浅谈NLP:从词向量到Transformer| 技术创作特训营第一期
原创
浅谈NLP:从词向量到Transformer| 技术创作特训营第一期
原创
languageX
发布于 2023-08-14 20:28:13
发布于 2023-08-14 20:28:13
是时候把之前学习NLP的知识整理下了。大模型火了后,又涌出好多Transfomer相关的文章,回想当时刚接触NLP的时候,还是从word2vec开始...很久前看的东西都快忘记了,所以想做一些总结。
首先我们看看chatGPT有多强大,
我自己起的本文标题:
《NLP小结》
chatGPT取的文章标题:
- "NLP技术揭秘:从词向量到GPT,你需要了解的一切"
- "探索NLP的进化:从RNN到Transformer,技术演进的全景图"
- "NLP技术大揭秘:Seq2Seq和GPT的对决,谁将主宰未来?"
- "深入解析NLP:从词向量到Transformer,你所不知道的技术细节"
- "NLP技术终极对决:RNN vs. Transformer vs. GPT,谁才是王者?"
- "NLP技术的革命:从词向量到GPT,如何改变我们的世界?"
- "NLP技术全景图:从RNN到GPT,探索自然语言处理的未来"
本系列根据当时学习的路径进行介绍:分词,词向量,RNN,Seq2Seq,Transformer,Bert,GPT,做一些简单介绍和总结。
分词
分词是中文文本处理的一个基础步骤,也是nlp工程中的基础模块。
chatGPT说:
分词是自然语言处理(NLP)中的一个重要步骤,它是将连续的文本序列切分成一系列的独立单元。
在英文中,分词相对简单,因为单词之间通常由空格分隔。但在一些语言中,如中文,文本是连续的,
没有明显的单词分隔符,这就需要分词技术来将句子切分成有意义的词汇单元。
分词的意义主要体现在以下几个方面:
信息检索:在搜索引擎中,用户输入的查询通常是一串连续的文本,分词可以帮助系统理解用户的查询意图,
提高搜索的准确性。
机器翻译:在机器翻译中,分词可以帮助系统更好地理解源语言,提高翻译的准确性。
文本挖掘:在文本挖掘中,分词可以帮助系统提取出文本中的关键信息,如关键词、主题等。
分词根据实现原理和特点,主要分为以下3个类别:
1、基于规则分词算法
该算法是按照一定的策略将待匹配的字符串和一个已建立好的“充分大的”词典中的词进行匹配,若找到某个词条,则说明
匹配成功。常见的基于词典的分词算法分为以下几种:正向最大匹配法、逆向最大匹配法和双向匹配分词法等。
2、基于统计的机器学习算法
这类方法主要是通过统计语料库中词出现的频率来进行分词。常用的是算法是HMM、CRF、SVM。
常见的分词器都是使用机器学习算法和词典相结合,一方面能够提高分词准确率,另一方面能够改善领域适应性。
3、基于深度学习的分词算法
这种方法主要是通过训练神经网络模型来进行分词。例如,双向长短期记忆网络(Bi-LSTM)和变压器(Transformer)
模型就是两种常用的基于深度学习的分词方法。具体的分词方法知识点太多了,本文就不做过多介绍。
我这里想详解介绍下人理解的分词和LLM使用的词(token)的区别。或者说对于文本建模,使用的最小单位究竟是什么?
字符: 英文就是26个英文字符,中文就是汉字。以字符为分词单位虽然简单,但是完全丢失了语义信息,粒度太细。
词:英文就是以空格切分,中文就是具有具体含义的词语。
token: 在LLM中,我们都知道对于训练文本, 第一步就是要tokenizer。词向量也是基于token。这里的token究竟是什么呢?
