GPT4RoI:面向区域级图像理解的端到端多模态大模型

GPT4RoI:面向区域级图像理解的端到端多模态大模型

OpenMMLab 官方账号
发布于 2023-08-21 18:42:54
发布于 2023-08-21 18:42:54

ChatGPT 和 GPT4 等大模型的出现让人们看到了通用人工智能的曙光。无论是能接触到海量数据和算力的大公司,还是在开源数据集和预训练模型上做小型实验的个体,这一次技术浪潮都给我们带来了无限可能。
本文将支持自然语言的交互方式的图片级多模态系统向前推进了一步,开发了一套同时支持自然语言与在线画框的交互方式的区域级多模态系统 GPT4RoI,希望在开源社区中贡献一份力量。
论文:
https://jshilong.github.io/images/gpt4roi.pdf
开源代码:
https://github.com/jshilong/GPT4RoI
在线 demo:
http://139.196.83.164:7000/
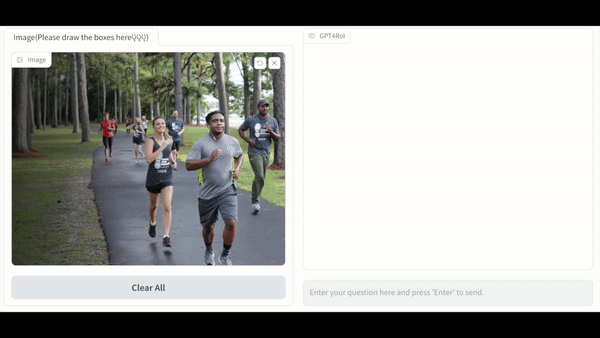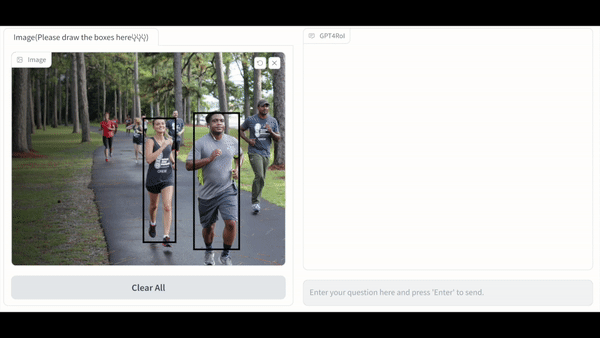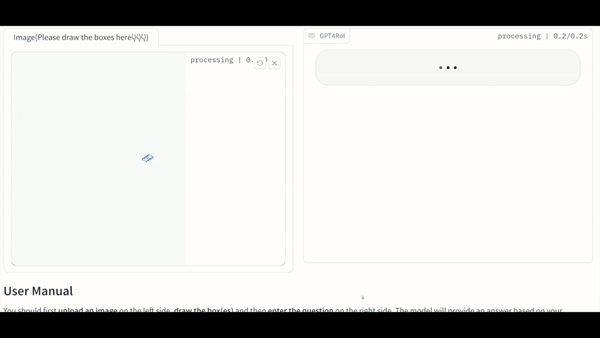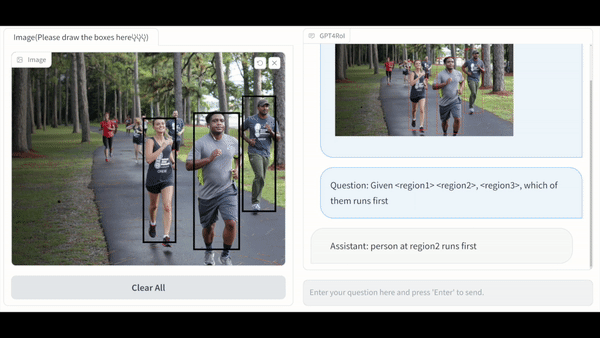
本文的结构如下:
- 回顾 GPT4 开源项目
- Lanauge Instruction 和 Spatial Instruction
- Spatial Instruction Tuning on Region-Text Pairs
- GPT4RoI Demo
- 未来的改进方向
回顾 GPT4 开源项目
回顾 GPT-4 相关的 paper 和开源项目,以自然语言的交互方式完成图片级感知和推理任务的研究中涌现出一系列优秀的工作。尽管这些工作只是基于开源数据集和预训练模型,缺乏在海量数据和算力条件下的大规模实验验证,但是通过各方贡献者的不懈努力,我们看到了平民化 GPT-4 的可能性。进一步发展,开源社区还能做些什么?我们发现,现有的开源模型在理解图片中特定物体或者区域时的表现并不能令人满意,主要体现在:
