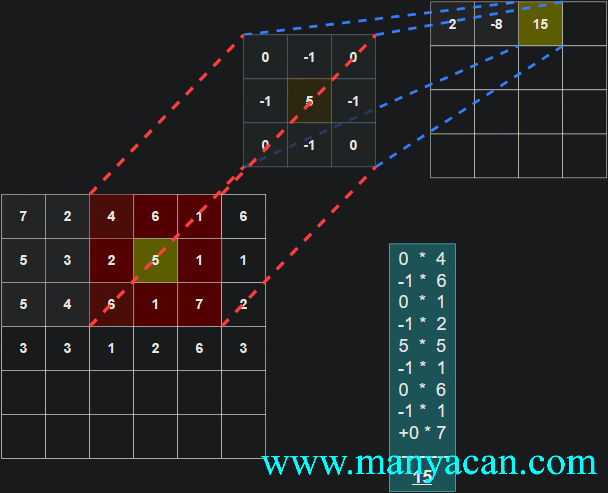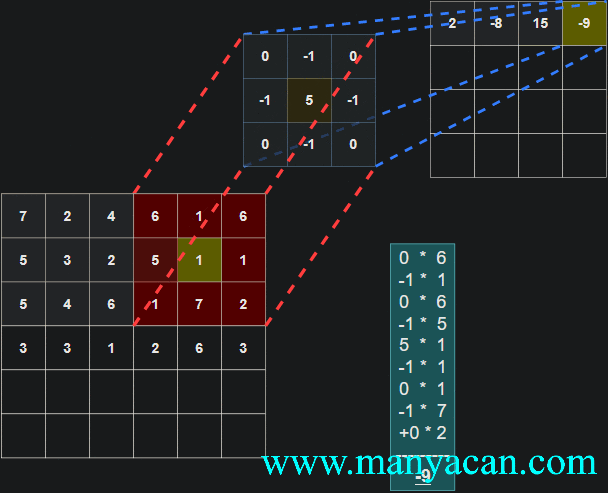
由上面的动画可以看出,卷积的过程就是使用卷积核对输入矩阵进行一步步地扫描。
假设输入矩阵为input,卷积核为kernel:
input = torch.tensor([ # 卷积层输入Tensor
[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]
])
kernel = torch.tensor([ # 卷积核
[1, 2, 1],
[0, 1, 0],
[2, 1, 0]
])卷积的结果:
import torch.nn.functional as F
F.conv2d(input, kernel)
Out[6]:
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])以卷积结果的第一行第一列的10为例:其计算过程为:
为什么卷积可以提取特征?
这个问题,一直困扰了我很久——为什么卷积的过程就可以提取特征?
上面卷积的过程中,对于一个3×3卷积核的卷积结果:
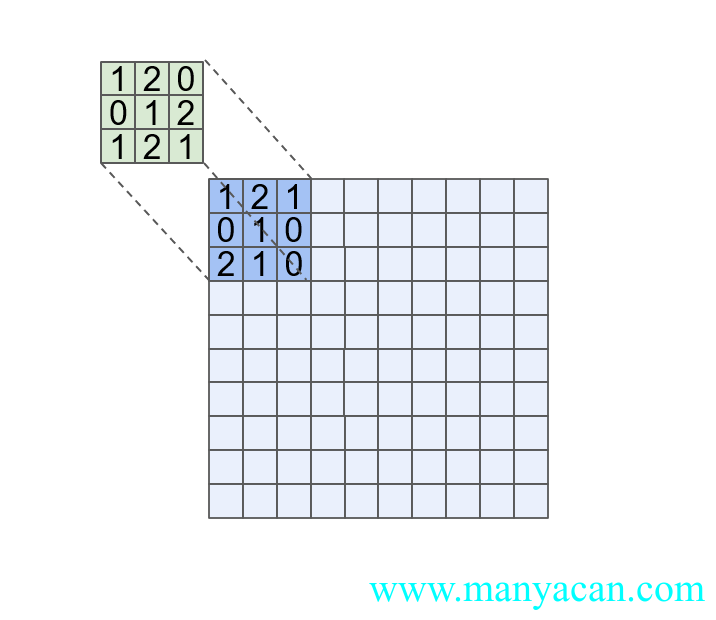
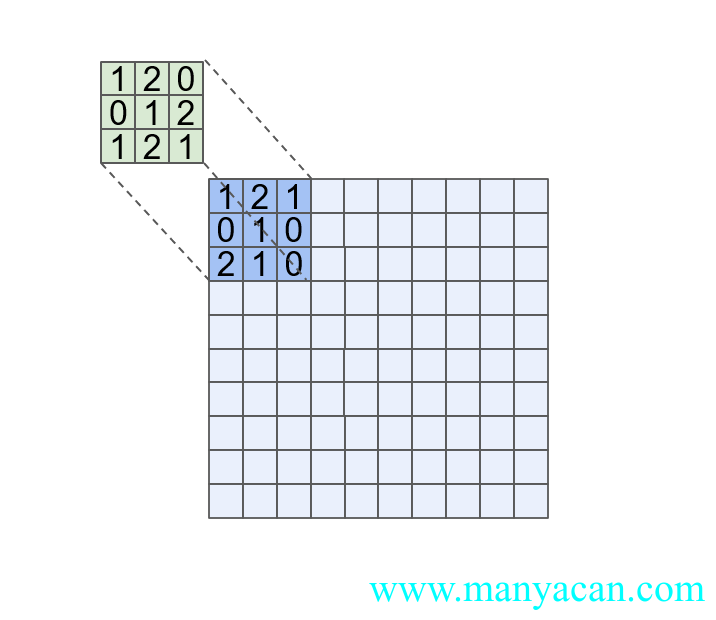
上述计算过程可以进一步抽象为:
上面这个计算过程,像不像向量的内积计算?对于两个向量a与b,其内积定义为:
当其两者非常相似时,意味着两者之间的夹角\theta很小,他们的内积a \cdot b会很大,当\theta=0时内积取得最大值,此时a与b重合;当\theta=180 \degree时内积取得最小值,此时a与b共线反向。
由此过程,上述卷积的结果S也被定义为相似度。
在《动手学深度学习 PyTorch》一书(P163)中写道,卷积运算也可以被称之为互相关运算,这个“互相关”感觉和这里的相关性有点联系哇!
举个🌰
如图所示,我们定义一个3×3的卷积核:


对一个输入矩阵:


进行卷积。
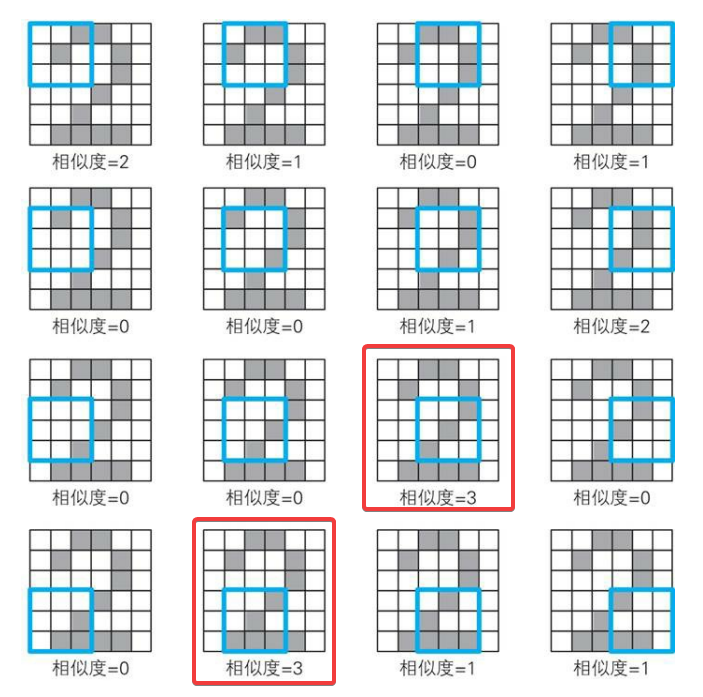
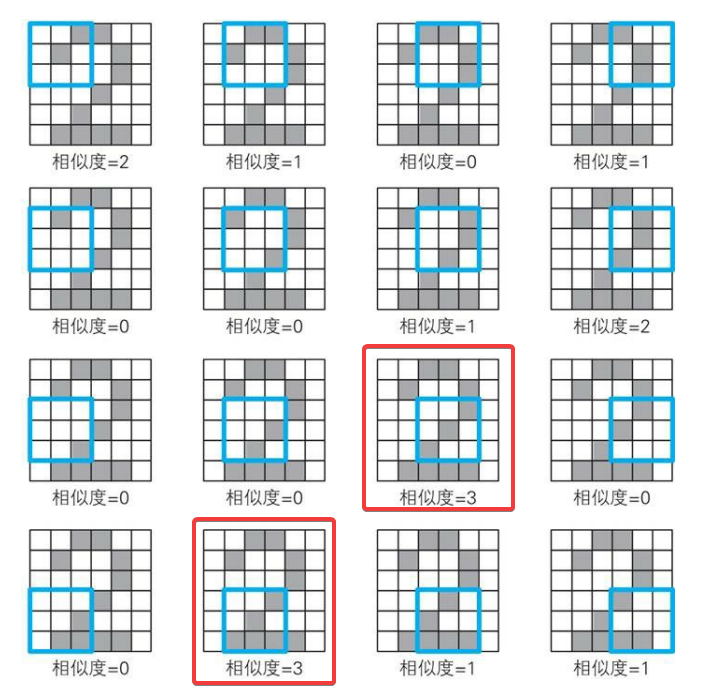
如图所示卷积过程我们共进行了16次计算,可以发现,经过卷积过程,我们切切实实地从输入矩阵中提取出来了卷积核的特征。
正是因为卷积层可以提取特征的特性,因此很多教科书中也会把卷积层称为过滤器。经过神经网络的原始数据与刚输入是的“模样”差别越来越大,而其中关于最终结果的信息却越来越丰富。深度学习网络可以看作多层信息蒸馏操作,信息通过连续的过滤器,其纯度越来越高。
至此,我们已经掌握了卷积的核心,再来大声朗读三遍:
- 卷积是为了提取特征!!!