在早期token就是我们语义上有完整含义的词,比如jieba就是有一个词典,对于未登录词也可以使用使用HMM隐马尔科夫模型和veterbi算法解决。在深度学习出现后,对于OOV问题就无法解决了,都是使用UNK替代未登录词。为了解决OOV的问题,大佬们就提出了一个subword的概念,粒度大于字符(char),又小于词(word)。这个人造概念subword就是LLM中使用的token。
主流的subword分词算法有BPE,WordPiece, ULM, SentencePiece等。
我们看看chatGLM的tokenizer,从源码可以看出使用的是sentencepice算法。
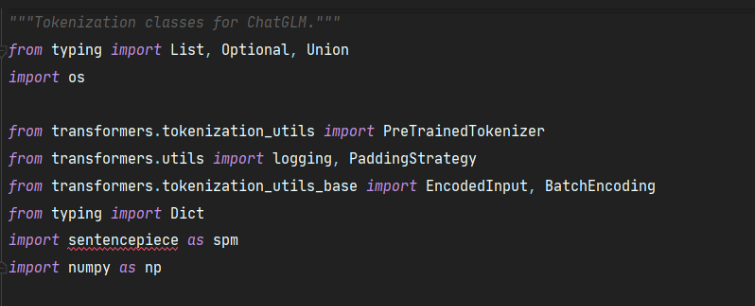
text='魑'
seqs = tokenizer._tokenize(text, add_dummy_prefix=False)
输出:
seq ['<0xE9>', '<0xAD>', '<0x91>']使用unicode编码,测试可以看出“魑”这个汉字是被三个token表示的。
词向量
通过分词以后,我们还需要将token表示为机器能表达的形式,也就是数字化。或者说将词嵌入到一个数学空间中,这种嵌入方式就是词嵌入(word embedding)。
最简单的词嵌入
最简单的将词转换为向量方式,就是one-hot形式。但是one-hot存在维度灾难(词表过大)和语义鸿沟(过于稀疏,词之间太生疏,无法体现词之间的关系)的问题。
早期词向量表示
词向量表示追求语义上的分布合理,分布合理的假设就是:相同上下文语境的词有相似的含义。所以相似或者语义上有关联的词在词向量空间中 应该距离更近。
早期最常用的词向量算法word2vec基于神经网络,采用两种模型CBOW和skip-gram模型,Hierarchical softmax和Negative sampling两套训练技巧。
CBOW(Continuous Bag-of-word Model)主要是使用上下文预测某个词。
skip-gram(Continuous skip-gram Model)只要是使用某个词 预测上下文。
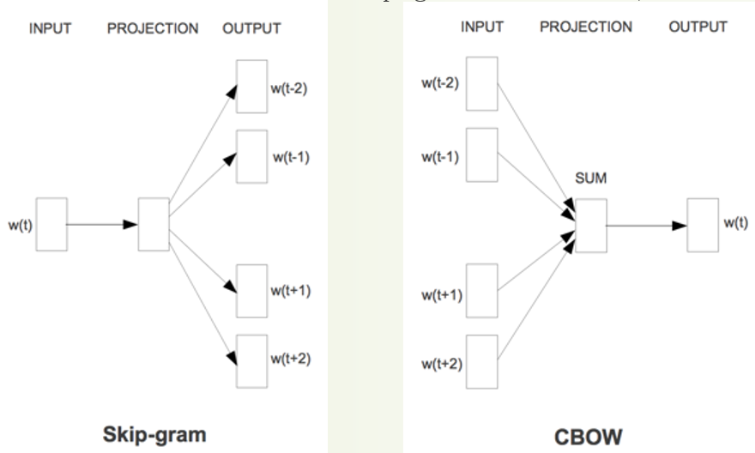
word2vec的目标就是给词一个向量表示。它主要就是一个降维度操作,将词的one-hot表示降维到低维空间。
近期词向量表示
近期词向量表示主要来源于语言模型,词向量不是模型的目标,属于附属品。
比如GPT,在训练语言模型的过程中,将word embedding设置为参数矩阵,然后使用无监督语言模型去自学。
wte = tf.get_variable('wte', [hparams.n_vocab, hparams.n_embd],