- MiniGPT-4,LLaVA 等仅支持自然语言交互,但在区域级理解的任务中仅用自然语言无法准确描述需求
- MM-REACT,InternGPT 等通过多模型拼接的方式实现了区域级理解,模型间的传输媒介是文本,这显然是一种暂时性的方案,以 feature 作为传输媒介的端到端的多模态模型会有更高的上限
- VisionLLM 等端到端的网络只实现了区域级感知的功能,还不能支持区域级逻辑推断
于是,一种支持自然语言与在线画框的交互方式,端到端的,区域级感知和推理的多模态对话系统成为 GPT-4 开源项目的下一个发展方向。
Language Instruction and Spatial Instruction
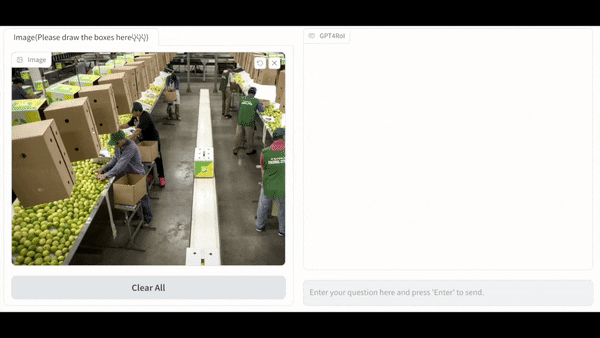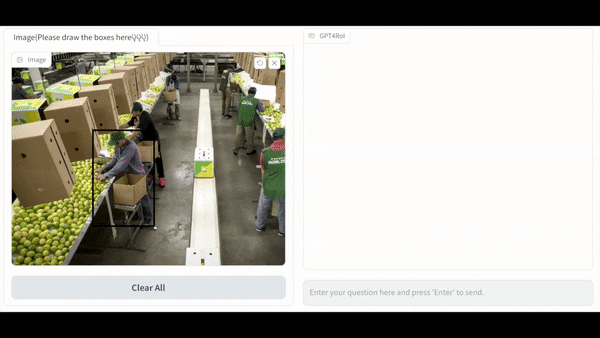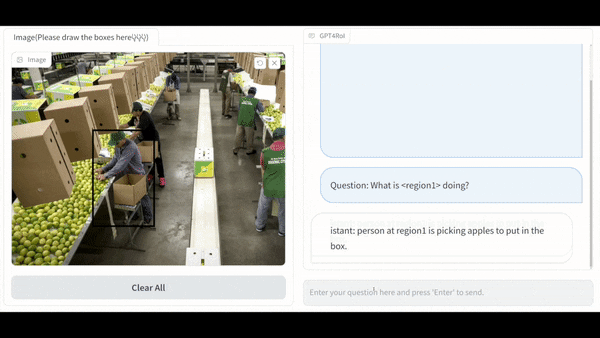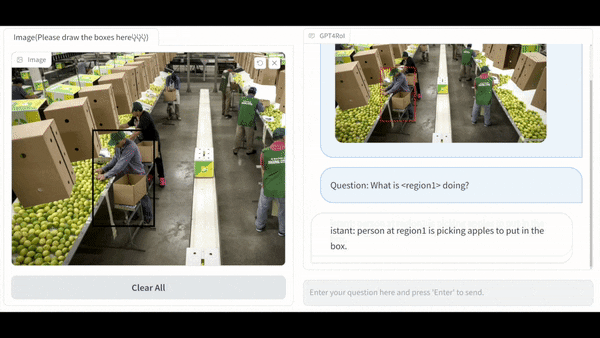
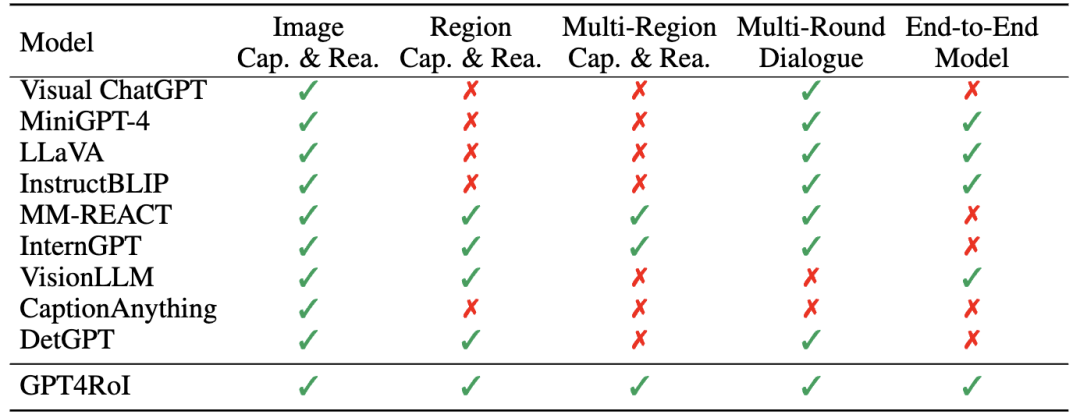
端到端多模态模型的基本框架为: 以 Large Language Model(LLM)作为通用接口,将 vision encoder 提供的 image token 和 language instruction token 拼接后送进 LLM, 得到 language response。这一框架中,整张图片的信息被无差别地压缩进 image token 中,用户如果对图片中某一特定区域感兴趣,只能通过自然语言描述需求,这在很多场景中的沟通效率较低,如下图 (a) 中的 the woman in the upper left corner of the picture。而一种更显式的描述需求的方式是综合自然语言与空间指代的方式(interleaved language instruction and spatial instruction)。以用户在线画框为例,用户在图像中框选出感兴趣的区域,记为 <region1>,并使用自然语言提问,如,what is <region1> doing?