- 卷积是为了提取特征!!!
- 卷积是为了提取特征!!!
一个卷积核提取特征的示例
卷积核参数
卷积核的参数主要有三个:
- 核大小:
kernel_size; - 步长:
stride; - 填充步数:
padding; - 空隙:
dilation。
kernel_size:定义了卷积的大小范围,在网络中代表感受野的大小,二维卷积核最常见的就是3×3的卷积核。一般情况下,卷积核越大,感受野越大,看到的图片信息越多,所获得的全局特征越好。但大的卷积核会导致计算量的暴增,计算性能也会降低。
上面的Python代码块中所定义的
kernel变量是一个3×3的卷积核,因此其卷积核大小为3。
stride:卷积核的步长代表提取的精度,步长定义了当卷积核在图像上面进行卷积操作的时候,每次卷积跨越的长度。对于size为2的卷积核,如果step为1,那么相邻步感受野之间就会有重复区域;如果step为2,那么相邻感受野不会重复,也不会有覆盖不到的地方;如果step为3,那么相邻步感受野之间会有一道大小为1颗像素的缝隙,从某种程度来说,这样就遗漏了原图的信息。
kernel_size=2, stride=1 | kernel_size=2, stride=2 |
|---|---|
对于上述5×5输入矩阵input,卷积核kernel的步长stride设置为2,完成一次卷积后的结果是2×2:
F.conv2d(input, kernel, stride=2)
Out[7]:
tensor([[[[10, 12],
[13, 3]]]])padding:卷积核与图像尺寸不匹配,会造成了卷积后的图片和卷积前的图片尺寸不一致,为了避免这种情况,需要先对原始图片做边界填充处理。
kernel_size=5, stride=1, padding=1 | kernel_size=7, stride=1, padding=2 |
|---|---|
padding=1参数为输入矩阵的上下左右周围添加了一圈为0的值,输入矩阵变成了7×7,如下面的input_pad_1所示:
F.conv2d(input, kernel, padding=1)
Out[8]:
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
input_pad_1 = torch.tensor([
[0 for i in range(7)],
[0, 1, 2, 0, 3, 1, 0],
[0, 0, 1, 2, 3, 1, 0],
[0, 1, 2, 1, 0, 0, 0],
[0, 5, 2, 3, 1, 1, 0],
[0, 2, 1, 0, 1, 1, 0],
[0 for i in range(7)]
])
input_pad_1 = torch.reshape(input_pad_1, (-1, 1, 7, 7))
F.conv2d(input_pad_1, kernel) # 与添加padding=1参数后得到了相同的结果
Out[10]:
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])padding参数的添加,有效防止了图像边缘信息的缺失。为了使输入2维Tensor与输出具有相同的宽高,我们可以设置padding=\frac{kernel\_size-1}{2}。卷积神经网络中,卷积核的宽、高通常情况下为奇数且相等,这样是为了方便在四周添加相同数量的行(也就是padding)。
用图的方式表达就非常明显了,当设置了dilation参数后,卷积过程会被“扩散”开来。
注意,
dilation参数的默认值为1,上图的动画过程,设置了dilation=2,太奇葩了!!!不能理解!!!
对于上述5×5输入矩阵input,卷积核kernel的dilation设置为2,完成一次卷积后的结果是1×1:
F.conv2d(input, kernel, dilation=2)
tensor([[[[7]]]])具体计算过程为:
多通道卷积
上述讲解的卷积过程只有一个通道,被称为单通道卷积。听名字就可以看出来,与之对应的还有多通道卷积。对于常规的JPG格式图片,其图片颜色由R(红)G(绿)B(蓝)三通道构成。


那么对于三个通道的输入层,我们也可以使用三通道的卷积核来进行卷积运算:
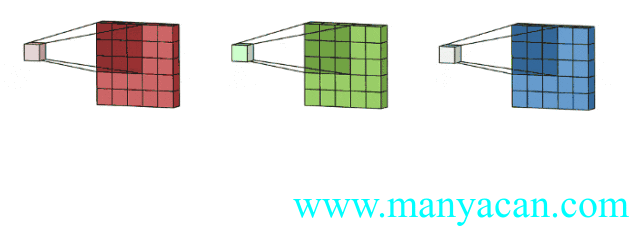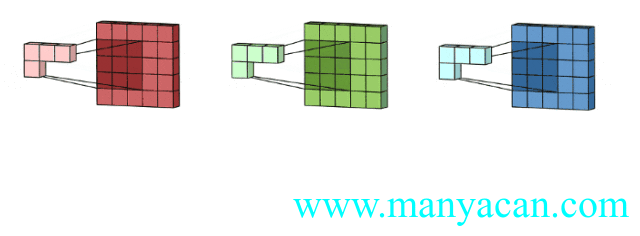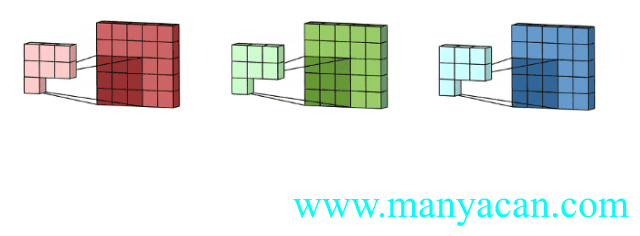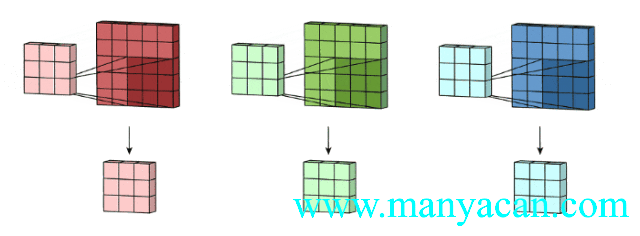
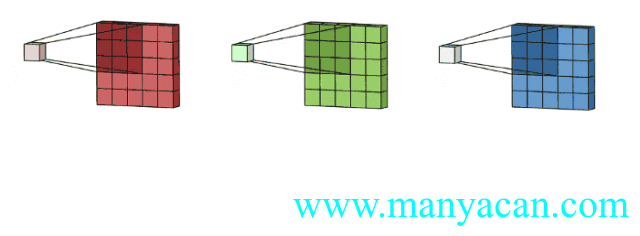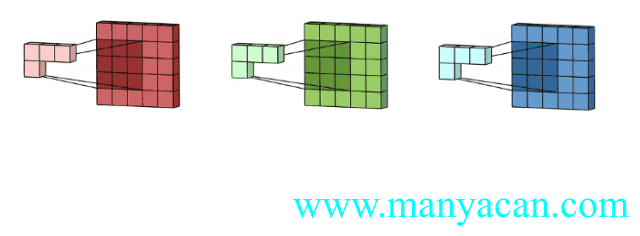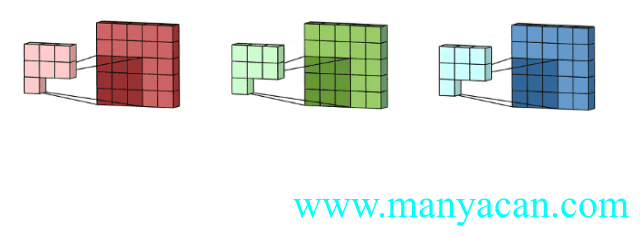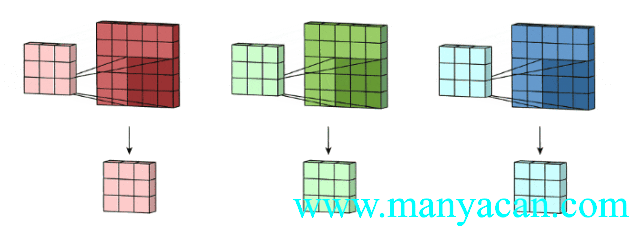
上面的动图里面,输入层为3×5×5(3个通道,每个通道为3×3);卷积层为3×3×3。三个通道完成分别完成卷积后,在按照对应位置相加,得到最后的结果。
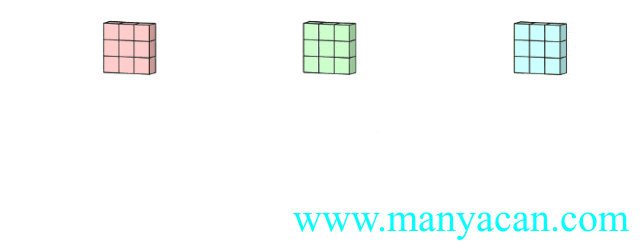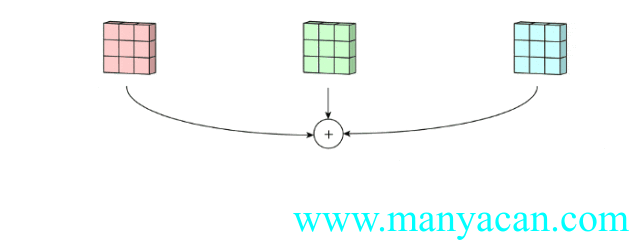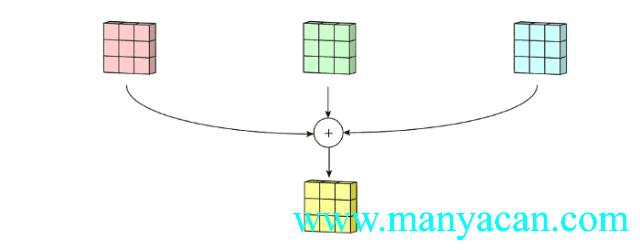
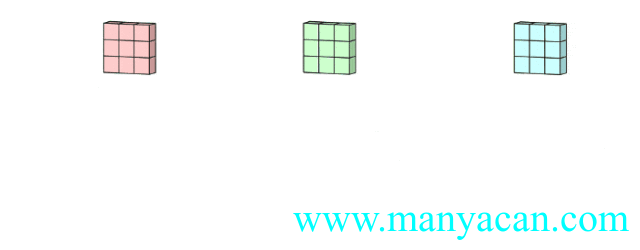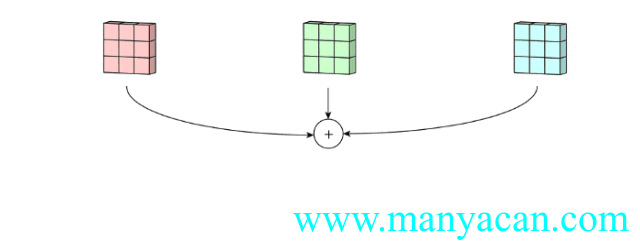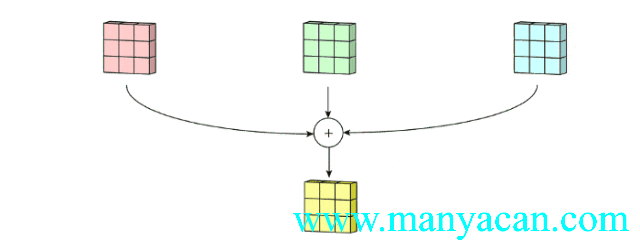