initializer=tf.random_normal_initializer(stddev=0.02))在LLM的应用中,比如前篇文章介绍的知识问答系统,我们需要利用词向量去寻找相关文档,有大把的embedding方案让你选择
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import sentence_transformers
embedding_model_dict = {
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
"ernie-base": "nghuyong/ernie-3.0-base-zh",
"text2vec": "GanymedeNil/text2vec-large-chinese",
"text2vec2": "uer/sbert-base-chinese-nli",
"text2vec3": "shibing624/text2vec-base-chinese",
}
EMBEDDING_MODEL = "text2vec3"
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_dict[EMBEDDING_MODEL], )
embeddings.client = sentence_transformers.SentenceTransformer(
embeddings.model_name, device='cuda')
db = Chroma(persist_directory="./data/doc_embeding", embedding_function=embeddings)
print(db)所以,现在使用语言模型获取word embedding已经是主流方案,而且有很多开源模型。
RNN
前面提到语言模型,在transformer框架出现前,有一个很优秀,为NLP做了很大贡献,但是现在好像没落了的NLP大哥RNN,也可用于构建语言模型。
递归神经网络(recurrent neural network,RNN)是一种具有反馈结构的神经网络,
用于处理序列数据的神经网络架构。RNN具有循环连接,使得网络可以处理任意长度的序列,并且在处理每个元素时都可以利用前面元素的信息。
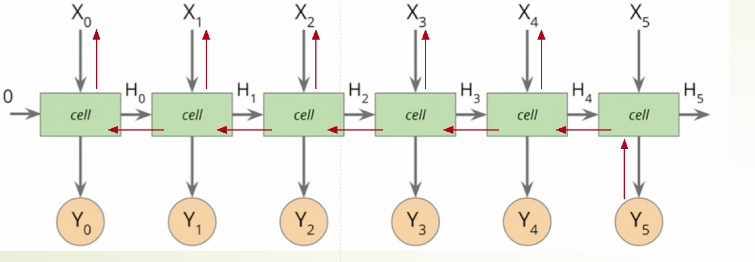
这里有一个注意点:在计算时,每一步使用的参数U、W、b都是一样的,也就是说每个步骤的参数都是共享的,这是RNN的重要特点,一定要牢记。
RNN的优点:
可以处理任意长度的序列。
在处理每个元素时都可以利用前面元素的信息,这对于许多任务(如语言模型、文本生成等)非常有用。
RNN的缺点:
难以处理长序列。由于梯度消失和梯度爆炸问题,RNN在处理长序列时可能难以捕捉序列中的长距离依赖关系。
训练可能比较困难。由于RNN的时间依赖性,不能像前馈神经网络那样进行并行计算,这使得训练可能比较慢。
如上图所示:当时间比较长时,需要回传的残差会指数下降,导致网络权重更新缓慢,无法体现出RNN的长期记忆的效果,因此需要一个存储单元来存储记忆,因此LSTM模型被提出。
为了解决RNN的缺点,人们提出了一些变体,如长短期记忆网络(Long Short-Term Memory,LSTM)和门控循环单元(Gated Recurrent Unit,GRU)。
LSTM通过引入一个记忆单元和三个门(输入门、遗忘门和输出门)来解决长距离依赖问题。记忆单元可以在长时间内保持状态,而门的作用是控制信息的流入、保留和流出。
GRU是LSTM的一个简化版本,它只有两个门(更新门和重置门)。虽然结构更简单,但在许多任务上,GRU的性能与LSTM相当。
总的来说,RNN及其变体是处理序列数据的强大工具,但也有其局限性和挑战。
之前我有比较详细介绍过GRU,本文对RNN算法就不做过多介绍。
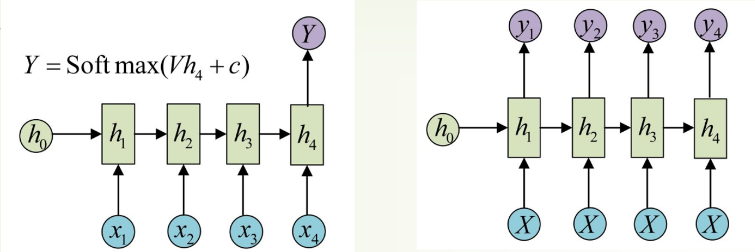
RNN通常对N-1或者N-N的问题解决比较好,对于N-M的问题就比较困难,如果把输出作为输入并不知道什么时候结束,效果也会大打折扣。
Seq2Seq
上面提到了单个RNN结构对于N-M的问题解决存在困难,那我们可以借助两个RNN结构来解决此问题,也就是seq2seq框架。
在一个典型的Seq2Seq模型中,有两个主要组成部分:编码器(Encoder)和解码器(Decoder),它们通常都是RNN或其变体(如LSTM或GRU)。
编码器负责接收输入序列(长度为N),并将其编码为一个固定长度的向量,这个向量可以被视为输入序列的抽象表示。然后,这个向量被传递给解码器,解码器根据这个向量生成输出序列(长度为M),如下图。
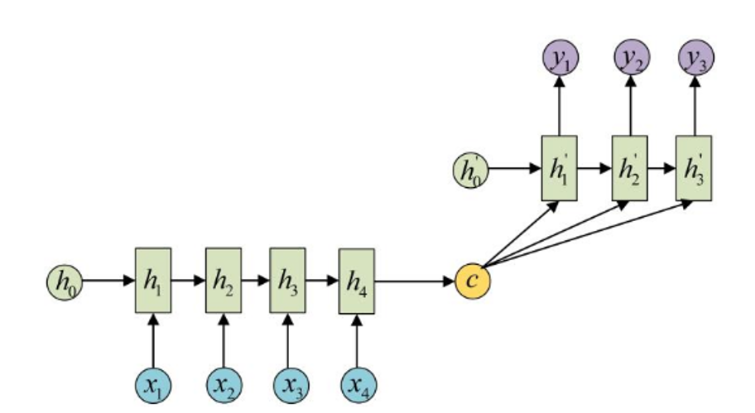
seq2seq框架1(2014.9)
特点是Encoder阶段将整个source序列编码成一个固定维度的向量C(也就是RNN最终的隐藏状态hT),C = f(x1, x2,...,xT),f就是各种RNN模型。并认为C中保存了source序列的信息,将其传入Decoder阶段,在每次进行decode时,仍然使用RNN神经元进行处理。
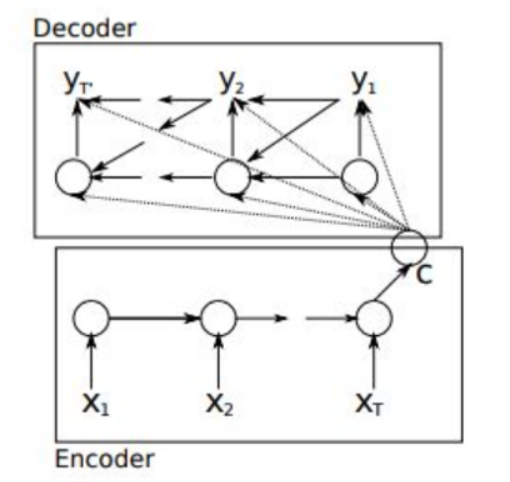
seq2seq框架2(2014.12)
encode的输出c直接进入decode作为初始状态,而不是在每次decode时都作为RNN cell的输入,此外,decode时RNN的输入是目标值,而不是前一时刻的输出。E和D都使用LSTM结构(4层)。
