清华大学SageFormer:解决多变量时间序列预测建模难题

清华大学SageFormer:解决多变量时间序列预测建模难题

圆圆的算法笔记
发布于 2023-08-17 08:53:25
发布于 2023-08-17 08:53:25
基于Transformer的多变量时间序列预测,是否需要显示建模各个变量之间关系呢?今天这篇文章来自清华大学近期发表的工作SageFormer,提出了一种新的基于Transformer的多变量时间序列预测算法,核心是利用token表征建立多变量的图结构关系。下面给大家详细介绍一下这篇文章。

论文标题:SageFormer: Series-Aware Graph-Enhanced Transformers for Multivariate Time Series Forecasting
下载地址:https://arxiv.org/pdf/2307.01616v1.pdf
1、背景
历史的Transformer在多元时间序列应用的工作中,大多都忽略多变量之间的关系,将多变量独立的输入到Transformer中编码。并且之前的部分工作反而证明,各个变量独立建模的Transformer模型效果更好。比如,在我们之前介绍的工作多元时序预测:独立预测 or 联合预测?中,就详细分析了独立建模和联合建模的差异。
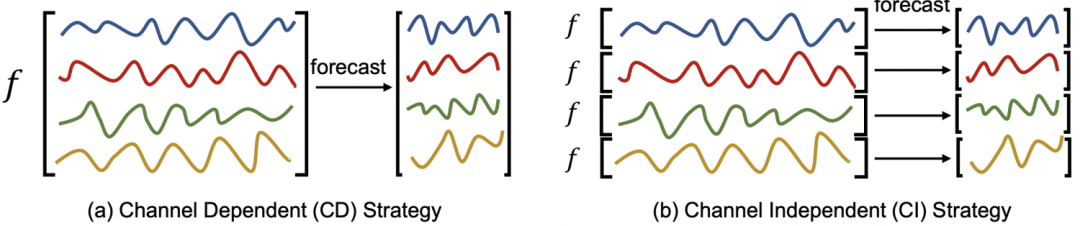
另外,在A TIME SERIES IS WORTH 64 WORDS: LONG-TERM FORECASTING WITH TRANSFORMERS(ICLR 2023)这篇文章中提出的Transformer多元时间序列建模方法PatchTST中,也使用的是各个通道独立建模的方式。
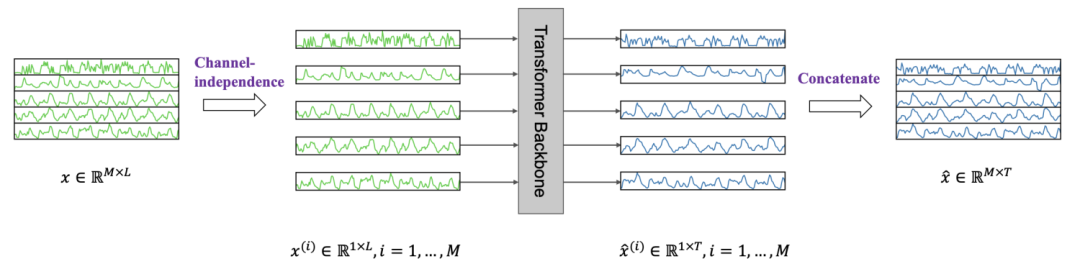
然而,多变量之间的关系是可以带来信息增益的,问题在于如何学习到各个变量的关系,将其有效的引入模型中,同时又能避免冗余的信息干扰模型训练过程。这也是SageFormer这篇文章研究的重点。
2、SageFormer原理
为了解决多变量关系建模的问题,清华大学提出了SageFormer,是一种全新的建模多变量时间序列关系方法。如下图中的b和c所示,b是一般的多变量联合建模方式,将多变量每个时间步的信息融合到一起输入到一个Transformer中;c则是完全不考虑多变量间关系,每个序列独立的输入到Transformer中。而本文提出的方法,为每个序列前加入一个全局token,用来提取各个变量序列自身的信息,然后利用图学习的方式进行多变量关系的抽取。
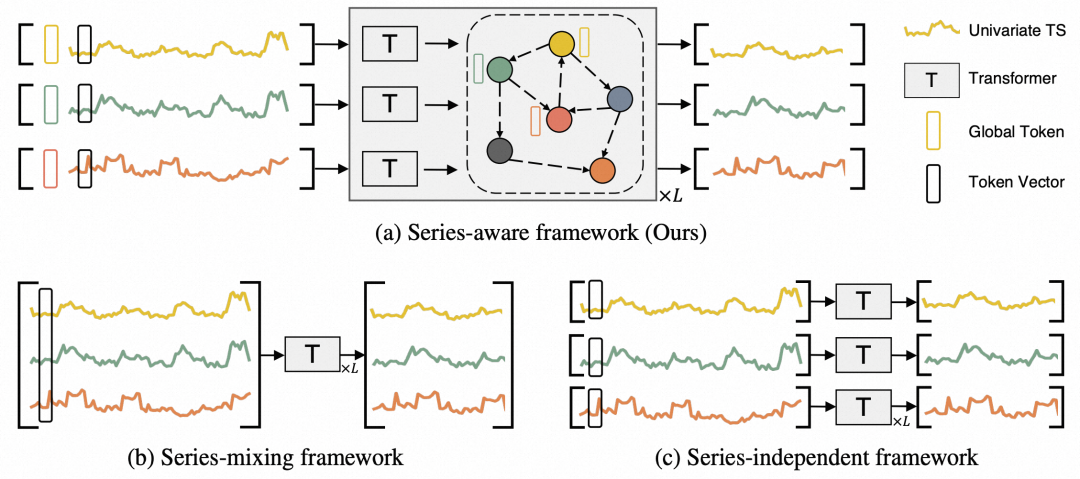
详细的模型结构主要包括3个部分:全局token、动态图学习、时空网络。输入序列采用PatchTST的方式处理成多个patch,在每个变量序列前方添加多个全局token,这些token用来提取每个序列的全局信息。同时,利用每个序列随机初始化的embedding端到端学习各个变量之间的图结构。最后,在时空网络部分,使用图学习根据学到的图结构,对全局token的表征进行空间上的汇聚,汇聚得到的结果过一次时序维度上的Transformer产出最终的编码,其中时空网络部分会迭代多次,每次是一层图汇聚加上一层时间维度Transformer。