在同时支持自然语言与在线画框的多模态系统中,LLM 的输入不再是 image token 和 language instruction token 的简单拼接,而是将 language instruction token 中的 <region> 替换为对应的 region token,其中 region token 可以通过 RoI-Align 的方式从 image feature map 中直接抠取,也可以通过 deformable decoder 的方式与 image feature map 进行 attention 交互获取。这种 interleaved language instruction and spatial instruction 的拼接方式允许多个区域输入,如,what was <region1> doing before <region3> touched him? 这使得多模态系统既可以实现单区域的理解,也可以实现多区域的理解。这种多区域的理解激发出了一些非常有趣的应用,例如,对区域描述的粒度控制和多区域间的关系推理。
Spatial Instruction Tuning on Region-Text Pairs
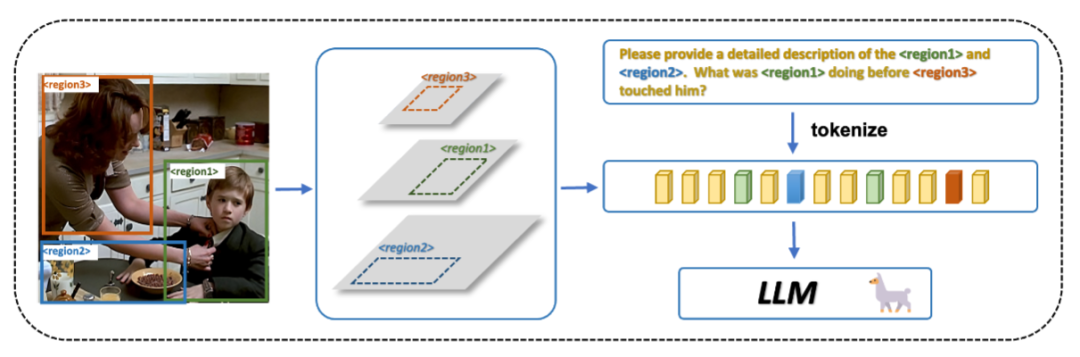
基于 LLM 的开源多模态大模型的训练方法一般是在 image-text pairs 数据上 instruction tuning 预训练好的 LLM 和 vision encoder (CLIP),从而对齐特征空间。这种图片级对齐的模型没有显式对齐文本片段与图片区域,在处理区域级任务时对图片特定区域的理解能力较差。因此,面向区域级理解的多模态大模型需要在 region-text pairs 数据上建立 LLM 和 vision encoder 的区域级对齐。