卷积核尺寸、个数的确定
首先卷积核表示尺寸、个数的参数一共有4个[out\_channels, in\_channels, width, height]:
out_channels:这个参数由输出的通道数决定,也就是通过该层,你想提取几个特征。in_channels:这个参数由输入矩阵的通道数决定,当输入为三通道RGB图像时,那么对应的in_channels=3。width、height:这两个代表的就是单个卷积核的尺寸大小,也就是上面叙述过程中反复提到的kernel_size,一般情况下width=height=kernel_size。
下面我们来通过代码具体看下:
import torch
from torch.nn import Conv2d
in_channels = 3 #输入通道数量
out_channels =10 #输出通道数量
width = 100 #每个输入通道上尺寸的宽
height = 100 #每个输入通道上尺寸的高
kernel_size = 3 #每个输入通道上的卷积尺寸3×3
batch_size = 1 #批数量
input = torch.randn(batch_size, in_channels, width, height)
conv_layer = torch.nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size)
out_put = conv_layer(input)
print(input.shape)
print(out_put.shape)
print(conv_layer.weight.shape)
torch.Size([1, 3, 100, 100])
torch.Size([1, 10, 98, 98])
torch.Size([10, 3, 3, 3])input.shape=[1, 3, 100, 100]:说明输入了1张图片,该张图片3个通道(RGB),图片尺寸为100×100;conv_layer.weight.shape=[10, 3, 3, 3]:说明卷积核共有10组,每组有3个通道(对应图片的RGB3个通道,每个通道都有一个卷积核),每个卷积核的尺寸大小为3×3;out_put.shape=[1, 10, 98, 98]:说明输出了1个对象(对应输入的1张图片),该张图片有10个通道(对应10组卷积核,也就是说提取了10组特征),每个图片的大小为98×98。
out_put输出的图片尺寸大小计算方式为(以高为例,宽的计算方法相同):
上面的计算方式有点局限,仅适用于
padding=1、stride=1、dilation=1的情况下。
总结一句话就是:
- 输入通道个数 = 卷积核通道个数;
- 卷积核个数 = 输出通道个数。
基于上面的分析与讲解,我们可以对卷积核参数的作用进行一个总结:
- 核大小
kernel_size:卷积核的元素决定了其可以提取的特征,卷积核大小决定了扫描的范围; - 步长
stride:设置该参数可以解决原始输入图像分辨率冗余的问题,大幅减小图像的宽高; - 填充步数
padding:防止原始图像丢失边缘信息; - 空隙:
dilation。
池化层——压缩特征
“池化”这俩字儿有点抽象,我更喜欢《动手学深度学习 PyTorch版》中的名称——汇聚层,“汇聚”两个字就把池化层的作用描述的非常形象——将局部特征进行“汇聚”,从而达到压缩信息的目的。
其中,池化分为两种:最大池化和平均池化。以最大池化为例,其工作原理如下图所示:
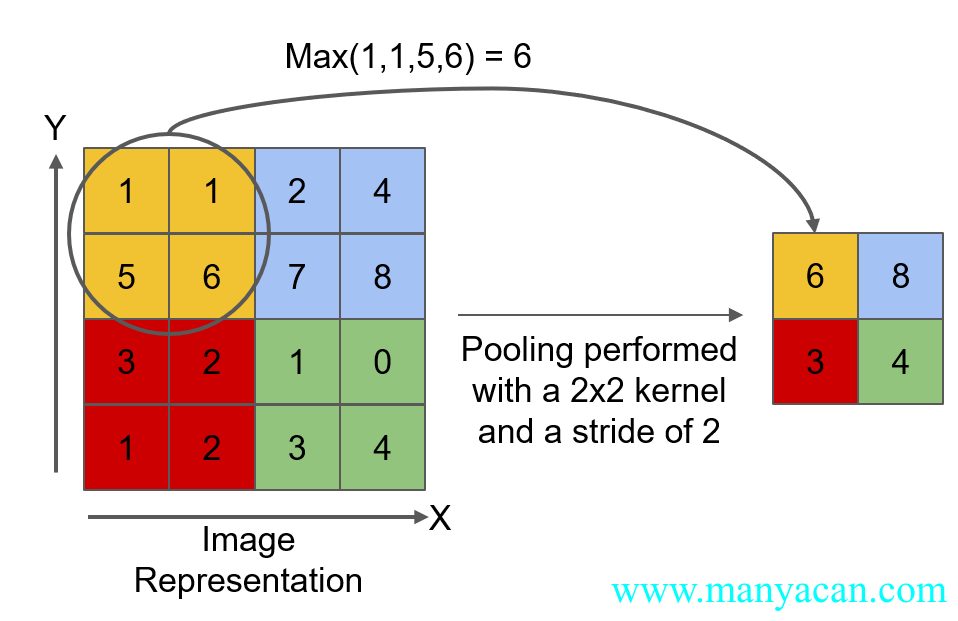
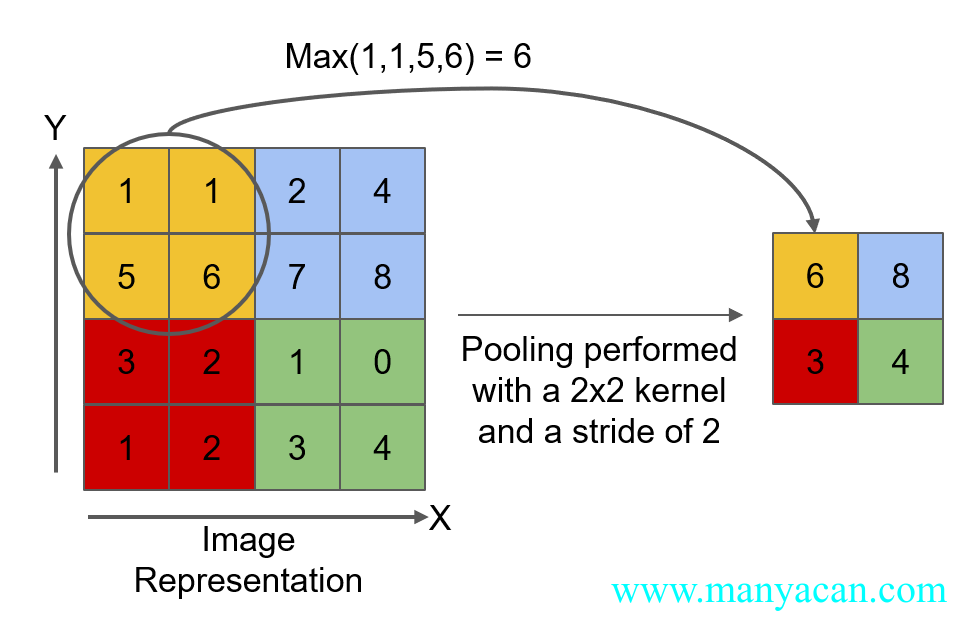
最大池化原理图
正如上所说,池化层的目的是压缩特征信息。对于图片这种数据,对其进行特征压缩是十分有必要的,而对于某些情况下,例如阿尔法Go的卷积神经网络设计中就没有池化层,因为对于围棋来说,每一个棋子(相当于一个像素)的位置信息都是至关重要的。
代码实现:
import torch
from torch.nn.functional import max_pool2d
a = torch.tensor([
[1, 1, 2, 4],
[5, 6, 7, 8],
[3, 2, 1, 0],
[1, 2, 3, 4]
], dtype=torch.float32)
a = a.reshape((1, 1, 4, 4))
a
Out[4]:
tensor([[[[1., 1., 2., 4.],
[5., 6., 7., 8.],
[3., 2., 1., 0.],
[1., 2., 3., 4.]]]])
max_pool2d(a, kernel_size=2)
Out[5]:
tensor([[[[6., 8.],
[3., 4.]]]])注意:池化层的步长stride默认等于其核大小,并不是1!!!因此对于任意一个n×n的图像,在经过kernel_size=m的池化层后,其大小应该变为\frac{n}{m}×\frac{n}{m}。
除了最大值池化,还有一种池化方法为平均值池化:
from torch.nn.functional import avg_pool2d
avg_pool2d(a, kernel_size=2)
Out[7]:
tensor([[[[3.2500, 5.2500],
[2.0000, 2.0000]]]])PyTorch官方文档:
池化层的作用与存在的意义就是将卷积层提取出来的特征进行压缩,从每一个感受野中提取出来最大值或者平均值,用来代表感受野内整体的分布情况,从而达到压缩特征的目的。
激活层
避免层数塌陷
小Tips
为什么DL模型中复杂度越高的模型往往是层数越多,而不是每一层的权重参数越多呢?