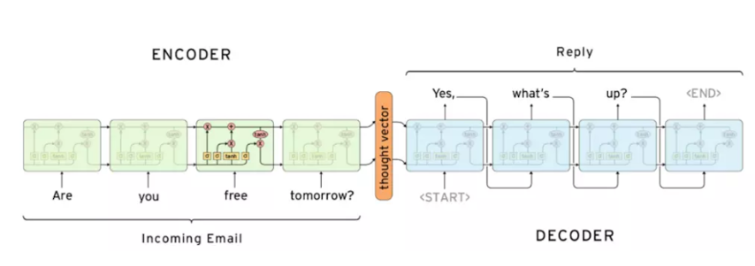
seq2seq with Attention(2016)
前面两个模型都是将source序列encode成一个固定维度的向量,但是这样做对于长序列将会丢失很多信息导致效果不好。
编码器需要将整个输入序列压缩到一个固定长度的向量中,然后解码器根据这个向量生成输出序列。这种设计在处理长序列时可能会遇到问题,因为一个固定长度的向量可能无法有效地表示一个长序列的所有信息。
有研究者就提出使用注意力机制解决了这个问题。在生成每个输出时,注意力机制会计算输入序列中每个词的“注意力分数”,然后根据这些分数生成一个加权的输入向量,这个向量被用来生成当前的输出。这样,模型就可以在生成每个输出时都关注输入序列的不同部分,而不是仅仅依赖于一个固定长度的向量。
如下图encoder阶段所有的隐层状态保存在一个列表当中,然后接下来decode的时候,根据前一时刻状态st-1去计算T个隐层状态与其相关程度,在进行加权求和得到编码信息ci,也就是说每个解码时刻的c向量都是不一样的,会根据target与source之间的相关程度进行权重调整和计算。
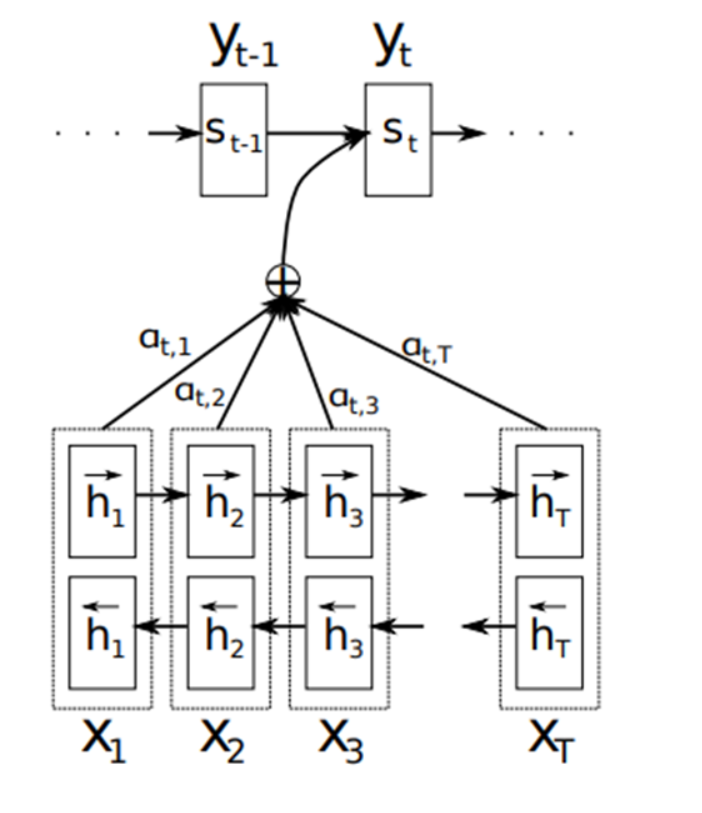
seq2seq with Attention的各种变形
attention效果较好,后续也出现了各种attention的变体,global Attention和local Attention。
出现了attention,大家就很耳熟了吧,attention is all you need。其实在RNN时代就已经有attention机制了,而在RNN的attention之前,CNN早就有attention的概念了。
Transformer
"Attention is All You Need"是一篇由Google的研究者在2017年发表的论文,这篇论文提出了一种全新的模型架构,被称为"Transformer",框架如下图,相信大家已经看过无数次了。
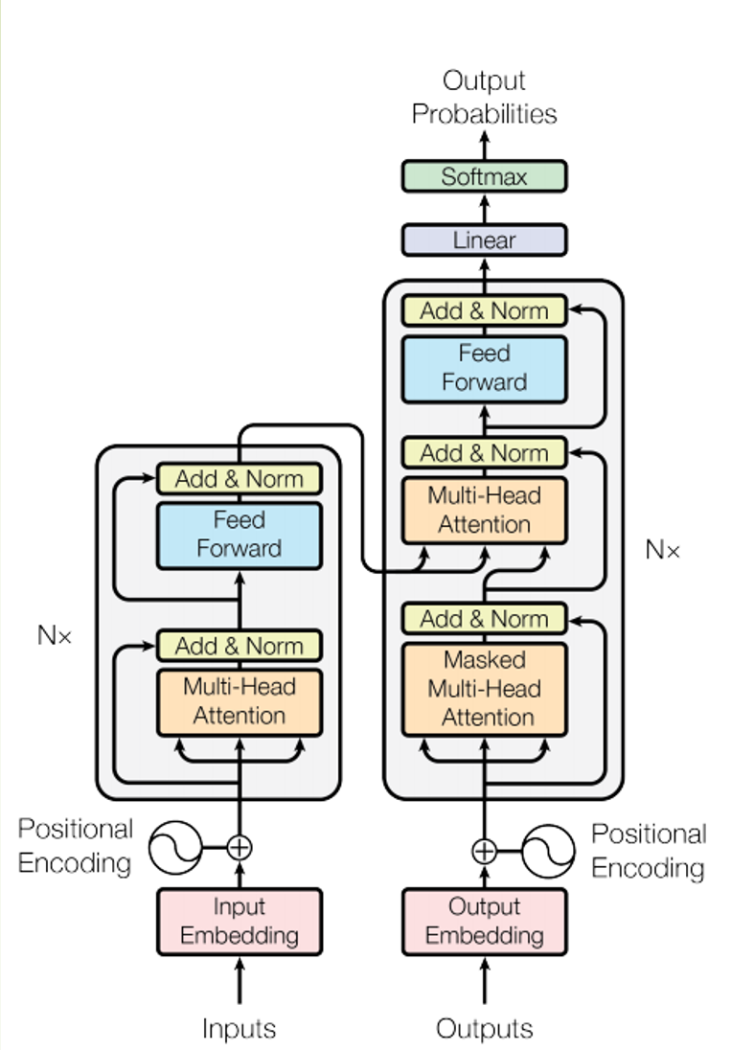
Transformer抛弃了RNN和CNN的“特征提取”,全程靠attention机制,能看到的上下文是属于全局性的。
其中的词向量,位置编码,多头注意力,层归一化,前向反馈,softmax层我就不一一介绍了,很多文章都有详细的介绍甚至动图解释,本文从另一个角度让大家对transformer有进一步的了解。
我们来计算下一个transformer层需要多少的参数量~
以前两篇文章有介绍过大模型的应用,使用的ChatGLM-6B。我们以chatGLM-6B为例,计算下6B是怎么来的。
chatGLM-6B 和chatGLM-6B-int4
首先大家猜一猜,chatGLM-6B-int4模型的参数量是多少?