幸运的是,开源数据集中已经有一些 region-text pairs 数据,虽然数量上远小于 image-text pairs 数据,但是对提高多模态模型的区域级理解和推理能力有很大帮助。
在具体训练时,region-text pairs 需要转化为用于 spatial instruction tuning 的格式,具体做法是,物体框标注作为 spatial instruction,文本标注转化成一组 language instruction和language response。image-text pairs 也可以转化为用于 spatial instruction tuning 的训练数据,具体做法是,通过一个预训练的通用物体检测器从图像中提取多个物体框作为 spatial instruction,将 spatial instruction 提取的 region token 直接拼接在 LLM 原有的输入上。
我们将这些转化后的数据根据 language response 的长度分为两类,分别用于模型的两阶段训练:
第一阶段训练:冻结 CLIP 和 LLM,只训练从 vision encoder 到 LLM 的 region 级别的 feature projection layer,具体则包括一个 multi-level 的 encoder 与一个 RoI head。这一阶段的训练主要是为了对齐 region 级别视觉特征和语言模型,response 的文本长度较短,包括 COCO, RefCOCO,RefCOCO+。
第二阶段训练:冻结 CLIP,联合训练 feature projection layer 和 LLM。这一阶段的训练主要是为了让 LLM 输出更符合人类习惯的回答,response 的文本长度较长,包括 VG,Flickr30k entities,RefCOCOg,Visual Commonsense Reasoning(VCR),LLaVA 150k。
GPT4RoI Demo
单区域理解:GPT4RoI 能感知用户框选区域内的物体的种类,颜色,动作等一系列属性。更进一步,GPT4RoI 具有推理能力:在左图的例子中,推理出男孩一边过马路一边看杂志是一种危险的行为;在右图的例子中,推理出谁是图中跑的最快的人。