换句话形象的话来问这个问题就是:为什么DL模型都是往“长”处发展,而不是往“胖”处发展?这是因为权重参数或者是卷积核个数的增加代表着是分解的特征多,而往“长”处发展意味着我们对一些特征往“精”处学。往“胖”处发展有点像我们学了很多们技术,但是都是浅尝辄止;而往“长”处发展意味着我们这对某几门技术往“死”里学,虽然我们学的相对少,但是只要学“精”了,一样是好的。
常见卷积神经网络
LeNet
LeNet是最早发布的卷积神经网络之一,因其在计算机视觉任务中的高效性能而受到广泛关注。这个模型是由AT&T贝尔实验室的研究员Yann LeCun在1989年提出的(并以其命名),目的是识别邮件图像中的手写数字。
当时,Yann LeCun发表了第一篇通过反向传播成功训练卷积神经网络的研究,这项工作代表了十多年来神经网络研究开发的成果。当时,LeNet取得了与支持向量机(support vector machines)性能相媲美的成果,成为监督学习的主流方法。
LeNet被广泛用于自动取款机(ATM)机中,帮助识别处理支票的数字。
时至今日,一些自动取款机仍在运行Yann LeCun和他的同事Leon Bottou在上世纪90年代写的代码呢!
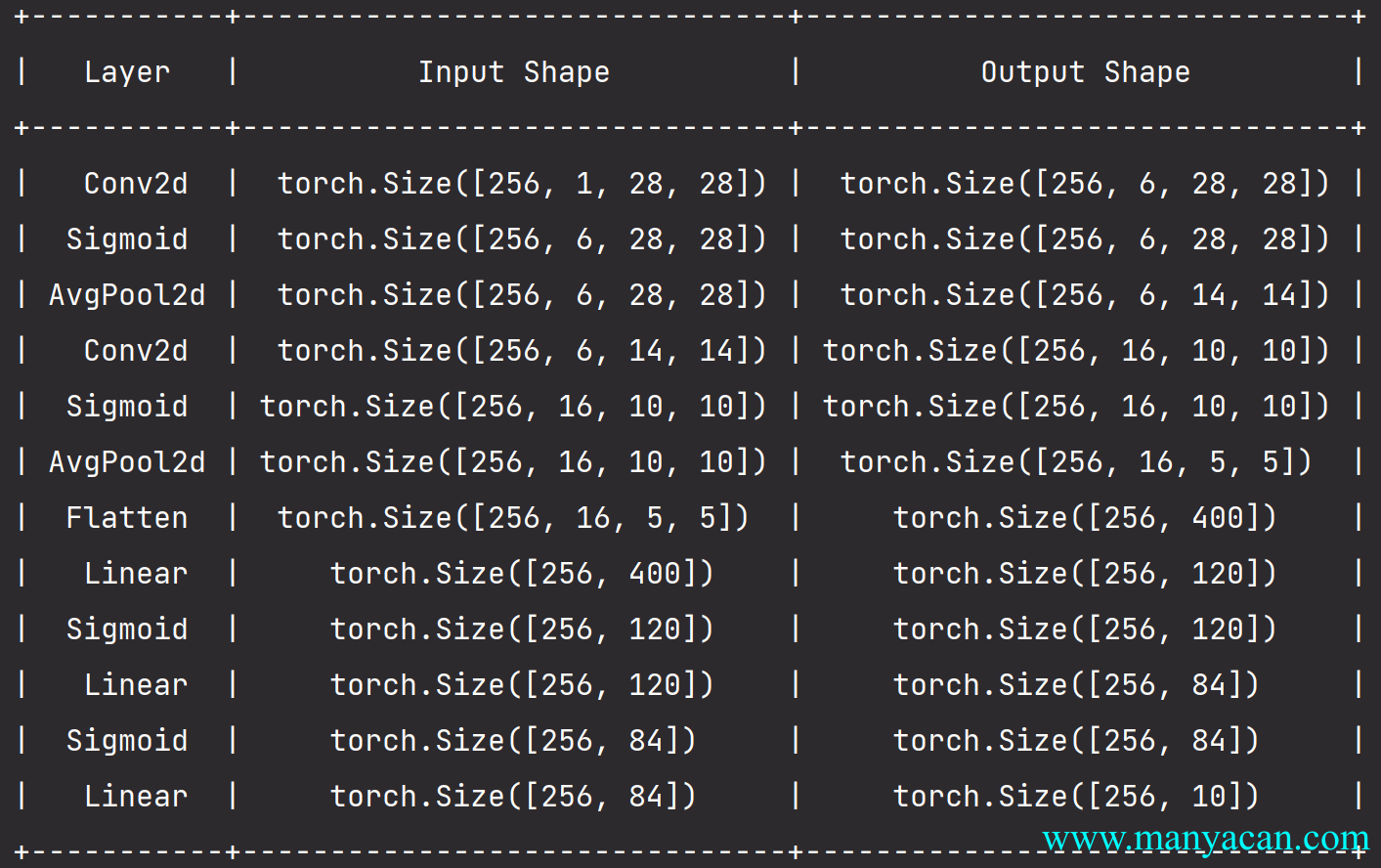
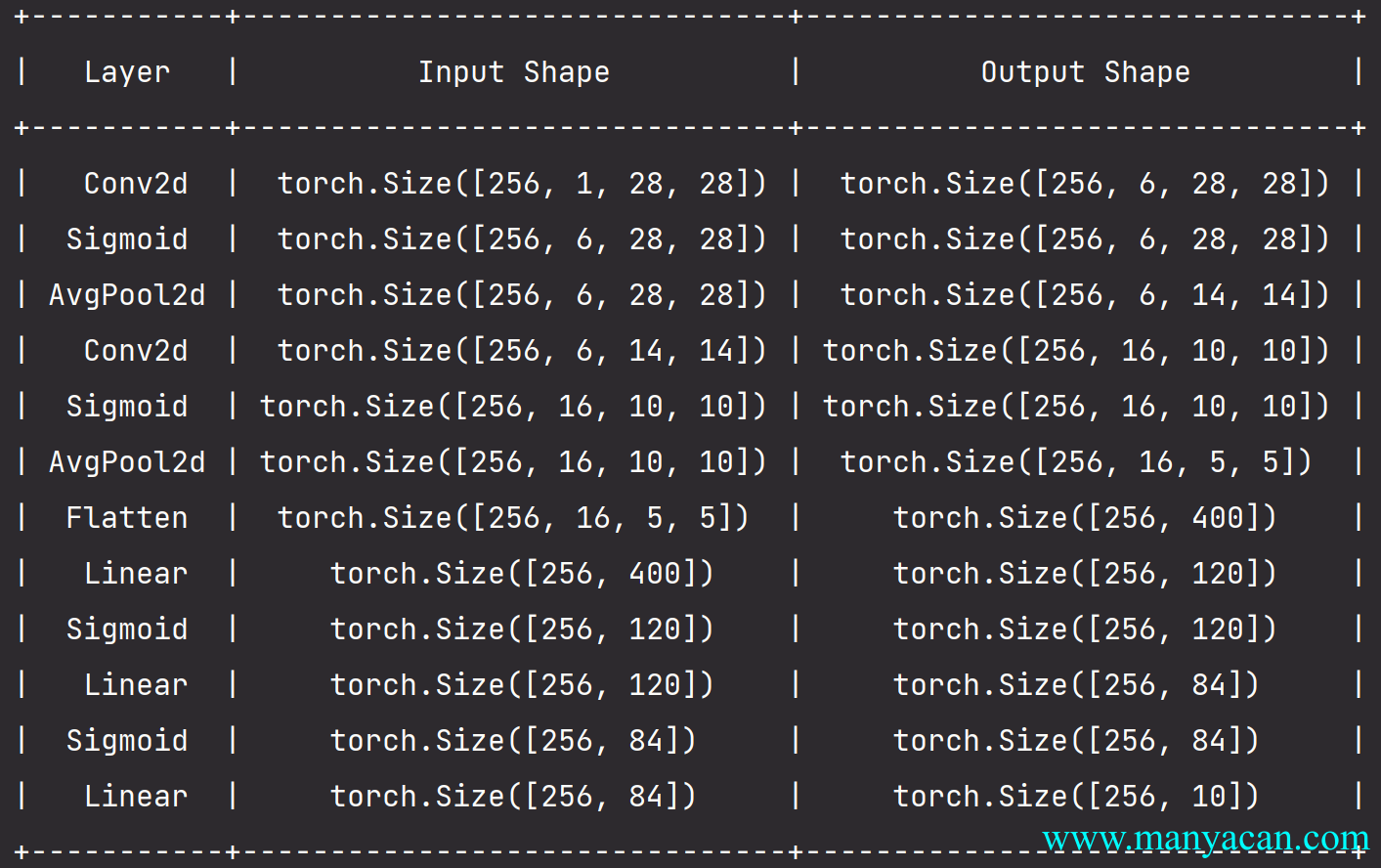
网络结构
net = Sequential(
Conv2d(1, 6, kernel_size=5, padding=2), Sigmoid(), # Input: 256×1×28×28; Output: 256×6×28×28.