量化又不会减少参数个数,当然还是6B呀!那我们代码统计下:
def get_info_by_zoey(model):
""" 查看参数个数
"""
Total_params = 0.0
Trainable_params = 0.0
for param in model.parameters():
mulValue = np.prod(param.size())
if param.requires_grad:
Trainable_params += mulValue
print(f'Trainable params: {Trainable_params}, {Trainable_params / 1e9}B')
tokenizer = AutoTokenizer.from_pretrained(r"F:\gpt\chatGLM\ChatGLM-6B\model_file\chatglm-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained(r"F:\gpt\chatGLM\ChatGLM-6B\model_file\chatglm-6b-int4", trust_remote_code=True).half().cuda()
get_info(model.transformer)如果用int4模型结果是:3,355,746,304,近3B
model = AutoModel.from_pretrained(r"F:\gpt\chatGLM\ChatGLM-6B\model_file\chatglm-6b", trust_remote_code=True).half().cuda()
get_info(model.transformer)如果不用int4模型,结果是:6173286400,近6B
这一点我是最初没有想到的,跟踪源码发现chatGLM在量化过程中是进一步模型优化了:
在chatglm-6b-int4/modeling_chatglm.py文件中,如果使用了量化,会调用quantization.py中的QuantizedLinear类,我们看下源码:
class QuantizedLinear(Linear):
def __init__(self, weight_bit_width: int, weight_tensor=None, bias_tensor=None, quantized_weight=None,
quantized_weight_scale=None, quantization_cache=None, empty_init=False, *args, **kwargs):
super(QuantizedLinear, self).__init__(*args, **kwargs)
self.weight_bit_width = weight_bit_width
self.quantization_cache = quantization_cache
if (quantized_weight is not None) and (quantized_weight_scale is not None):
del self.weight
self.weight = Parameter(quantized_weight.to(kwargs["device"]), requires_grad=False)
self.weight_scale = Parameter(quantized_weight_scale.to(kwargs["device"]), requires_grad=False)
else:
shape = self.weight.shape
del self.weight
# 注意:这里逻辑导致int4参数量减少
if weight_tensor is None or empty_init:
self.weight = torch.empty(
shape[0], shape[1] * weight_bit_width // 8, dtype=torch.int8, device=kwargs["device"]
)
self.weight_scale = torch.empty(shape[0], dtype=kwargs["dtype"], device=kwargs["device"])
else:
self.weight_scale = (weight_tensor.abs().max(dim=-1).values / ((2 ** (weight_bit_width - 1)) - 1)).to(
kwargs["dtype"])
self.weight = torch.round(weight_tensor / self.weight_scale[:, None]).to(torch.int8)
if weight_bit_width == 4:
self.weight = compress_int4_weight(self.weight)
print("real shape", self.weight.shape)
self.weight = Parameter(self.weight.to(kwargs["device"]), requires_grad=False)
self.weight_scale = Parameter(self.weight_scale.to(kwargs["device"]), requires_grad=False)看源码逻辑,如果使用量化,会del self.weight,然后重新定义weight的shape,另外新增一个self.weight_scale
后面我们就按照chatGLM-6B-int4的模型分析参数量。
模型配置
先通过配置文件看下超参
{
"_name_or_path": "THUDM/chatglm-6b-int4",
"architectures": [
"ChatGLMModel"
],
"auto_map": {
"AutoConfig": "configuration_chatglm.ChatGLMConfig",
"AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration"
},
"bos_token_id": 130004,
"eos_token_id": 130005,
"mask_token_id": 130000,
"gmask_token_id": 130001,
"pad_token_id": 3,
"hidden_size": 4096,
"inner_hidden_size": 16384,
"layernorm_epsilon": 1e-05,
"max_sequence_length": 2048,
"model_type": "chatglm",
"num_attention_heads": 32,
"num_layers": 28,
"position_encoding_2d": true,
"quantization_bit": 4,
"quantization_embeddings": false,
"torch_dtype": "float16",
"transformers_version": "4.27.1",
"use_cache": true,
"vocab_size": 130528
}词表size是130528,使用了4位量化,transformer层数是28层,分了32个头,hidden_size(attentino层用)是4096,inner_hidden_size是16348(mlp层用)。
词向量
vocab_size=130528, hidden_size=4096 ,也就是一共130528个token,每个token用4096维度的向量表示。
word_embeddings参数量:130528*4096
transformer层
模型类ChatGLMModel,其中有28个GLMBlock构成。我们先分析GLMBlock参数量
class GLMBlock(torch.nn.Module):
def __init__(
self,
hidden_size,
num_attention_heads,
layernorm_epsilon,
layer_id,
inner_hidden_size=None,
hidden_size_per_attention_head=None,
layernorm=LayerNorm,
use_bias=True,
params_dtype=torch.float,
num_layers=28,
position_encoding_2d=True,
empty_init=True
):
super(GLMBlock, self).__init__()
