spark structure streaming初探
原创
spark structure streaming初探
原创
滕百川
修改于 2023-07-28 19:02:21
修改于 2023-07-28 19:02:21
1.技术背景
//TODO
2.数据模型
2.1 输入流
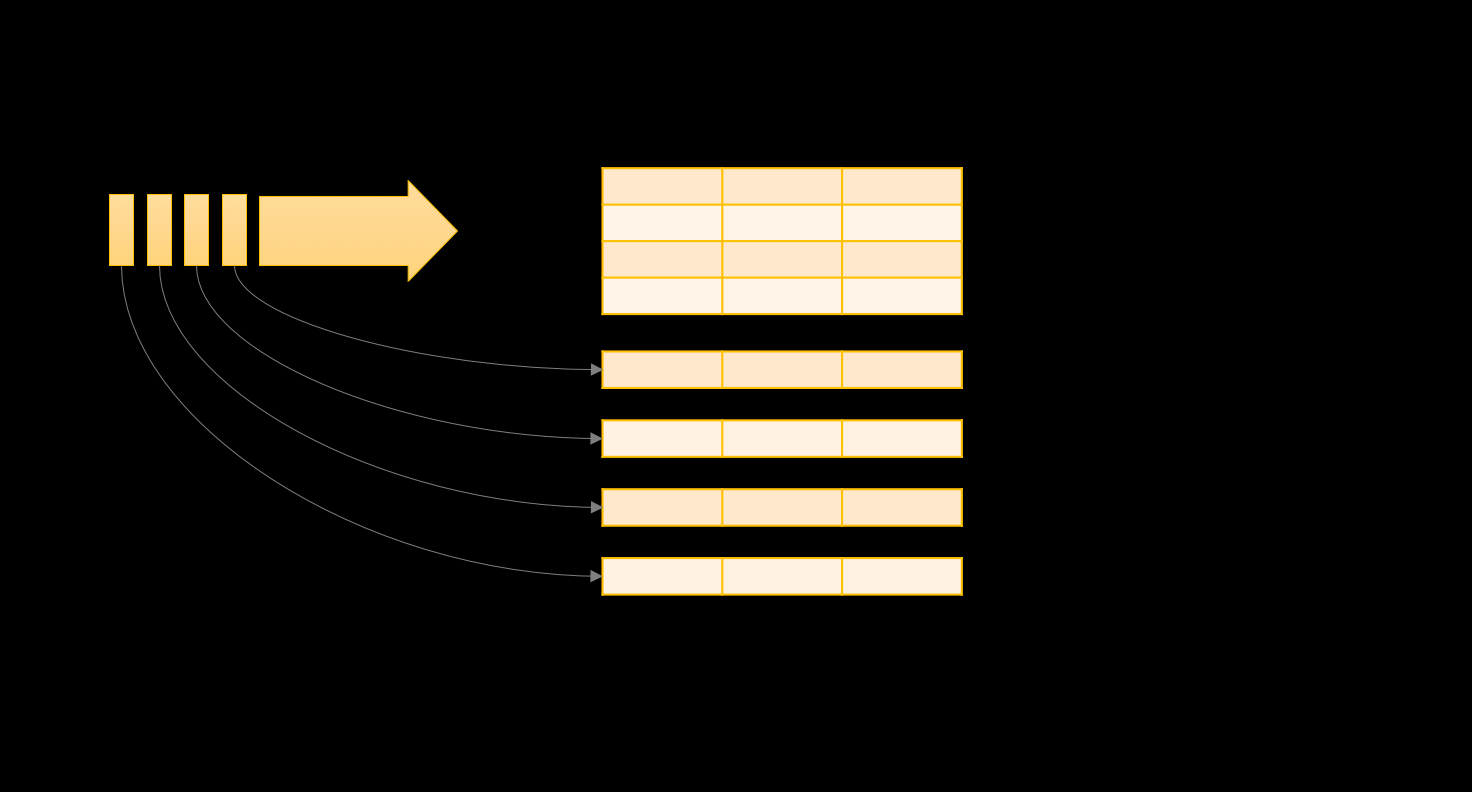
unbounded table
2.2 编程模型
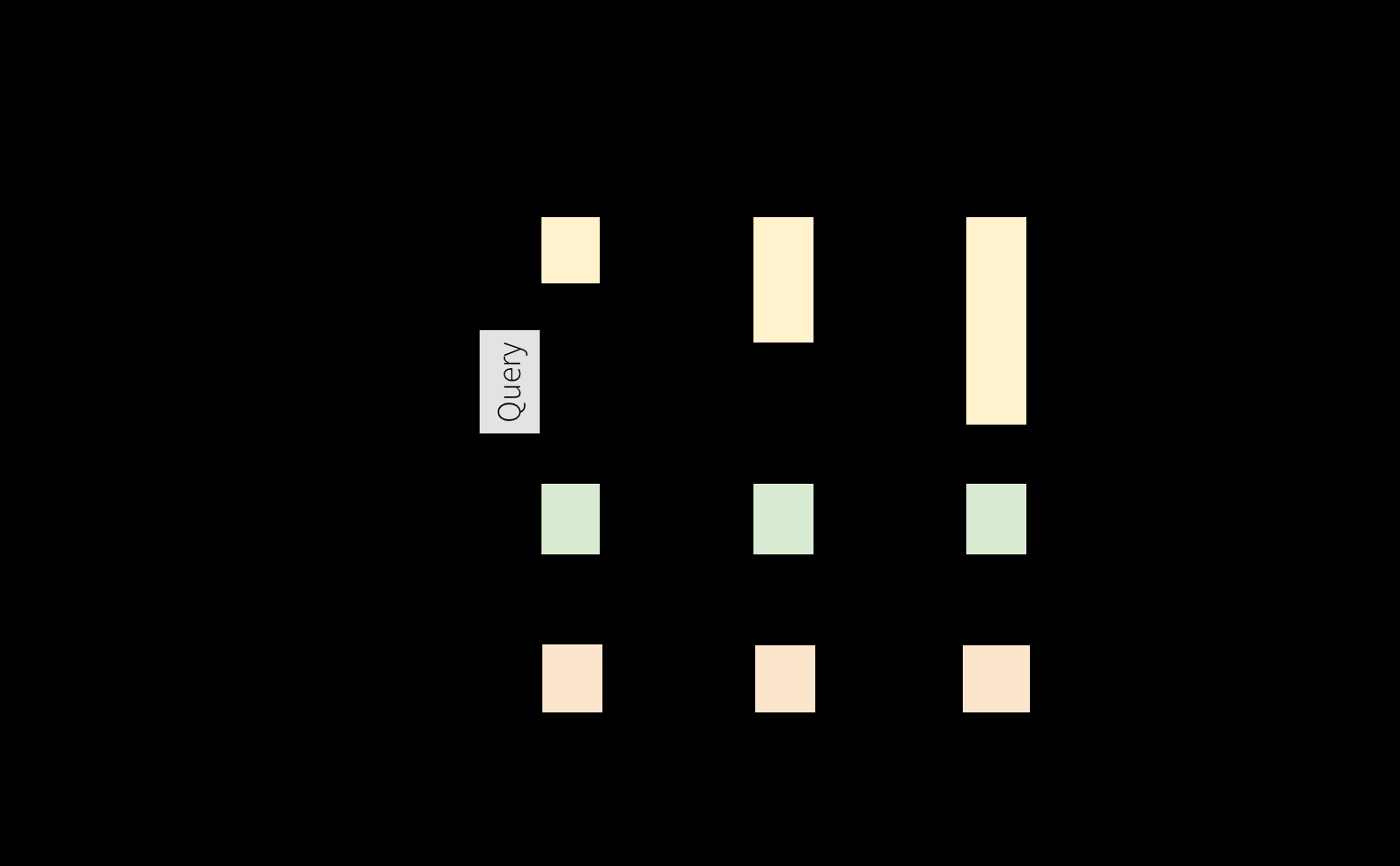
3. 代码示例
3.1 从kafka流式查询数据示例
// Subscribe to 1 topic
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to 1 topic, with headers
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.option("includeHeaders", "true")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)", "headers")
.as[(String, String, Map)]
// Subscribe to multiple topics
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1,topic2")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to a pattern
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribePattern", "topic.*")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]3.2 从kafka批量查询数据示例
// Subscribe to 1 topic defaults to the earliest and latest offsets
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to multiple topics, specifying explicit Kafka offsets
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1,topic2")
.option("startingOffsets", """{"topic1":{"0":23,"1":-2},"topic2":{"0":-2}}""")
.option("endingOffsets", """{"topic1":{"0":50,"1":-1},"topic2":{"0":-1}}""")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
// Subscribe to a pattern, at the earliest and latest offsets
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribePattern", "topic.*")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]3.3 为streaming queries创建kafka sink
// Write key-value data from a DataFrame to a specific Kafka topic specified in an option
val ds = df
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.start()
// Write key-value data from a DataFrame to Kafka using a topic specified in the data
val ds = df
.selectExpr("topic", "CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.start()3.4 批量查询输出到kafka
// Write key-value data from a DataFrame to a specific Kafka topic specified in an option
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.write
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.save()
// Write key-value data from a DataFrame to Kafka using a topic specified in the data
df.selectExpr("topic", "CAST(key AS STRING)", "CAST(value AS STRING)")
.write
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.save()4.参考文档
structured-streaming-programming-guide
structured-streaming-kafka-integration
Real-Time End-to-End Integration with Apache Kafka in Apache Spark’s Structured Streaming
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号