AvgPool2d(kernel_size=2, stride=2), # Input: 256×6×28×28; Output: 256×6×14×14.
Conv2d(6, 16, kernel_size=5), Sigmoid(), # Input: 256×6×14×14; Output: 256×16×10×10.
AvgPool2d(kernel_size=2, stride=2), # Input: 256×16×10×10; Output: 256×16×5×5.
Flatten(), # Input: 256×16×5×5; Output: 256×400.
Linear(16 * 5 * 5, 120), Sigmoid(), # Input: 256×400; Output: 256×120.
Linear(120, 84), Sigmoid(), # Input: 256×120; Output: 256×84.
Linear(84, 10) # Input: 256×84; Output: 256×10.
)
AlexNet
在LeNet提出后,卷积神经网络在计算机视觉和机器学习领域中很有名气。但卷积神经网络并没有主导这些领域。这是因为虽然LeNet在小数据集上取得了很好的效果,但是在更大、更真实的数据集上训练卷积神经网络的性能和可行性还有待研究。事实上,在上世纪90年代初到2012年之间的大部分时间里,神经网络往往被其他机器学习方法超越,如支持向量机(support vector machines)。
Alex Krizhevsky、Ilya Sutskever和Geoff Hinton提出了一种新的卷积神经网络变体AlexNet。在2012年ImageNet挑战赛中取得了轰动一时的成绩。AlexNet以Alex Krizhevsky的名字命名,他是论文Krizhevsky.Sutskever.Hinton.2012的第一作者。
AlexNet和LeNet的设计理念非常相似,但也存在显著差异。
- AlexNet比相对较小的LeNet5要深得多。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
- AlexNet使用ReLU而不是sigmoid作为其激活函数。
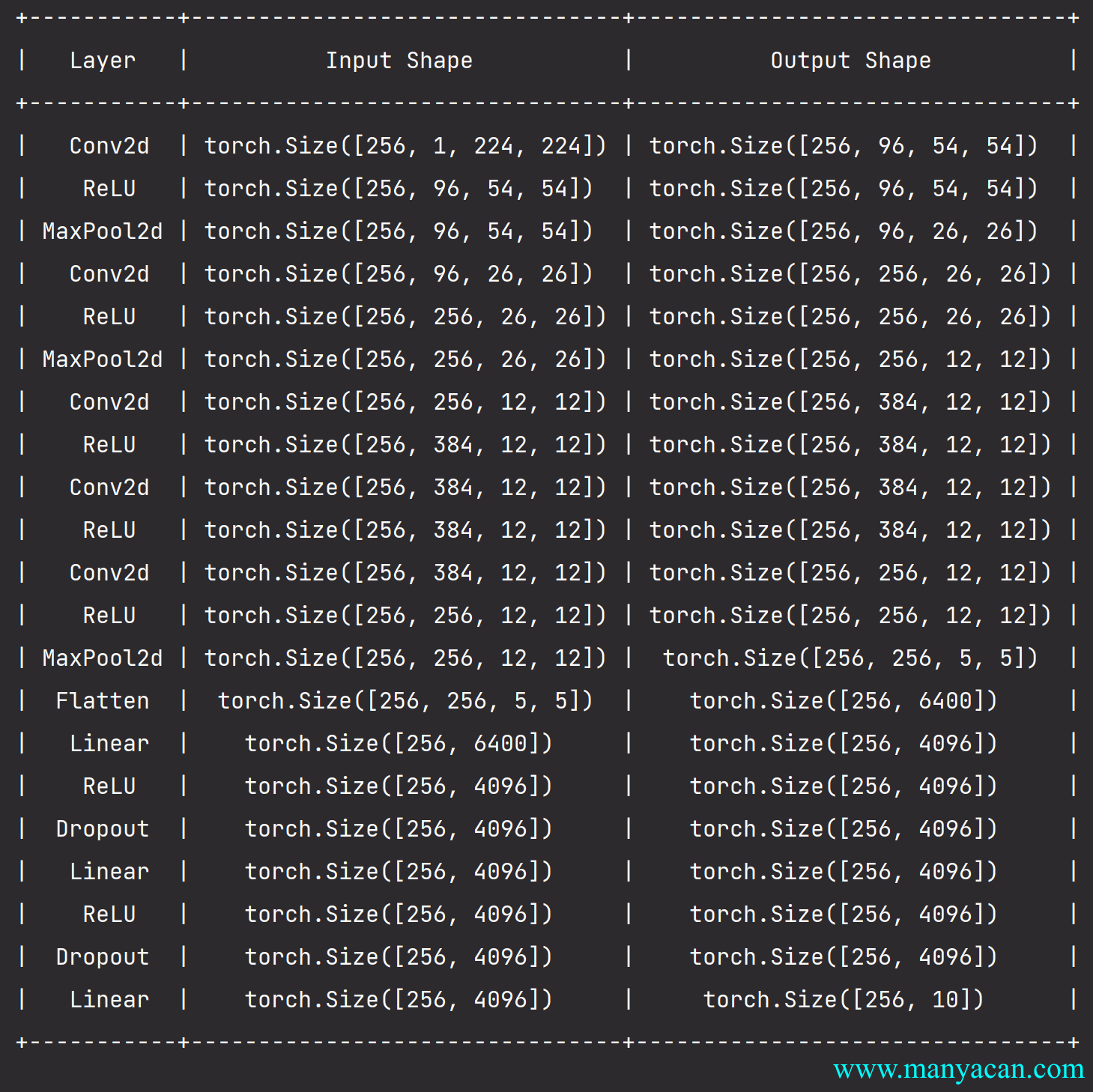
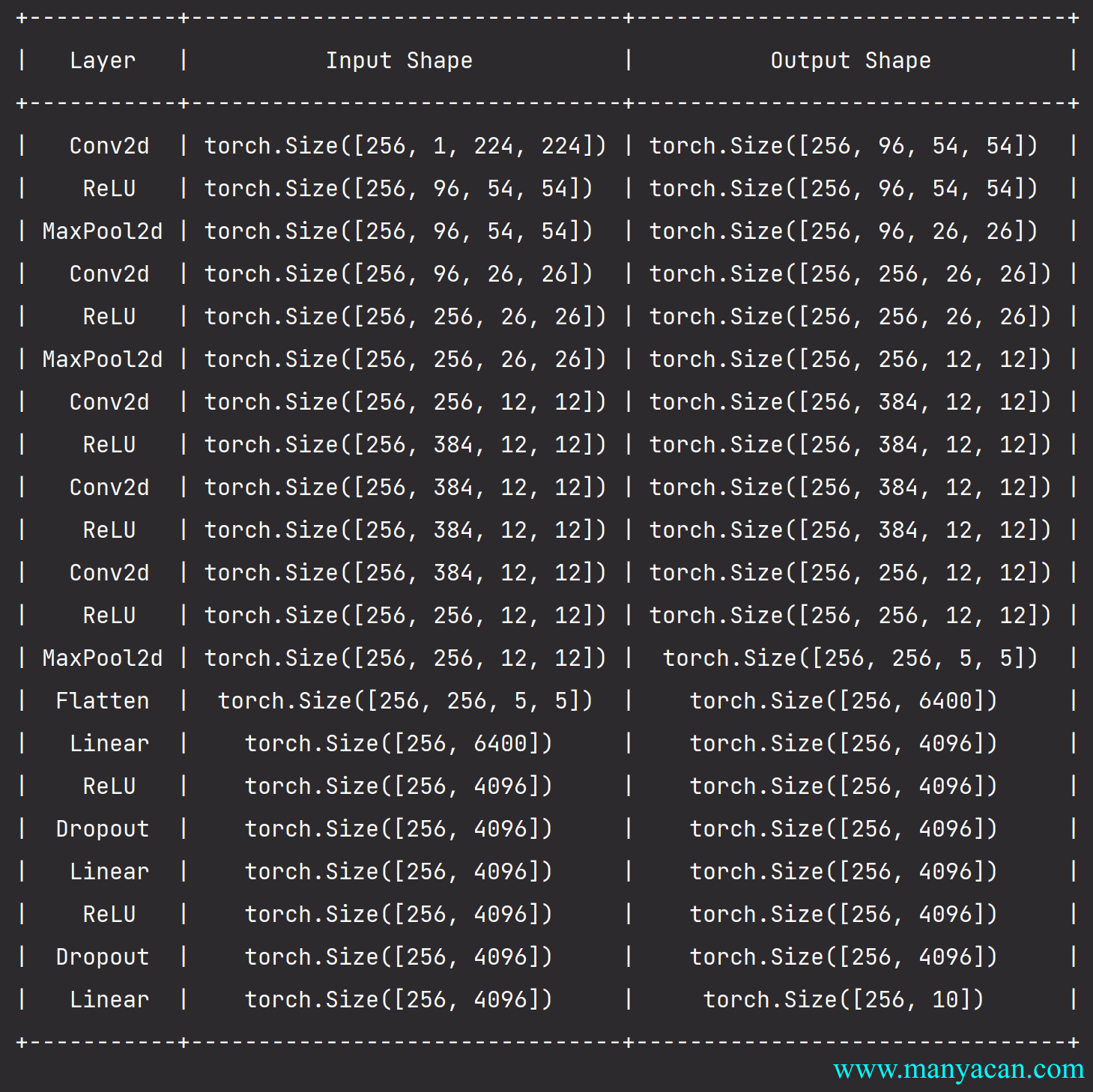
下面的内容将深入研究AlexNet的细节。
模型设计
在AlexNet的第一层,卷积窗口的形状是11\times11。由于ImageNet中大多数图像的宽和高比MNIST图像的多10倍以上,因此,需要一个更大的卷积窗口来捕获目标。第二层中的卷积窗口形状被缩减为5\times5,然后是3\times3。此外,在第一层、第二层和第五层卷积层之后,加入窗口形状为3\times3、步幅为2的最大汇聚层。而且,AlexNet的卷积通道数目是LeNet的10倍。
在最后一个卷积层后有两个全连接层,分别有4096个输出。这两个巨大的全连接层拥有将近1GB的模型参数。由于早期GPU显存有限,原版的AlexNet采用了双数据流设计,使得每个GPU只负责存储和计算模型的一半参数。幸运的是,现在GPU显存相对充裕,所以现在很少需要跨GPU分解模型(因此,本书的AlexNet模型在这方面与原始论文稍有不同)。
激活函数
此外,AlexNet将sigmoid激活函数改为更简单的ReLU激活函数。一方面,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。另一方面,当使用不同的参数初始化方法时,ReLU激活函数使训练模型更加容易。当sigmoid激活函数的输出非常接近于0或1时,这些区域的梯度几乎为0,因此反向传播无法继续更新一些模型参数。相反,ReLU激活函数在正区间的梯度总是1。因此,如果模型参数没有正确初始化,sigmoid函数可能在正区间内得到几乎为0的梯度,从而使模型无法得到有效的训练。
容量控制和预处理
AlexNet通过暂退法控制全连接层的模型复杂度,而LeNet只使用了权重衰减。为了进一步扩充数据,AlexNet在训练时增加了大量的图像增强数据,如翻转、裁切和变色。这使得模型更健壮,更大的样本量有效地减少了过拟合。