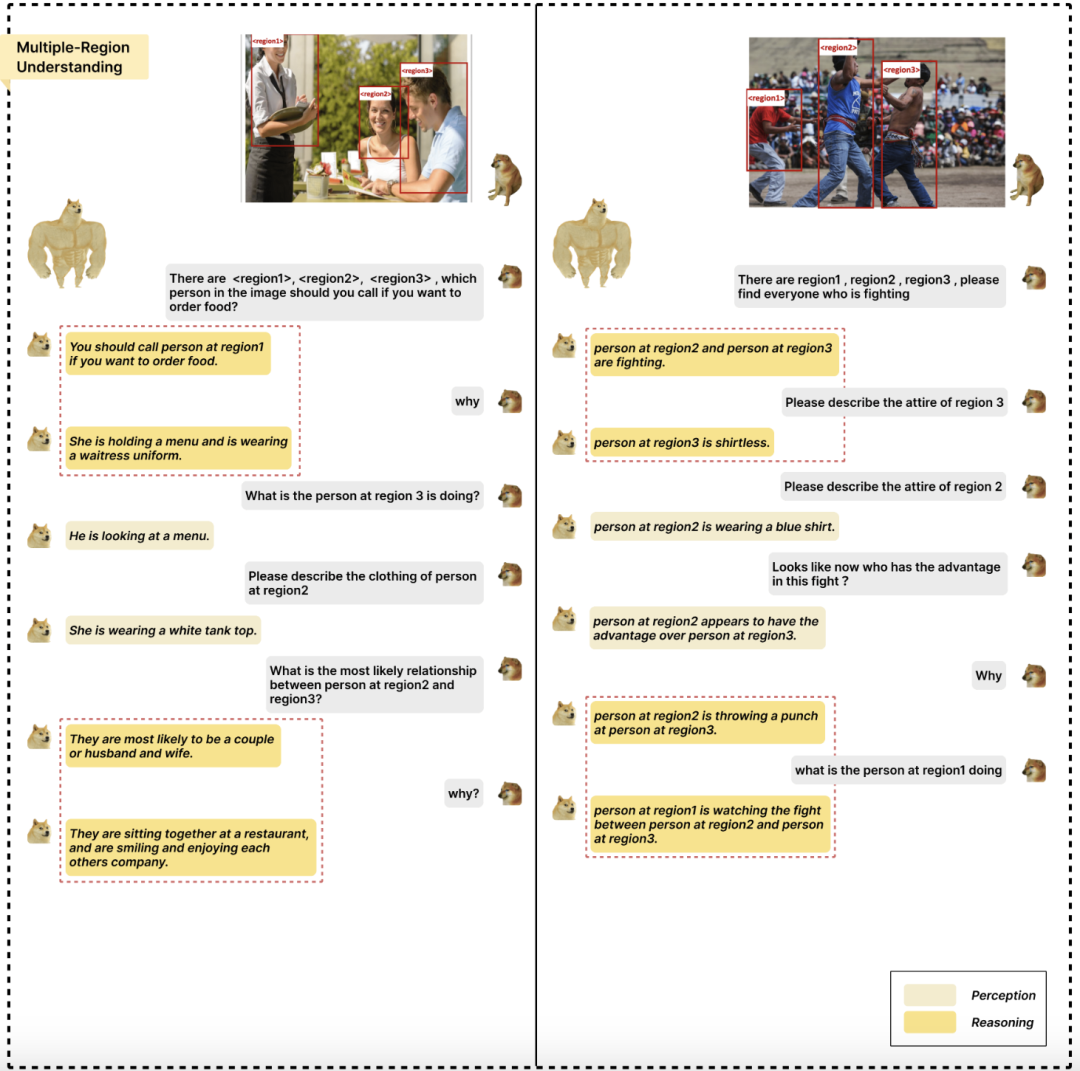
多区域理解:当用户框选多个区域时,GPT4RoI 能够感知每个区域内的物体。更重要的是,GPT4RoI 能够推理出多个区域间的关系:在左图的例子中,推理出 <region2> 和 <region3> 是情侣或夫妻;在右图的例子中,推理出 <region2> 在与 <region3> 的搏击中占据上风。
未来的改进方向
模型架构的改进:基于 CLIP(VIT-Huge)的 vision encoder 在处理大分辨率图像时,消耗巨大的计算资源,但是区域级理解恰恰需要大分辨的图片。而更高效的架构,如基于 CNN 或者 sliding window attention 的架构没有强大如 CLIP 的开源模型。
训练数据的改进:在 region-text pair 数据上的训练对提高模型的区域级理解和推理能力有很大帮助,但是开源的 region-text pair 数据并不多,尤其是包含推理任务的数据。如果将来能收集和标注更多的 region-level caption 和 region-level commonsense reasoning 数据集,有希望进一步提高模型能力。
Region 级别 instruction 的改进:GPT4RoI 主要依靠现有的 region-text pair 标注构造用户 instruction,触发特定功能依旧需要特定的问句,难以理解更多样化的用户指令,希望下一步能收集和构造出更多样的 region 级别的 instruction,提升用户体验。
交互方式的改进:GPT4RoI 目前仅支持自然语言和在线画框的交互方式,增加 point,scribble,以图搜物等更开放的交互方式也能进一步提升用户体验。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-07-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号