通过本文的这种方式,多变量的每个序列主体仍然是单独过Transformer建模的,但是增加了一路学习序列间关系的分支,利用全局token提取每个序列的表征进行信息交互。这样将时间维度和空间维度分拆开,相比原来直接多变量融合到一起输入模型,更清晰的独立建模了每个变量的时序信息和多个变量的空间交互信息。
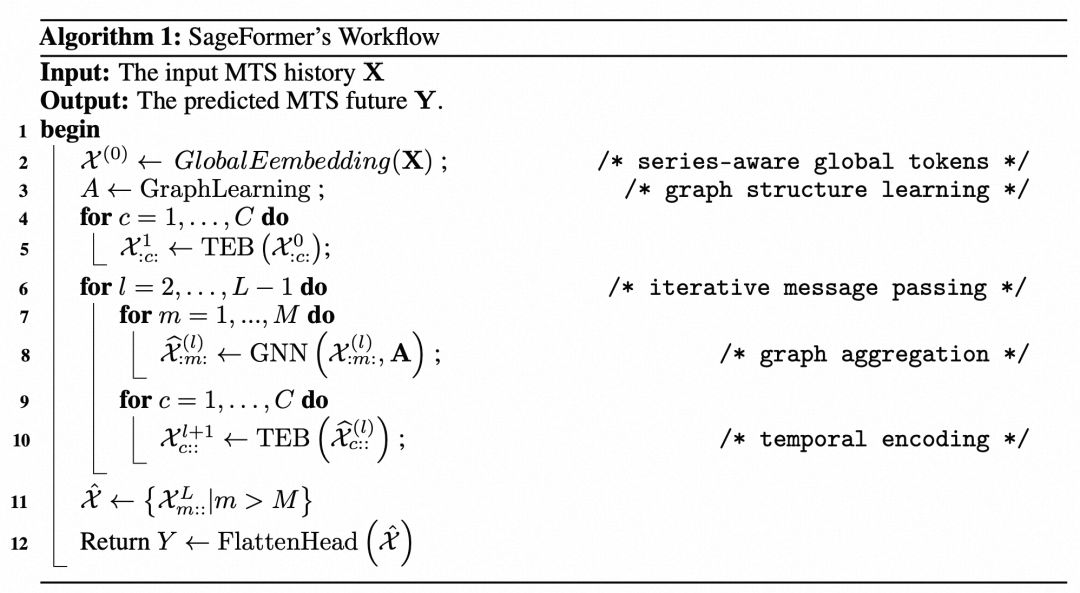
SageFormer整体的工作流程如下:
3、实验结果
文中对比了各类模型在多个数据集中的效果,对比模型包括Transformer单变量预测模型,如AutoFormer、Informer等,也包括一些时空预测模型,如MTGNN。实验结果表明,本文提出的方法在多元时间序列预测任务中效果显著。

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-08-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号