网络结构
net = nn.Sequential(
# 这里使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(), # Input: 128×1×224×224; Output: 128×96×54×54.
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10)
)
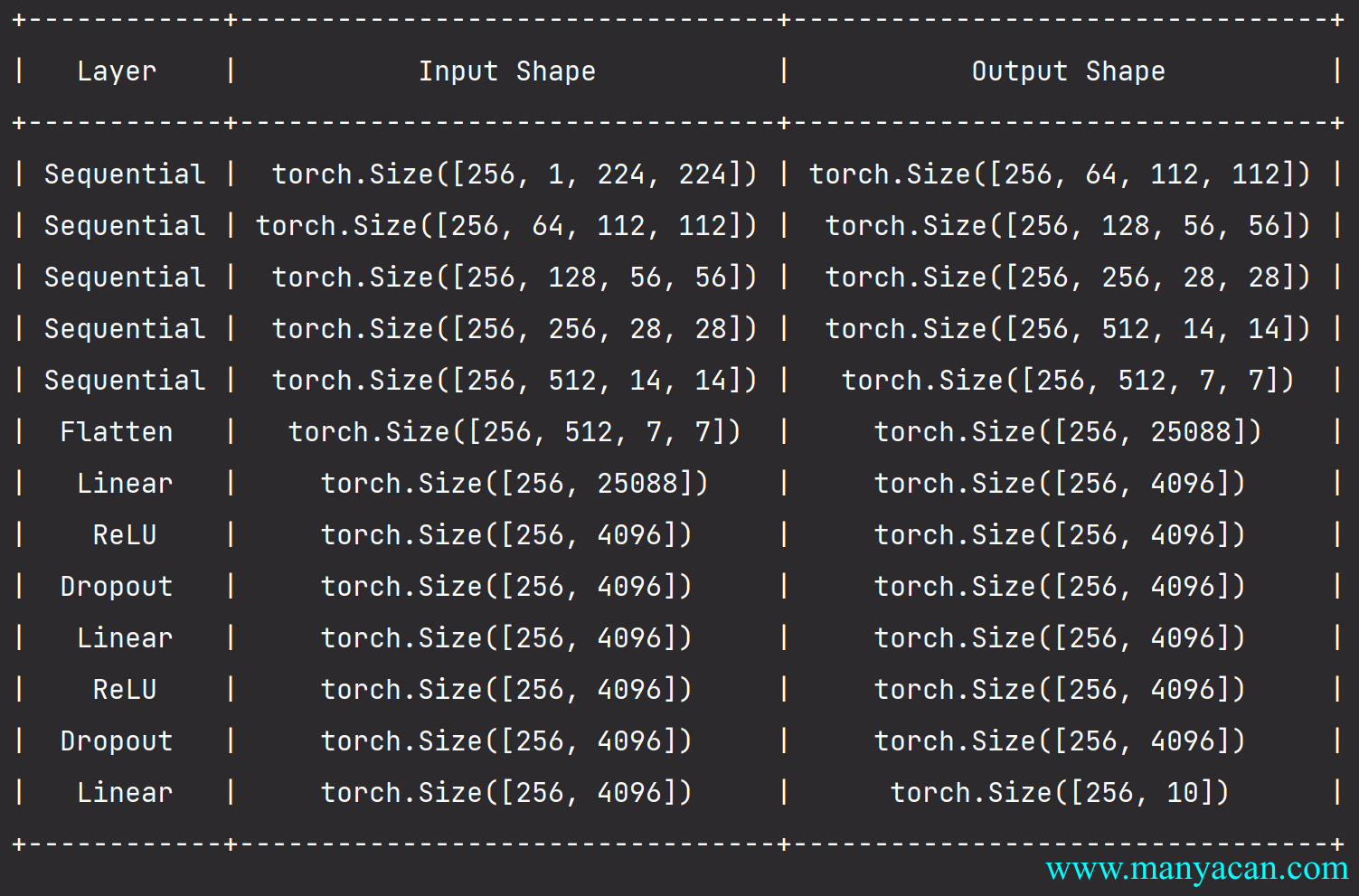
VGG
与芯片设计中工程师从放置晶体管到逻辑元件再到逻辑块的过程类似,神经网络架构的设计也逐渐变得更加抽象。研究人员开始从单个神经元的角度思考问题,发展到整个层,现在又转向块,重复层的模式。使用块的想法首先出现在牛津大学的视觉几何组(visual geometry group)的VGG网络中。通过使用循环和子程序,可以很容易地在任何现代深度学习框架的代码中实现这些重复的架构。
经典卷积神经网络的基本组成部分是下面的这个序列:
- 带填充以保持分辨率的卷积层;
- 非线性激活函数,如ReLU;
- 汇聚层,如最大汇聚层。
而一个VGG块与之类似,由一系列卷积层组成,后面再加上用于空间下采样的最大汇聚层。在最初的VGG论文中,作者使用了带有3\times3卷积核、填充为1(保持高度和宽度)的卷积层,和带有2 \times 2汇聚窗口、步幅为2(每个块后的分辨率减半)的最大汇聚层。

VGG结构与AlexNet对比
网络结构
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layers)
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10)
)
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