# Set output layer initialization if not provided.
self.layer_id = layer_id
# Layernorm on the input data.
self.input_layernorm = layernorm(hidden_size, eps=layernorm_epsilon)
self.position_encoding_2d = position_encoding_2d
# Self attention.
self.attention = SelfAttention(
hidden_size,
num_attention_heads,
layer_id,
hidden_size_per_attention_head=hidden_size_per_attention_head,
bias=use_bias,
params_dtype=params_dtype,
position_encoding_2d=self.position_encoding_2d,
empty_init=empty_init
)
# Layernorm on the input data.
self.post_attention_layernorm = layernorm(hidden_size, eps=layernorm_epsilon)
self.num_layers = num_layers
# GLU
self.mlp = GLU(
hidden_size,
inner_hidden_size=inner_hidden_size,
bias=use_bias,
layer_id=layer_id,
params_dtype=params_dtype,
empty_init=empty_init
)
def forward(
self,
hidden_states: torch.Tensor,
position_ids,
attention_mask: torch.Tensor,
layer_id,
layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
use_cache: bool = False,
output_attentions: bool = False,
):
"""
hidden_states: [seq_len, batch, hidden_size]
attention_mask: [(1, 1), seq_len, seq_len]
"""
# Layer norm at the begining of the transformer layer.
# [seq_len, batch, hidden_size]
attention_input = self.input_layernorm(hidden_states)
# Self attention.
attention_outputs = self.attention(
attention_input,
position_ids,
attention_mask=attention_mask,
layer_id=layer_id,
layer_past=layer_past,
use_cache=use_cache,
output_attentions=output_attentions
)
attention_output = attention_outputs[0]
outputs = attention_outputs[1:]
# Residual connection.
alpha = (2 * self.num_layers) ** 0.5
hidden_states = attention_input * alpha + attention_output
mlp_input = self.post_attention_layernorm(hidden_states)
# MLP.
mlp_output = self.mlp(mlp_input)
# Second residual connection.
output = mlp_input * alpha + mlp_output
if use_cache:
outputs = (output,) + outputs
else:
outputs = (output,) + outputs[1:]
return outputs # hidden_states, present, attentions可以看出每一层是一个GLMBlock结构,参数变量构成主要是self.input_layernorm,self.attention,self.post_attention_layernorm,self.final_layernorm。
input_layernorm
self.input_layernorm:是一个layer_norm层,LN层参数个数只和通道数有关,而隐藏层是4096。
所以参数量:4092(weight)+4092(bias)
attention
transformer中一个attention计算过程:
step1: 输入经过一层线性变换,通道数转换为4096*3,也就是self.query_key_value。
参数量:12288*4096(weight) + 12288(bias)
但是这里有个量化操作,真实的参数量为:
12288*2048(weight) + 12288(weight scale)+ 12288(bias)
step2: self.query_key_value经过attention_fn计算attention,再经过一个dense操作得到输出。
参数量: 4096*4096(weight) +4096(bias)
量化真实参数:4096*2048(weight) + 4096(weight scale) +4096(bias)
attention模块参数总量:12288 + 12288*2048 + 12288 + 4096 + 4096*2048 + 4096=33,587,200
post_attention_layernorm
attention计算后再经过一层LN,参数量:4096(weight)+4096(bias)=8192
mlp
最后经历一次mlp,mlp主要两个操作dense_h_to_4h,dense_4h_to_h
参数量:
dense_h_to_4h:4096*16384(weight)+ 16384(bias)
dense_4h_to_h:16384*4096(weight)+ 4096(bias)
量化真实参数量:
dense_h_to_4h:2048*16384(weight)+16384(weight scale)+16384(bias)
dense_4h_to_h:8192*4096(weight)+4096(weight scale)+4096(bias)
总参数量:67,149,824
综上,一层glmblock的总参数量: 8192 + 33587200 + 8192 + 67149824 = 100,753,408
总共28层,总参数量:100753408 * 28= 2,821,095,424
final_layernorm层
最后再经过一次LN,参数量:4092(weight)+4092(bias)
所以chatGLM-6B-int4模型总的参数量:
3,355,746,304 = 2,821,095,424 (transformer)+ 534642688(word embeding) + 8192(final LN)
相信通过参数量的统计,大家对模型结构和流程能有进一步的了解。
LLM
近年来,LLM相关的文章和模型太多了

我只简单列出openAI和google的重要模型:
- 2017年中,google提出了Transformer结构。不用rnn,不用cnn, 提出attention is all you need。
- 2018年,OpenAI发布了GPT(Generative Pretrained Transformer)模型。GPT主要使用了Transformer的解码器部分,它是一个自回归模型,即在生成每个词时都会考虑前面的词。GPT在预训练阶段,使用了一个大型的文本语料库,通过预测每个词的下一个词来进行训练。在微调阶段,GPT可以被适应到各种不同的任务,如文本分类、情感分析等。
- 同年,Google发布了BERT(Bidirectional Encoder Representations from Transformers)模型。BERT使用了Transformer的编码器部分,它是一个双向模型,即在理解每个词时都会考虑它的上下文。BERT在预训练阶段,使用了一个大型的文本语料库,通过预测被随机遮挡的词来进行训练。在微调阶段,BERT也可以被适应到各种不同的任务。BERT模型在11个NLP任务上刷新了记录,包括阅读理解、情感分析等。但是BERT名气和应用是大于GPT,但是BERT不适合用于生成任务。
- 2019年openAI又推出了GPT-2模型,GPT模型的升级版。GPT-2模型的结构与GPT类似,但模型的大小和训练数据都有大幅度增加。GPT-2在生成文本的能力上表现出色,能生成连贯且具有一定逻辑的长文本。
- 2019年,google也提出了T5(Text-to-Text Transfer Transformer)模型。T5将所有NLP任务视为文本到文本的转换问题,通过统一的输入输出格式来处理各种任务。T5模型采用了编码器-解码器架构,使用了类似BERT的双向预训练和GPT的生成式微调。T5在多个NLP基准测试中取得了最先进的性能。
- 2020年,OpenAI又发布了GPT-3(Generative Pretrained Transformer 3)。GPT-3的模型规模远超过之前的版本,拥有1750亿个参数。GPT-3在许多NLP任务上表现出色,包括文本生成、翻译、摘要等。由于模型规模的增加,GPT-3在很多任务上可以实现“零样本学习”(Zero-Shot Learning),即不需要微调就能直接应用于特定任务。开辟了NLP任务的一个新范式。
- 2022年1月,openAI推出InstructGPT,采用GPT3的网络结构,对GPT3进行有监督微调(SFT),然后使用人工标注使用人类反馈,训练一个奖励模型(RM),最后再使用RM作为强化学习的训练目标,利用PPO算法去微调SFT模型。也就是说使用了指示学习(Instruction Learning)和人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF),顺便提一下,RLHF最早可以追溯到Google在2017年发表的《Deep Reinforcement Learning from Human Preferences》。
- 2022年11月,推出chatGPT,ChatGPT 的博客中讲到 ChatGPT 和 InstructGPT 的训练方式相同,不同点仅仅是它们采集数据和使用数据的训练方式有所不同,但是目前并没有更多的资料来说明其数据采集和训练上到底有哪些细节上的不同。但是效果要比InstructGPT好很多,很少胡说八道了。
- 再后来就是2023年3月,大家都知道的openAI推出的GPT4了。
【选题思路】
从22年底,大模型就是深度学习领域的一个热门话题,一直想对transformer和LLM写一些技术文章,但是好的文章一篇接一篇的出现,根据看不完,自己也犯懒只看不写。恰好借着这次创作特训营的机会,觉得还是要动手将之前对NLP相关的技术进行一些总结,虽然大家现在都只关注transformer以后的LLM技术,但是对于之前的“老技术”,我觉得还是需要记住,从文章中也可以看出来,每次新技术都是在旧技术之上的改进和优化。而且LLM的参数量是很大的,不是所有的问题都要上大模型,有时候也许一个分词或者bert也能解决。
【写作提纲】
1、介绍分词。了解chat,word,subword和token的区别。
2、了解RNN的优缺点。
3、了解Seq2Seq框架。
4、了解Transformer框架。以ChatGLM为例,了解如何计算一个大模型的参数量
5、了解bert和GPT系列。
参考:
https://www.zhihu.com/question/64984731
https://blog.51cto.com/u_15671528/5573196
https://www.infoq.cn/article/pfvzxggdm27453bbs24w
https://zhuanlan.zhihu.com/p/32092871
https://maimai.cn/article/detail?fid=1783205073&efid=f3JZ5G-Zze3dSjL9d775ag
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号