net = vgg(conv_arch)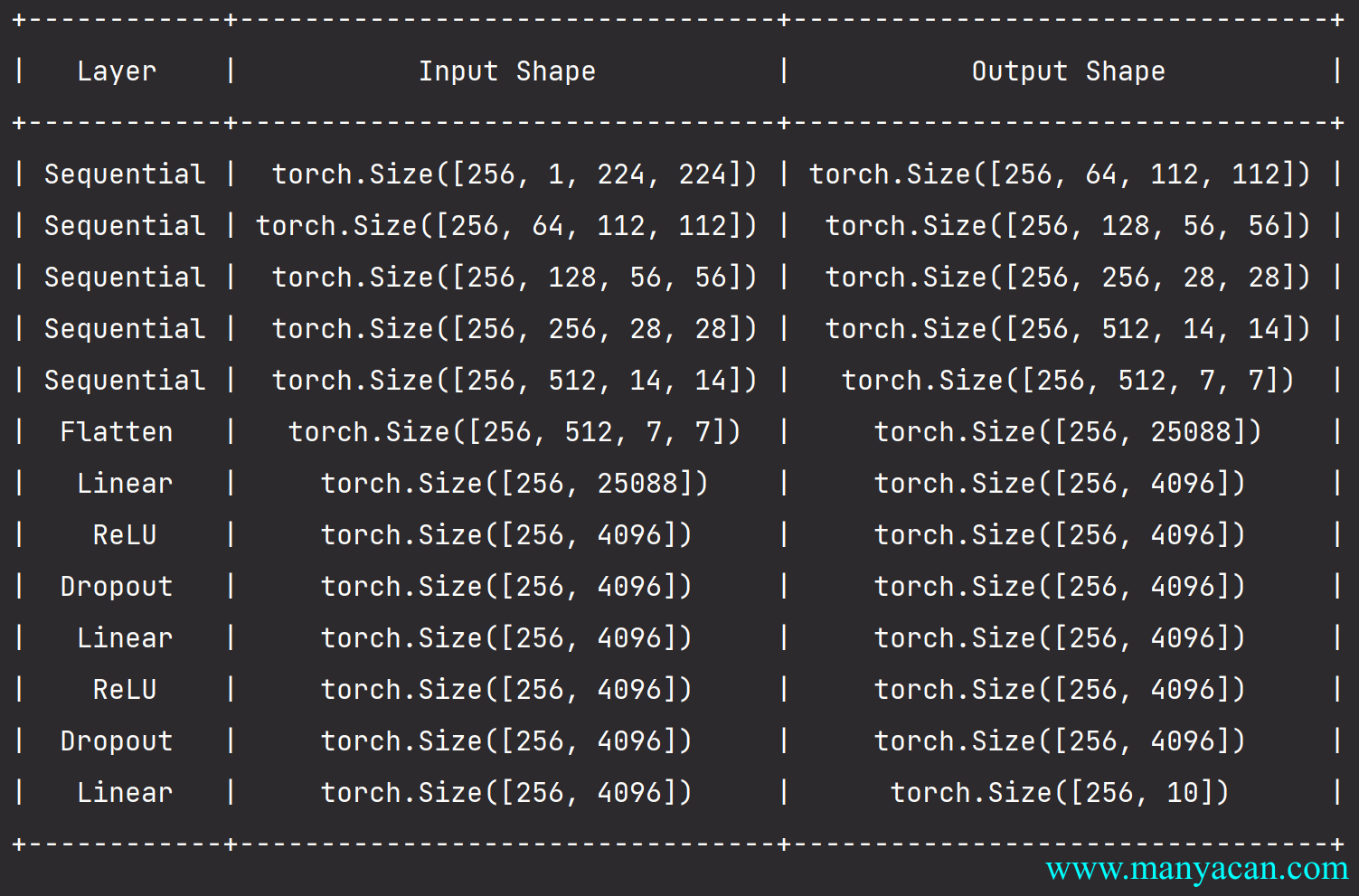
NiN
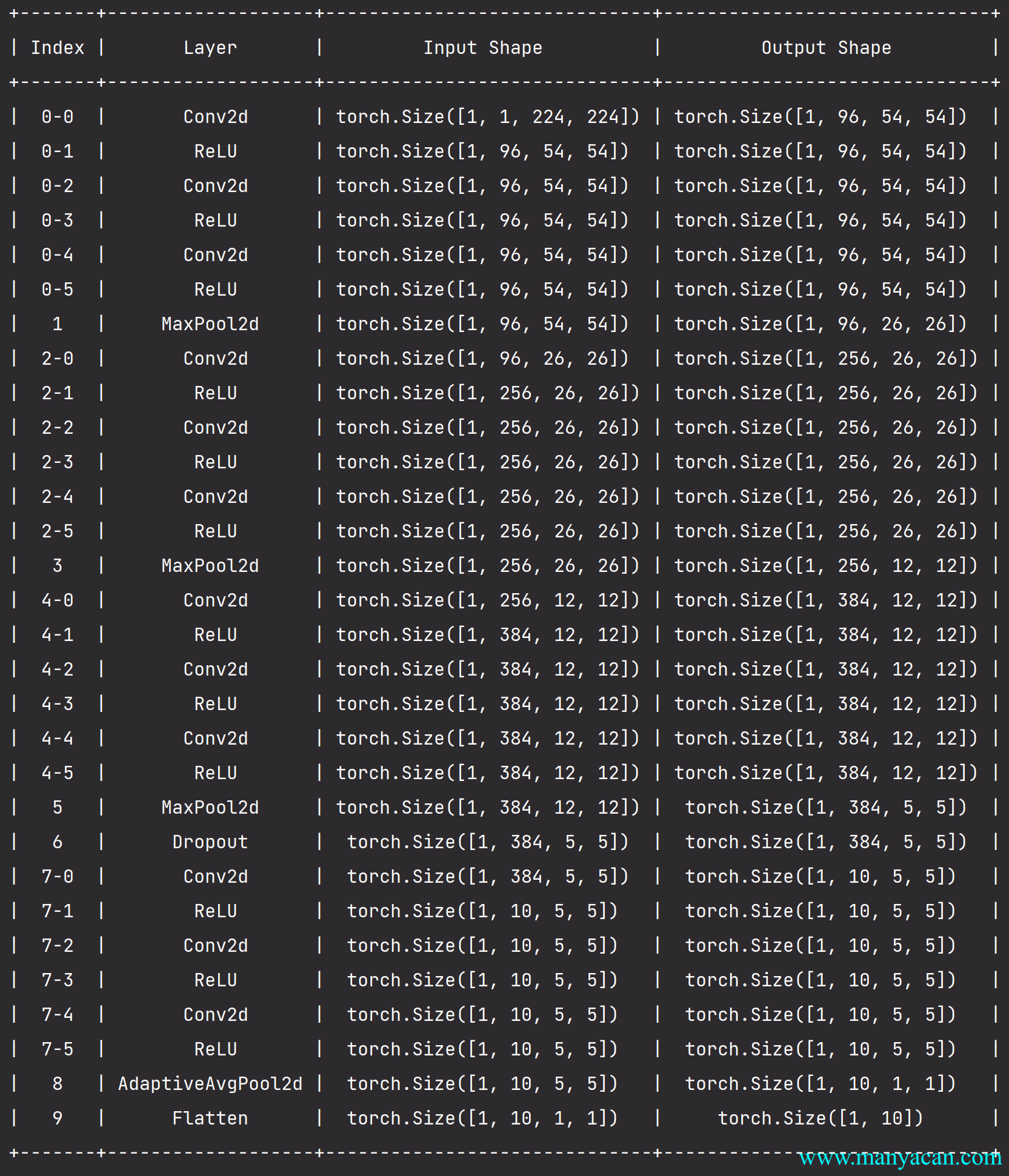
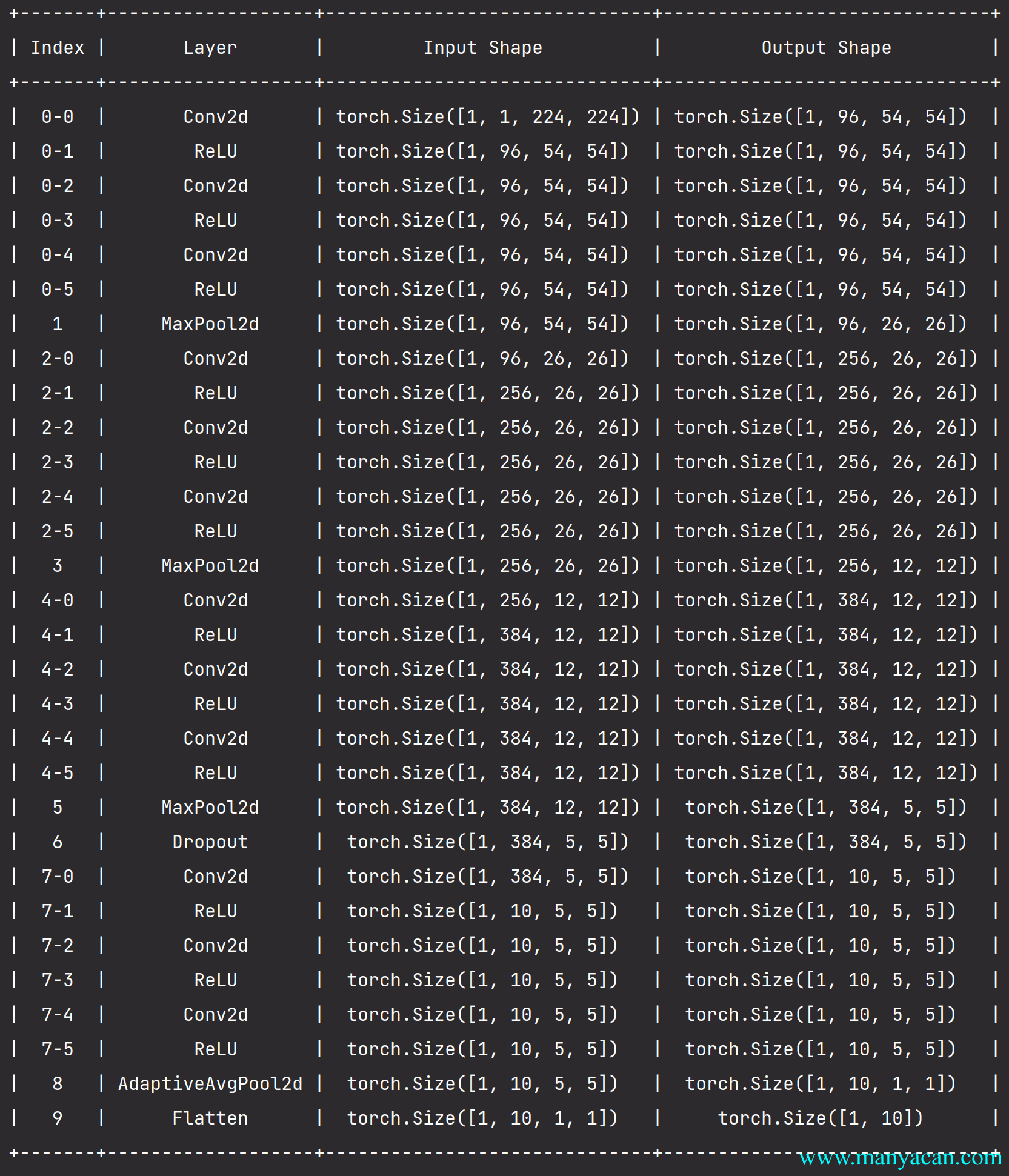
最初的NiN网络是在AlexNet后不久提出的,显然从中得到了一些启示。NiN使用窗口形状为11\times 11、5\times 5和3\times 3的卷积层,输出通道数量与AlexNet中的相同。每个NiN块后有一个最大汇聚层,汇聚窗口形状为3\times 3,步幅为2。
NiN和AlexNet之间的一个显著区别是NiN完全取消了全连接层。相反,NiN使用一个NiN块,其输出通道数等于标签类别的数量。最后放一个全局平均汇聚层(global average pooling layer),生成一个对数几率 (logits)。NiN设计的一个优点是,它显著减少了模型所需参数的数量。然而,在实践中,这种设计有时会增加训练模型的时间。
网络结构
NIN块:
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU()
)网络结构:
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten()
)
GoogLeNet
在2014年的ImageNet图像识别挑战赛中,一个名叫GoogLeNet的网络架构大放异彩。GoogLeNet吸收了NiN中串联网络的思想,并在此基础上做了改进。
本文的一个观点是,有时使用不同大小的卷积核组合是有利的。
在GoogLeNet中,基本的卷积块被称为Inception块(Inception block)。这很可能得名于电影《盗梦空间》(Inception),因为电影中的一句话“我们需要走得更深”(“We need to go deeper”)。
Inception块由四条并行路径组成。前三条路径使用窗口大小为1\times 1、3\times 3和5\times 5的卷积层,从不同空间大小中提取信息。中间的两条路径在输入上执行1\times 1卷积,以减少通道数,从而降低模型的复杂性。第四条路径使用3\times 3最大汇聚层,然后使用1\times 1卷积层来改变通道数。
这四条路径都使用合适的填充来使输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。在Inception块中,通常调整的超参数是每层输出通道数。
网络结构
Inception块:
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)网络结构:
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))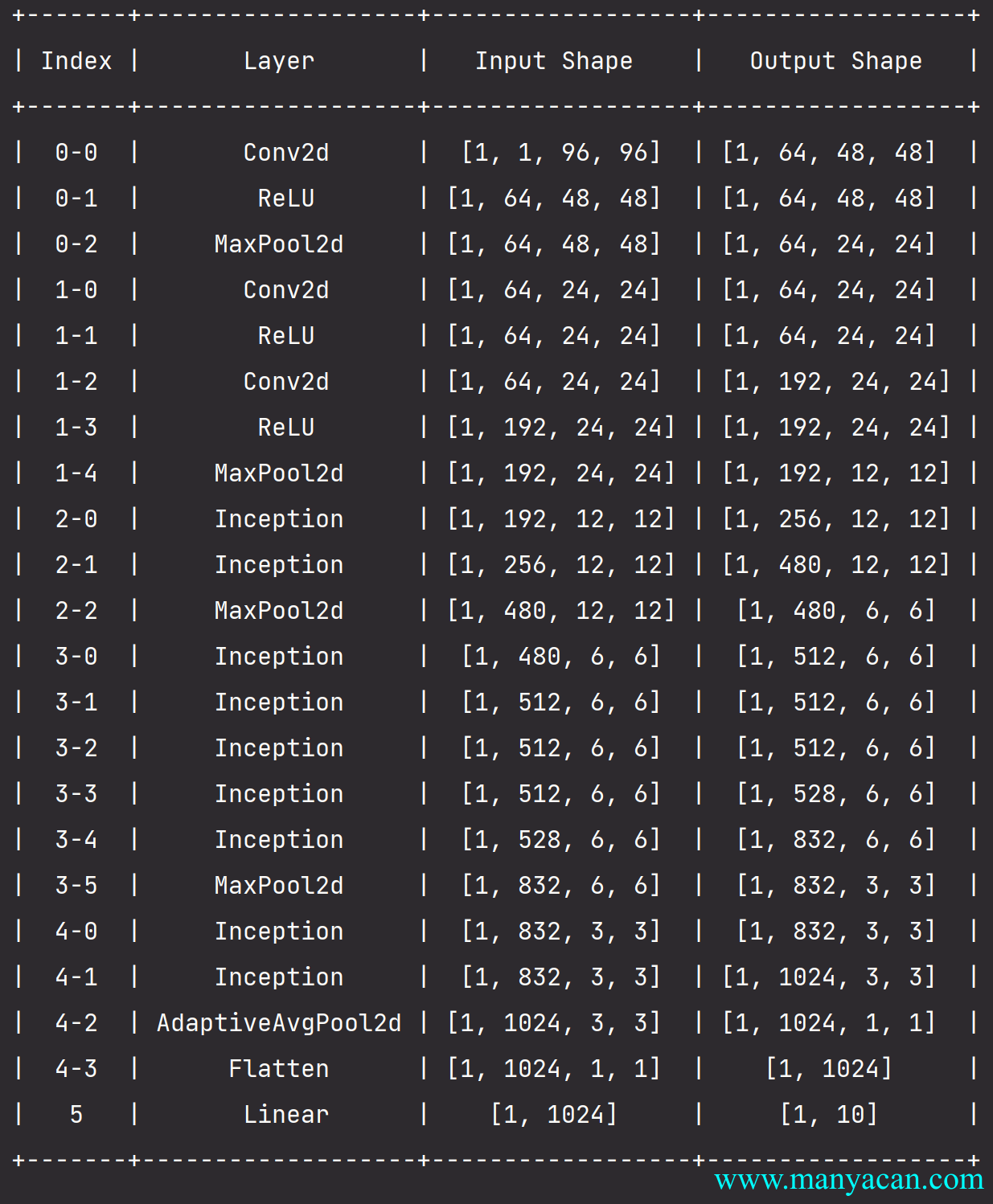
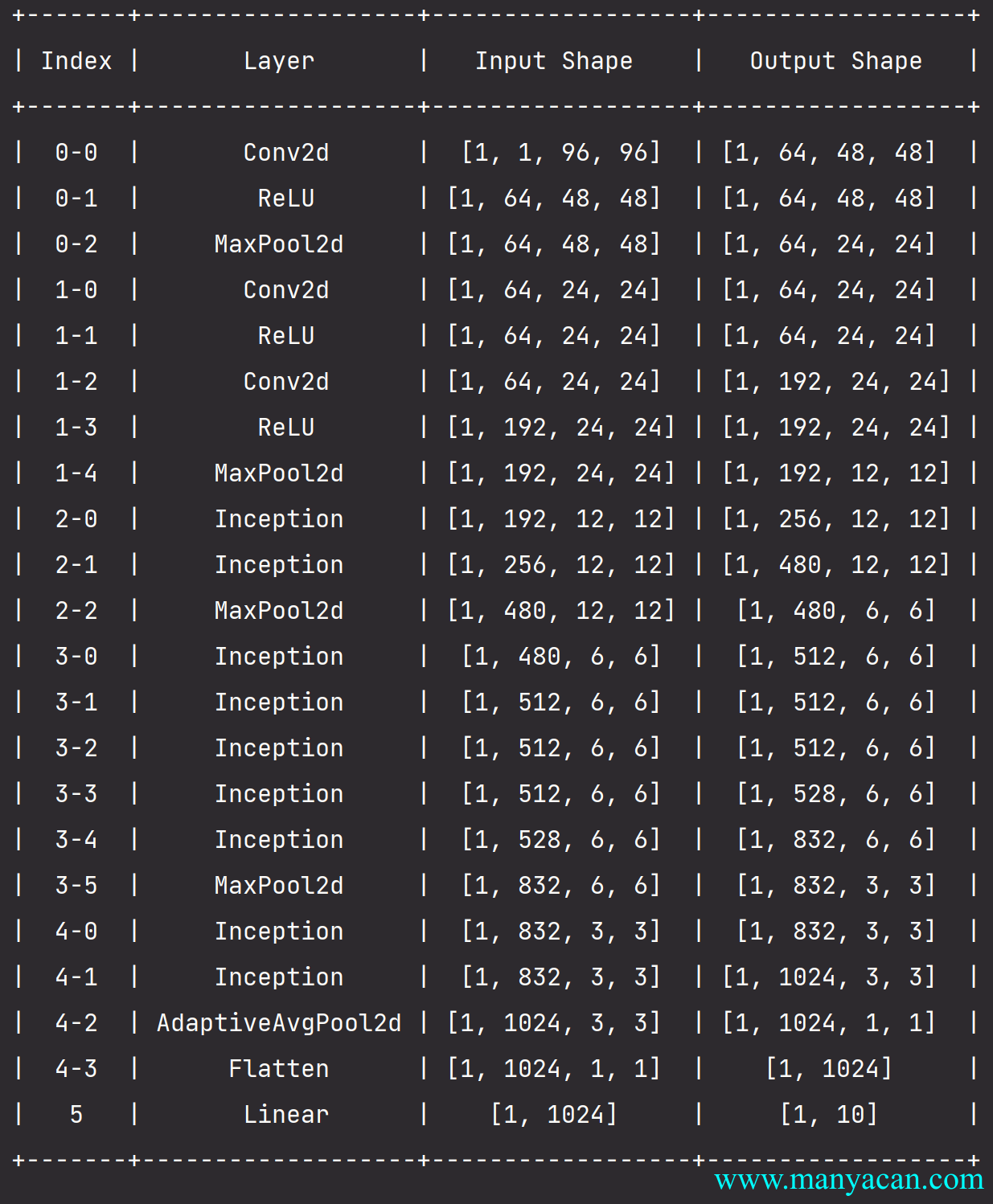
完
当你把深度学习神经网络中的全部数学知识捋一遍会发现,好像其实也没有那么难以理解,甚至其中除了矩阵运算相关的内容有点“高深”以外,剩下的数学知识有个高中水平就可以来理解。
但事实证明,当这些看起来觉得非常简单的数学问题组成了足够大的规模,就可以产生魔法般的效果。
----- END -----
博客站点:亚灿网志(Yacan's Blog) 本文链接:https://blog.manyacan.com/archives/2040/ 版权声明:本文章采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-07-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号